💐大家好!我是码银~,欢迎关注💐:
CSDN:码银
公众号:码银学编程
实验目的和要求
- 会用Python创建Kmeans聚类分析模型
- 使用KMeans模型对航空公司客户价值进行聚类分析
- 会对聚类结果进行分析评价
实验环境
- pycharm2020
- Win11
- Python3.7
- Anaconda2019
KMeans聚类算法简介
KMeans聚类算法是一种基于中心点的聚类方法,其目标是将数据点划分为K个簇,使得每个簇内的数据点与簇中心的距离之和最小。算法的基本步骤包括:
- 初始化:随机选择K个数据点作为初始簇中心。
- 分配:将每个数据点分配到最近的簇中心,形成K个簇。
- 更新:重新计算每个簇的中心点。
- 迭代:重复步骤2和3,直到簇中心不再变化或达到最大迭代次数。
数据的加载和分析
数据集的获取:搜索微信公众号“码银学编程”。回复:航空数据集
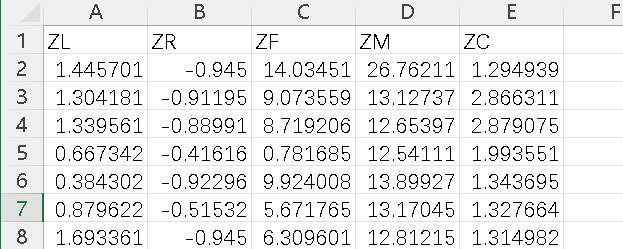
ZL:入会至当前时长,反映客户的活跃时间。
ZR:最近消费时间间隔,反映客户的最近活跃程度。
ZF:消费频次,反映客户的忠诚度。
ZM:消费里程总额,反映客户对航空公司服务的依赖程度。
ZC:舱位等级对应折扣系数,通常舱位等级越高,折扣系数越大。
首先,使用Pandas库加载CSV格式的环境监测数据文件。
def load_data(filepath):
"""加载CSV数据文件"""
return pd.read_csv(filepath, header=0)
聚类分析
接着,使用Scikit-learn库中的KMeans模型对数据进行聚类分析。通过设置不同的参数,如最大迭代次数、簇的数量等,可以对模型进行调整以适应不同的数据集。
def perform_kmeans(data, n_clusters):
"""执行KMeans聚类分析"""
model = KMeans(max_iter=300, n_clusters=n_clusters, random_state=None, tol=0.0001)
model.fit(data)
return model
结果可视化
为了直观展示聚类结果,使用Matplotlib库绘制聚类图。通过将数据点和簇中心在二维平面上表示,可以清晰地观察到数据的分布和簇的划分情况。
def plot_clusters(model, data):
"""绘制聚类结果"""
plt.figure(figsize=(10, 6)) # 设置图表大小
plt.xlabel("ZL-ZR-ZF-ZM-ZC") # 假设环境指标
plt.ylabel("Cluster-center-value")
plt.title("聚类分析结果图")
colors = ['r', 'g', 'y', 'b', 'k']
for i in range(model.n_clusters):
plt.plot(data.columns, model.cluster_centers_[i], label=f'Cluster {i}', color=colors[i], marker='o')
plt.legend()
plt.grid(True)
plt.show()
主函数
def main():
# 加载数据
data = load_data("air_data.csv")
