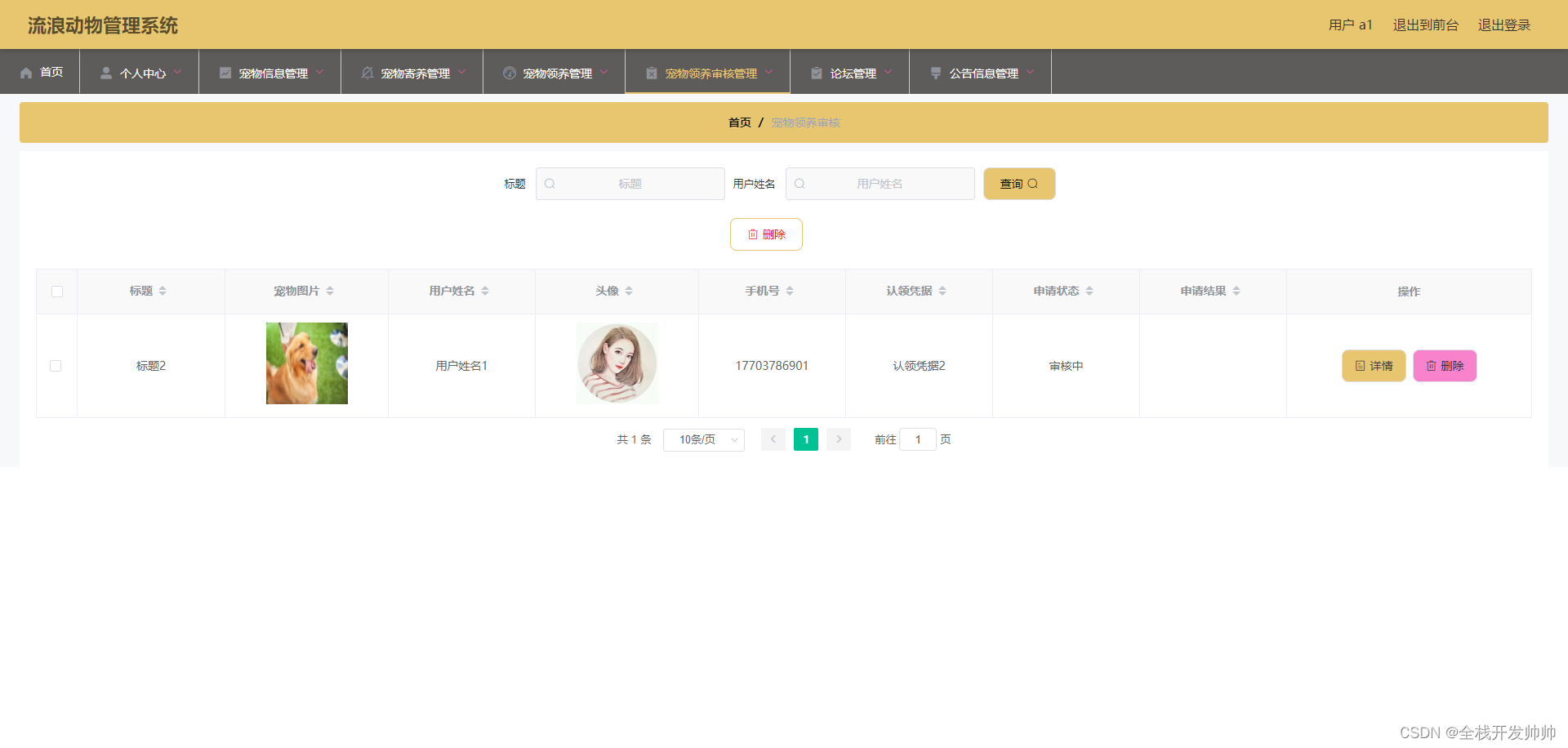
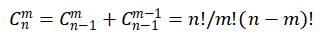我这边有个需求需要把一份docx翻译成指定语言的文档并且保存,研究了下,记录。
首先先安装依赖
pip install python-docx==1.1.2 googletrans==4.0.0rc1python-docx是用来读取docx的,googletrans使用来翻译的。
googletrans · PyPI
这个是官方文档,额外的用法可以再这里找到
然后就是使用.
