pandas支持group_by进行聚合,有如下Excel
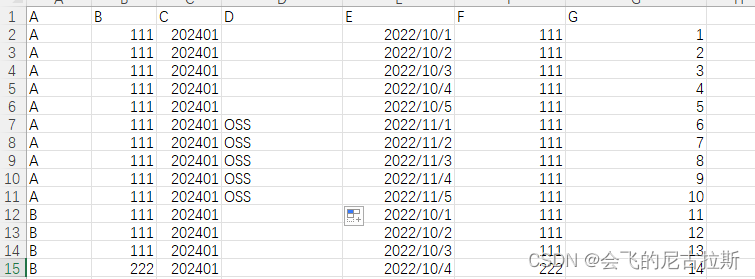
按照A B C D四列进行聚合,其中D列可空也就是nan
import pandas as pd
from pandas import ExcelFile
from pathlib import Path
import os
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
sys.stdin = io.TextIOWrapper(sys.stdin.buffer,encoding='utf-8')
root_path = Path(__file__).absolute().parent
excel_path = os.path.join(root_path,'test.xlsx')
excel_sheetnames = ExcelFile(excel_path).sheet_names
df = pd.read_excel(excel_path,sheet_name=excel_sheetnames[0])
df['year_month'] = df['E'].dt.year.astype(str)+'-'+df['E'].dt.month.astype(str)
# 这句话很关键,否则NAN聚合会出为题
df['D'] = df['D'].astype(str)
vv = df.groupby(['A','B','C','D'])
# print(vv.grouper)
# print(vv.count())
# print(vv.value_counts())
for group_key in vv.groups.keys():
value = vv.get_group(group_key)
print('-------------------个数------------------')
print(len(value))
print(group_key)