print("数据形状:", data.shape)
print("数据前五行:")
print(data.head())
# 聚类分析
kmodel = perform_kmeans(data, 5)
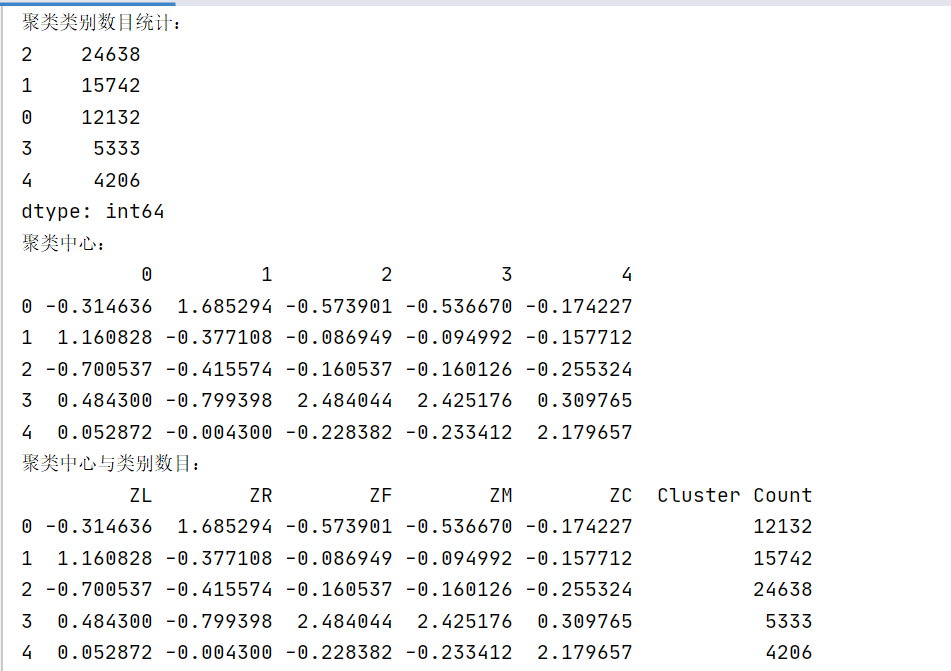
print("聚类类别数目统计:")
print(pd.Series(kmodel.labels_).value_counts())
# 聚类中心
cluster_centers = pd.DataFrame(kmodel.cluster_centers_)
print("聚类中心:")
print(cluster_centers)
# 聚类中心与类别数目
cluster_info = pd.concat([cluster_centers, pd.Series(kmodel.labels_).value_counts()], axis=1)
cluster_info.columns = list(data.columns) + ['Cluster Count']
print("聚类中心与类别数目:")
print(cluster_info)
# 绘制聚类结果图
plot_clusters(kmodel, data)
if __name__ == "__main__":
main()
分析与讨论
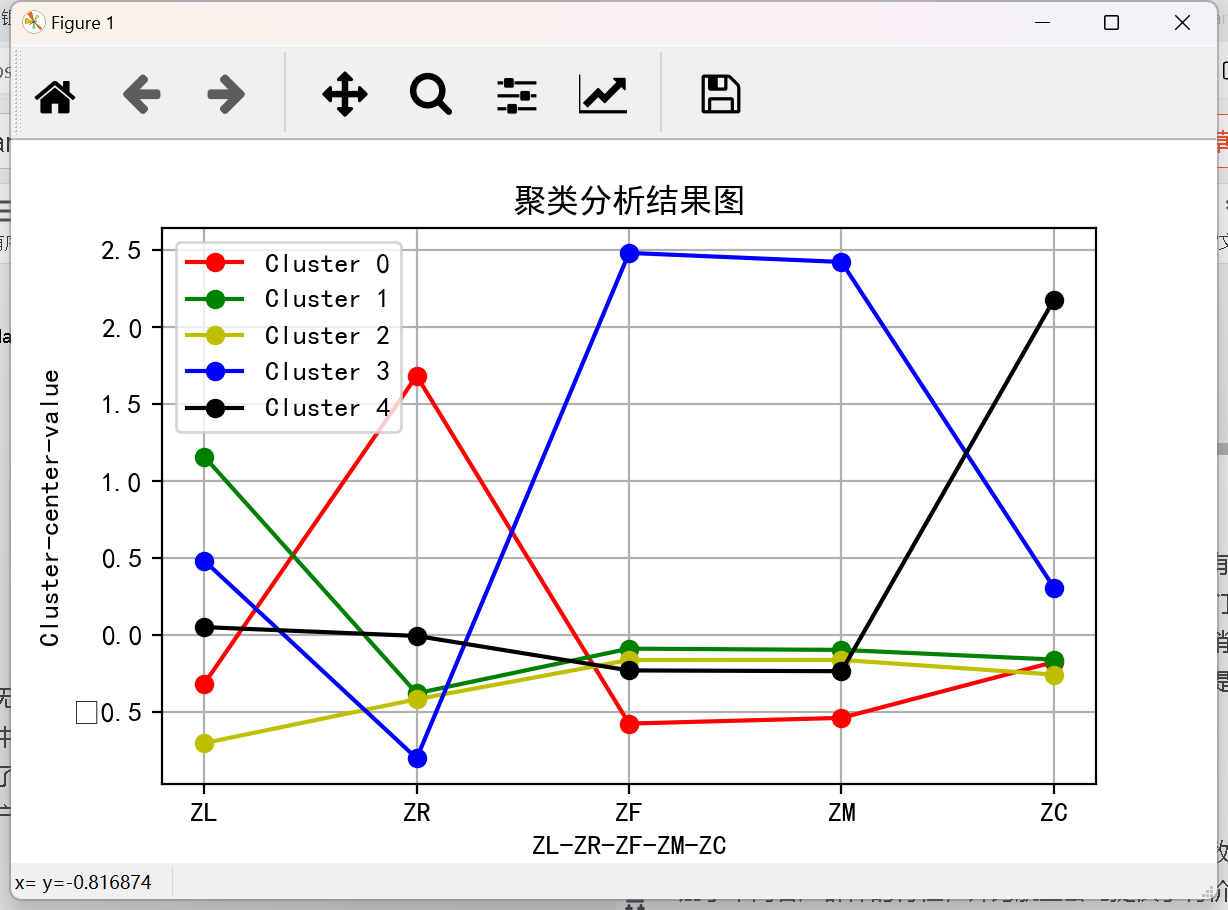
这个结果展示了使用K-Means聚类算法对航空公司客户数据进行分析后得到的聚类中心和每个聚类的样本数量。每一列(ZL、ZR、ZF、ZM、ZC)代表数据集中的一个特征,这些特征分别表示:
- ZL:入会至当前时长,反映客户的活跃时间。
- ZR:最近消费时间间隔,反映客户的最近活跃程度。
- ZF:消费频次,反映客户的忠诚度。
- ZM:消费里程总额,反映客户对航空公司服务的依赖程度。
- ZC:舱位等级对应折扣系数,通常舱位等级越高,折扣系数越大。
聚类中心(Cluster Centers)是每个聚类中所有点的均值,可以看作是该聚类的“代表”或“典型”客户。在这个例子中,我们有5个聚类中心和它们的统计数据:
-
第一个聚类中心(Cluster 0)的ZL值较低,ZR值较高,ZF和ZM值较低,ZC值也较低。这可能代表一群活跃时间较短、最近消费间隔较长、消费频次和里程较低的客户,他们可能对航空公司的忠诚度和依赖程度不高。
-
第二个聚类中心(Cluster 1)的ZL值较高,ZR值较低,ZF值较低,ZM值较低,ZC值较低。这可能代表一群活跃时间较长但最近不太活跃的客户,他们的消费频次和里程也较低。
-
第三个聚类中心(Cluster 2)的ZL和ZR值都较低,ZF值较低,ZM值较低,ZC值较高。这可能代表一群活跃时间较短且最近消费间隔较长的客户,他们的消费频次和里程较低,但可能购买了较高舱位等级的机票。
-
第四个聚类中心(Cluster 3)的ZL和ZR值都较高,ZF和ZM值较高,ZC值也较高。这可能代表一群活跃时间较长、最近消费频繁、消费里程高且购买了较高舱位等级机票的客户,他们对航空公司的忠诚度和依赖程度很高。
-
第五个聚类中心(Cluster 4)的ZL值较低,ZR值较低,ZF值较低,ZM值较低,ZC值较高。这可能代表一群最近活跃且购买了较高舱位等级机票的客户,但他们的总体消费频次和里程较低。
