背景
无论是前端代码还是后端代码,都存在着定位困难,不好抽离,改造困难的问题,造成代码开发越来越慢,此外因为代码耦合较高,总是出现改了一处地方,然后影响其他地方,要么就是要修改一个逻辑,结果耗费了大量时间进行改造,代码写得耦合较高,造成这种情况的原因无非就是程序员本身没有管理者的思维,喜欢取巧,合并,凑数,偷懒造成的,说白了,想比做的少,更多的是先动手去干,而不是先想好过去/现在/未来三种情况再干,这样撸着撸着,就会将代码撸得让自己越来越反感,越枯燥!
新语法,高阶语法无心尝试,这些东西并非为了装逼用,大佬创造他们并设为标准,就是为了解决代码可能存在的问题。
问题一:顺向思维
需求交接后,并不对旧逻辑 + 新逻辑进行整合过滤,而忙于添加一个 if...elseif 就着手开发了,一个例子就是智能养号,拿到需求后,快速得出 3 个按钮的组合是 4 种可能,实际上整体思考后,会发现其中 团队开关开启和互养池开关开启 只走互养池逻辑,也即 3 个逻辑。
以下是伪代码,主要讲述主逻辑展示的必要性,子逻辑仍然要遵循一条线法继续拆分函数,直到最小颗粒度的函数体,才去实现,而函数体不应该超过 100 行,否则很有必要继续拆分
@router.post('/target-wid')
async def get_target_wid(
user_id: int = Depends(get_user_id),
company_id: int = Depends(get_company_id),
item: TargetWhatsappIdGetParam = Body()
):
'''
第一层代码纯主逻辑 绝无细节 未来还可能有更多主逻辑
而未来追加新逻辑链路只是再加一行代码而已
第一层逻辑绝无 elsif 因为要一条线到底
'''
if huyang.switch:
return huyang.match_numbers()
if team_huyang.switch:
return team_huyang.match_numbers()
return selfyang.match_numbers()问题二:不封装函数
无论是前端还是后端,现在都已经有了面向对象的概念,尤其是 ES6 的存在,相同逻辑的东西可以封装成函数,但是目前前端的代码封装密集度不够。仍然是面向过程的开发。
问题三:面向对象
python 本身已支持面向对象,而后端程序员都是科班出身,同时又都学过 java,但是代码写得不尽人意,仍然是赤裸裸地面向过程,更别提面向切面了,连个装饰器都没有尝试写过,真的不需要吗?还是懒得去总结代码,划分出来这些东西?
model 是什么?
model 是编程语言映射数据库字段的中转对象,将 mysql 二进制字符对应转化为编程语言的类型,每条记录对应一个 model
-
model 是编程语言对象,是对象除了属性还是有行为,行为就是静态函数或者成员函数
-
静态函数往往处理本表的一些转换性操作,例如创建对象时的前置数据处理,保存对象前的前置处理,获取对象后的后置处理,都是静态成员函数的工作,不针对于某个对象,而是针对于所有对象的面向切面的操作
-
成员函数,往往是对于从数据库查询了特定记录,针对这一条记录进行数据的处理,处理完成后返回某值,或者入库
-
以上两个操作都是 model 的操作范畴
-
service 是什么?
service 是针对功能模块下的一堆逻辑的操作集合,它含有各种函数,又可以将各种函数进行组合再构成新函数,主要的目的就是将逻辑进行最大化的封装,不暴露细节,而细节都在私有函数里
举个例子我想下单,那么就有 OrderService,OrderService 对外提供一个 public 函数,createOrder(orderInfo, userId),那么 OrderService.createOrder(orderInfo, userId),创建完订单后还要干什么,那就是其他各种公共函数了,createOrder 函数里面例如提取可用优惠券,drawCanUseCoupons(userId),这个就是私有函数,提取后还得计算优惠券的匹配情况 getMatchCoupons(orderInfo, coupons)等等各类私有函数,这些私有函数在取消订单时也会用到,但是你单独使用 drawCanUseCoupons(userId),例如用户卡券包,这时你发现可以再抽出一个 UserService,将drawCanUseCoupons(userId)挪过去,因为这个跟订单信息无关,跟用户信息有关,这就是 Service
service 存在意义?
