前言
在上一章课程【课程总结】Day13(上):使用YOLO进行目标检测,我们了解到目标检测有两种策略,一种是以YOLO为代表的策略:特征提取→切片→分类回归;另外一种是以MTCNN为代表的策略:先图像切片→特征提取→分类和回归。因此,本章内容将深入了解MTCNN模型,包括:MTCNN的模型组成、模型训练过程、模型预测过程等。
人脸识别
在展开了解MTCNN之前,我们对人脸检测先做一个初步的梳理和了解。人脸识别细分有两种:人脸检测和人脸身份识别。
人脸检测
简述
人脸检测是一个重要的应用领域,它通常用于识别图像或视频中的人脸,并定位其位置。
识别过程
- 输入图像:首先,将包含人脸的图像输入到人脸检测模型中。
- 特征提取:深度学习模型将学习提取图像中的特征,以便识别人脸。
- 人脸定位:模型通过在图像中定位人脸的位置,通常使用矩形边界框来框定人脸区域。
- 输出结果:最终输出包含人脸位置信息的结果,可以是边界框的坐标或其他形式的标注。
输入输出
- 输入:一张图像
- 输出:所有人脸的坐标框
应用场景
- 表情识别:识别人脸的表情,如快乐、悲伤等。
- 年龄识别:根据人脸特征推断出人的年龄段。
- 人脸表情生成:通过检测到的人脸生成不同的表情。
- …

人脸检测特点
人脸检测是目标检测中最简单的任务
- 类别少
- 人脸形状比较固定
- 人脸特征比较固定
- 周围环境一般比较好
人脸身份识别
简述
人脸身份识别是指通过识别人脸上的独特特征来确定一个人的身份。
识别过程
人脸录入流程:
- 数据采集:采集包含人脸的图像数据集。
- 人脸检测:使用人脸检测算法定位图像中的人脸区域。
- 人脸特征提取:通过深度学习模型提取人脸图像的特征向量。
- 特征向量存储:将提取到的特征向量存储在向量数据库中。
人脸验证流程:
- 人脸检测:使用人脸检测算法定位图像中的人脸区域。
- 人脸特征提取:通过深度学习模型提取人脸图像的特征向量。
- 人脸特征匹配:将输入人脸的特征向量与向量数据库中的特征向量进行匹配。
- 身份识别:根据匹配结果确定输入人脸的身份信息。
应用领域
