Buffer Pool是什么
Buffer Pool是MySQL数据库中一个非常关键的组件。数据库中的数据最终都是存放在磁盘文件上的。但是在对数据库执行增删改查操作时,不可能直接更新磁盘上的数据。因为如果直接对磁盘进行随机读写操作,那速度是相当的慢的。随便一个大磁盘文件的随机读写操作,可能都要几百毫秒,这样数据库每秒也就只能处理几百个请求。
数据库执行增删改操作时,是基于内存Buffer Pool中的数据进行的。同时为了防止在更新完内存中的数据之后,由于机器宕机而造成数据丢失,数据库引入了redo日志机制,即增删改时会把修改也写入redo日志中。
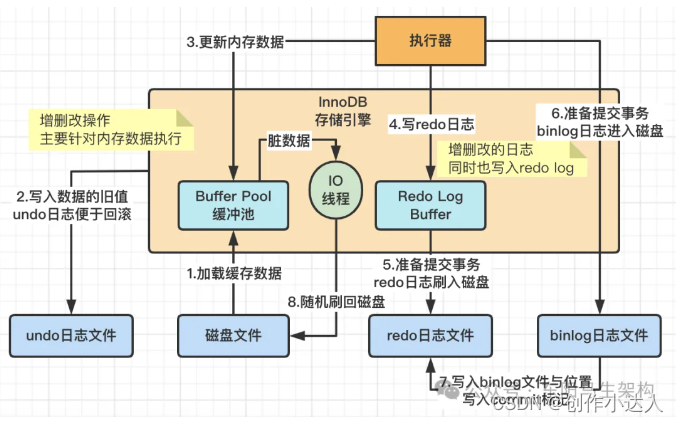
Buffer Pool就是数据库的一个内存组件,里面缓存了磁盘上的真实数据。当执行更新时,会写undo日志、修改Buffer Pool数据、写redo日志;当提交事务时,会将redo日志刷磁、binlog刷盘、添加commit标记。最后后台IO线程会随机把Buffer Pool里的脏数据刷入到磁盘数据文件中。
为什么要有 Buffer Pool?
虽然说 MySQL 的数据是存储在磁盘里的,但是也不能每次都从磁盘里面读取数据,这样性能是极差的。
要想提升查询性能,加个缓存就行了嘛。所以,当数据从磁盘中取出后,缓存内存中,下次查询同样的数据的时候,直接从内存中读取。
为此,Innodb 存储引擎设计了一个缓冲池(Buffer Pool),来提高数据库的读写性能。
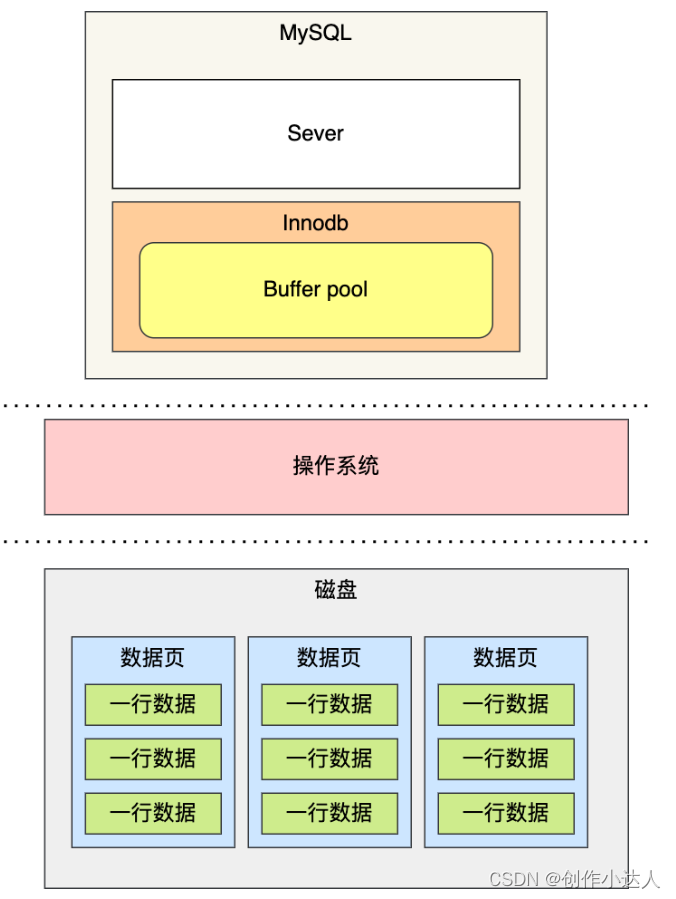
有了缓冲池后:
-
当读取数据时,如果数据存在于 Buffer Pool 中,客户端就会直接读取 Buffer Pool 中的数据,否则再去磁盘中读取。
-
当修改数据时,首先是修改 Buffer Pool 中数据所在的页,然后将其页设置为脏页,最后由后台线程将脏页写入到磁盘。
如何配置Buffer Pool的大小
由于Buffer Pool本质就是数据库的一个内存组件,所以Buffer Pool是有大小的,不能无限大。
Buffer Pool的默认大小是128MB,有点偏小。在实际生产环境下可以对Buffer Pool进行调整。比如对于16核32GB的数据库,可以给Buffer Pool分配2GB大小的内存。
[server]innodb_buffer_pool_size = 2147483648
Buffer Pool 缓存什么?
