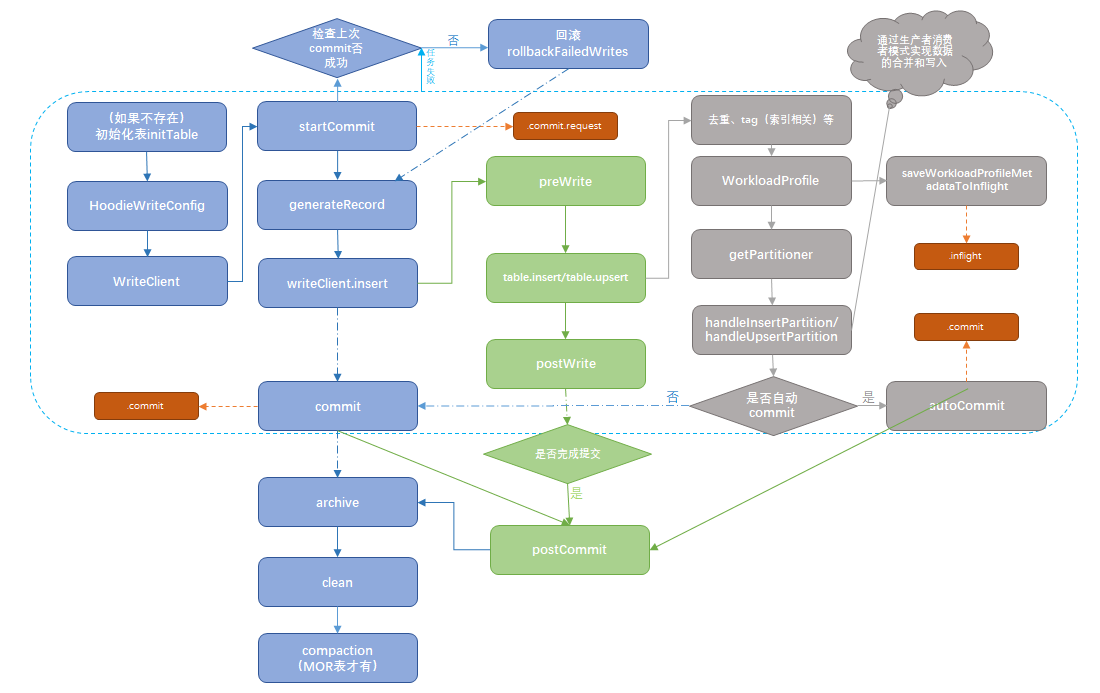
KAN: Kolmogorov–Arnold Networks: A review
公和众与号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)

目录
0. 摘要
1. MLP 也有可学习的激活函数
2. 标题的意义
3. KAN 是具有样条基激活函数的 MLP
4. 关于 KAN 打破维度灾难的说法是错误的
5. 参考文献
0. 摘要
为什么要评论这篇文章?2024 年 4 月 30 日,KAN [Liu et al., 2024] 出现在 ArXiV 上,到 5 月 7 日,我已经从多位学生那里听说了这篇论文,而这些学生平时并不会告诉我新论文。这一定很特别,我想。我决定看看。
如果我在专业上审查这篇论文,我会接受这篇论文,但需要做重大修改。这篇论文有足够的贡献,值得发表。但一些声明需要弱化,解释需要澄清,并且需要与基于样条(spline)的神经网络进行比较。
大纲:我对这篇论文提出了四个主要批评:
- 多层感知机(MLP)也有可学习的激活函数
- 论文的内容不符合其标题,Kolmogorov-Arnold networks(KANs)
- KANs是使用样条基函数作为激活函数的MLP
- KANs并没有打破维度灾难
页面:https://vikasdhiman.info/reviews/2024/05/08/review-KAN/
(2024,KAN,MLP,可训练激活函数,样条函数,分层函数)Kolmogorov–Arnold 网络
1. MLP 也有可学习的激活函数
作者在摘要中声称: “虽然 MLP 在节点(“神经元”)上有固定的激活函数,但 KANs 在边(“权重”)上有可学习的激活函数。KANs 根本没有线性权重——每个权重参数都被一个参数化为样条的单变量函数所取代。”
这不是一个有用的描述,因为也可以将 MLP 解释为有 “可学习的激活函数”;这取决于你如何定义“激活函数”。考虑一个两层的 MLP,输入 x ∈ R^n,权重 W1, W2(暂时忽略偏置)和激活函数σ,
![]()
如果我定义 ϕ1(x) = σ(W_1·x) 并将 ϕ1(.) 称为激活函数,那么我在 MLP 中有一个可学习的激活函数。与图 0.1 相同,这是一种重新解释,而不是如所声称的那样重新设计 MLP。

2. 标题的意义
KANs 实际如何使用 Kolmogorov-Arnold Theorem(KAT)?该定理在 KANs 的开发中并没有实际作用。KANs 只是受到 KAT 的启发,而不是基于它。
那么 KAT 是什么?论文将其描述为,将任何光滑函数 f : [0, 1]^n → R 分解为有限基函数 ϕ^(2)_ q: R → R 和 ϕ_(q,p) : [0, 1] → R。

如果你打算使用 KAT,你需要理解 KAT 定理的中心论点,以及该定理与最接近的竞争对手通用逼近定理(Universal Approximation Theorem,UAT)有何不同。UAT 表明,任何函数都可以通过足够宽的两层神经网络来逼近。

