0、前言
本文涉及的主题:
-
redis 对象存储
-
底层数据结构:int、embstr、raw、ziplist、listpack、quicklist、skiplist、intset、hashtable
-
redis 数据类型:string、list、set、zset、hash
1、对象存储、底层编码、数据类型
1.1 对象存储
每个键值对对应一个 dictEntry
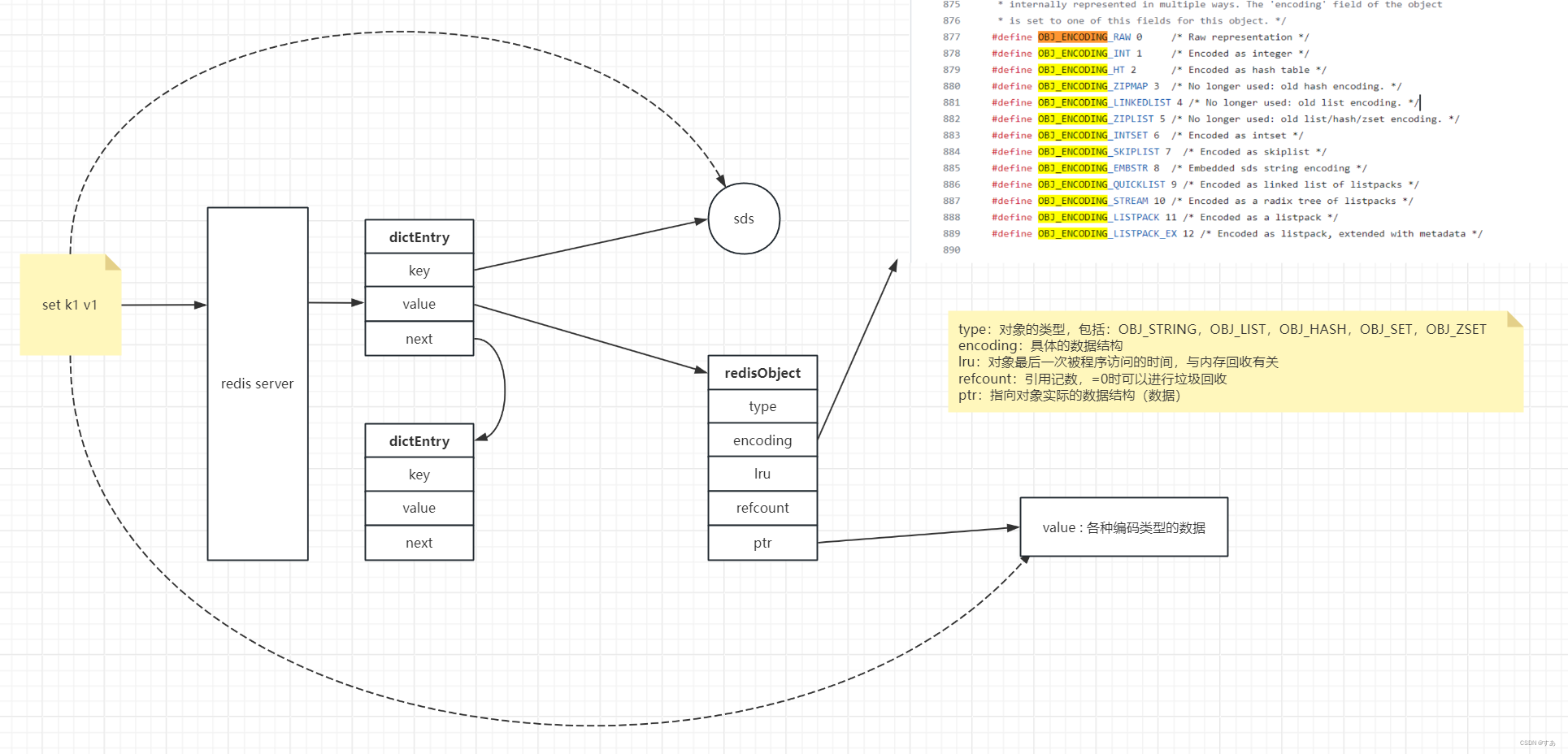
1.2 数据类型 X 底层编码 = 映射关系
