一、目录
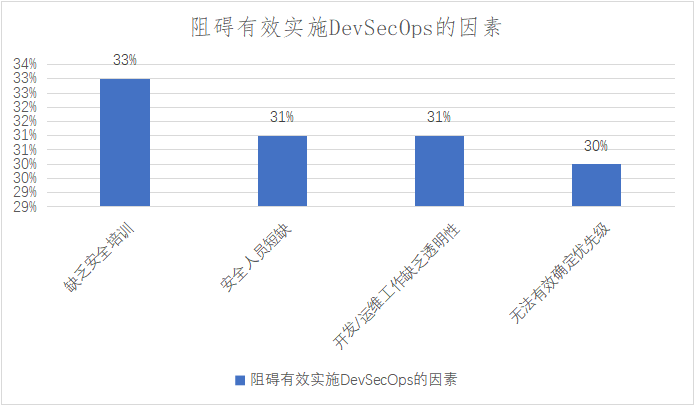
- 定义
- 求模型的计算强度,绘制屋檐模型,并分析
- 绘制多级缓存的屋檐模型
- 计算模型计算强度、工具
- A100显卡下模型分析
- 分析
- 如何提高模型的计算强度
二、实现
-
定义:
Roof line Model(屋檐模型):模型在一个计算平台的限制下,到底能达到多快的浮点计算速度.
模型构建的曲线:曲线由 硬件决定。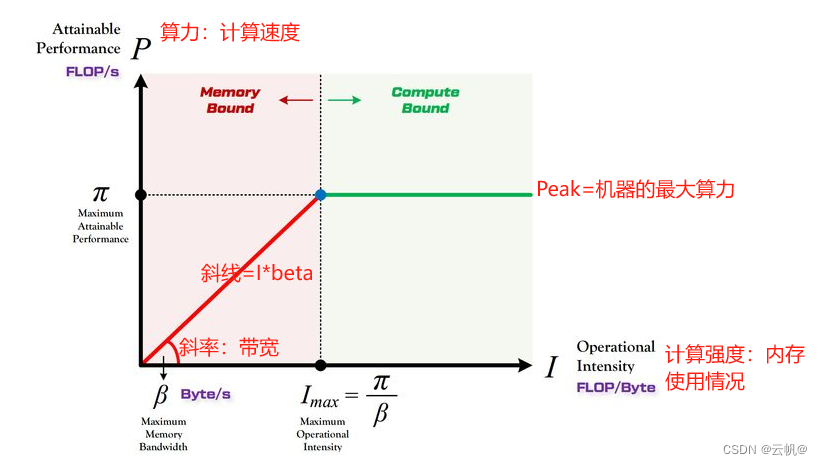
算力决定“屋顶”的高度(绿色线段)
带宽决定“房檐”的斜率(红色线段)
Peak:机器的最大算力,查表获取
Imax:计算强度上限,即内存最大情况。
带宽: 计算平台每秒能完成的内存交换量上限;单位: Byte/s
计算强度I: 表示每Byte内存交换到底用于多少次浮点运算,计算强度越大,内存使用效率越高。
例如:1080Ti 的算力 π=11.3 TFLOP/s
,1080Ti 的带宽 β=484 GB/s 进行绘图:
Imax=(11.310^12) /(48410^9)=23.35 1gb约10^9 byte
Peak=11.3 TFLOP
所以: 可以绘制计算机Roof line 模型。
计算瓶颈区、宽带瓶颈区
讲的是模型位于 屋檐模型中的分析。
计算瓶颈区
不管模型的计算强度 I 有多大,它的理论性能 P 最大只能等于计算平台的算力 π 。当模型的计算强度 I 大于计算平台的计算强度上限 Imax 时,模型在当前计算平台处于 Compute-Bound状态,即模型的理论性能 P 受到计算平台算力 π 的限制,无法与计算强度 I 成正比。从充分利用计算平台算力的角度上看,此时模型已经 100% 的利用了计算平台的全部算力。可见,计算平台的算力 π 越高,模型进入计算瓶颈区域后的理论性能 P 也就越大。
模型位于计算瓶颈区:模型的算力受限于平台的算力。
宽带瓶颈区
当模型的计算强度 I 小于计算平台的计算强度上限 Imax 时,由于此时模型位于“房檐”区间,因此模型理论性能 P 的大小完全由计算平台的带宽上限 β (房檐的斜率)以及模型自身的计算强度 I 所决定,因此这时候就称模型处于 Memory-Bound 状态。可见,在模型处于带宽瓶颈区间的前提下,计算平台的带宽 β 越大(房檐越陡),或者模型的计算强度 I 越大,模型的理论性能 P 可呈线性增长。
模型位于计算瓶颈区,位于曲线下,可优化模型的计算强度。位于曲线上,可优化模型的计算强度+宽带。 -
求模型的计算强度,绘制屋檐模型,并分析