完整代码
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.cluster import KMeans
def load_data(filepath):
"""加载CSV数据文件"""
return pd.read_csv(filepath, header=0)
def perform_kmeans(data, n_clusters):
"""执行KMeans聚类分析"""
model = KMeans(max_iter=300, n_clusters=n_clusters, random_state=None, tol=0.0001)
model.fit(data)
return model
def plot_clusters(model, data):
"""绘制聚类结果"""
plt.figure(figsize=(10, 6)) # 设置图表大小
plt.xlabel("ZL-ZR-ZF-ZM-ZC")
plt.ylabel("Cluster-center-value")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 确保中文标签正常显示
plt.title("聚类分析结果图")
cluster_centers = model.cluster_centers_
colors = ['r', 'g', 'y', 'b', 'k']
for i in range(len(cluster_centers)):
plt.plot(data.columns, cluster_centers[i], label=f'Cluster {i}', color=colors[i], marker='o')
plt.legend()
plt.grid(True) # 添加网格线
plt.show()
def main():
# 加载数据
data = load_data("air_data.csv")
print("数据形状:", data.shape)
print("数据前五行:")
print(data.head())
# 聚类分析
kmodel = perform_kmeans(data, 5)
print("聚类类别数目统计:")
print(pd.Series(kmodel.labels_).value_counts())
# 聚类中心
cluster_centers = pd.DataFrame(kmodel.cluster_centers_)
print("聚类中心:")
print(cluster_centers)
# 聚类中心与类别数目
cluster_info = pd.concat([cluster_centers, pd.Series(kmodel.labels_).value_counts()], axis=1)
cluster_info.columns = list(data.columns) + ['Cluster Count']
print("聚类中心与类别数目:")
print(cluster_info)
# 绘制聚类结果图
plot_clusters(kmodel, data)
if __name__ == "__main__":
main()