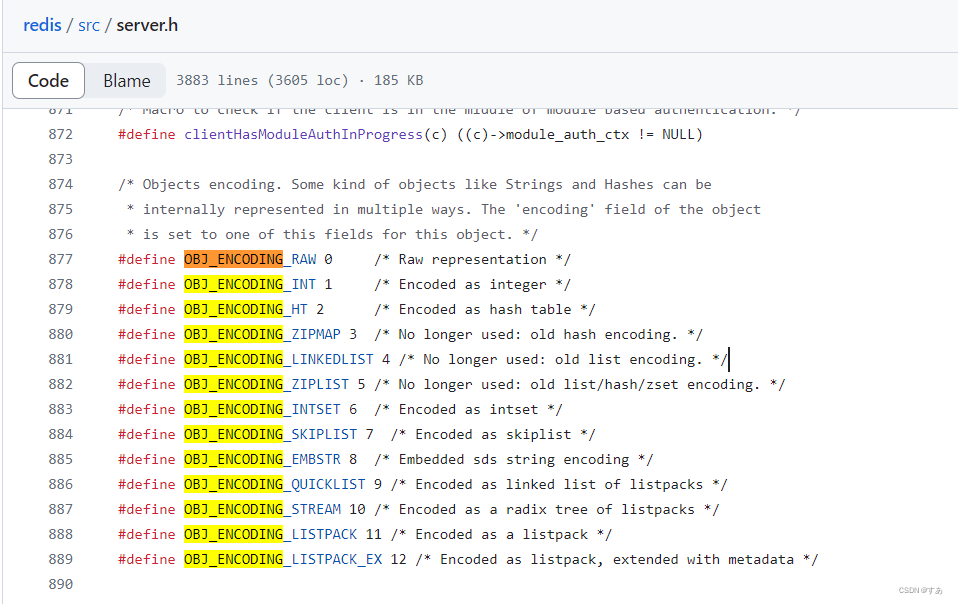
编码常量 : github
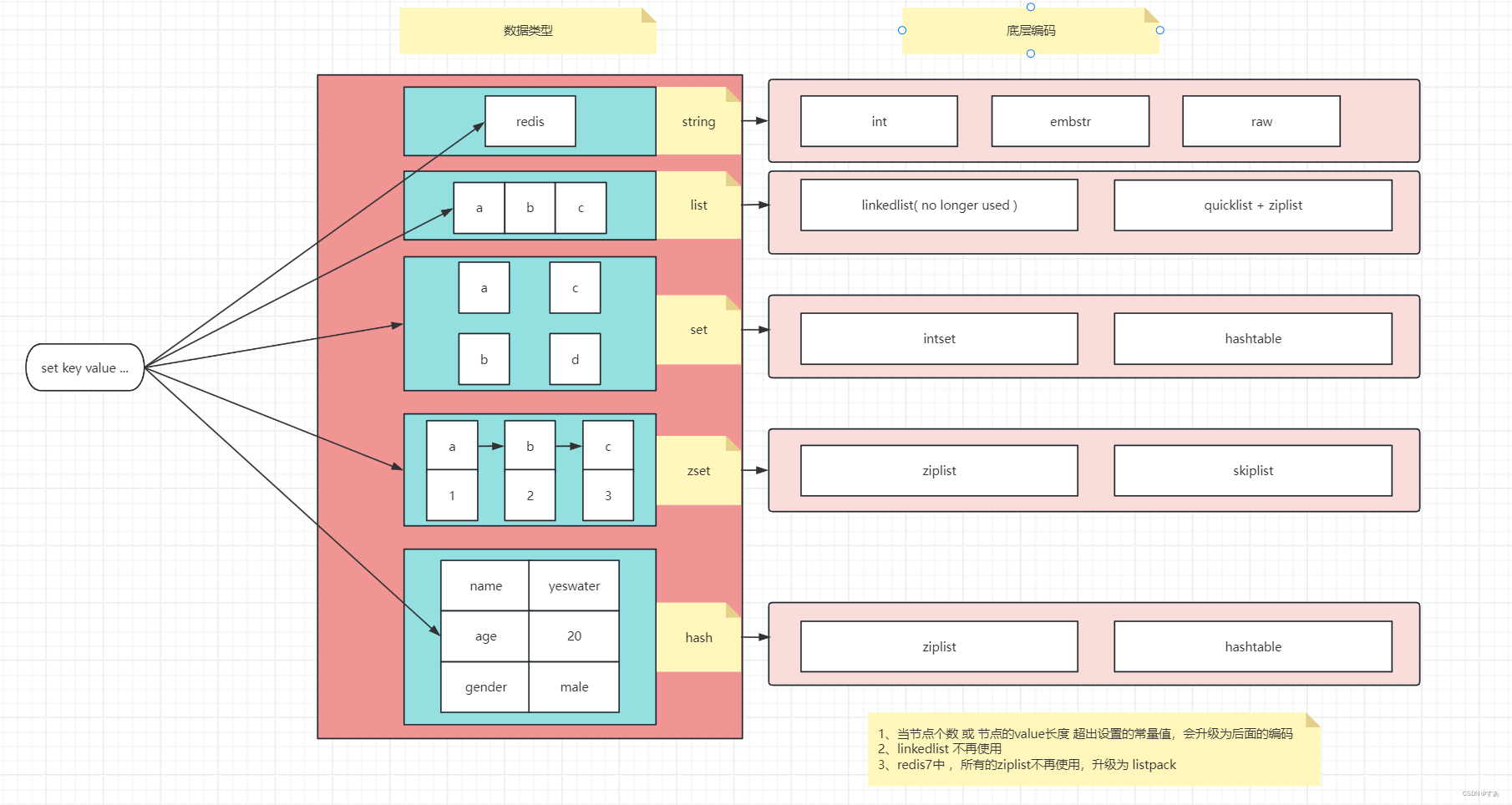
映射关系演示 1:
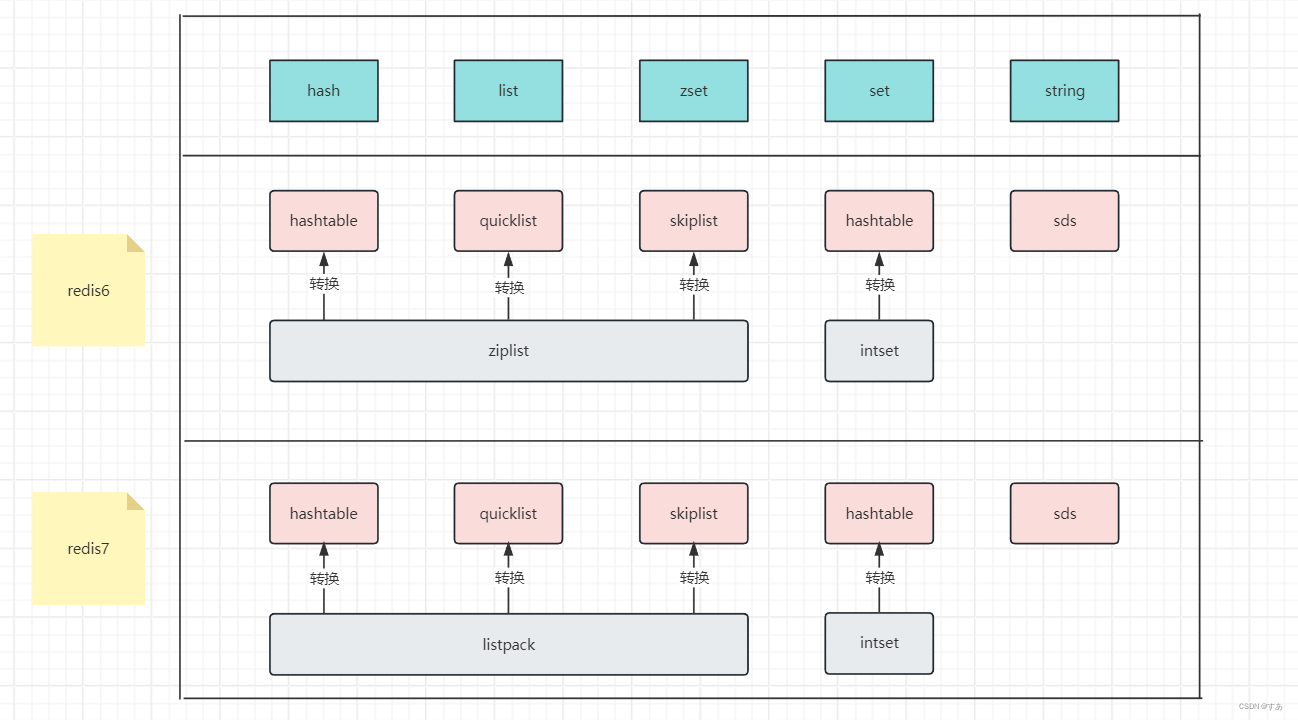
映射关系演示 2:
2、string
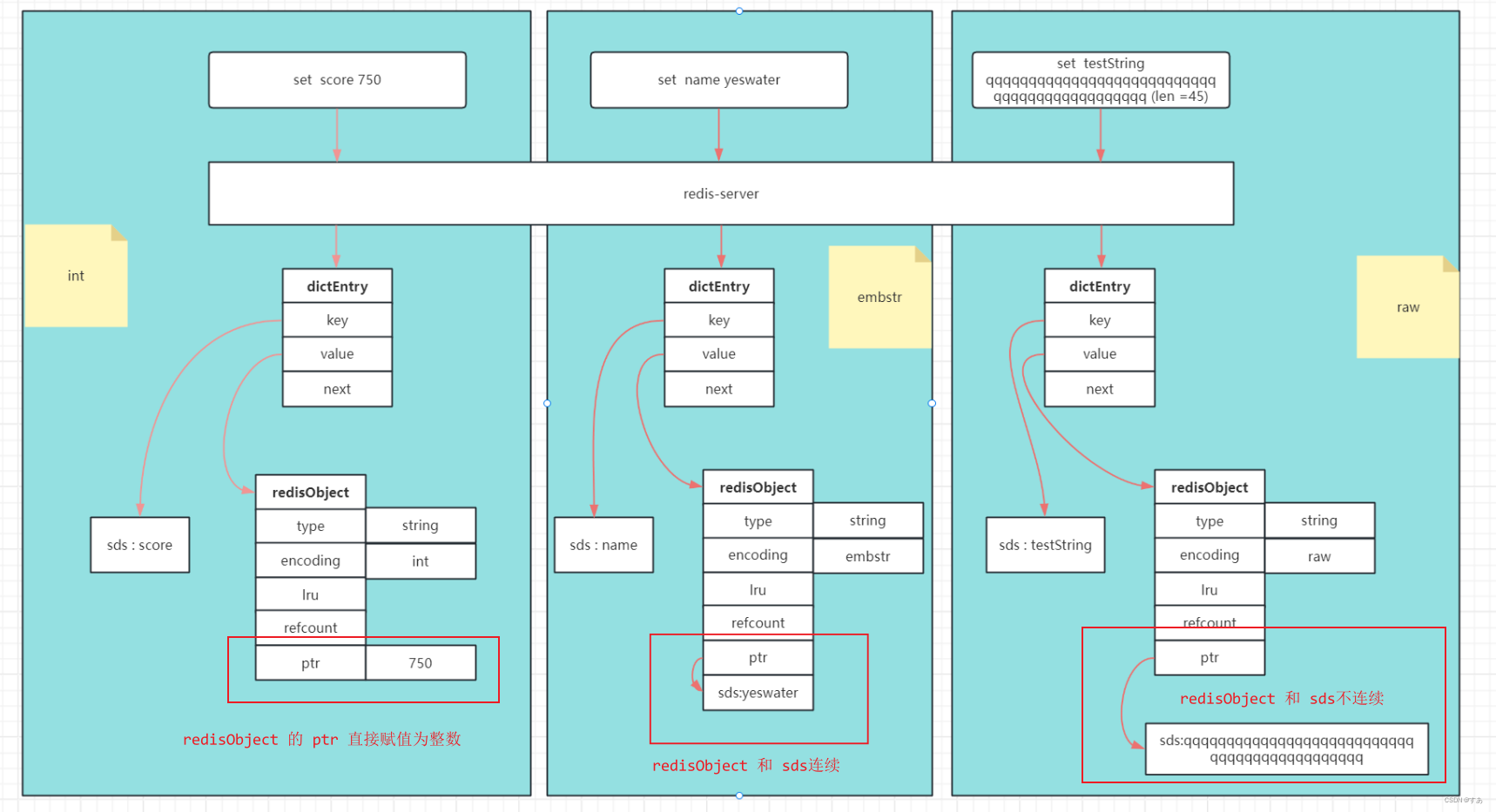
2.1 int、embstr、raw
int:长度小于19的整数
embstr:长度小于44的字符串