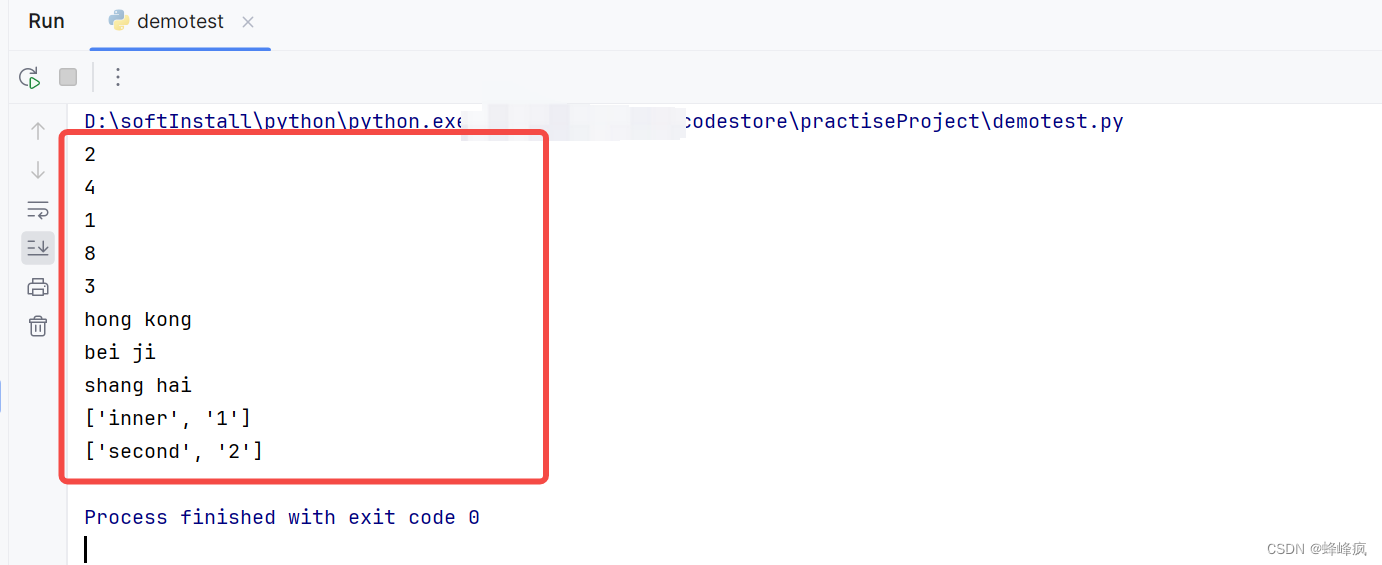
传入文件名,后缀,需要翻译成的语言。我这里用的自动检测语言,但是翻译的速度就会慢一点,如果想要达到最快的翻译速度的话,最好就是指定源语言是什么。这样翻译出来需要一点点时间,但是不会丢失格式,约等于完美翻译。
from googletrans import Translator
def translate(self,filename,ext,to_language):
after_filename=filename+self._add_suffix(to_language)
output_file=os.path.join(self.upload_path, after_filename+ext)
if not os.path.exists(output_file):
translator = Translator()
full_path=os.path.join(self.upload_path, filename+ext)
doc = Document(full_path)
for paragraph in doc.paragraphs:#读取每个段落,回车为结尾
if paragraph.text.strip():
translated_text = self._translate_text(paragraph.text, translator,to_language,filename)
paragraph.text = translated_text.replace('Besides','') #因为有些时候会奇奇怪怪的出现这个翻译,就临时替换一下,之后再找具体解决方案
for table in doc.tables:#读取所有表格内的内容,段落不会读取到表格,所以还要读取一次表格
for row in table.rows:
for cell in row.cells:
if cell.text.strip():
translated_text = self._translate_text(cell.text, translator,to_language,filename)
cell.text = translated_text.replace('Besides','')
doc.save(output_file)
return after_filename,ext
def _translate_text(self,text:str, translator:Translator,to_language:str,filename:str):
translated = translator.translate(text, src=LANGUAGE_KEY.AUTO, dest=to_language)
current_app.logger.info(f'====== In Translate {filename}, to language : {to_language} origin text : {text}, translated : {translated.text}')
return translated.text
def _add_suffix(self,to_language):
return SIGN.UNDERLINE+to_language
如果要获取他所有支持的语言,找这个常量
from googletrans.constants import LANGUAGESLANGUAGES = {
'af': 'afrikaans',
'sq': 'albanian',
'am': 'amharic',
'ar': 'arabic',
'hy': 'armenian',
'az': 'azerbaijani',
'eu': 'basque',
'be': 'belarusian',
'bn': 'bengali',
'bs': 'bosnian',
'bg': 'bulgarian',
'ca': 'catalan',
'ceb': 'cebuano',
'ny': 'chichewa',
'zh-cn': 'chinese (simplified)',