- 安防监控:用于门禁系统、监控系统等,实现人脸识别进出控制。
- 移动支付:通过人脸识别来进行身份验证,实现安全的移动支付功能。
- 社交媒体:用于自动标记照片中的人物,方便用户管理照片。
- 人机交互:实现人脸识别登录、人脸解锁等功能。

一般来说,一切目标检测算法都可以做人脸检测,但是由于通用目标检测算法做人脸检测太重了,所以会使用专门的人脸识别算法,而MTCNN就是这样一个轻量级和专业级的人脸检测网络。
MTCNN模型
简介
MTCNN(Multi-Task Cascaded Convolutional Neural Networks)是一种用于人脸检测和面部对齐的神经网络模型。
论文地址:https://arxiv.org/abs/1604.02878v1
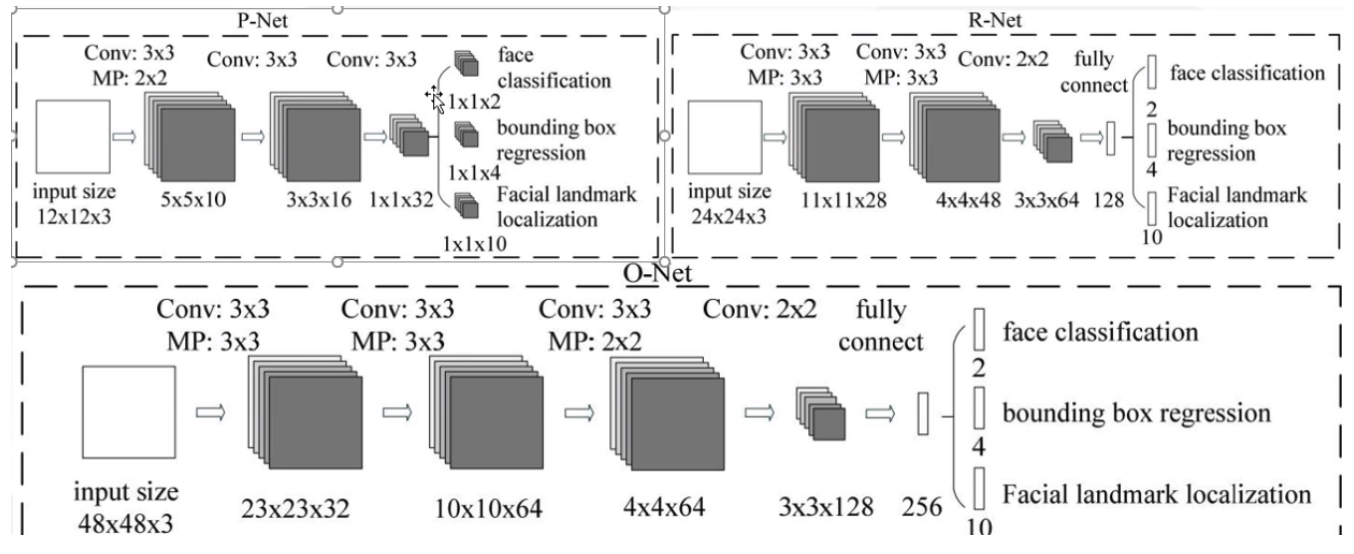
模型结构
- MTCNN采用了级联结构,包括三个阶段的深度卷积网络,分别用于人脸检测和面部对齐。
- 每个阶段都有不同的任务,包括人脸边界框回归、人脸关键点定位等。
这个级联过程,相当于
海选→淘汰赛→决赛的过程。
整体流程
上图是论文中对于MTCNN整体过程的图示,我们换一种较为容易易懂的图示来理解整体过程:
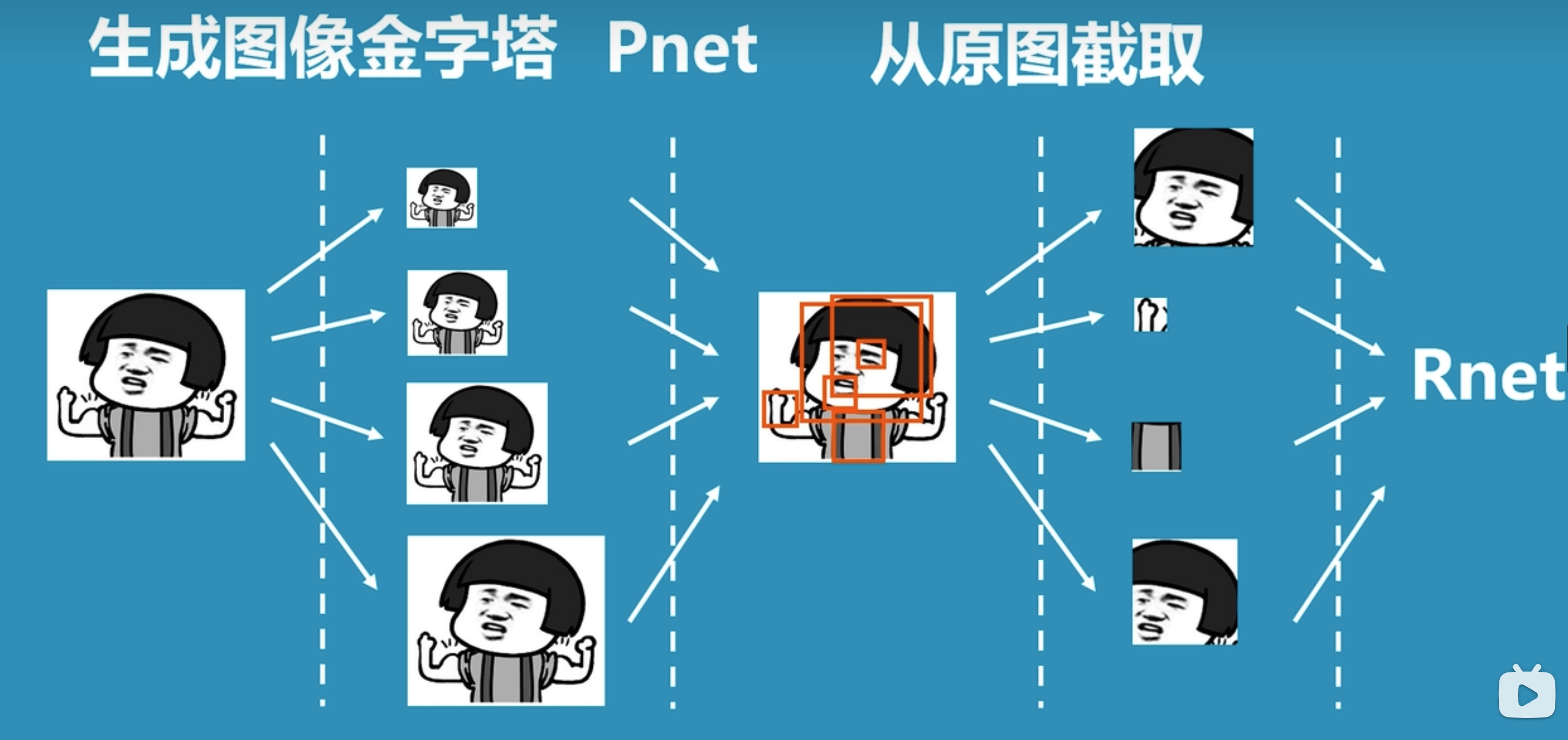
- 先将图片生成不同尺寸的图像金字塔,以便识别不同大小的人脸。
- 将图片输入到P-net中,识别出可能包含人脸的候选窗口。
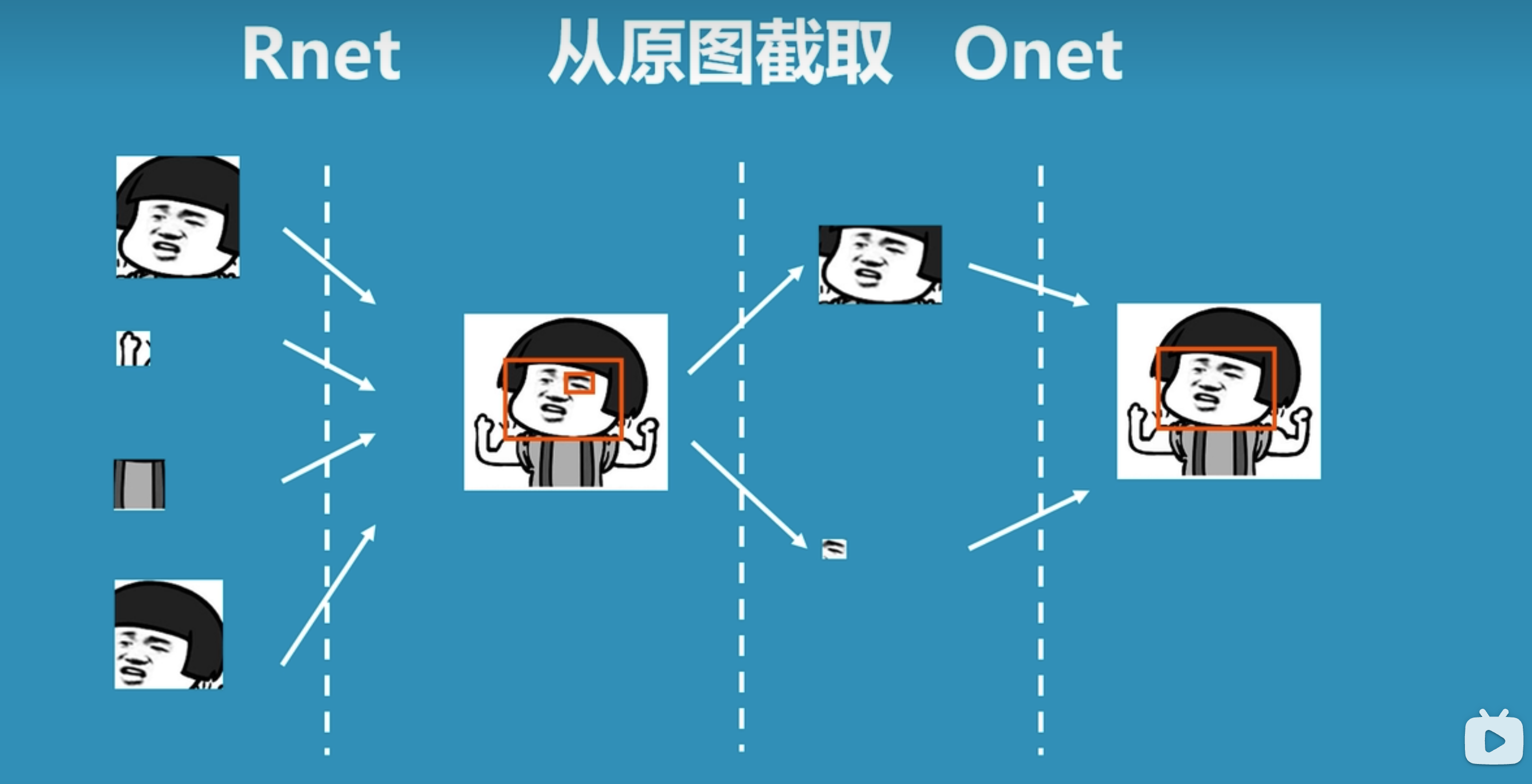
- 将P-net中识别的可能人脸的候选窗口输入到R-net中,识别出更精确的人脸位置。
- 将R-net中识别的人脸位置输入到O-net中,进行更加精细化识别,从而找到人脸区域。
备注:上图引用自科普:什么是mtcnn人脸检测算法
P-net:人脸检测
- 名称:提议网络(proposal network)
- 作用:P网络通过卷积神经网络(CNN)对输入图像进行处理,识别出可能包含人脸的候选窗口,并对这些候选窗口进行边界框的回归,以更准确地定位人脸位置。
