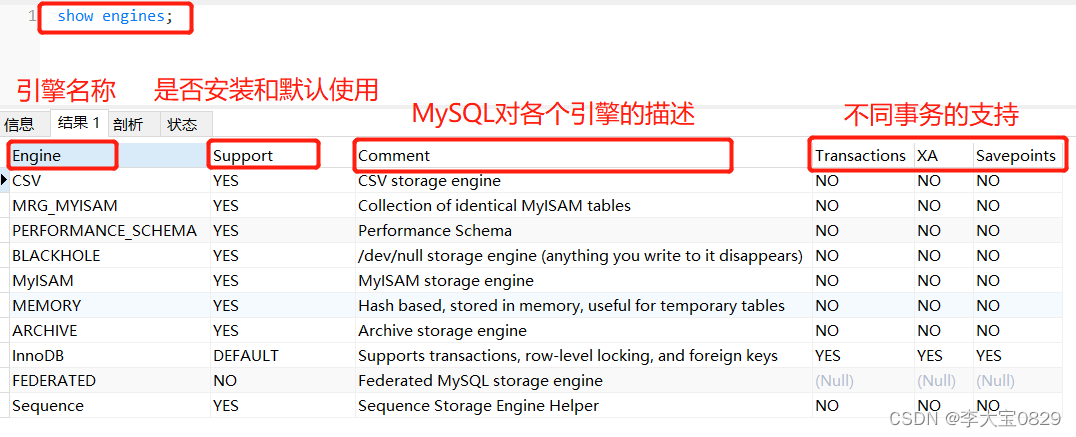
第四章.神经网络
4.2 线性神经网络与Delta学习规则
线性神经网络在结构上与感知器非常相似,只是激活函数不同。在模型训练时把原来的sign函数改成purelin函数:y = x
1.激活函数
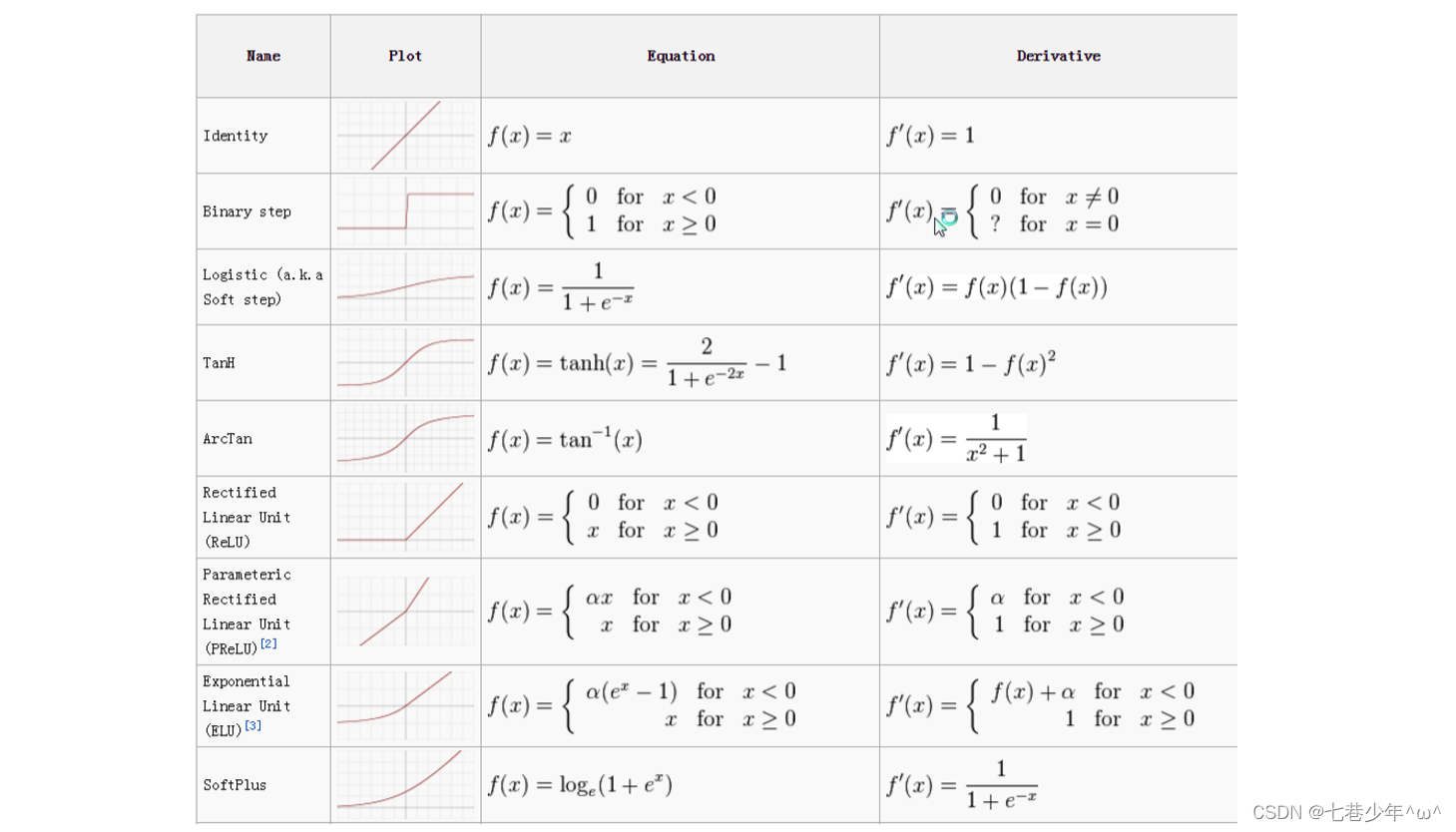
2.线性神经网络示例
1).题目:
- 假设平面坐标系上有四个点,(3,3),(4,3)这两个点是标签1,(1,1),(0,2)这两个点的标签为-1,构建神经网络来分类。
2).思路:
-
我们要分类的数据是一个二维数据,我们只需要两个输入节点,我们可以把神经元的偏置值也设置为一个输入节点,这样我们就有3个输入节点。
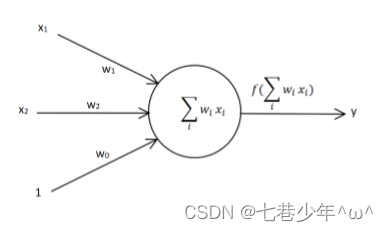
-
输入数据有4个(1,3,3),(1,4,3),(1,1,1),(1,0,2),对应的标签为(1,1,-1,-1),初始化权值为w0,w1,w2取-1到1之间的随机数,学习率η设置为0.11,激活函数为purelin函数
-
斜率(k)和截距(b)的公式推导:
①.数据的输入:Xi=[1,xi ,yi ],对应的权重W=[w0 ,w1 ,w2 ]; 求∑ XiWi=0;
②.即求:w0 +xiw1 +yiw2 = 0
③.所以:yiw2 = -w0 -xiw1
④.即:yi= -(w0/w2)-(w1/w2)xi
⑤.斜率k=-(w1/w2)
⑥.截距b=-(w0/w2)
3).代码:
import numpy as np
import matplotlib.pyplot as plt
