在近年来的深度学习领域,Transformer模型凭借其在自然语言处理(NLP)中的卓越表现,迅速成为研究热点。尤其是基于自注意力(Self-Attention)机制的模型,更是推动了NLP的飞速发展。然而,随着研究的深入,Transformer模型不仅在NLP领域大放异彩,还被引入到计算机视觉领域,形成了Vision Transformer(ViT)。ViT模型在不依赖传统卷积神经网络(CNN)的情况下,依然能够在图像分类任务中取得优异的效果。本文将深入解析ViT模型的结构、特点,并通过代码示例展示如何使用MindSpore框架实现ViT模型的训练、验证和推理。
ViT模型结构
ViT模型的主体结构基于Transformer模型的编码器(Encoder)部分,其整体结构如下图所示:
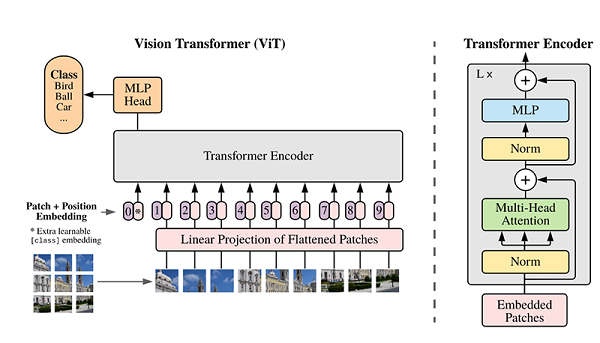
模型特点
为什么要使用Patch Embedding?
在传统的Transformer模型中,输入通常是一维的词向量序列,而图像数据是二维的像素矩阵。为了将图像数据转换为Transformer可以处理的形式,我们需要将图像划分为多个小块(patch),并将每个patch转换为一维向量。这一过程称为Patch Embedding。通过这种方式,我们可以将图像数据转换为类似于词向量的形式,从而利用Transformer模型处理图像数据。
为什么要使用位置编码(Position Embedding)?
由于Transformer模型在处理输入序列时不考虑顺序信息,因此在图像数据中,patch之间的空间关系可能会丢失。为了解决这个问题,我们引入了位置编码(Position Embedding),它为每个patch增加了位置信息,使得模型能够识别不同patch之间的空间关系。这对于保留图像的空间结构信息非常重要。
- Patch Embedding:输入图像被划分为多个patch(图像块),然后将每个二维patch转换为一维向量,并加上类别向量和位置向量作为模型输入。
- Transformer Encoder:模型主体的Block结构基于Transformer的Encoder部分,主要结构是多头注意力(Multi-Head Attention)和前馈神经网络(Feed Forward)。
- 分类头(Head):在Transformer Encoder堆叠后接一个全连接层,用于分类。
环境准备与数据读取
开始实验之前,请确保本地已经安装了Python环境和MindSpore。
首先下载本案例的数据集,该数据集是从ImageNet中筛选出来的子集。数据集路径结构如下:
.dataset/
├── ILSVRC2012_devkit_t12.tar.gz
├── train/
├── infer/
└── val/
from download import download
import os
import mindspore as ms
from mindspore.dataset import ImageFolderDataset
import mindspore.dataset.vision as transforms
# 下载数据集
dataset_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/vit_imagenet_dataset.zip"
path = "./"
path = download(dataset_url, path, kind="zip", replace=True)
data_path = './dataset/'
mean = [0.485 * 255, 0.456 * 255, 0.406 * 255]
std = [0.229 * 255, 0.224 * 255, 0.225 * 255]
dataset_train = ImageFolderDataset(os.path.join(data_path, "train"), shuffle=True)
trans_train = [
transforms.RandomCropDecodeResize(size=224, scale=(0.08, 1.0), ratio=(0.75, 1.333)),
transforms.RandomHorizontalFlip(prob=0.5),
transforms.Normalize(mean=mean, std=std),
transforms.HWC2CHW()
]
dataset_train = dataset_train.map(operations=trans_train, input_columns=["image"])
dataset_train = dataset_train.batch(batch_size=16, drop_remainder=True)
Transformer基本原理
Transformer模型源于2017年的一篇文章,其主要结构为多个编码器和解码器模块。编码器和解码器由多头注意力(Multi-Head Attention)、前馈神经网络(Feed Forward)、归一化层(Normalization)和残差连接(Residual Connection)组成。
Self-Attention机制
Self-Attention机制是Transformer的核心,其主要步骤如下:
- 输入向量映射:将输入向量映射成Query(Q)、Key(K)、Value(V)三个向量。
- 计算注意力权重:通过点乘计算Query和Key的相似性,并通过Softmax函数归一化。
- 加权求和:使用注意力权重对Value进行加权求和,得到最终的Attention输出。
以下是Self-Attention的代码实现:
from mindspore import nn, ops
class Attention(nn.Cell):
def __init__(self, dim: int, num_heads: int = 8, keep_prob: float = 1.0, attention_keep_prob: float = 1.0):
super(Attention, self).__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = ms.Tensor(head_dim ** -0.5)
self.qkv = nn.Dense(dim, dim * 3)
self.attn_drop = nn.Dropout(p=1.0-attention_keep_prob)
self.out = nn.Dense(dim, dim)
self.out_drop = nn.Dropout(p=1.0-keep_prob)
self.attn_matmul_v = ops.BatchMatMul()
self.q_matmul_k = ops.BatchMatMul(transpose_b=True)
self.softmax = nn.Softmax(axis=-1)
def construct(self, x):