- 特点:
- 纯卷积网络,无全链接(精髓所在)
R-net:人脸对齐
- 名称:精修网络(refine network)
- 作用:R网络通过分类器和回归器对P网络生成的候选窗口进行处理,进一步筛选出包含人脸的区域,并对人脸位置进行修正,以提高人脸检测的准确性。
O-net:人脸识别
- 名称:输出网络(output network)
- 作用:O网络通过更深层次的卷积神经网络处理人脸区域,优化人脸位置和姿态,并输出面部关键点信息,为后续的面部对齐提供重要参考。
MTCNN用到的主要模块
图像金字塔
MTCNN的P网络使用的检测方式是:设置建议框,用建议框在图片上滑动检测人脸

由于P网络的建议框的大小是固定的,只能检测12*12范围内的人脸,所以其不断缩小图片以适应于建议框的大小,当下一次图像的最小边长小于12时,停止缩放。
IOU
定义:IOU(Intersection over Union)是指交并比,是目标检测领域常用的一种评估指标,用于衡量两个边界框(Bounding Box)之间的重叠程度。
两种方式:
- 交集比并集
- 交集比最小集
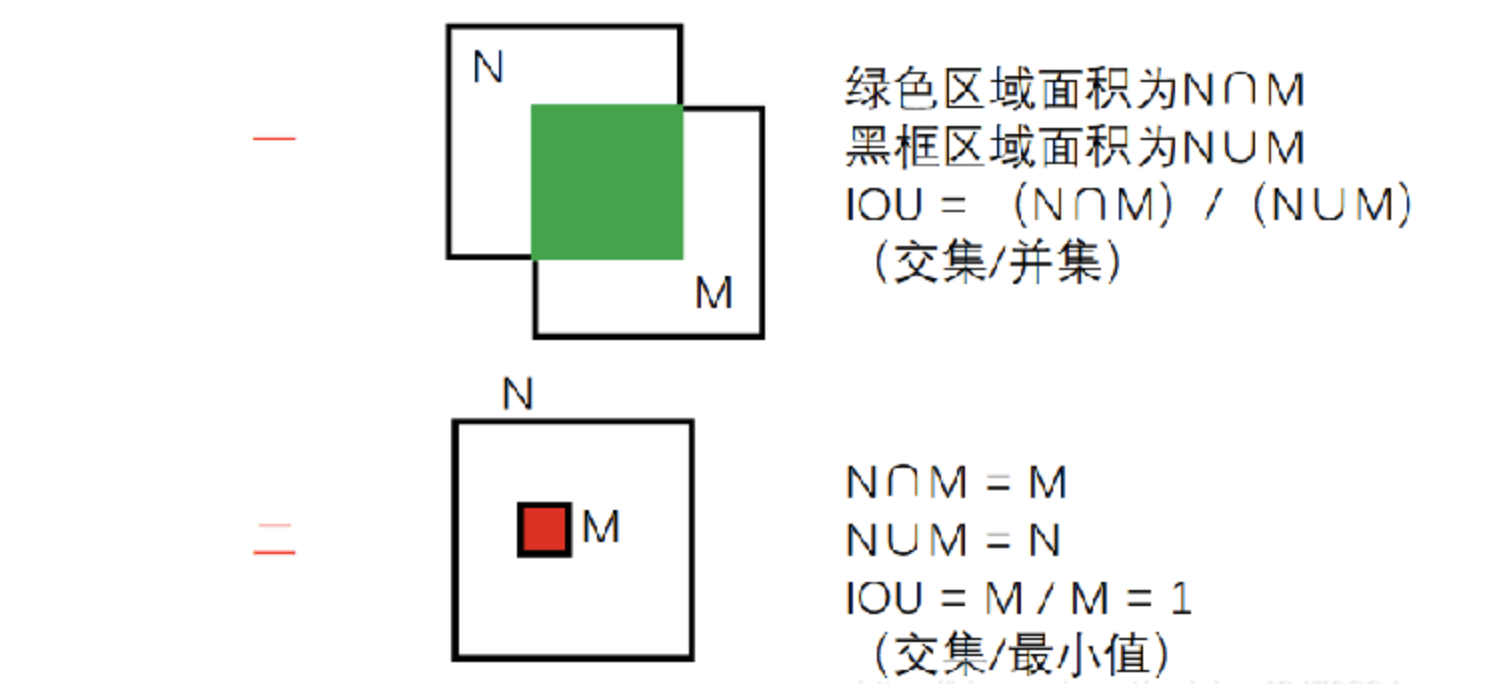
O网络iou值大于阈值的框被认为是重复的框会丢弃,留下iou值小的框,但是如果出现了下图中大框套小框的情况,则iou值偏小也会被保留,是我们不想看到的,因此我们在O网络采用了第二种方式的iou以提高误检率。
NMS(Non-Maximum Suppression,非极大值抑制)
定义:
NMS是一种目标检测中常用的技术,旨在消除重叠较多的候选框,保留最具代表性的边界框,以提高检测的准确性和效率。
工作原理:
NMS的工作原理是通过设置一个阈值,比如IOU(交并比)阈值,对所有候选框按照置信度进行排序,然后从置信度最高的候选框开始,将与其重叠度高于阈值的候选框剔除,保留置信度最高的候选框。

- 如上图所示框出了五个人脸,置信度分别为0.98,0.83,0.75,0.81,0.67,前三个置信度对应左侧的Rose,后两个对应右侧的Jack。
