【因果推断】是研究如何从观测数据中识别和估计变量之间因果关系的领域。它在医学、经济学、环境科学等多个领域有着广泛的应用,帮助科学家和决策者理解复杂现象背后的因果机制。通过使用统计方法、机器学习技术以及逻辑推理,因果推断能够揭示变量间的潜在影响路径,从而为预测和干预提供依据。随着技术的发展,特别是在大数据和人工智能的推动下,因果推断的方法和应用正变得越来越精确和广泛,对提高决策质量和科学研究的深度具有重要意义。
为了帮助大家全面掌握【因果推断】的方法并寻找创新点,本文总结了最近两年【因果推断】相关的15篇前沿研究成果,这些论文的文章、来源、论文的代码都整理好了,希望能给各位的学术研究提供新的思路。
需要的同学扫码添加我
回复“因果推断15”即可全部领取

任意三篇论文解析
1、Causal Inference Using LLM-Guided Discovery
方法:
- 背景理解:论文首先指出因果推断的核心挑战是如何仅依赖观测数据确定可靠的因果图。传统的后门准则依赖于图的准确性,任何图的错误都可能影响推断结果。
- 因果顺序的重要性:作者提出,并非需要完整的因果图信息,仅图变量的拓扑顺序(因果顺序)就足以进行因果效应推断。
- 领域专家与LLMs:鉴于确定因果顺序比图边更容易从领域专家那里获得,作者探索了使用大型语言模型(如GPT-3.5和GPT-4)作为虚拟领域专家来自动获取因果顺序。
- 提示策略:论文提出了基于三元组的提示技术,让LLM同时考虑三个变量,并使用多数投票聚合这些三元组来产生因果顺序。在出现因果顺序的平局时,使用另一个LLM(例如GPT-4)来打破平局。
- 算法整合:作者提出了两种算法,分别基于约束和基于评分的因果发现算法,将LLM输出的因果顺序整合进现有的因果发现算法中,以提高性能。
创新点:
- 简化因果图的需求:论文提出了一种简化的方法,通过只使用因果顺序而非完整的因果图来进行因果效应推断,这降低了问题复杂度。
- 使用LLM作为领域专家:将大型语言模型应用于因果顺序的获取,这是一种新颖的方法,因为它利用了LLM在处理语言和模式识别方面的能力。
- 三元组提示技术:提出了一种新的提示策略,通过三元组而不是成对提示来提高因果顺序的准确性,并避免了预测顺序中的循环。
- 算法改进:通过将LLM输出与现有的因果发现算法结合,提出了改进的算法,这些算法在确定因果顺序方面表现优于单独使用的发现算法。
- 实验验证:通过在多个基准数据集上的广泛实验,证明了所提出方法的因果排序准确性显著提高,强调了LLM在跨领域增强因果推断中的潜力。
- 对现有算法的改进:展示了如何将LLM输出用于提高现有因果发现算法的准确性,特别是在样本量有限的情况下,这对于实际应用中的因果推断具有重要意义。

2、Continual Causal Inference with Incremental Observational Data
方法:
- 背景理解:论文讨论了在大数据时代,观测数据的日益增长为因果效应估计提供了便利,但现有方法主要关注特定来源和静态观测数据,这在工业应用中不现实。
- 问题定义:提出了一个新的问题,即如何从非静态数据分布中逐步可用的观测数据估计因果效应,并提出了三个新的评估标准:可扩展性、适应性和可访问性。
- CERL方法:提出了一种持续因果效应表示学习(Continual Causal Effect Representation Learning, CERL)方法,该方法通过仅存储从先前数据中学到的有限特征表示的子集,而不是所有观测数据,来实现对新数据的持续因果效应估计。
- 模型架构:CERL包含两个主要组件:基线因果效应学习模型和持续因果效应学习模型。基线模型用于初始数据集,而持续学习模型用于顺序可用的数据,处理知识转移、灾难性遗忘等问题。
- 特征表示学习:采用深度特征选择模型,通过弹性网正则化来学习选择性和平衡的特征表示。
- 特征表示蒸馏:鼓励基于基线模型的学习表示向量与基于新模型的学习表示向量相似,以防止在新特征表示空间中学习到的表示漂移过多。
- 特征表示转换:定义了一个特征转换函数,将旧数据的表示映射到与新数据兼容的新特征表示空间。
- 全局特征表示空间平衡:采用积分概率度量确保治疗和对照组在全局特征表示空间中的表示分布是平衡的。
创新点:
- 持续学习在因果推断中的应用:首次提出并探讨了在因果推断领域中,如何处理增量式可用的观测数据的问题。
- 新的评价标准:提出了可扩展性、适应性和可访问性三个新的评估标准,以适应不断变化的数据环境。
- CERL方法:提出了一种新颖的方法,该方法结合了选择性和平衡表示学习、特征表示蒸馏和特征转换,以实现对新旧数据的持续因果效应估计。
- 记忆机制:通过存储有限的特征表示而不是全部原始数据,解决了存储和访问大规模数据时的内存效率和隐私问题。
- 特征表示蒸馏和转换:通过特征表示蒸馏和转换技术,CERL能够在不访问原始数据的情况下,适应新的数据分布并保持对旧数据的估计能力。
需要的同学扫码添加我
回复“因果推断15”即可全部领取