raw:长度大于44的字符串
对 int 、embstr对象进行修改,例如append操作,修改后的对象会变为 raw
类似于Java里面 byte short 执行相加操作后,会变为 int
2.2 sds 简单动态字符串
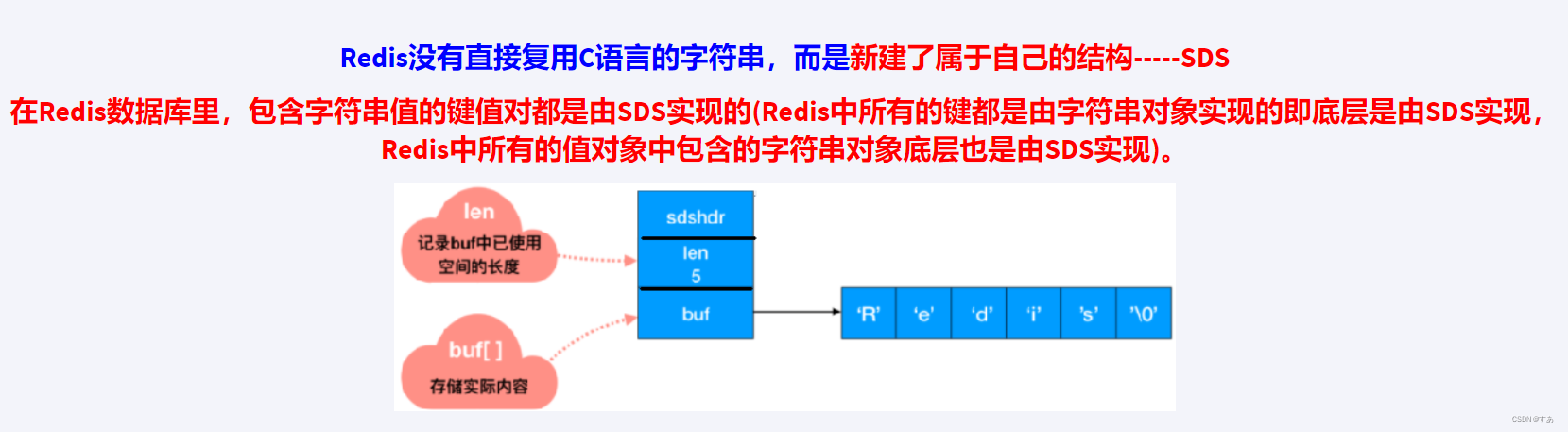
| C语言 | SDS | |
|---|---|---|
| 字符串长度处理 | 从头开始遍历,直到遇到 ‘\0’ 为止,时间复杂度O(N) | 记录当前字符串的长度,时间复杂度 O(1) |