- NMS将这五个框根据置信度排序,取出最大的置信度(0.98)的框分别和剩下的框做iou,保留iou小于阈值的框(代码中阈值设置的是0.3),这样就剩下0.81和0.67这两个框了。
- 重复上面的过程,取出置信度(0.81)大的框和剩下的框做iou,保留iou小于阈值的框。这样最后只剩下0.98和0.81这两个人脸框了。
代码实现
P-Net
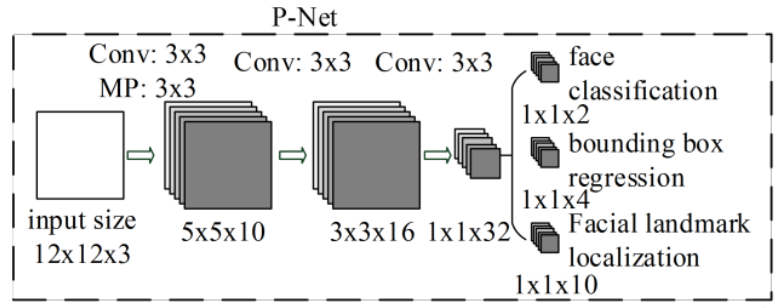
import torch
from torch import nn
"""
P-Net
"""
class PNet(nn.Module):
def __init__(self):
super().__init__()
self.features_extractor = nn.Sequential(
# 第一层卷积
nn.Conv2d(in_channels=3, out_channels=10, kernel_size=3, stride=1, padding=0),
nn.BatchNorm2d(num_features=10),
nn.ReLU(),
# 第一层池化
nn.MaxPool2d(kernel_size=3,stride=2, padding=1),
# 第二层卷积
nn.Conv2d(in_channels=10, out_channels=16, kernel_size=3, stride=1, padding=0),
nn.BatchNorm2d(num_features=16),
nn.ReLU(),
# 第三层卷积
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=0),
nn.BatchNorm2d(num_features=32),
nn.ReLU()
)
# 概率输出
self.cls_out = nn.Conv2d(in_channels=32, out_channels=2, kernel_size=1, stride=1, padding=0)
