1 介绍
机器遗忘(Machine Unlearning)是指从机器学习模型中安全地移除或"遗忘"特定的数据点或信息。这个概念源于数据隐私保护的需求,尤其是在欧盟通用数据保护条例(GDPR)等法规中提出的"被遗忘的权利"(Right to be Forgotten)。机器遗忘的目标是确保一旦用户请求删除其个人数据,相关的机器学习模型也能够相应地更新,以确保不再利用这些数据进行预测或分析。
具体来说,机器遗忘包括以下几个关键点:
- 数据点的移除:从训练数据集中删除特定的数据点,同时确保模型的泛化能力不受影响。
- 模型更新:在数据点被移除后,对模型进行更新,以反映数据的变更,这可能涉及到重新训练或使用更高效的更新技术。
- 隐私保护:确保在数据被遗忘后,模型不会保留任何可以追溯到被遗忘数据的信息,从而保护用户的隐私。
- 法律遵从:满足法律法规对于数据删除和隐私保护的要求。
本文介绍了机器遗忘技术的分类、优缺点、威胁、攻击、防御机制以及评估方法。首先将机器遗忘技术分为精确遗忘和近似遗忘两大类,并对每类中的不同方法进行了详细讨论。精确遗忘技术涉及SISA结构、图模型、k-Means和联邦学习等,而近似遗忘技术则基于影响函数、重新优化、梯度更新和特定于图数据的方法。此外指出这些技术在存储、假设、模型效用、计算成本和处理动态数据方面的局限性。

2 机器遗忘技术分类
2.1 技术分类
2.1.1 精确遗忘
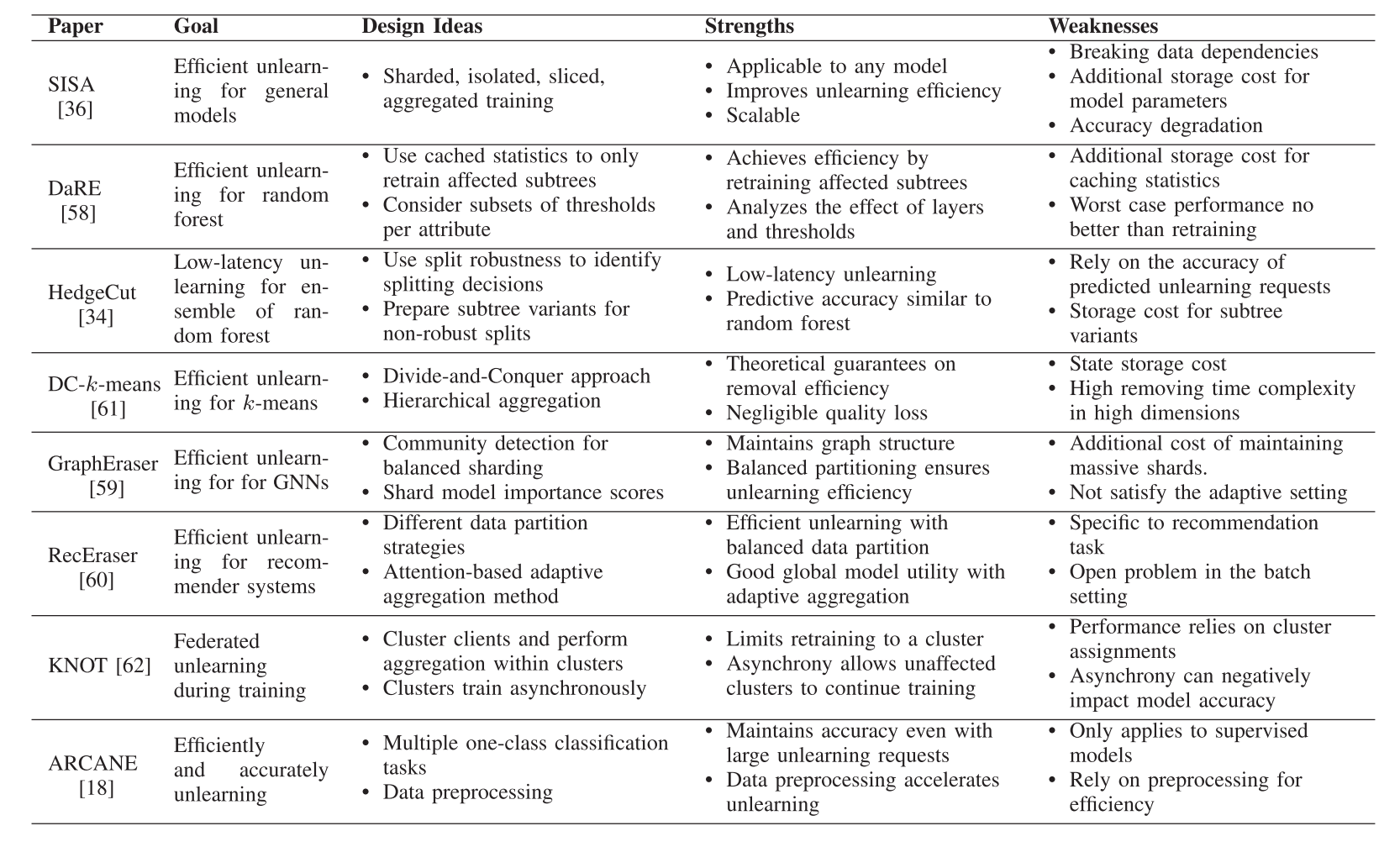
(1)基于SISA结构的精确遗忘
- 随机森林的精确遗忘:讨论了如何将SISA框架应用于随机森林模型,特别是DaRE森林和HedgeCut方法,它们通过不同的策略来提高遗忘效率和降低延迟。
- 基于图的模型的精确遗忘:由于图数据的相互连接特性,提出了GraphEraser和RecEraser方法,这些方法扩展了SISA框架以适应图数据结构。