模型的计算强度=运算量/访存量
运算量= 模型前向传播的浮点运算次数
访存量=模型前向传播内存交换数量
假设 VGG16 的计算强度 IV≈25 MobileNet 的计算强度 IM≈7 (后面)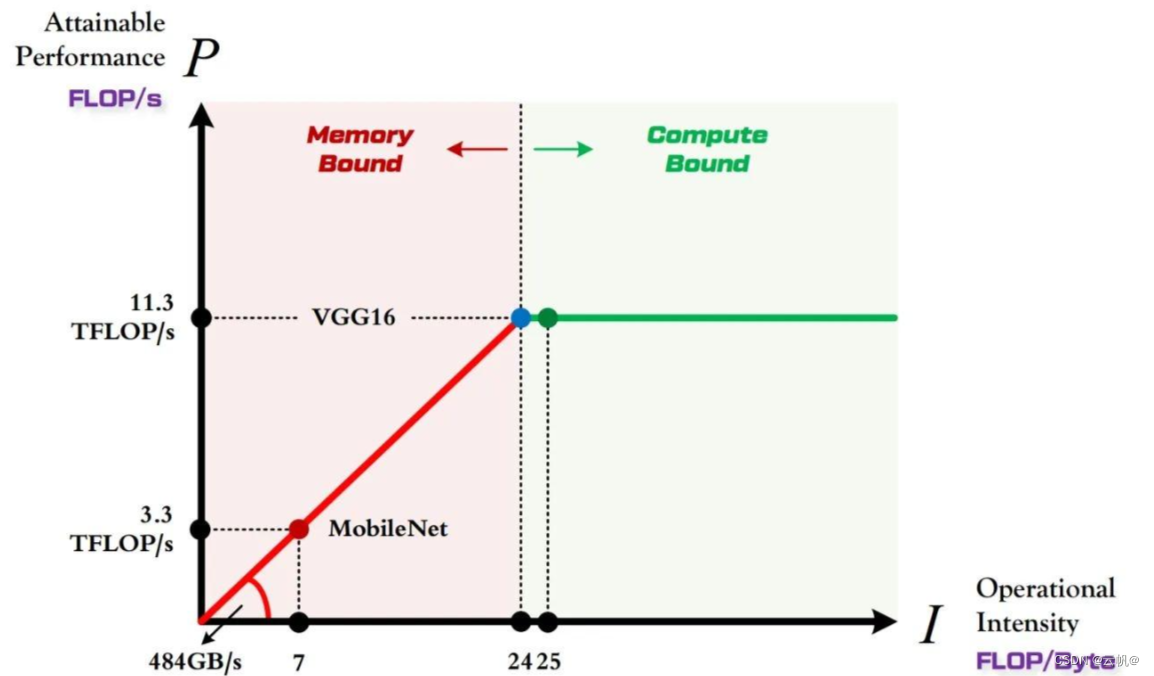
(7484109)/(1012)=3.3
由上图可以非常清晰的看到:
MobileNet 处于 Memory-Bound 区域。在 1080Ti 上的理论性能只有 3.3 TFLOP/s。
VGG16 刚好迈入 Compute-Bound 区域。完全利用 1080Ti 的全部算力。 -
绘制多级缓存的屋檐模型
参考:https://zhuanlan.zhihu.com/p/665990267
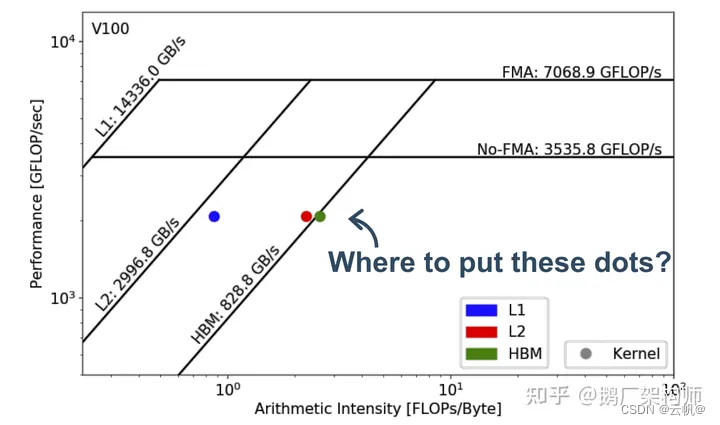
流程:
确定不同计算指令的峰值FLOPS值,画出其Roof-line(即上方横向“屋顶”)—>查询平台算力
以L1、L2、HBM三级缓存之间的最大带宽速率为斜率,得到包括多级缓存Roof-line(即左侧斜向“屋檐”)---->查询带宽
使用prof工具得到算子的一次推理中L1、L2、HBM三层的访存量。---->求模型的访存量
使用prof工具得到算子的一次推理的计算量FLOPs。 ------>求模型的推理量
计算L1、L2、HBM三层的计算强度(FLOPs/访存量),计算得到三个计算强度,画到图中。---->计算、绘图。 -
计算模型计算强度、工具
from torchstat import stat
import torchvision.models as models
net = models.resnet18() #以resnet18为例
print(stat(net, (3, 224, 224))) # (3,224,224)表示输入图片的尺寸
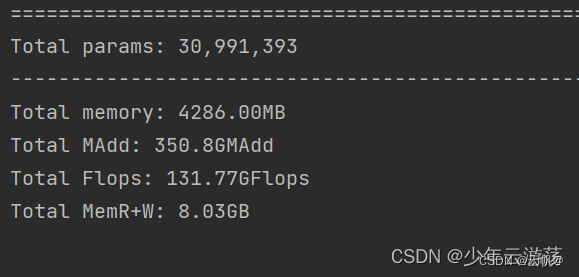
计算量:131.77GFlops、内存读写8.03GB
模型计算强度=(131.77*109)/(8.03*109)=16.471Flops/Byte
- A100显卡下模型分析
- 查看算力、宽带: https://www.nvidia.cn/data-center/a100/
FP32 算力为 19.5TFLOPS,
HBM2E(高带宽内存)High Bandwidth Memory: 1555GB/SEC
L1:一级缓存 缓存可以不用绘制
L2: 二级缓存
I max=(19.5/1555)*1000=12.5