3、COLA: Contextualized Commonsense Causal Reasoning from the Causal Inference Perspective
方法:
- 任务定义:提出了一个新的任务,即在事件序列中检测两个事件之间的常识性因果关系,称为情境化常识因果推理(Contextualized Commonsense Causal Reasoning, Contextualized CCR)。
- COLA框架:设计了一个名为COLA(Contextualized Commonsense Causality Reasoner)的零样本框架,用于从因果推断的角度解决上述任务。
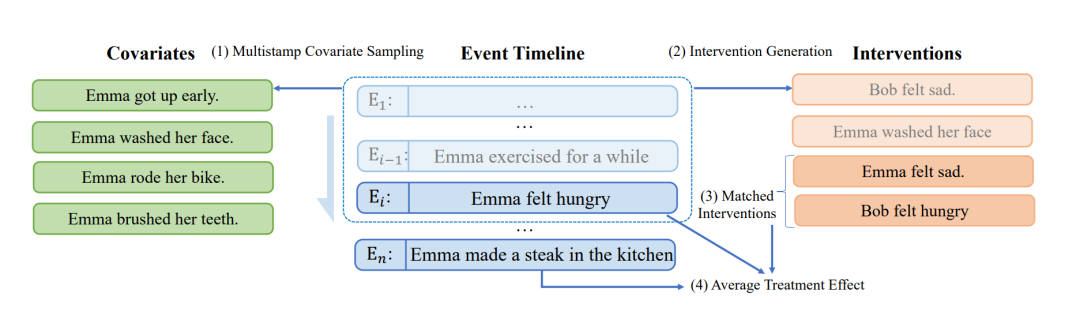
- 潜在结果框架:采用潜在结果框架来估计因果估计量(causal estimand),将其定义为一种“平均处理效应”(ATE),量化了干预事件对另一事件发生可能性的影响。
- 多时间戳协变量采样:从多个时间戳采样协变量,以纳入上下文信息。
- 干预生成:使用PolyJuice等工具生成可能的干预事件。
- 时间倾向匹配:使用时间倾向匹配来平衡协变量,确保比较的可比性。
- 得分估计:计算平均处理效应的估计值,以评估两个事件之间的因果关系。
创新点:
- 情境化常识因果推理任务:提出了一个新的任务定义,强调了在检测因果关系时考虑上下文的重要性。
- COLA框架:提出了一个新的框架,用于在考虑上下文信息的情况下检测事件之间的因果关系。
- 时间倾向匹配:创新性地使用时间倾向匹配来平衡协变量,以减少由于事件共现引入的偏误。
- 多时间戳协变量采样:通过从事件序列的多个时间点采样协变量,增加了模型考虑上下文的能力。
- 零样本学习:COLA框架能够在没有特定任务训练的情况下,利用预训练语言模型进行常识性因果推理。
- 因果推断视角:与以往依赖于语言模型的监督学习方法不同,COLA从因果推断的角度出发,提供了一种新的解决常识性因果推理的方法。
- 数据集构建:为了评估提出的任务和框架,作者通过众包方式创建了一个新的数据集COPES(Choice of Plausible Event in Sequence),并进行了严格的质量控制。
需要的同学扫码添加我
回复“因果推断15”即可全部领取