service 存在意义是将需求主逻辑变得特别简洁易懂,不暴露任何细节,如图:
这是一个巨复杂的创建订单的前置校验,如果我直接将 createOrder 暴露出来,这个代码得有 1000 行,但是为了要保持函数代码的体积,这里只将主逻辑呈现,细节继续细化
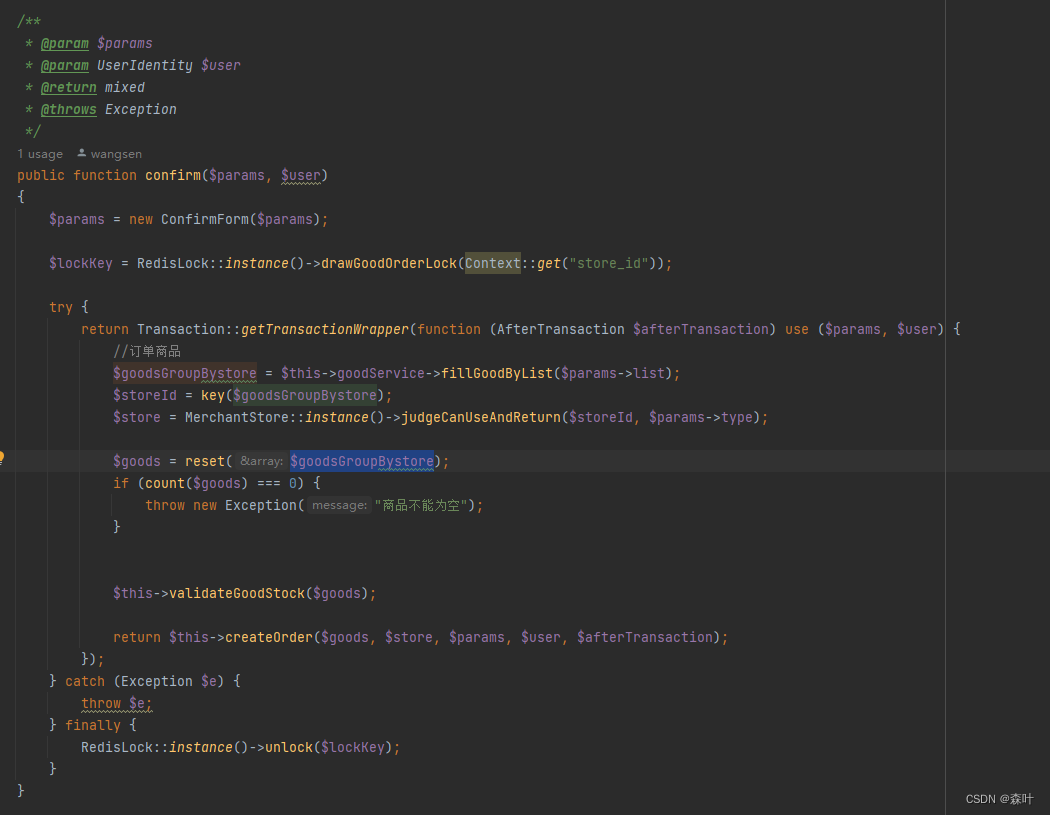
而 createOrder 主逻辑也仅仅 40 行代码
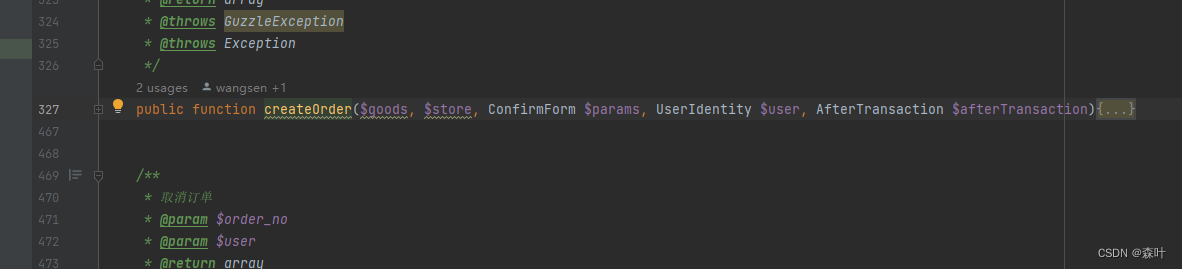
createOrder 主体逻辑也是由大量其他 model 和 service 逻辑函数组合而成
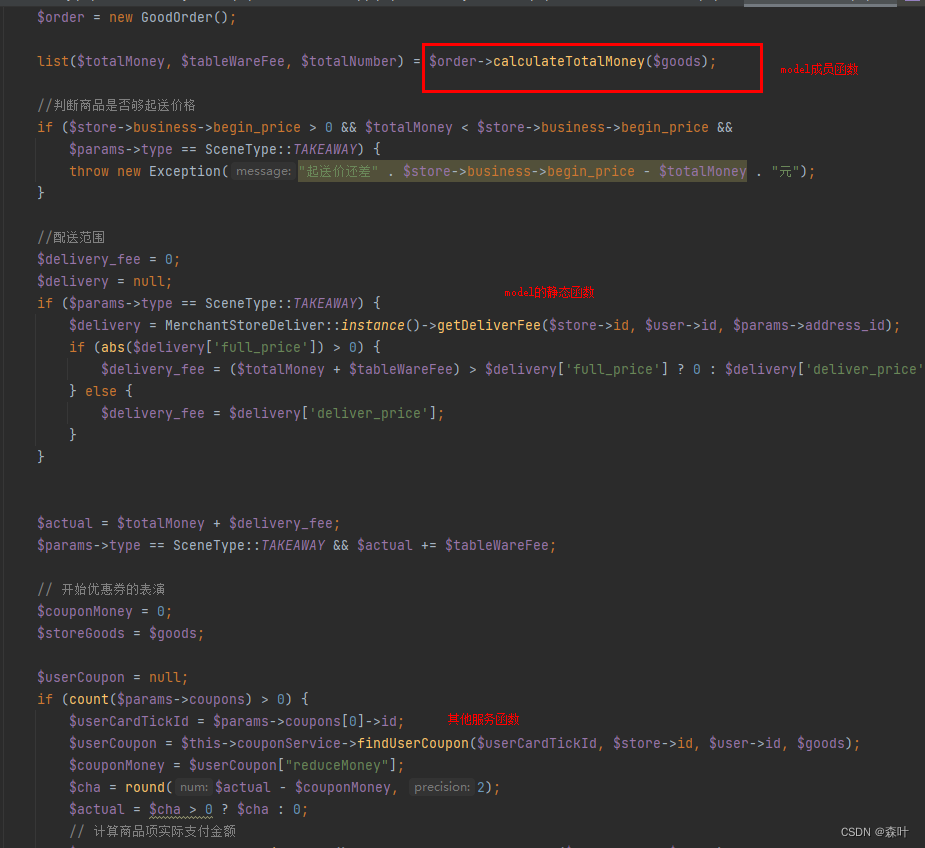
这样写的好处就是主逻辑结构一直很清晰,自己需要记忆的东西是分层的,每次进入一个函数,或者跳出一个函数,都不用带着巨大的上下文来思考,只需要集中在这个单元函数里,保证单元函数的正确性即可,整体逻辑组合在一起,是不可能出现大差错的。
问题三:重复函数的使用
程序员有个习惯,尤其是面向过程的习惯