- k-Means的精确遗忘:DC-k-means方法采用了类似SISA的框架,但使用了树状分层聚合方法。
- 联邦学习的精确遗忘:KNOT方法采用了SISA框架,实现了客户端级别的异步联邦遗忘学习。
(2)非SISA的精确遗忘
- 统计查询学习:Cao等人提出了一种中介层“求和”,通过更新求和来实现数据点的移除。
- 联邦学习的快速重训练:Liu等人提出了一种快速重训练方法,利用一阶泰勒近似技术和低代价的Hessian矩阵近似方法来减少计算和通信成本。
(3)精确遗忘方法的优缺点
- 附加存储成本:精确遗忘方法通常需要大量的额外存储空间来缓存模型参数、统计数据或中间结果。例如,SISA框架需要存储每个数据分片的模型参数,而HedgeCut需要存储子树变体。这限制了在大型模型或频繁遗忘请求中的可扩展性。
- 强假设:一些方法对学习算法或数据特性有强烈的假设。例如,SISA可能在处理高度依赖的数据时表现不佳,而统计查询学习要求算法能够以求和形式表达。特定于某些模型的方法,如DaRE、HedgeCut、GraphEraser和RecEraser,适用性有限。
- 模型效用:尽管大多数方法声称在遗忘后能够保持准确性,但缺乏在不同设置下的彻底分析。需要对不同模型、数据集和移除量进行严格的评估,以提供具体的效用保证。
- 计算成本:精确遗忘方法在初始训练期间增加了计算成本,因为需要训练多个子模型并进行聚合。当计算资源有限时,这可能不可行。
- 处理动态数据:现有方法主要集中在固定训练集上移除数据。处理动态变化的数据,以及持续的插入和移除请求,仍然是一个开放问题。
- 选择和实用性:尽管现有的精确遗忘方法能够高效准确地移除数据,但它们在存储、假设、效用维持和可扩展性方面存在局限性。选择最合适的方法取决于应用的具体要求,包括数据类型、模型类型、可用资源,以及效率和准确性之间的期望平衡。
2.1.2 近似遗忘
(1)基于移除数据的影响函数的近似遗忘