我以求和的方式写了 MLP,而不是矩阵乘法,以便在 UAT 和 KAT 之间画出相似之处。UAT 和 KAT 之间有两个主要区别:
- UAT 处理具有常见激活函数的线性层(如 sigmoid [Cybenko, 1989]、ReLU、tanh),而 KAT 处理任意函数,可能是 “非平滑甚至分形的”。
- UAT 可能需要无限的隐藏单元(hidden units)进行精确逼近,而 KAT 只需要 2n+1 个隐藏单元。
我认为 KAT 的中心点在于只需要 2n + 1 个隐藏单元,否则它是一个比 UAT 弱的定理。KAN 论文是否一致使用了 2n + 1 个隐藏单元?没有。但他们通过说以下内容来证明论文的其余部分基于 KAT, “然而,我们对 KAT 在机器学习中的有用性更加乐观。首先,我们不需要坚持只有两层非线性和隐藏层中少量项(2n + 1)的原始公式(2.1):我们将网络推广到任意宽度和深度。”

好吧。但那我们不就回到了 UAT 了吗?
作者强调了 KAT 的一个方面,“从某种意义上说,他们表明唯一真正的多变量函数是加法,因为每个其他函数都可以使用单变量函数和求和来表示。” 这是一个很酷的解释,但这种解释并不能将 KAT 与已经在 MLP 中使用的 UAT 区分开来。
3. KAN 是具有样条基激活函数的 MLP
实际上,作者最终提出了一个 KAN 残差层,其每个标量函数写为,

什么是样条?【https://personal.math.vt.edu/embree/math5466/lecture10.pdf】对于本节的目的,你不需要了解样条。顺便说一句,一些样条在神经网络中使用的论文 [Bohra et al., 2020, Aziznejad et al., 2020] 没有在 KAN 论文中引用 。
现在,假设样条是特定类型基函数 B_i(x) 的线性组合 c_i·B_i(x) 的结果。为了将这个标量函数重新解释为 MLP,让我们重新写成如下,

其中,w 包含样条的可学习参数,一旦样条网格固定,b(x) 是确定的,尽管它可以变得可学习。让我们将其代入(2),

如果我们将 w 视为线性权重,将基函数视为激活函数,这与 MLP 非常接近,有以下几个区别:
- 激活函数 b() 应用在输入侧,这通常不是 MLP 的一部分。然而,将输入转换为一组特征向量作为预处理步骤,而不是直接提供原始输入给 MLP,是很常见的。
- 不像(3)中 w^(1)_(p,q) 是标量,(10) 中的 w^(1)_(p,q) 是向量。这不是问题,因为它仍然是通过基函数 b(x) 处理后的输入值的线性组合。为了明确这一点,我们将(10)写成矩阵向量乘法,后跟激活函数。
为了将(10)写成矩阵向量乘积,只考虑第一层项,

你可以重复应用这种解释,
![]()
![]()
其中,B(x) 与其他激活函数不同。它不是从一个标量产生一个标量,而是为输入中的每个标量值产生 G 个不同的值。
4. 关于 KAN 打破维度灾难的说法是错误的
作者声称,“KAN 具有有限网格大小,可以很好地逼近函数,其残差率与维度无关,因此打破了维度灾难!”
这是一个巨大的声明,需要大量的证据。正如前一节所述,如果所有 KAN 都可以写成 MLP,那么要么 MLP 和 KAN 都打破了维度灾难,要么都没有。
我的第一个反对意见是对 “维度灾难” 的解释。通常,机器学习中的维度灾难是通过训练一个函数达到所需误差所需的数据量来衡量的。
我不理解定理 2.1 的证明,尤其是第一步。不清楚这一结果是如何从 [de Boor, 2001] 中的哪个定理得出的。如果能提供页码或章节那就更好了。
这也违反直觉,因为假定所有 n 个输入维度都有相同的网格大小 G。如果 x 的每个维度被划分为不同的网格大小,界限会是什么样子。


5. 参考文献
[Aziznejad et al., 2020] Aziznejad, S., Gupta, H., Campos, J., and Unser, M. (2020). Deep neural networks with trainable activations and controlled lipschitz constant. IEEE Transactions on Signal Processing, 68:4688–4699.
[Bohra et al., 2020] Bohra, P., Campos, J., Gupta, H., Aziznejad, S., and Unser, M. (2020). Learning activation functions in deep (spline) neural networks. IEEE Open Journal of Signal Processing, 1:295–309.
[Cybenko, 1989] Cybenko, G. (1989). Approximation by superpositions of a sigmoidal function. Mathematics of control, signals and systems, 2(4):303–314.
[de Boor, 2001] de Boor, C. (2001). A Practical Guide to Splines. Applied Mathematical Sciences. Springer New York.
[Liu et al., 2024] Liu, Z., Wang, Y., Vaidya, S., Ruehle, F., Halverson, J., Soljaˇci´c, M., Hou, T. Y., and Tegmark, M. (2024). Kan: Kolmogorov-arnold networks. arXiv preprint arXiv:2404.19756.

![[C++]——继承 深继承](https://i-blog.csdnimg.cn/direct/5325aa76935740359cb7bc9922d678c4.png)