| 内存重新分配 | 分配内存空间超过后,会导致数组下标越级或者内存分配溢出 | 空间预分配 && 惰性空间释放 |
| 二进制安全 | 字符串包含特殊字符,比如 ‘\0’ ,C中字符串遇到 ‘\0’ 会结束,那’\0’ 之后的数据就读取不到 | 根据 len 长度来判断字符串结束的 |
3、hash
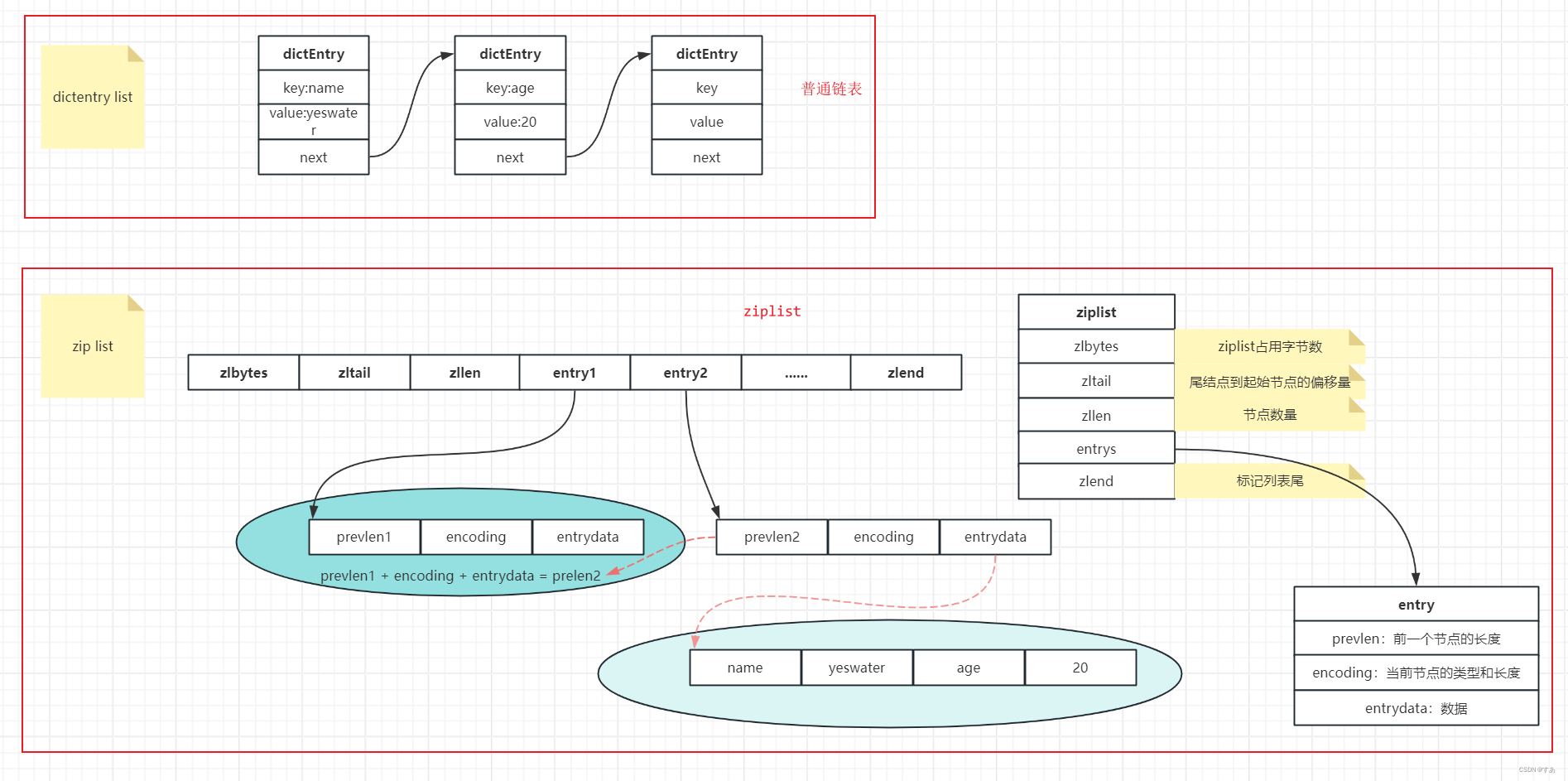
3.1 ziplist
ziplist 可以存储字符串或整数,以紧凑的数据结构存储在连续的内存块中,元素之间没有指针,内存使用率非常高