看一个 python 代码,这里为了要承接上面代码最终结果的过滤,就用了大量的 if...else 以及嵌套的 if...else
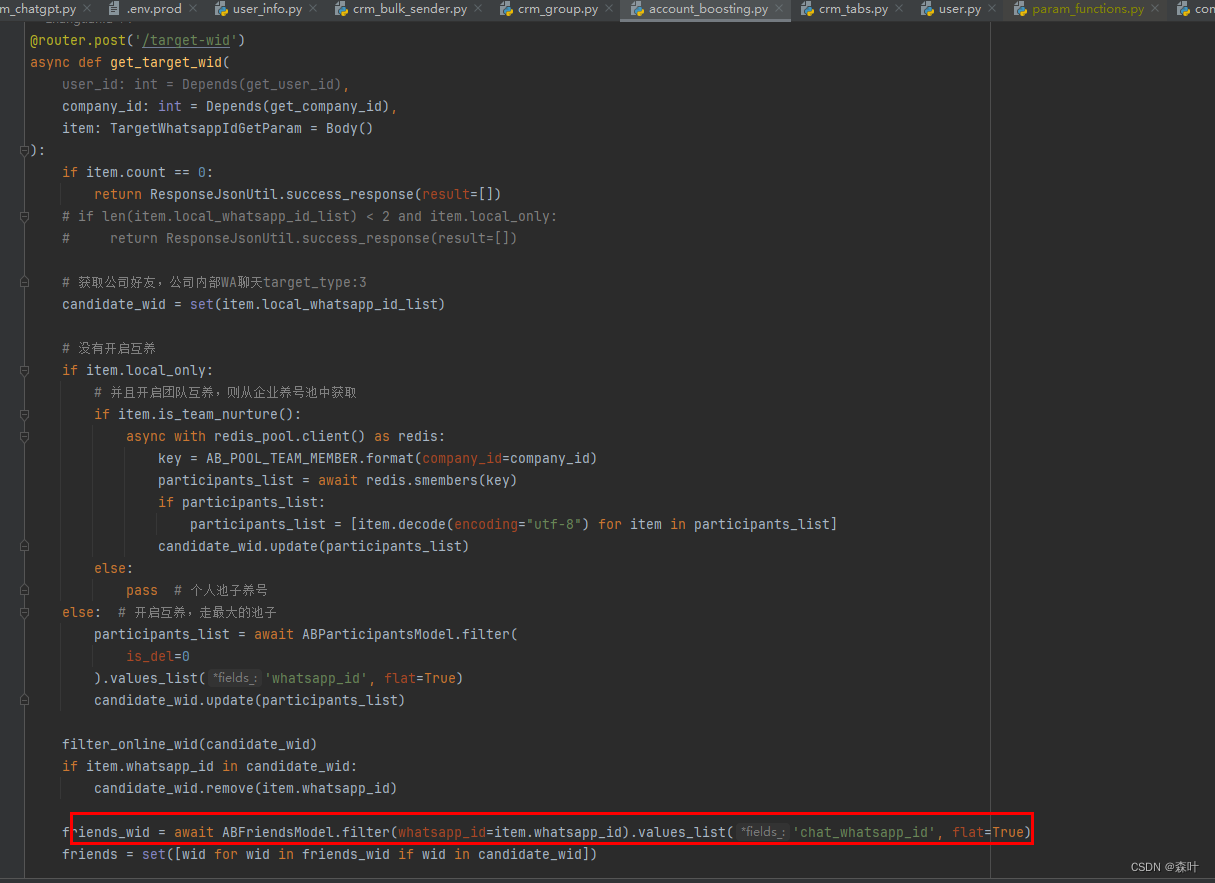
如果改造完了之后,应该就是 3 个主逻辑函数,分别调用 NurtureService.xxx1/2/3 三种逻辑,每个函数都是 return,针对 filter,再各自调用 NurtureService.filter(numbers),如果 filter 里面还需要 if...else 判断,则再将 filter 拆分为 filter1/2/3,也即将逻辑改为一顺而下,而非底层汇编语言的来回 jump,每个 while 和每个 if 都是一次 jump,jump 计算机会中断,人脑也会中断,阅读识别都不方便
而函数对于计算机来说,用完即焚,会快速清理内存,而上面这种面向过程的代码,就很难做到清理内存,if 过程中产生的变量都会存在内存里,直到这个函数运行完毕。