# 回归量输出
self.reg_out = nn.Conv2d(in_channels=32, out_channels=4, kernel_size=1, stride=1, padding=0)
def forward(self, x):
print(x.shape)
x = self.features_extractor(x)
cls_out = self.cls_out(x)
reg_out = self.reg_out(x)
return cls_out, reg_out
R-Net
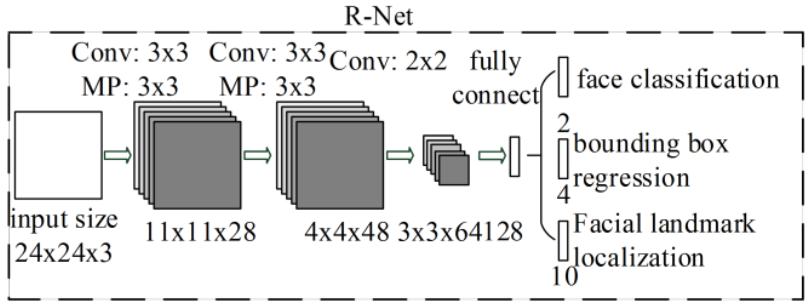
import torch
from torch import nn
class RNet(nn.Module):
def __init__(self):
super().__init__()
self.feature_extractor = nn.Sequential(
# 第一层卷积 24 x 24
nn.Conv2d(in_channels=3, out_channels=28, kernel_size=3, stride=1, padding=0),
nn.BatchNorm2d(num_features=28),
nn.ReLU(),
# 第一层池化 11 x 11
nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=False),
# 第二层卷积 9 x 9
nn.Conv2d(in_channels=28, out_channels=48, kernel_size=3, stride=1, padding=0),
nn.BatchNorm2d(num_features=48),
nn.ReLU(),
# 第二层池化 (没有补零) 4 x 4
nn.MaxPool2d(kernel_size=3, stride=2, padding=0, ceil_mode=False),