优点:
- 遍历比指针快。ziplist 中 entry的遍历是通过计算
当前起始位置+当前entry长度 - 可以直接通过
zllen获取列表长度
缺点:
- 连锁更新。修改 entry 时,可能会导致后面的 entry 都需要重新分配内存,以及更新
prevlen
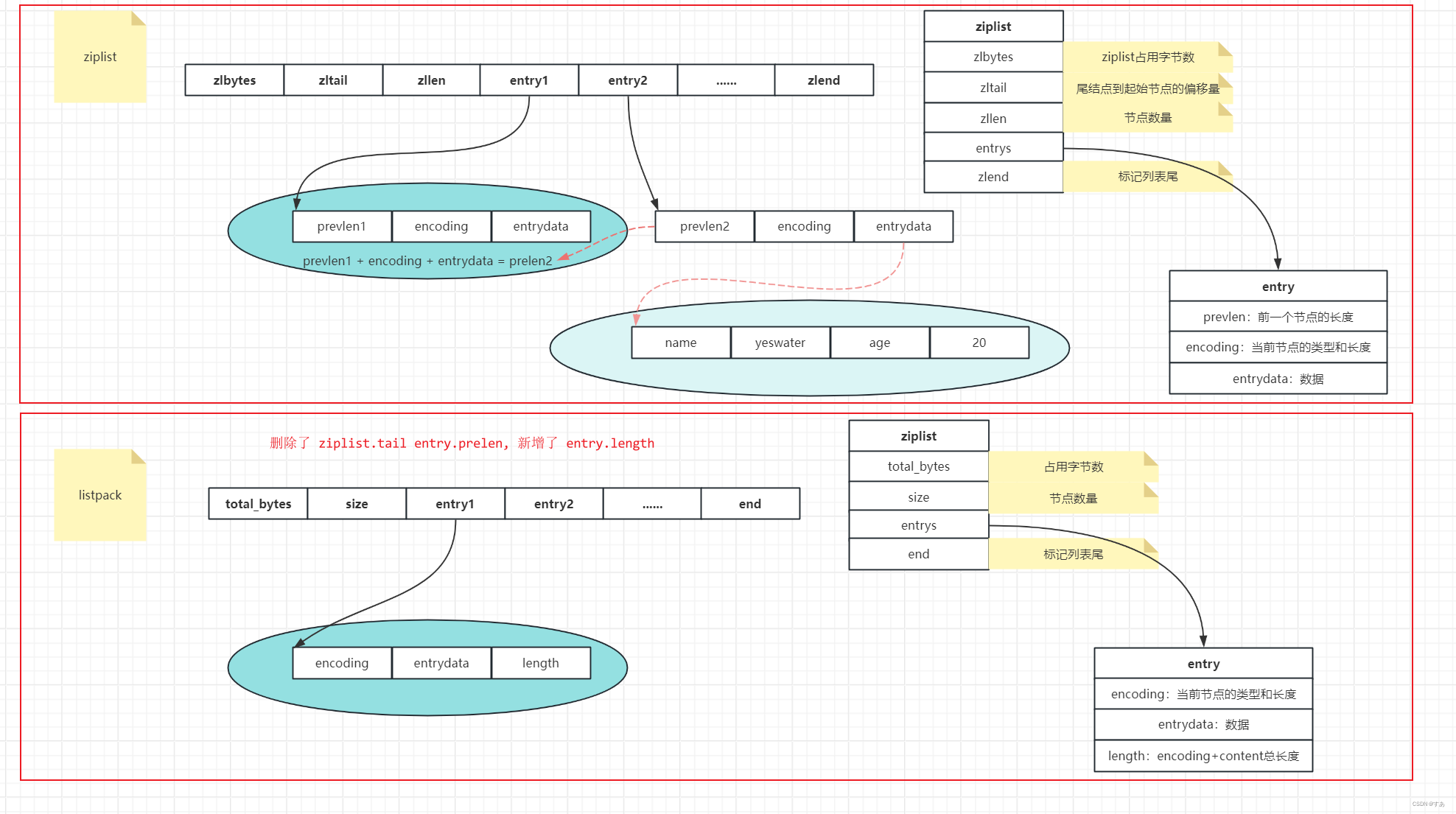
3.2 listpack
优点:
(解决了连锁更新问题,兼具ziplist的优点)