- 查看算力、宽带: https://www.nvidia.cn/data-center/a100/

3. 求模型参数:
16.471Flops/sec1555GB/sec109/1012=25.61
import matplotlib.pyplot as plt
import numpy as np
# 峰值性能(Peak Performance)与内存带宽(Memory Bandwidth)
peak_performance = 19500 # 以 GFLOPS 表示, 处理器可以达到的最大浮点运算性能
memory_bandwidth = 1555 # 以 GB/s 表示, 内存与处理器之间每秒可以交换的最大数据量
# 设置算术密集度的范围(FLOPS/Byte)
arithmetic_intensity = np.logspace(-2, 2, num=100)
# 计算绩效上限
performance_limit = np.minimum(peak_performance, memory_bandwidth * arithmetic_intensity)
# 绘制 Roofline 模型
plt.loglog(arithmetic_intensity, performance_limit, label='Roofline')
app_arithmetic_intensity = 16.474 # FLOPS/Byte 运算量/访存量
app_peak_performance = 25610 # 每秒进行的浮点运算次数
# 标记应用程序性能
plt.scatter(app_arithmetic_intensity, app_peak_performance, color='red', label='App Performance')
# 添加图例和标签
plt.xlabel('Arithmetic Intensity (FLOPS/Byte)')
plt.ylabel('Performance (GFLOPS)')
plt.legend()
plt.grid(True, which="both", ls="--")
plt.title('Roofline Model')
# 显示图表
plt.show()
- 分析
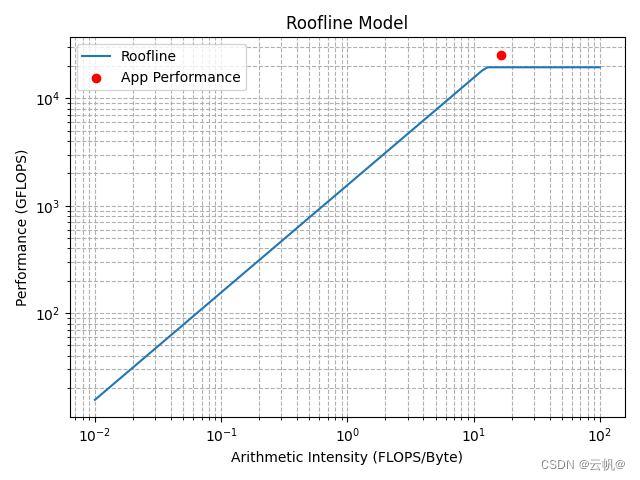
模型位于计算瓶颈期,宽带已充分使用,模型计算能力也超过平台的最大计算能力。
7. 如何提高模型的计算强度
https://zhuanlan.zhihu.com/p/677057296
平台的计算强度:Imax=Peak_flops/ 带宽