原理:这种方法通过计算被移除数据点对模型参数的影响,然后更新模型参数以减少这些数据点的影响。影响函数衡量了单个训练样本对模型预测的影响。
代表性算法:Guo等人提出的算法利用影响函数进行数据移除,并实现了L2正则化线性模型的认证移除。Sekhari等人的工作通过使用训练数据的统计信息来减少存储和计算需求。
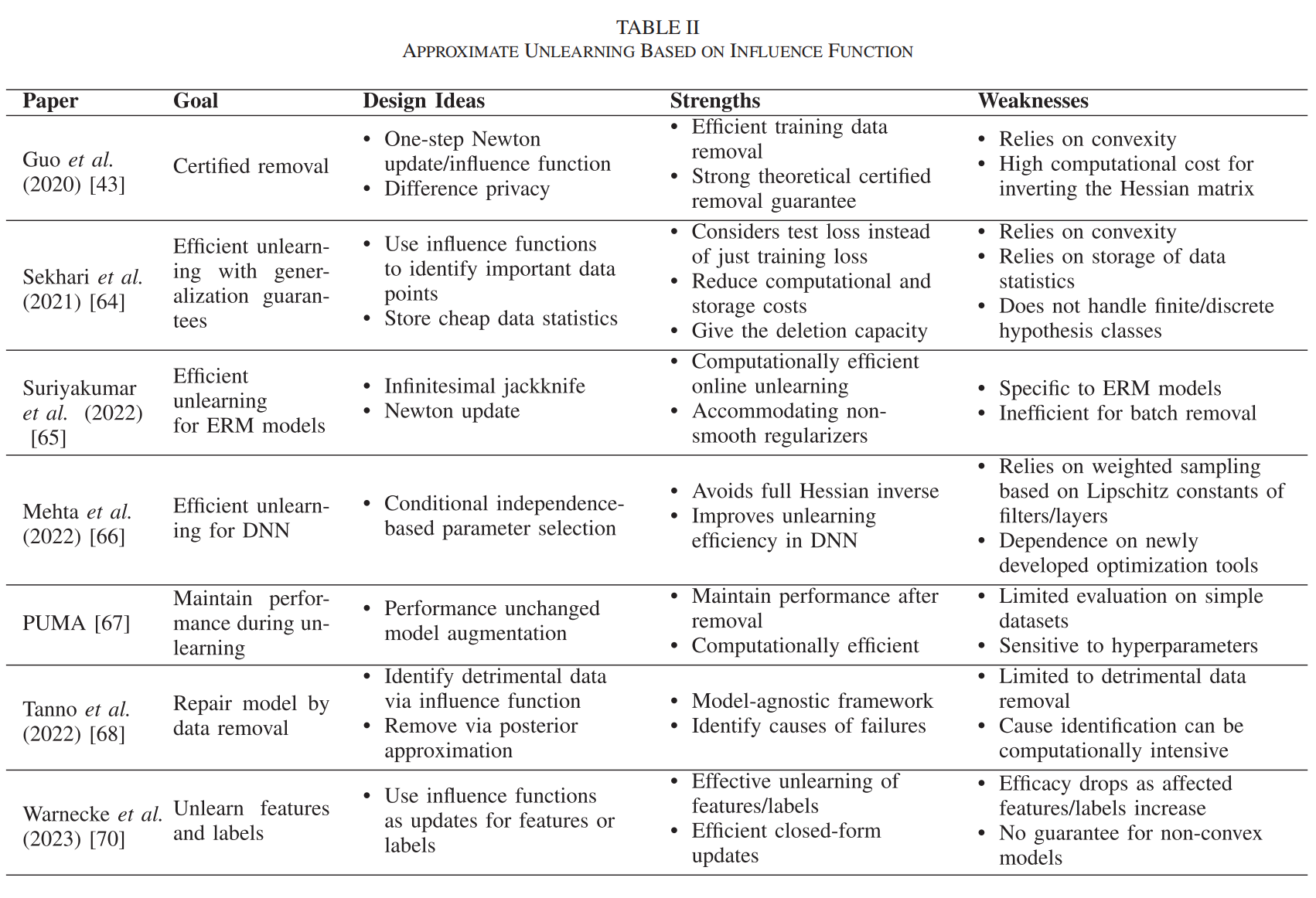
(2)基于移除数据后的重新优化的近似遗忘
原理:此方法首先在完整数据集上训练模型,然后定义一个新的损失函数以在保留的数据上维持准确性,并通过重新优化过程来最小化这个新的损失函数,从而实现对特定数据点的遗忘。
代表性算法:Golatkar等人提出的选择性遗忘算法通过修改网络权重,使得被遗忘数据的分布与从未训练过这些数据的网络权重分布不可区分。
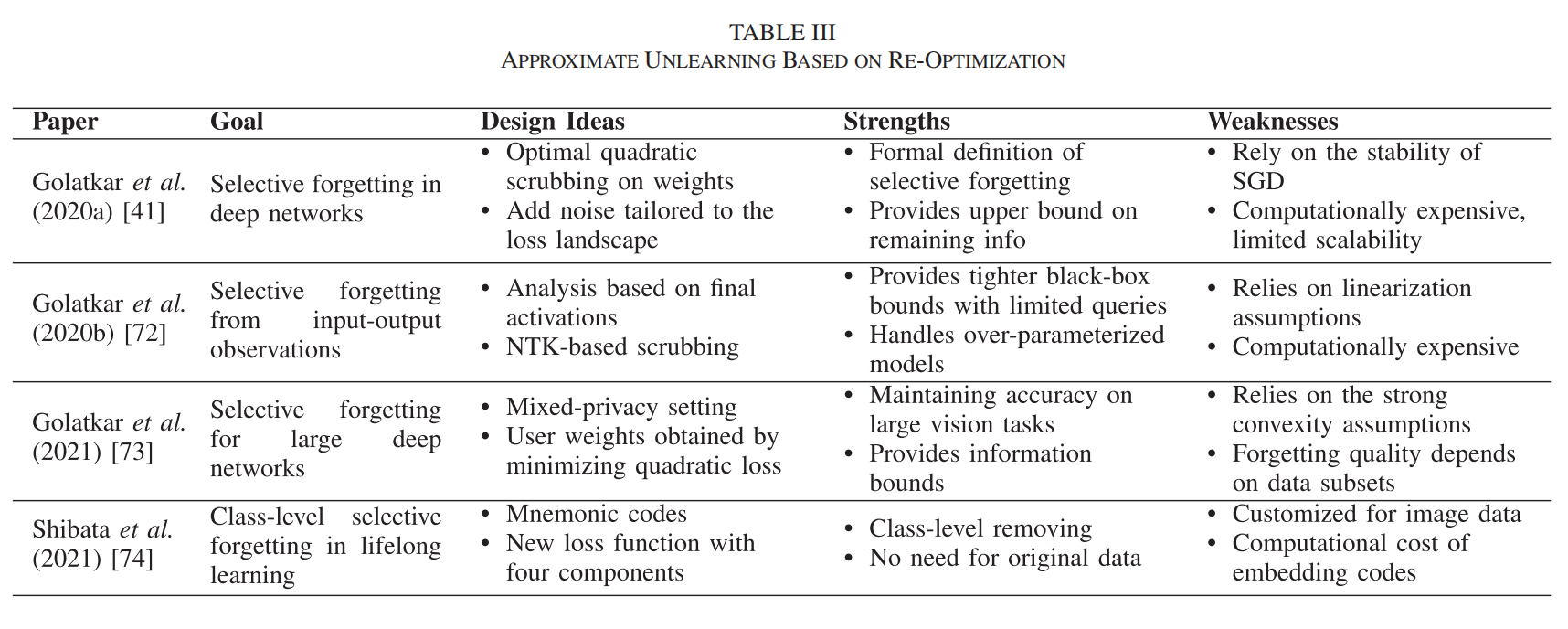
(3)基于梯度更新的近似遗忘
原理:在这种方法中,通过对新数据执行少量梯度更新步骤来适应模型参数的小变化,而无需完全重新训练模型。
代表性算法:DeltaGrad算法利用缓存的梯度和参数信息来快速适应小的训练集变化。FedRecover算法从被污染的模型中恢复准确的全局模型,同时最小化客户端的计算和通信成本。

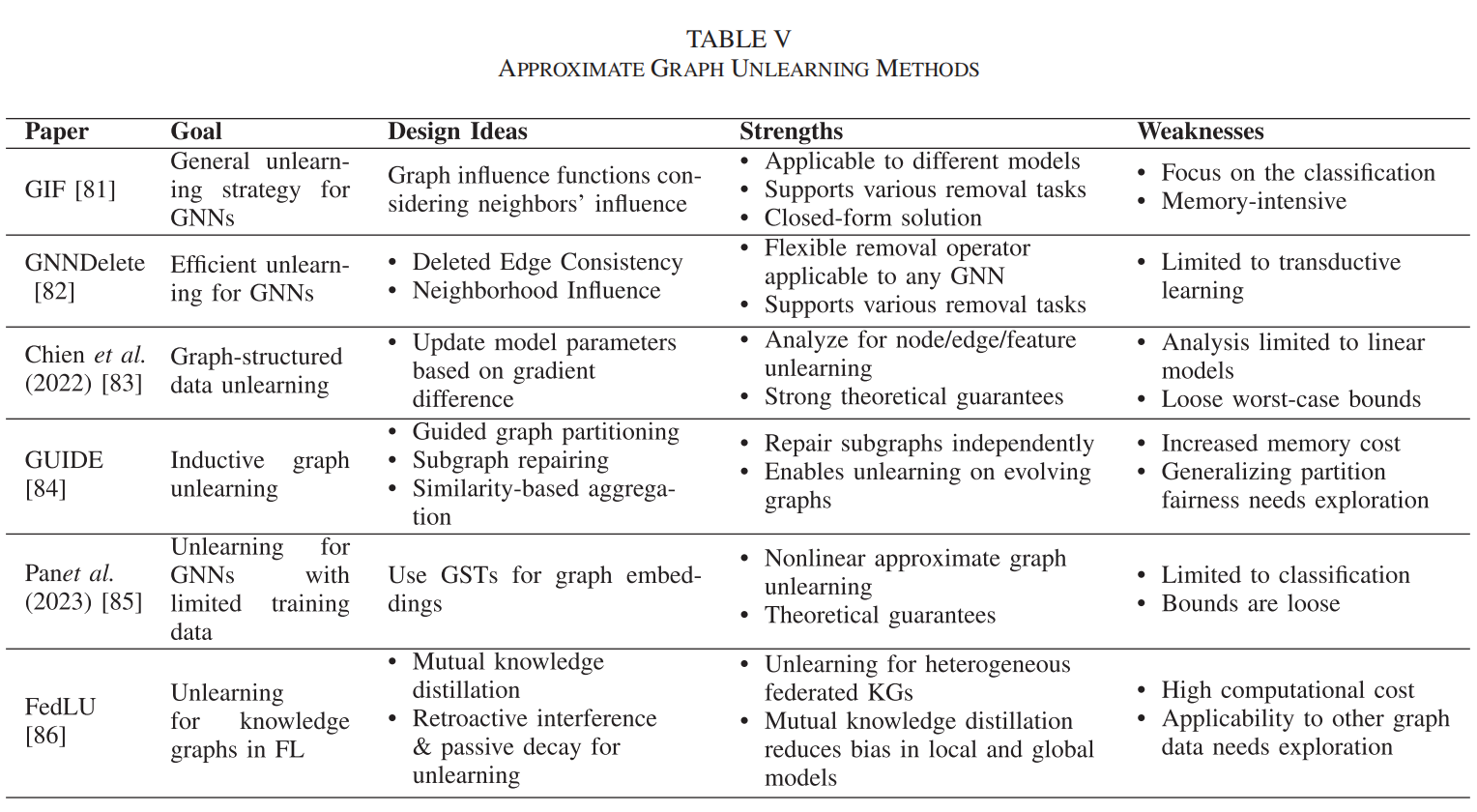
(4)特定于图数据的近似遗忘
原理:图数据由于其固有的依赖性,需要专门的方法来处理。这些方法考虑了图结构数据中节点和边的相互依赖性。
代表性算法:Wu等人提出的Graph Influence Function (GIF) 考虑了节点/边/特征对其邻居的结构影响。Cheng等人提出的GNNDELETE方法集成了一种新颖的删除操作符来处理图中边的删除影响。
(5)基于新颖技术的近似遗忘
原理:这种方法利用独特的模型架构或数据特性来开发新的近似遗忘技术。