listpack不仅解决了ziplist中存在的连锁更新问题,还通过特有的编码方式和结构设计,实现了高效的正反方向遍历
4、list
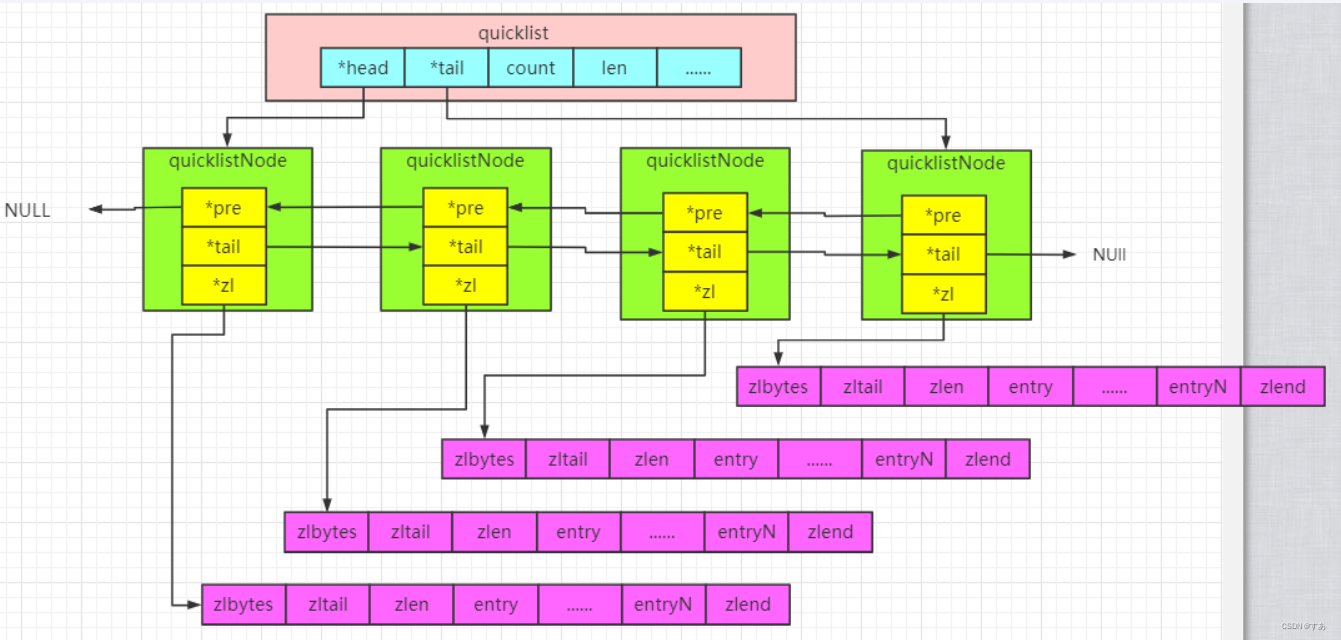
4.1 quicklist
quicklist 是一个双向链表,每个节点都是一个 ziplist(redis 6 )/ listpack(redis 7),head 和 tail 指向头尾
5、set
5.1 intset
节点个数 <= 常量值, 编码为 intset
5.2 hashtable
节点个数 > 常量值 , 编码为 hashtable