# 第三层卷积 3 x 3
nn.Conv2d(in_channels=48, out_channels=64, kernel_size=2, stride=1, padding=0),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
# 展平
nn.Flatten(),
# 全连接层 [batch_size, 128]
nn.Linear(in_features=3 * 3 * 64, out_features=128)
)
# 概率输出
self.cls_out = nn.Linear(in_features=128, out_features=1)
# 回归量输出
self.reg_out = nn.Linear(in_features=128, out_features=4)
def forward(self, x):
x = self.feature_extractor(x)
cls = self.cls_out(x)
reg = self.reg_out(x)
return cls, reg
O-Net
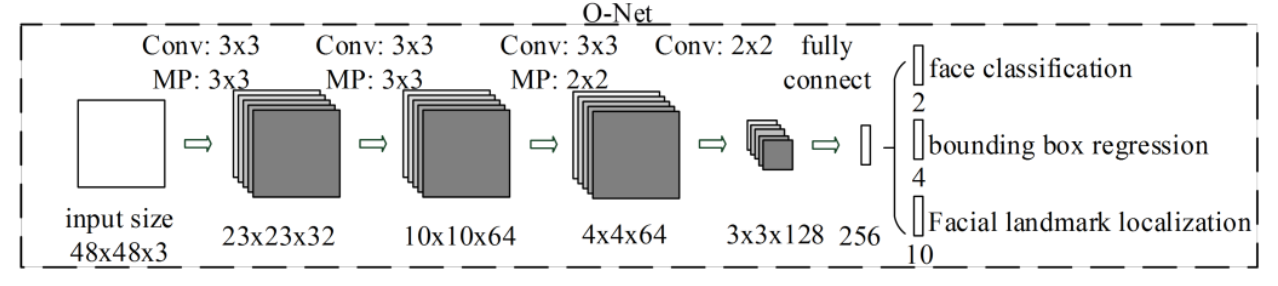
import torch
from torch import nn
class ONet(nn.Module):
def __init__(self):
super().__init__()
self.feature_extractor = nn.Sequential(
# 第1层卷积 48 x 48
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=1, padding=0),
nn.BatchNorm2d(num_features=32),
nn.ReLU(),
# 第1层池化 11 x 11
nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=False),
# 第2层卷积 9 x 9
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=