InnoDB 会把存储的数据划分为若干个「页」,以页作为磁盘和内存交互的基本单位,一个页的默认大小为 16KB。因此,Buffer Pool 同样需要按「页」来划分。
在 MySQL 启动的时候,InnoDB 会为 Buffer Pool 申请一片连续的内存空间,然后按照默认的16KB的大小划分出一个个的页, Buffer Pool 中的页就叫做缓存页。此时这些缓存页都是空闲的,之后随着程序的运行,才会有磁盘上的页被缓存到 Buffer Pool 中。
所以,MySQL 刚启动的时候,你会观察到使用的虚拟内存空间很大,而使用到的物理内存空间却很小,这是因为只有这些虚拟内存被访问后,操作系统才会触发缺页中断,接着将虚拟地址和物理地址建立映射关系。
Buffer Pool 除了缓存「索引页」和「数据页」,还包括了 undo 页,插入缓存、自适应哈希索引、锁信息等等。

为了更好的管理这些在 Buffer Pool 中的缓存页,InnoDB 为每一个缓存页都创建了一个控制块,控制块信息包括「缓存页的表空间、页号、缓存页地址、链表节点」等等。
控制块也是占有内存空间的,它是放在 Buffer Pool 的最前面,接着才是缓存页,如下图:
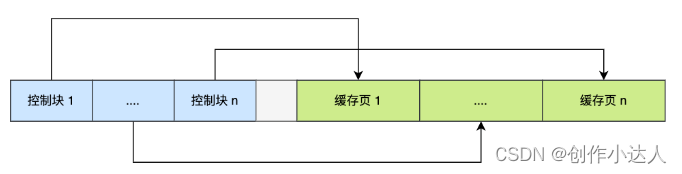
上图中控制块和缓存页之间灰色部分称为碎片空间。
为什么会有碎片空间呢?
你想想啊,每一个控制块都对应一个缓存页,那在分配足够多的控制块和缓存页后,可能剩余的那点儿空间不够一对控制块和缓存页的大小,自然就用不到喽,这个用不到的那点儿内存空间就被称为碎片了。
当然,如果你把 Buffer Pool 的大小设置的刚刚好的话,也可能不会产生碎片。
查询一条记录,就只需要缓冲一条记录吗?
不是的。
当我们查询一条记录时,InnoDB 是会把整个页的数据加载到 Buffer Pool 中,因为,通过索引只能定位到磁盘中的页,而不能定位到页中的一条记录。将页加载到 Buffer Pool 后,再通过页里的页目录去定位到某条具体的记录。
free链表可判断哪些缓存页是空闲的
当数据库运行起来后,肯定会不停地进行增删改查操作。此时会从磁盘上读取一个个的数据页放入到Buffer Pool中的缓存页里。
默认情况下,磁盘上的数据页和缓存页是一一对应的,都是16KB。Buffer Pool把数据缓存起来后,就可以对数据在内存里执行增删改查。
但是当数据库从磁盘上读取数据页放入Buffer Pool中的缓存页时,首先需要解决一个问题:哪些缓存页是空闲的?