b, n, c = x.shape
qkv = self.qkv(x)
qkv = ops.reshape(qkv, (b, n, 3, self.num_heads, c // self.num_heads))
qkv = ops.transpose(qkv, (2, 0, 3, 1, 4))
q, k, v = ops.unstack(qkv, axis=0)
attn = self.q_matmul_k(q, k)
attn = ops.mul(attn, self.scale)
attn = self.softmax(attn)
attn = self.attn_drop(attn)
out = self.attn_matmul_v(attn, v)
out = ops.transpose(out, (0, 2, 1, 3))
out = ops.reshape(out, (b, n, c))
out = self.out(out)
out = self.out_drop(out)
return out
Transformer Encoder
为什么要使用残差连接(Residual Connection)和归一化层(Normalization Layer)?
在深层神经网络中,随着层数的增加,梯度消失和梯度爆炸的问题变得越来越严重。残差连接通过在每一层加上输入的跳跃连接,可以有效缓解这些问题,确保信息能够顺利传递。此外,归一化层(如LayerNorm)可以加速模型的训练,并提高模型的稳定性和泛化能力。这些技术的结合,使得Transformer模型能够在更深的层次上进行有效的训练。
Transformer Encoder由多层Self-Attention和前馈神经网络(Feed Forward)组成,通过残差连接和归一化层增强模型的训练效果和泛化能力。
class FeedForward(nn.Cell):
def __init__(self, in_features: int, hidden_features: Optional[int] = None, out_features: Optional[int] = None, activation: nn.Cell = nn.GELU, keep_prob: float = 1.0):
super(FeedForward, self).__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.dense1 = nn.Dense(in_features, hidden_features)
self.activation = activation()
self.dense2 = nn.Dense(hidden_features, out_features)
self.dropout = nn.Dropout(p=1.0-keep_prob)
def construct(self, x):
x = self.dense1(x)
x = self.activation(x)
x = self.dropout(x)
x = self.dense2(x)
x = self.dropout(x)
return x
class ResidualCell(nn.Cell):
def __init__(self, cell):
super(ResidualCell, self).__init__()
self.cell = cell
def construct(self, x):
return self.cell(x) + x
class TransformerEncoder(nn.Cell):
def __init__(self, dim: int, num_layers: int, num_heads: int, mlp_dim: int, keep_prob: float = 1., attention_keep_prob: float = 1.0, drop_path_keep_prob: float = 1.0, activation: nn.Cell = nn.GELU, norm: nn.Cell = nn.LayerNorm):
super(TransformerEncoder, self).__init__()
layers = []
for _ in range(num_layers):
normalization1 = norm((dim,))
normalization2 = norm((dim,))
attention = Attention(dim=dim, num_heads=num_heads, keep_prob=keep_prob, attention_keep_prob=attention_keep_prob)
feedforward = FeedForward(in_features=dim, hidden_features=mlp_dim, activation=activation, keep_prob=keep_prob)
layers.append(nn.SequentialCell([ResidualCell(nn.SequentialCell([normalization1, attention])), ResidualCell(nn.SequentialCell([normalization2, feedforward]))]))
self.layers = nn.SequentialCell(layers)
def construct(self, x):
return self.layers(x)
ViT模型的输入
ViT模型通过将输入图像划分为多个patch,将每个patch转换为一维向量,并加上类别向量和位置向量作为模型输入。以下是Patch Embedding的代码实现:
class PatchEmbedding(nn.Cell):
MIN_NUM_PATCHES = 4
def __init__(self, image_size: int = 224, patch_size: int = 16, embed_dim: int = 768, input_channels: int = 3):
super(PatchEmbedding, self).__init__()
self.image_size = image_size
self.patch_size = patch_size
self.num_patches = (image_size // patch_size) ** 2
self.conv = nn.Conv2d(input_channels, embed_dim, kernel_size=patch_size, stride=patch_size, has_bias=True)
def construct(self, x):
x = self.conv(x)
b, c, h, w = x.shape
x = ops.reshape(x, (b, c, h * w))
x = ops.transpose(x, (0, 2, 1))