代码重复一定要封装,函数重复没问题,函数名在底层就是 16 进制,而且并不是重复存储,所以大胆地将函数重复调用,将代码逻辑实现完美解耦。
下面就是一个好例子

问题四:善用文件夹
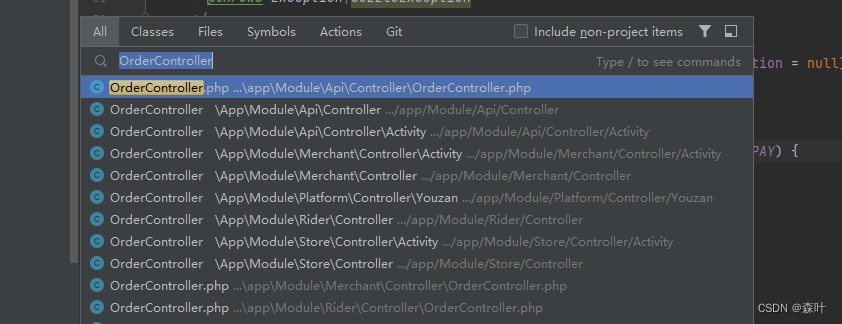
程序员养成了一个习惯,就是通过命名前缀来区分代码文件,加多了就造成命名冗长,同时单个文件夹下的代码文件巨多,看这里 OrderController,我都用一个命名,通过文件夹的方式进行区分,任何语言都有命名空间的概念,所以这样既能让代码命名简洁,不来回乱起,还能保持层次分明
问题五:控制反转和反射机制
我们的习惯是一个类的处理逻辑必须由自己实现,也即 order.createOrder,实际上我们可以将这种权力交出去,让其他对象来处理它,例如
OrderService.createOrder(order),如果前面的 OrderService 可以通过上面的那种命名空间的方式用反射机制,这种方式可以根据传入参数,这种方式可有效减少 if...else 的使用,但也造成了代码的不易读,最好用 Factory 工厂模式,通过传入参数,显式地调用具体的类,这样可读性就高了很多,代码可维护性也提高了很多,而且每个逻辑都是隔离的,改动起来不会对其他逻辑产生任何影响