模型的计算强度=运算量/访问量 ---->横坐标
模型计算强度>平台的计算强度(Imax)模型受限于平台的计算资源运行速度慢、延迟高、吞吐量低等模型的计算强度<平台计算强度(Imax)模型受限于平台的宽带资源运行速度慢、延迟高、吞吐量低等

- 如果处于计算能力受限情况下,可以:
1 升级到更强大、更昂贵、峰值 FLOPS 更高的芯片。
2 对于矩阵乘法等特殊运算,NVIDIA Tensor Cores 等更快的专用硬件单元。
3 减少模型运行所需的运算操作数量。更具体地说,对于 ML 模型,这可能说明使用更少的参数就能获得相同的结果。像模型剪枝(pruning)或知识蒸馏(knowledge distillation)这样的技术可以帮助实现这一点。
4 使用精度更低、速度更快的数据类型进行计算。 - 如果处于内存带宽受限情况(Memory bandwidth bound)下,可以:
1 升级到功能更强大、更昂贵、具有更高内存带宽的芯片。
2 使用模型量化(quantization)等模型压缩技术或并不流行的模型剪枝和知识蒸馏技术,减少需要移动的数据量。对于 LLM(大语言模型),data size issue(译者注:此处应当指的是由于大规模数据传输导致的内存带宽受限问题)主要通过仅对模型权重进行量化的技术来解决(如 GTPQ [5] 和 AWQ [6] 量化算法),以及 KV-cache 量化来解决。
3 减少内存操作的次数。在 GPU 上运行任务实际上就是执行一个有向图,图中的每个节点都代表一个计算核心(或 GPU 函数)的执行。对于每个核心(kernel),必须从内存中获取输入,并将输出写入内存。将多个计算核心(或 GPU 函数)合并为一个更大的计算核心,即以调用单个计算核心的方式来执行最初分散在多个计算核心中的内存操作,可以减少内存操作的次数。将多个内存操作融合的过程可以由编译器自动执行,也可以通过手动编写自定义的内核来进行内存操作融合(这种方式比较困难,但对于复杂的内存操作融合来说是必要的)。
4 对于 Transformer 模型,为注意力层(attention layer)开发高效的经过融合处理后的计算核心(fused kernels)仍然是一个较为活跃的领域。许多经过优化的计算核心都基于流行的FlashAttention算法 [7]。Transformer 模型所需的经过融合处理的计算核心库包括 FlashAttention 、 Meta 的 xFormers 以及现已废弃的 NVIDIA FasterTransformer (已并入 NVIDIA TensorRT-LLM 中)。