代表性算法:Wang等人提出的模型剪枝方法在联邦学习中选择性地移除CNN分类模型中的类别。Izzo等人提出的Projective Residual Update (PRU) 用于从线性回归模型中移除数据。ERM-KTP是一种可解释的知识级机器遗忘方法,通过在训练期间使用减少纠缠的掩码(ERM)来分离和隔离特定类别的知识。
2.2 威胁、攻击、防御
(1)威胁(Threats):指的是危害机器遗忘系统的安全和隐私的潜在风险。这些威胁源自系统内部的脆弱性或外部的恶意行为。威胁包括信息泄露(Information Leakage)和恶意遗忘(Malicious Unlearning)。
- 信息泄露(Information Leakage):未遗忘模型和遗忘模型之间的差异被用来推断敏感信息。
- 模型差异导致的泄露(Leakage from Model Discrepancy): 这种方式的信息泄露来自于训练模型和被遗忘模型之间的差异。攻击者可以利用这些差异来获取关于被遗忘数据的额外信息。具体手段可能包括:
- 成员资格推断攻击(Membership Inference Attacks):攻击者尝试确定特定的数据点是否属于被遗忘的数据,通过分析模型对数据点的响应差异。
- 数据重建攻击(Data Reconstruction Attacks):攻击者尝试根据模型的输出重建被遗忘的数据点。
- 恶意请求(Malicious Requests):恶意用户提交请求以破坏模型的安全性或性能。
- 知识依赖性导致的泄露(Leakage from Knowledge Dependency): 这种方式的信息泄露来自于模型与外部知识源之间的自然关系。这可能包括:
- 自适应请求(Adaptive Requests):连续的遗忘请求可能揭示关于其他数据点的信息,攻击者可以通过一系列请求来收集足够的知识,以确定特定数据的成员资格。
- 缓存的计算(Cached Computations):遗忘算法可能缓存部分计算以加快处理速度,这可能无意中泄露了跨多个版本中本应被删除的数据的信息。
- 模型差异导致的泄露(Leakage from Model Discrepancy): 这种方式的信息泄露来自于训练模型和被遗忘模型之间的差异。攻击者可以利用这些差异来获取关于被遗忘数据的额外信息。具体手段可能包括:
- 恶意遗忘(Malicious Unlearning)
- 直接遗忘攻击(Direct Unlearning Attacks): 这类攻击仅在遗忘阶段发生,不需要在训练阶段操纵训练数据。攻击者可能利用模型的推断服务来获取关于训练模型的知识,并使用对抗性扰动等方法来制定恶意遗忘请求。直接遗忘攻击可以是无目标的,旨在降低模型在遗忘后的整体性能,也可以是有目标的,目的是使遗忘模型对具有预定义特征的目标输入进行错误分类。
- 预条件遗忘攻击(Preconditioned Unlearning Attacks): 与直接遗忘攻击不同,预条件遗忘攻击采取更策略性的方法,在训练阶段操纵训练数据。这些攻击通常设计为执行更复杂和隐蔽的有目标攻击。预条件遗忘攻击通常通过以下步骤执行:
- 攻击者在干净数据集中插入有毒数据(Poisoned Data)和缓解数据(Mitigation Data),形成一个训练数据集。
- 服务器基于这个数据集训练机器学习模型并返回模型。
- 攻击者提交请求以遗忘缓解数据。
- 服务器执行遗忘过程并返回一个遗忘模型,该模型实际上对应于仅在有毒数据和干净数据上训练的模型。通过这种方式,遗忘过程中移除缓解数据后,模型就会对训练阶段插入的有毒数据变得脆弱。
- 其他漏洞(Other Vulnerabilities)
- “减速攻击”:一种旨在减慢遗忘过程的投毒攻击,通过策略性地在训练数据中制作有毒数据,最小化通过近似更新处理的遗忘请求的间隔或数量。
- 公平性影响:讨论了遗忘算法本身可能在特定领域应用中引入的副作用,例如在大型语言模型中影响公平性。
(2)攻击(Attacks):基于上述威胁,攻击者执行的具体行动。这些攻击发生在机器遗忘的任何阶段,包括:
- 训练阶段攻击(Training Phase Attacks):如数据投毒,攻击者在训练数据中注入恶意数据。
- 遗忘阶段攻击(Unlearning Phase Attacks):如提交设计精巧的请求以移除对模型性能至关重要的数据点。
- 后遗忘阶段攻击(Post-Unlearning Phase Attacks):利用对模型的双重访问来提取额外信息或发起更复杂的攻击。
(3)防御(Defenses):为了保护机器遗忘系统免受威胁和攻击,研究者和实践者开发了多种防御机制。这些防御包括:
- 预遗忘阶段(Pre-unlearning Stage):在遗忘过程开始之前检测恶意请求或制定遗忘规则。
- 遗忘阶段(In-unlearning Stage):监控模型变化,如果检测到异常则停止遗忘过程。
- 后遗忘阶段(Post-unlearning Stage):保护遗忘后模型的信息泄露,或恢复模型到攻击前的状态。
2.3 通过攻击手段来评估机器遗忘系统的有效性
(1)隐私泄露审计(Audit of Privacy Leakage)
- 目的:评估机器遗忘系统在遗忘过程中可能产生的隐私泄露。
- 方法:使用攻击手段,如推断攻击,来检测训练模型和遗忘模型之间的差异,或利用系统内部的漏洞来提取信息。
- 指标:采用诸如区域下曲线(AUC)和攻击成功率(ASR)等指标来量化隐私攻击的有效性,从而指示隐私泄露的程度。
(2)模型鲁棒性评估(Assessment of Model Robustness)
- 目的:通过恶意遗忘评估遗忘模型的鲁棒性,类似于对抗性攻击中使用的原则。
- 方法:提交被扰动的数据点进行遗忘,以改变分类器的决策边界,从而评估模型对边界附近数据点的敏感性和对挑战模型预测能力的点的影响。
- 技术:例如,在大型语言模型(LLMs)中,攻击者可能插入对抗性嵌入到提示的嵌入中,以提取模型中本应被遗忘的知识。
(3)遗忘证明(Proof of Unlearning)
- 目的:使用攻击手段来证明遗忘过程的有效性,即验证数据是否已被有效地从模型中移除。
- 方法:如果遗忘后的数据在模型中没有显示出成员资格,或者遗忘数据中的后门无法被检测到,则可以认为遗忘数据已以高概率从模型中有效移除。
- 应用:研究中使用了标准的推断攻击和后门攻击的变体,或其他对抗性攻击来检测遗忘程序的不足。
2.4 验证指标和评价指标
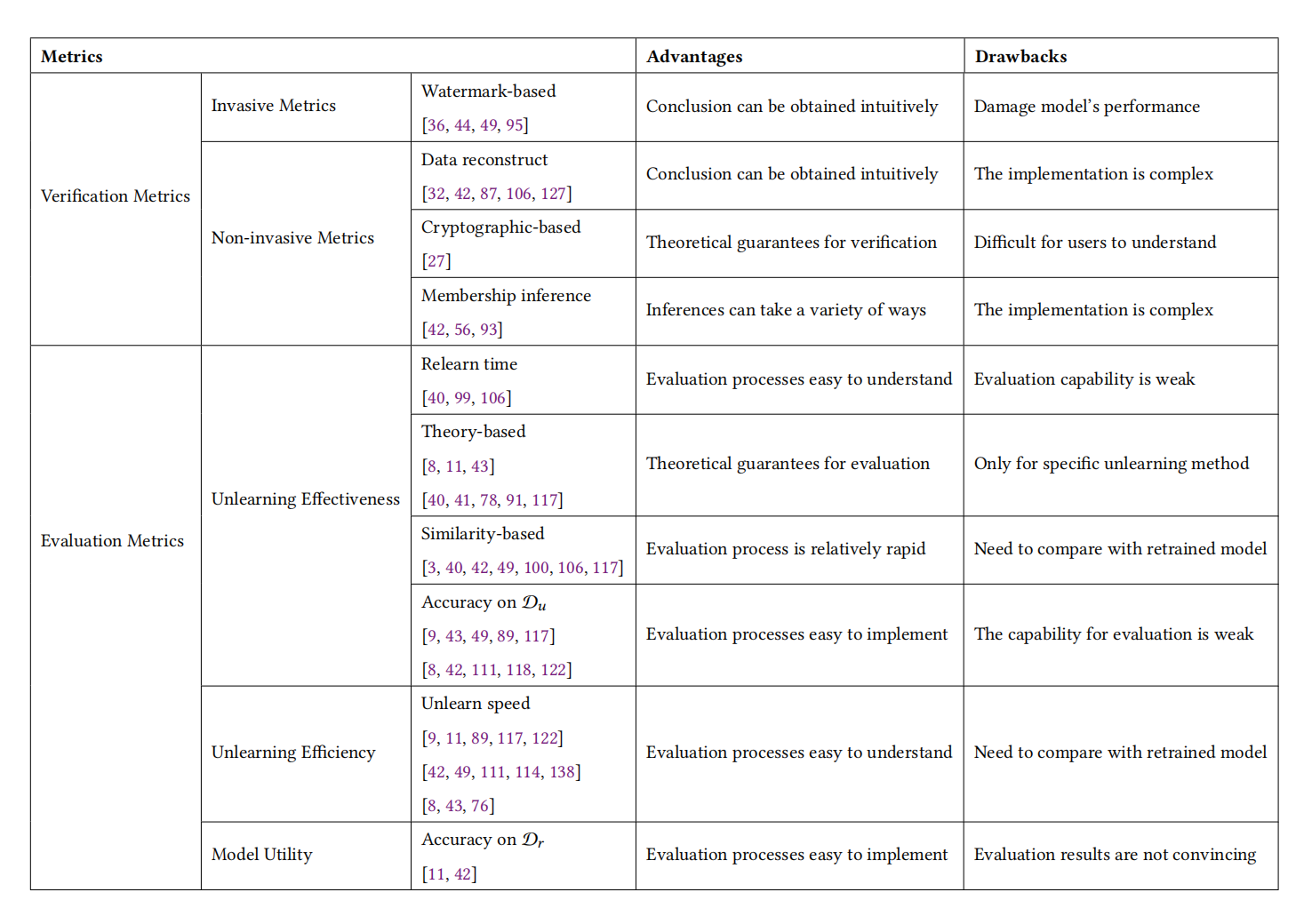
(1)验证指标(Verification Metrics)
验证指标主要用于数据提供者来验证模型提供者声称的遗忘效果是否真实。
- 侵入性指标(Invasive Metrics):
- 基于水印的指标:通过在数据或模型参数中嵌入水印(如后门触发器或特定二进制字符串),然后在遗忘后验证这些水印是否仍被模型所记忆。
- 非侵入性指标(Non-invasive Metrics):
- 成员资格推断指标:确定给定数据样本是否存在于训练数据集中,以验证模型是否仍包含有关被遗忘数据的信息。
- 数据重构指标:基于模型输出或参数,尝试重构训练数据信息,以验证遗忘数据是否仍被模型保留。
- 基于密码学的指标:使用密码学方法提供遗忘过程的证明,如使用简洁的非交互式知识论证。
(2)评价指标(Evaluation Metrics)
评价指标帮助模型提供者评估其遗忘算法的有效性、效用和效率。
- 有效性指标(Effectiveness Metrics):
- 重学时间指标:测量遗忘后的模型重新获得与原始模型相同精度所需的训练周期数。
- 基于相似度的指标:通过测量遗忘模型与重新训练模型之间的激活、权重或分布距离来评估遗忘效果。
- 理论基础的指标:基于特定遗忘方法设计的指标,如基于重学的指标和基于认证的指标。