为此,数据库为Buffer Pool设计了一个free链表,它是一个双向链表。在这个free链表里,每个节点就是一个空闲缓存页的描述数据块的地址。只要一个缓存页是空闲的,则其描述数据块的地址就会被放入free链表中。所以数据库刚启动时,如果此时所有的缓存页都是空闲的,那么所有缓存页的描述数据块就会被放进该free链表里。
简单LRU链表的工作原理
假设InnoDB从磁盘加载一个数据页到缓存页时,就把这个缓存页的描述数据块放到LRU链表头部去。
那么只要一个缓存页有数据,那么该缓存页就会在LRU里。并且最新加载数据的缓存页,会被放到LRU链表的头部。
假设某个缓存页的描述数据块本来在LRU链表的尾部,后面只要查询或者修改了这个缓存页的数据,也会把其描述数据块挪动到LRU链表头部。
总之,就是保证最近被访问过的缓存页,一定在LRU链表的头部。这样当缓冲区没有空闲的缓存页时,可以在LRU链表尾部找一个缓存页。而这个缓存页就是最近最少被访问的那个缓存页。然后把LRU链表尾部的那个缓存页刷入磁盘从而腾出一个空闲的缓存页,最后把需要的磁盘数据页加载到这个空闲的缓存页中即可。
这个LRU链表需要一定长度,不能只有2个节点。否则如果先是节点1被访问100次,接着到节点2被访问。这样虽然链表尾部是节点1,但实际上节点1是最近最少被访问的。
简单LRU链表可能存在的预读问题
在LRU链表的尾部,一定是最近最少被访问的那个缓存页。但这个LRU机制在实际运行中,面对MySQL的预读机制,会有问题。
MySQL预读,指的是从磁盘加载一个数据页时,可能会连带着把这个数据页相邻的其他数据页,也加载到缓存里。比如现在有两个空闲缓存页,在加载一个数据页时,就会连带着把其相邻的一个数据页也加载到缓存里去。但是接下来只有一个缓存页被访问了,另外一个通过预读机制加载的缓存页,其实并没被访问,而此时这两个缓存页可能都在LRU链表前面。
触发MySQL预读机制的情况
情况一:参数innodb_read_ahead_threshold默认值是56,意思是如果顺序访问一个区的多个数据页的数量超过了该阀值。就会触发预读机制,把下一个相邻区中的所有数据页都加载到缓存里去。
情况二:Buffer Pool里缓存一个区13个连续的会被频繁访问的数据页,此时就会直接触发预读机制,把这个区里的其他数据页也加载到缓存里。该情况通过参数innodb_random_read_ahead控制,默认OFF表示关闭。
所以,默认情况下第一种情况很可能会触发预读机制。并且第一种情况会一下子把相邻区中很多数据页加载到缓存里。这些缓存页如果都放在LRU链表前面,并且没什么访问了。这样就会导致一些频繁被访问的缓存页放到了LRU链表的尾部。最后造成频繁被访问的缓存页反而被清空掉。而被清空掉的缓存页很快又要从磁盘中重新加载进入缓冲区。这时不但不合理还很影响性能。
简单LRU链表可能存在的全表扫描问题
全表扫描,就是类似于执行这样的SQL语句:select * from users。此时没有加任何一个where条件,这个会导致MySQL把该表所有的数据页,都从磁盘加载到Buffer Pool里。
这时LRU链表中排在前面的缓存页,可能都是全表扫描加载进来的缓存页。而如果这次全表扫描后,后面几乎没有用到这个表里的数据。那此时LRU链表的尾部,也可能都是之前一直被频繁访问的缓存页。这样也会把频繁访问的缓存页给淘汰掉,最后留下不经常访问的全表扫描加载进来的缓存页。
总结
所以如果使用简单的LRU链表机制,其实是漏洞百出的。因为预读机制、全表扫描会把未来并不经常访问的数据页加载到缓存页里,从而导致那些频繁被访问的缓存页不得不处于LRU链表尾部。如果此时恰好需要把一些缓存页刷入磁盘或者清空以腾出空闲的缓存页,那么就会把频繁被访问的缓存页给清空了。