return x
整体构建ViT
以下代码构建了一个完整的ViT模型:
from mindspore.common.initializer import Normal
from mindspore.common.initializer import initializer
from mindspore import Parameter
def init(init_type, shape, dtype, name, requires_grad):
initial = initializer(init_type, shape, dtype).init_data()
return Parameter(initial, name=name, requires_grad=requires_grad)
class ViT(nn.Cell):
def __init__(self, image_size: int = 224, input_channels: int = 3, patch_size: int = 16, embed_dim: int = 768, num_layers: int = 12, num_heads: int = 12, mlp_dim: int = 3072, keep_prob: float = 1.0, attention_keep_prob: float = 1.0, drop_path_keep_prob: float = 1.0, activation: nn.Cell = nn.GELU, norm: Optional[nn.Cell] = nn.LayerNorm, pool: str = 'cls') -> None:
super(ViT, self).__init__()
self.patch_embedding = PatchEmbedding(image_size=image_size, patch_size=patch_size, embed_dim=embed_dim, input_channels=input_channels)
num_patches = self.patch_embedding.num_patches
self.cls_token = init(init_type=Normal(sigma=1.0), shape=(1, 1, embed_dim), dtype=ms.float32, name='cls', requires_grad=True)
self.pos_embedding = init(init_type=Normal(sigma=1.0), shape=(1, num_patches + 1, embed_dim), dtype=ms.float32, name='pos_embedding', requires_grad=True)
self.pool = pool
self.pos_dropout = nn.Dropout(p=1.0-keep_prob)
self.norm = norm((embed_dim,))
self.transformer = TransformerEncoder(dim=embed_dim, num_layers=num_layers, num_heads=num_heads, mlp_dim=mlp_dim, keep_prob=keep_prob, attention_keep_prob=attention_keep_prob, drop_path_keep_prob=drop_path_keep_prob, activation=activation, norm=norm)
self.dropout = nn.Dropout(p=1.0-keep_prob)
self.dense = nn.Dense(embed_dim, num_classes)
def construct(self, x):
x = self.patch_embedding(x)
cls_tokens = ops.tile(self.cls_token.astype(x.dtype), (x.shape[0], 1, 1))
x = ops.concat((cls_tokens, x), axis=1)
x += self.pos_embedding
x = self.pos_dropout(x)
x = self.transformer(x)
x = self.norm(x)
x = x[:, 0]
if self.training:
x = self.dropout(x)
x = self.dense(x)
return x
模型训练与推理
模型训练
模型训练前,需要设定损失函数、优化器和回调函数。以下是训练ViT模型的代码:
from mindspore.nn import LossBase
from mindspore.train import LossMonitor, TimeMonitor, CheckpointConfig, ModelCheckpoint
from mindspore import train
# 定义超参数
epoch_size = 10
momentum = 0.9
num_classes = 1000
resize = 224
step_size = dataset_train.get_dataset_size()
# 构建模型
network = ViT()
# 加载预训练模型参数
vit_url = "https://download.mindspore.cn/vision/classification/vit_b_16_224.ckpt"
path = "./ckpt/vit_b_16_224.ckpt"
vit_path = download(vit_url, path, replace=True)
param_dict = ms.load_checkpoint(vit_path)
ms.load_param_into_net(network, param_dict)
# 定义学习率
lr = nn.cosine_decay_lr(min_lr=float(0), max_lr=0.00005, total_step=epoch_size * step_size, step_per_epoch=step_size, decay_epoch=10)
# 定义优化器
network_opt = nn.Adam(network.trainable_params(), lr, momentum)
# 定义损失函数
class CrossEntropySmooth(LossBase):
def __init__(self, sparse=True, reduction='mean', smooth_factor=0., num_classes=1000):
super(CrossEntropySmooth, self).__init__()
self.onehot = ops.OneHot()
self.sparse = sparse