'zh-tw': 'chinese (traditional)',
'co': 'corsican',
'hr': 'croatian',
'cs': 'czech',
'da': 'danish',
'nl': 'dutch',
'en': 'english',
'eo': 'esperanto',
'et': 'estonian',
'tl': 'filipino',
'fi': 'finnish',
'fr': 'french',
'fy': 'frisian',
'gl': 'galician',
'ka': 'georgian',
'de': 'german',
'el': 'greek',
'gu': 'gujarati',
'ht': 'haitian creole',
'ha': 'hausa',
'haw': 'hawaiian',
'iw': 'hebrew',
'he': 'hebrew',
'hi': 'hindi',
'hmn': 'hmong',
'hu': 'hungarian',
'is': 'icelandic',
'ig': 'igbo',
'id': 'indonesian',
'ga': 'irish',
'it': 'italian',
'ja': 'japanese',
'jw': 'javanese',
'kn': 'kannada',
'kk': 'kazakh',
'km': 'khmer',
'ko': 'korean',
'ku': 'kurdish (kurmanji)',
'ky': 'kyrgyz',
'lo': 'lao',
'la': 'latin',
'lv': 'latvian',
'lt': 'lithuanian',
'lb': 'luxembourgish',
'mk': 'macedonian',
'mg': 'malagasy',
'ms': 'malay',
'ml': 'malayalam',
'mt': 'maltese',
'mi': 'maori',
'mr': 'marathi',
'mn': 'mongolian',
'my': 'myanmar (burmese)',
'ne': 'nepali',
'no': 'norwegian',
'or': 'odia',
'ps': 'pashto',
'fa': 'persian',
'pl': 'polish',
'pt': 'portuguese',
'pa': 'punjabi',
'ro': 'romanian',
'ru': 'russian',
'sm': 'samoan',
'gd': 'scots gaelic',
'sr': 'serbian',
'st': 'sesotho',
'sn': 'shona',
'sd': 'sindhi',
'si': 'sinhala',
'sk': 'slovak',
'sl': 'slovenian',
'so': 'somali',
'es': 'spanish',
'su': 'sundanese',
'sw': 'swahili',
'sv': 'swedish',
'tg': 'tajik',
'ta': 'tamil',
'te': 'telugu',
'th': 'thai',
'tr': 'turkish',
'uk': 'ukrainian',
'ur': 'urdu',
'ug': 'uyghur',
'uz': 'uzbek',
'vi': 'vietnamese',
'cy': 'welsh',
'xh': 'xhosa',
'yi': 'yiddish',
'yo': 'yoruba',
'zu': 'zulu',
}如果需要手动检测语言,可以调用这个方法.
from googletrans import Translator
from googletrans.models import Detected
translator = Translator()
text_d:Detected=translator.detect(some_text)
lang_key=text_d.lang可以看到他的source code是返回的一个 Detcted,直接.lang就可以拿到语言的key了