6、zset
默认 ziplist / listpack , 当节点个数 或 节点的value长度 超出设置的常量值,会升级为 skiplist
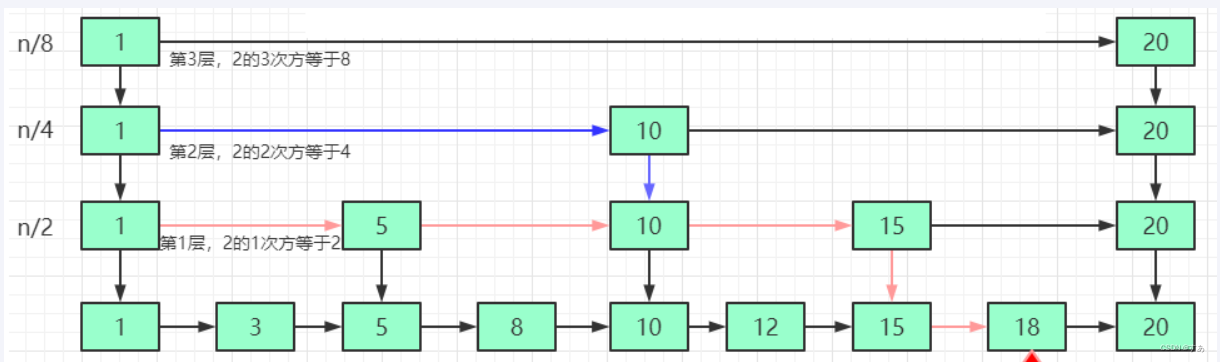
6.1 skiplist
是什么:
- 实现二分查找的有序链表 = 链表 + 多级索引
解决的问题:
- 大数据量情况下 ,顺序存储的 单链表查询 效率低
缺点:
- 修改数据效率比较低
7、总结
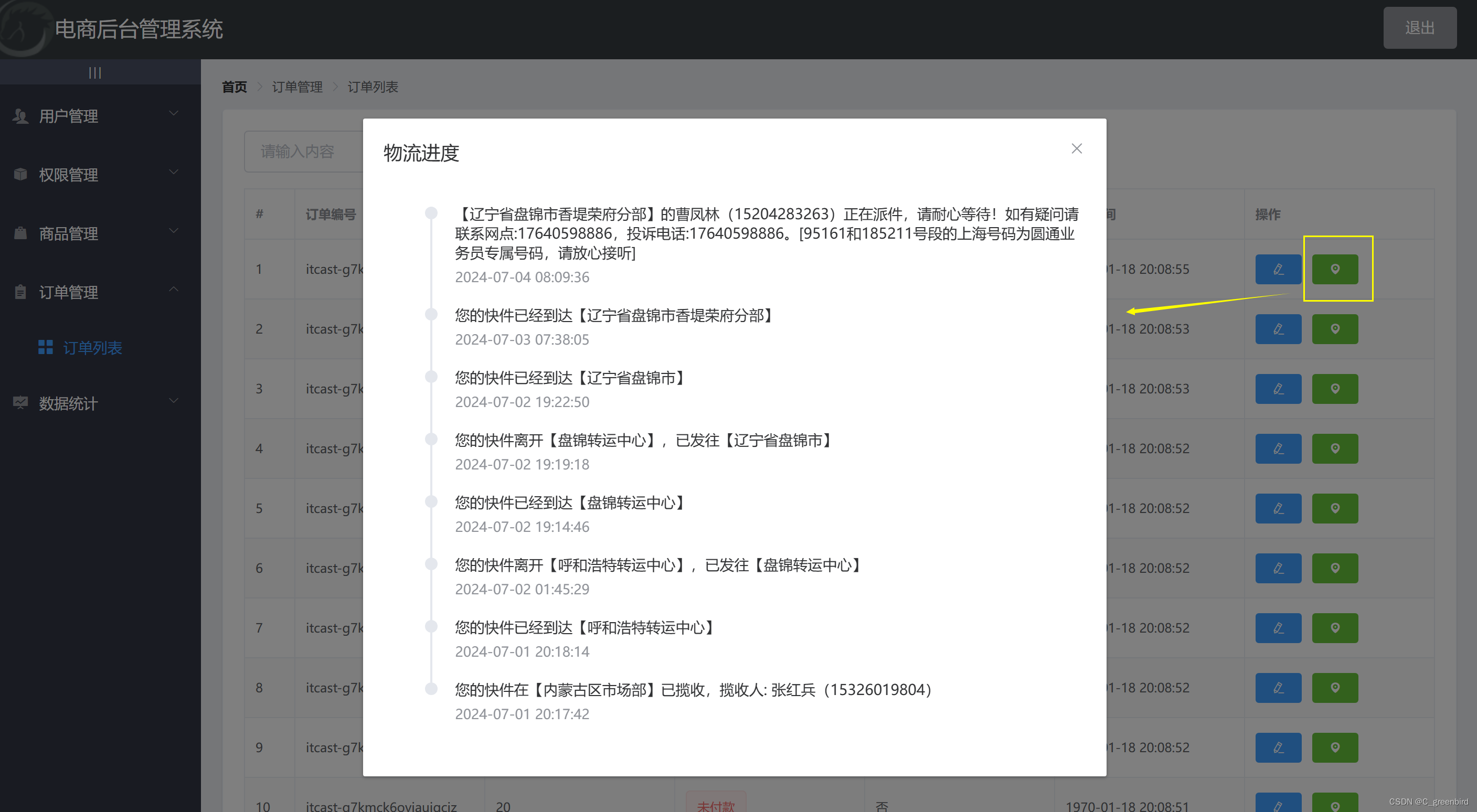


![plugin:vite:import-analysis]No known conditions for“./lib/locale/lang/zh-cn“](https://img-blog.csdnimg.cn/direct/f8bc1bdd95d04863b21097178a021ece.png)



![软考-系统架构设计师[九年]上岸感想](https://img-blog.csdnimg.cn/direct/84565ecf4e304c3cb0784a22607890f1.png)