class_name = "api.OrderService"
my_class = globals()[class_name]
# 创建对象实例
instance = my_class()
# 调用对象的方法
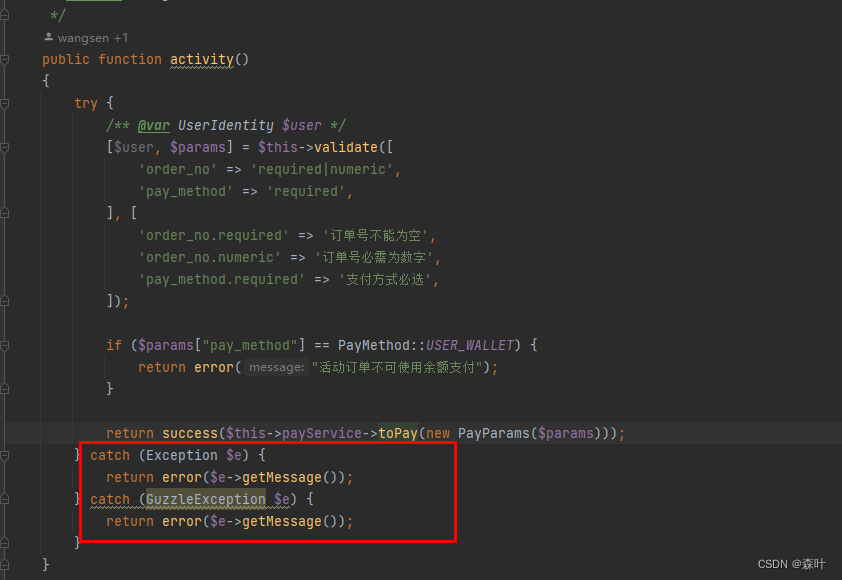
print(instance.createOrder(order))问题六:很少对单函数进行异常预测和收集
如果上面 5 个问题都得到了很好的处理,那么剩下的就是异常的预测和收集,每个单元函数都会出现异常,go 语言就很好,返回值总是,result,err = xxxx(),其中 err 就是一个错误,错误产生后,可以通过人为判断是否向上抛出,或者自行消化,再或者 push 到一个错误收集器里
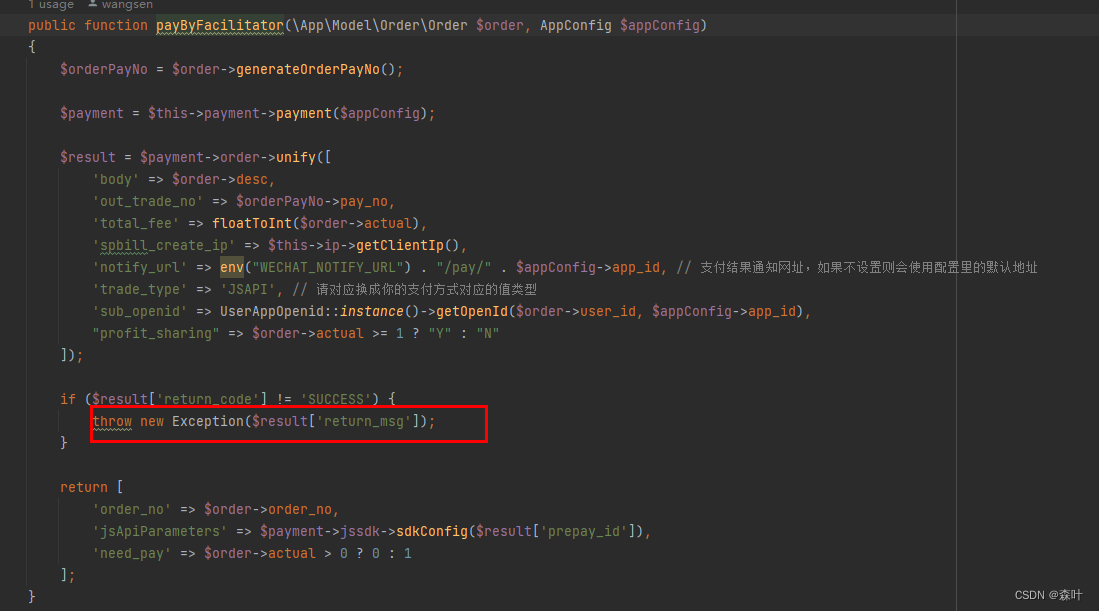
顶级函数外层都会进行错误捕获和处理,这里 PHP 做得比较粗糙了些