- 效率指标(Efficiency Metrics):
- 遗忘速度指标:评估遗忘过程的效率,测量遗忘操作与从头开始训练相比所需的时间差异。
- 效用指标(Utility Metrics):
- 在被遗忘数据集上的精度:评估遗忘操作对模型在剩余数据集上预测准确性的影响,确保遗忘后的模型仍然可用。
(3)其他相关指标
- 遗忘率(Forgetting Rate):通过测量成员资格推断的精度变化来直观地衡量遗忘成功率。
- 记忆掩蔽(Neuron Masking):通过掩盖神经网络中的特定神经元来实现对特定数据的遗忘。
3 参考文献
-
Xu J, Wu Z, Wang C, et al. Machine unlearning: Solutions and challenges[J]. IEEE Transactions on Emerging Topics in Computational Intelligence, 2024. 【引用量 12】
-
Liu Z, Ye H, Chen C, et al. Threats, attacks, and defenses in machine unlearning: A survey[J]. arXiv preprint arXiv:2403.13682, 2024. 【引用量 3】
-
Li N, Zhou C, Gao Y, et al. Machine Unlearning: Taxonomy, Metrics, Applications, Challenges, and Prospects[J]. arXiv preprint arXiv:2403.08254, 2024. 【引用量 3】
-
Wang W, Tian Z, Yu S. Machine Unlearning: A Comprehensive Survey[J]. arXiv preprint arXiv:2405.07406, 2024.【引用量 0】