self.on_value = ms.Tensor(1.0 - smooth_factor, ms.float32)
self.off_value = ms.Tensor(1.0 * smooth_factor / (num_classes - 1), ms.float32)
self.ce = nn.SoftmaxCrossEntropyWithLogits(reduction=reduction)
def construct(self, logit, label):
if self.sparse:
label = self.onehot(label, ops.shape(logit)[1], self.on_value, self.off_value)
loss = self.ce(logit, label)
return loss
network_loss = CrossEntropySmooth(sparse=True, reduction="mean", smooth_factor=0.1, num_classes=num_classes)
# 设置检查点
ckpt_config = CheckpointConfig(save_checkpoint_steps=step_size, keep_checkpoint_max=100)
ckpt_callback = ModelCheckpoint(prefix='vit_b_16', directory='./ViT', config=ckpt_config)
# 初始化模型
ascend_target = (ms.get_context("device_target") == "Ascend")
if ascend_target:
model = train.Model(network, loss_fn=network_loss, optimizer=network_opt, metrics={"acc"}, amp_level="O2")
else:
model = train.Model(network, loss_fn=network_loss, optimizer=network_opt, metrics={"acc"}, amp_level="O0")
# 训练模型
model.train(epoch_size, dataset_train, callbacks=[ckpt_callback, LossMonitor(125), TimeMonitor(125)], dataset_sink_mode=False)

模型验证
模型验证过程主要应用了ImageFolderDataset,CrossEntropySmooth和Model等接口。以下是验证ViT模型的代码:
dataset_val = ImageFolderDataset(os.path.join(data_path, "val"), shuffle=True)
trans_val = [
transforms.Decode(),
transforms.Resize(224 + 32),
transforms.CenterCrop(224),
transforms.Normalize(mean=mean, std=std),
transforms.HWC2CHW()
]
dataset_val = dataset_val.map(operations=trans_val, input_columns=["image"])
dataset_val = dataset_val.batch(batch_size=16, drop_remainder=True)
# 构建模型
network = ViT()
# 加载预训练模型参数
param_dict = ms.load_checkpoint(vit_path)
ms.load_param_into_net(network, param_dict)
network_loss = CrossEntropySmooth(sparse=True, reduction="mean", smooth_factor=0.1, num_classes=num_classes)
# 定义评价指标
eval_metrics = {'Top_1_Accuracy': train.Top1CategoricalAccuracy(), 'Top_5_Accuracy': train.Top5CategoricalAccuracy()}
if ascend_target:
model = train.Model(network, loss_fn=network_loss, optimizer=network_opt, metrics=eval_metrics, amp_level="O2")
else:
model = train.Model(network, loss_fn=network_loss, optimizer=network_opt, metrics=eval_metrics, amp_level="O0")
# 验证模型
result = model.eval(dataset_val)
print(result)
模型推理
在进行模型推理之前,首先要定义一个对推理图片进行数据预处理的方法。以下是推理ViT模型的代码:
dataset_infer = ImageFolderDataset(os.path.join(data_path, "infer"), shuffle=True)
trans_infer = [
transforms.Decode(),
transforms.Resize([224, 224]),
transforms.Normalize(mean=mean, std=std),
transforms.HWC2CHW()
]
dataset_infer = dataset_infer.map(operations=trans_infer, input_columns=["image"], num_parallel_workers=1)
dataset_infer = dataset_infer.batch(1)
# 读取推理数据
for i, image in enumerate(dataset_infer.create_dict_iterator(output_numpy=True)):
image = image["image"]
image = ms.Tensor(image)
prob = model.predict(image)
label = np.argmax(prob.asnumpy(), axis=1)
mapping = index2label()
output = {int(label): mapping[int(label)]}
print(output)
show_result(img="./dataset/infer/n01440764/ILSVRC2012_test_00000279.JPEG", result=output, out_file="./dataset/infer/ILSVRC2012_test_00000279.JPEG")