# 输入数据
X = np.array([[1, 3, 3], [1, 4, 3], [1, 1, 1], [1, 0, 2]])
# 标签
Y = np.array([[1], [1], [-1], [-1]])
# 随机初始化权重,范围[-1,1]
W = (np.random.random([3, 1]) - 0.5) * 2
# 神经网络输出
Output = 0
# 学习率
lr = 0.11
# 更新权重的函数
def update():
global X, Y, W, lr
Output = np.dot(X, W) # purelin函数:y=x
Wi = lr * (X.T.dot(Y - Output)) / int(X.shape[0])
W = W + Wi
# 循环次数
epochs = 100
for i in range(epochs):
update()
# 正样本
x1 = [3, 4]
y1 = [3, 3]
# 负样本
x2 = [1, 0]
y2 = [1, 2]
# 斜率和截距
k = -W[1] / W[2]
b = -W[0] / W[2]
print('k=', k)
print('b=', b)
x_data = [-2, 3]
y_data = k * x_data + b
# 画图
plt.figure()
plt.scatter(x1, y1, c='b', marker='o')
plt.scatter(x2, y2, c='y', marker='x')
plt.plot(x_data, y_data, 'r')
plt.show()
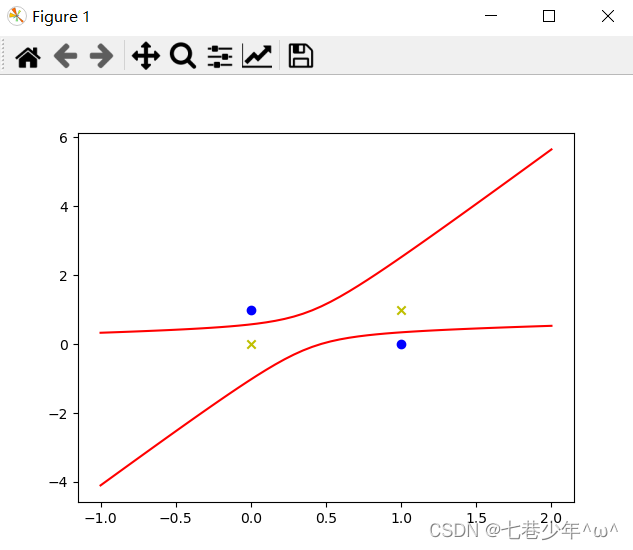
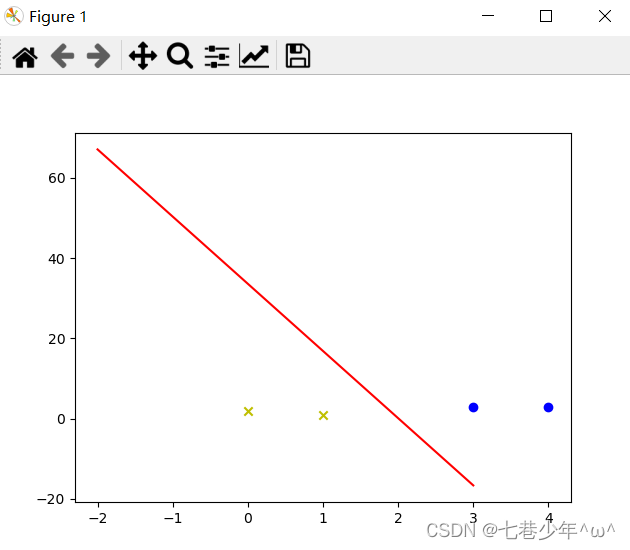
4).结果展示:
3.Delta学习规则
Delta(δ)学习规则是一种利用梯度下降法一般性的学习规则
1).二次代价函数:
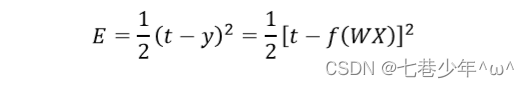
- 误差E是权向量W的函数,我们可以使用梯度下降法来最小化E的值.
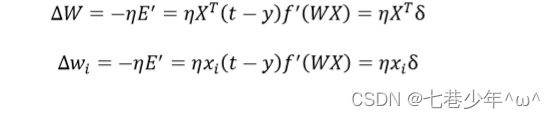
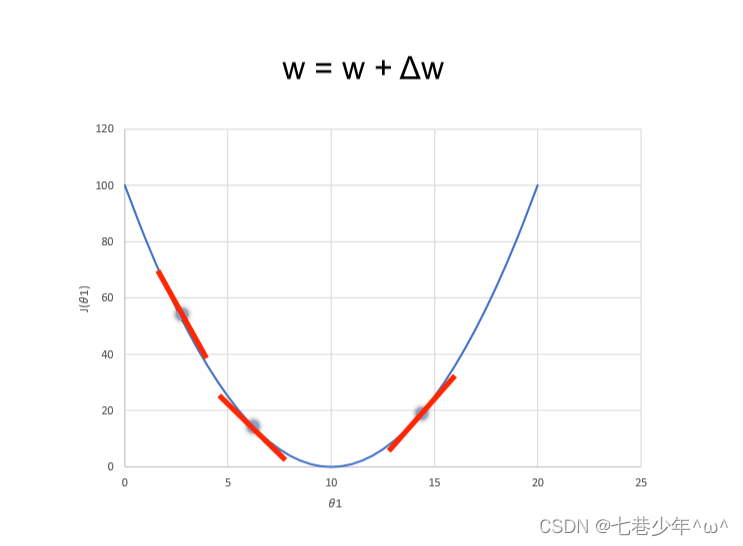
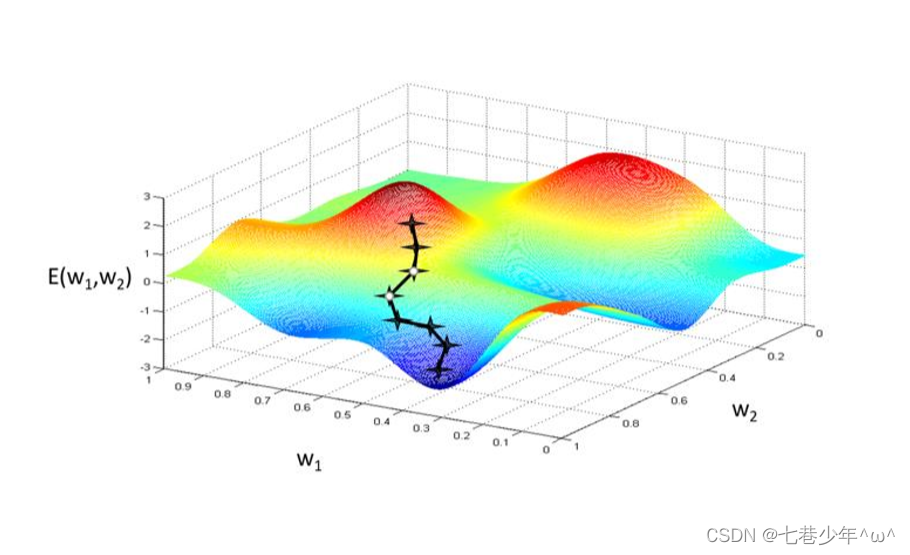
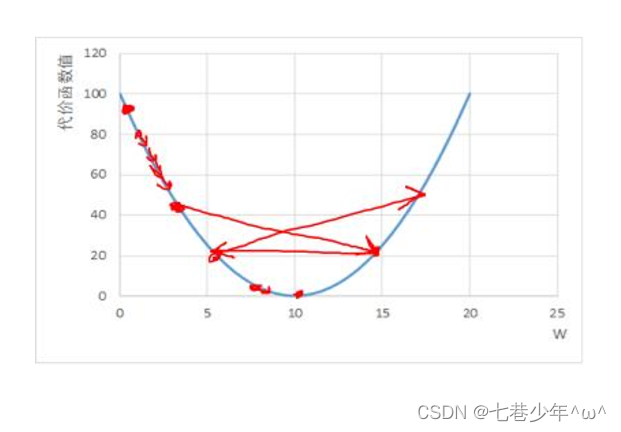
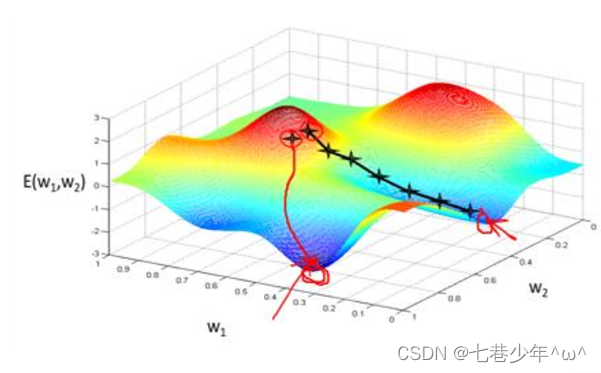
2).不同维度下梯度下降法示意图:
-
一维情况
-
二维情况:
3).梯度下降法的问题:
-
学习率(η)难以选取,太大会产生震荡,太小收敛缓慢
-
容易存在局部极小值的问题
4.解决异或问题的两种方式
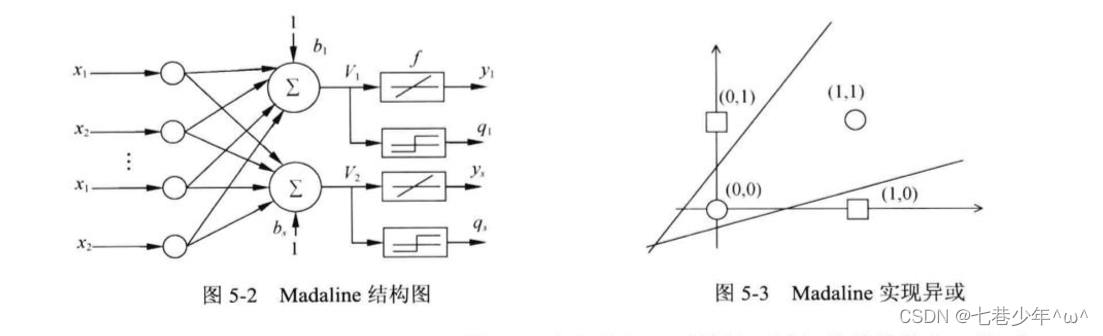
1).Madaline可以用一种间接的方式解决线性不可分的问题
- 方法:用多个线性函数对区域进行划分,然后对各个神经元的输出做逻辑运算,如图5-3所示,Madaline用两条直线实现了异或逻辑
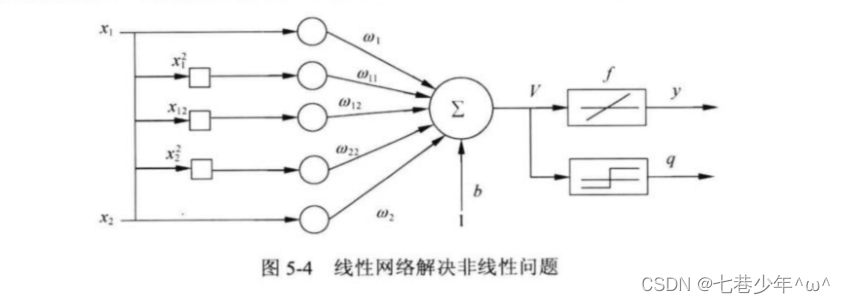
2).线性神经网络解决线性不可分问题:
- 方法:对神经元添加非线性输入,从而引入非线性成分,这样做会使等效的输入维度变大,如图5-4所示:
5.线性神经网络示例-异或问题(第二种方式解决异或问题示例)
1).简易图:
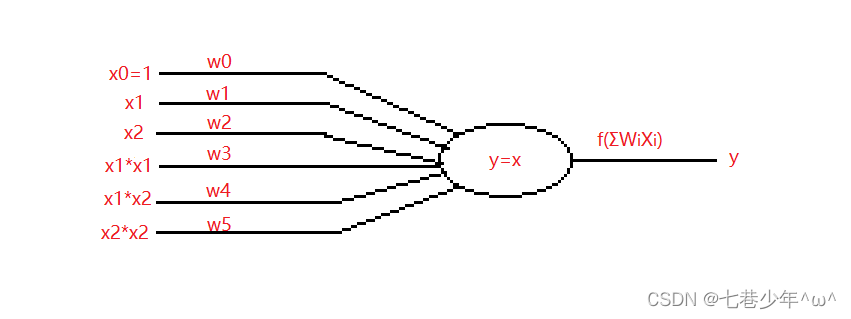
2).斜率(k)和截距(b)的公式推导:
①.数据的输入:Xi=[1,xi ,yi ,…],对应的权重W=[w0 ,w1 ,w2 ,…]; 求∑ XiWi=0;
②.即求:x0w0 +x1w1 +x2w2 +x12w3 +x1x2w4 +x22w5 = 0
③.所以:w0 +xw1 +yw2 +x2w3 +xyw4 +y2w5 = 0
④.所以:y2w5 +y(w2 +xw4)+w0+xw1+x2w3 = 0
⑤.求根公式为:y=(-b±√b2-4ac)/2a
⑥.a=w5
⑦.b=w2+xw4
⑧.c=w0+xw1+x2w3
3).代码:
import numpy as np
import matplotlib.pyplot as plt
# 输入数据
X = np.array([[1, 0, 0, 0, 0, 0], [1, 0, 1, 0, 0, 1], [1, 1, 0, 1, 0, 0], [1, 1, 1, 1, 1, 1]])
# 标签
Y = np.array([-1, 1, 1, -1])
# 随机初始化权重
W = (np.random.random(6) - 0.5) * 2
print(W)
# 神经网络输出
Output = 0
Output = 1
# 学习率
lr = 0.11
# 更新权重函数
def update():
global X, Y, W, lr, n
Output = np.dot(X, W) # purelin:y=x
Wi = lr * (X.T.dot(Y - Output)) / int(X.shape[0])
W = W + Wi
# 循环次数
epochs = 100
for i in range(epochs):
update()
Output = np.dot(X, W.T)
print(Output)
# 正样本
x1 = [0, 1]
y1 = [1, 0]
# 负样本
x2 = [0, 1]
y2 = [0, 1]
def calculate(x, root):
a = W[5]
b = W[2] + x * W[4]
c = W[0] + x * W[1] + x * x * W[3]
if root == 1:
return (-b + np.sqrt(b * b - 4 * a * c)) / (2 * a)
if root == 2:
return (-b - np.sqrt(b * b - 4 * a * c)) / (2 * a)
x_data = np.linspace(-1, 2)
y_data1 = calculate(x_data, 1)
y_data2 = calculate(x_data, 2)
# 画图
plt.figure()
plt.scatter(x1, y1, c='b', marker='o')
plt.scatter(x2, y2, c='y', marker='x')
plt.plot(x_data, y_data1, 'r')
plt.plot(x_data, y_data2, 'r')
plt.show()
4).结果展示: