系列篇章💥
| No. | 文章 |
|---|---|
| 1 | 【Qwen部署实战】探索Qwen-7B-Chat:阿里云大型语言模型的对话实践 |
| 2 | 【Qwen2部署实战】Qwen2初体验:用Transformers打造智能聊天机器人 |
| 3 | 【Qwen2部署实战】探索Qwen2-7B:通过FastApi框架实现API的部署与调用 |
| 4 | 【Qwen2部署实战】Ollama上的Qwen2-7B:一键部署大型语言模型指南 |
| 5 | 【Qwen2部署实战】llama.cpp:一键部署高效运行Qwen2-7b模型 |
| 6 | 【Qwen2部署实战】部署高效AI模型:使用vLLM进行Qwen2-7B模型推理 |
目录
- 系列篇章💥
- 引言
- 一、环境准备
- 1、镜像选择
- 2、环境配置
- 二、模型下载
- 1、模型下载脚本示例
- 三、代码准备
- 1、FastAPI 应用代码示例
- 四、API 部署
- 五、API 测试
- 1、使用curl调用API
- 2、使用python的requests库调用API
- 结语
引言
在人工智能的快速发展中,大型语言模型(LLM)逐渐成为研究和应用的新宠。它们在自然语言处理(NLP)领域的广泛应用,如文本生成、翻译、摘要等任务中展现出了卓越的性能。Qwen2-7B作为其中的一个代表,不仅因其强大的能力受到关注,更因其开源的特性,让广大研究者和开发者能够自由地使用和创新。本文将详细介绍在AutoDL平台上部署Qwen2-7B模型,并利用FastAPI框架创建API服务的全流程。
一、环境准备
首先,我们需要在AutoDL平台租赁一台配备RTX 3090/24G显存的显卡机器。选择适合的镜像,这里我们选择的是PyTorch-2.1.0-3.10(ubuntu20.04)-12.1,这个镜像为我们后续的操作提供了必要的基础环境。

1、镜像选择
- PyTorch版本: 2.1.0
- 操作系统: Ubuntu 22.04
- CUDA版本: 12.1
2、环境配置
通过JupyterLab访问服务器,并打开终端进行环境配置。使用以下命令更换pip源以加速依赖包的下载:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
这一步是必要的,因为默认的pip源在国外,对于国内用户来说,访问速度较慢,更换为清华大学的镜像源可以显著提高下载速度。
接着,安装所需的依赖包:
pip install fastapi==0.104.1 uvicorn==0.24.0.post1 requests==2.25.1 modelscope==1.11.0 transformers==4.41.0 streamlit==1.24.0 sentencepiece==0.1.99 accelerate==0.24.1 transformers_stream_generator==0.0.4
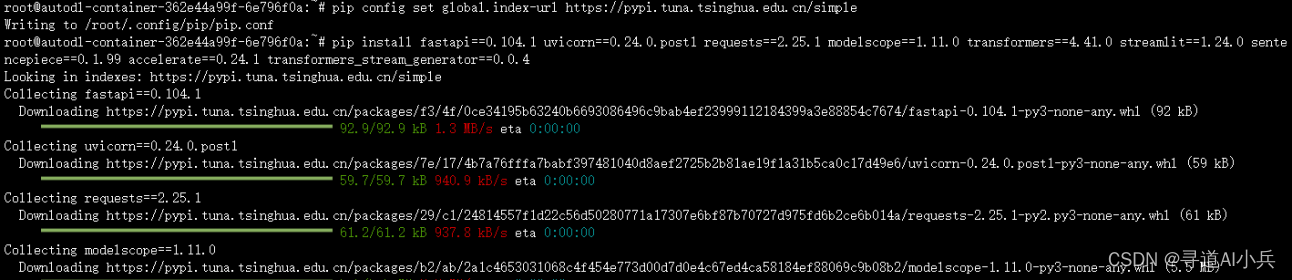
这些依赖包含了构建Web服务的FastAPI框架、用于提供服务的Uvicorn ASGI服务器,以及其他与模型加载和运行相关的库。
二、模型下载
利用modelscope库的snapshot_download函数下载Qwen2-7B-Instruct模型
也可以采用git下载 git clone https://www.modelscope.cn/qwen/Qwen2-7B-Instruct.git
1、模型下载脚本示例
import torch
from modelscope import snapshot_download
# snapshot_download函数用于下载模型
model_dir = snapshot_download(
'qwen/Qwen2-7B-Instruct', # 模型名称
cache_dir='/root/autodl-tmp', # 缓存目录
revision='master' # 版本号
)
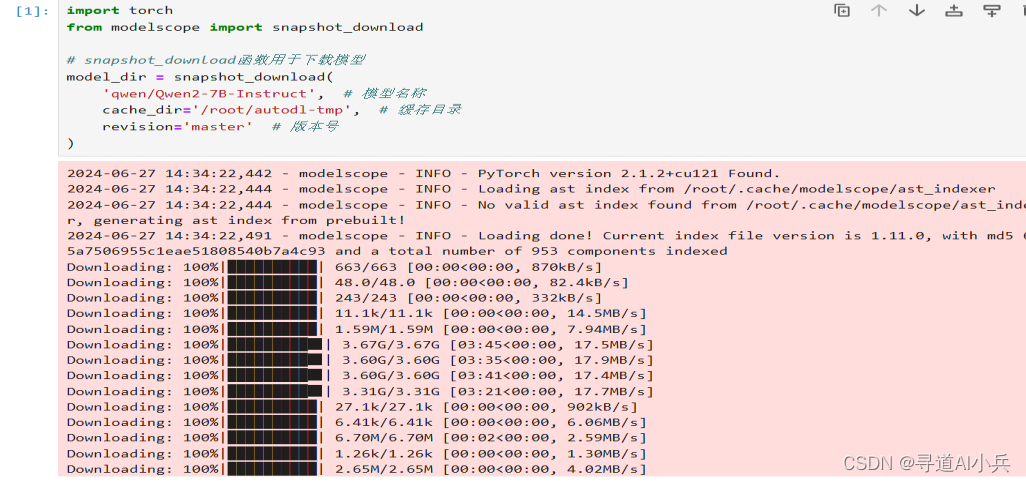
执行该脚本将从modelscope下载Qwen2-7B-Instruct模型,并保存到指定的缓存目录中。
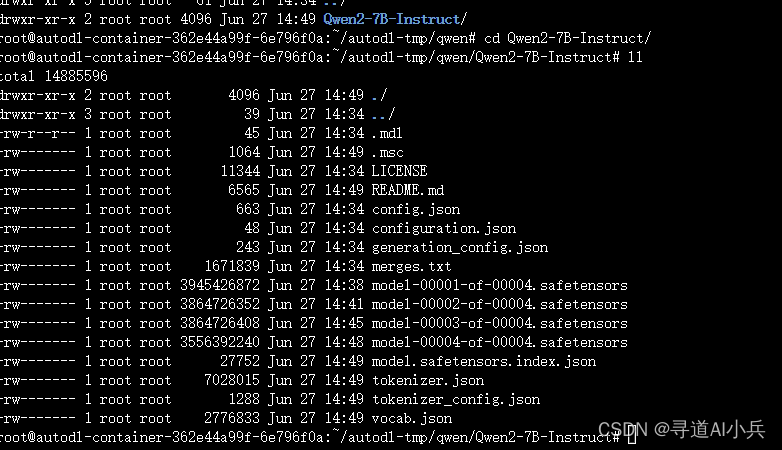
注意:检查文件大小,确认是否下载完整
三、代码准备
在/root/autodl-tmp路径下创建fastapi_Demo.py文件,编写FastAPI应用代码,用于加载模型并提供API服务。
1、FastAPI 应用代码示例
from fastapi import FastAPI, Request
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
import uvicorn
import json
import datetime
import torch
# 设置设备参数
DEVICE = "cuda" # 使用CUDA
DEVICE_ID = "0" # CUDA设备ID,如果未设置则为空
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE # 组合CUDA设备信息
# 清理GPU内存函数
def torch_gc():
if torch.cuda.is_available(): # 检查是否可用CUDA
with torch.cuda.device(CUDA_DEVICE): # 指定CUDA设备
torch.cuda.empty_cache() # 清空CUDA缓存
torch.cuda.ipc_collect() # 收集CUDA内存碎片
# 创建FastAPI应用
app = FastAPI()
# 处理POST请求的端点
@app.post("/")
async def create_item(request: Request):
global model, tokenizer # 声明全局变量以便在函数内部使用模型和分词器
json_post_raw = await request.json() # 获取POST请求的JSON数据
json_post = json.dumps(json_post_raw) # 将JSON数据转换为字符串
json_post_list = json.loads(json_post) # 将字符串转换为Python对象
prompt = json_post_list.get('prompt') # 获取请求中的提示
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
# 调用模型进行对话生成
input_ids = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)
model_inputs = tokenizer([input_ids], return_tensors="pt").to('cuda')
generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
now = datetime.datetime.now() # 获取当前时间
time = now.strftime("%Y-%m-%d %H:%M:%S") # 格式化时间为字符串
# 构建响应JSON
answer = {
"response": response,
"status": 200,
"time": time
}
# 构建日志信息
log = "[" + time + "] " + '", prompt:"' + prompt + '", response:"' + repr(response) + '"'
print(log) # 打印日志
torch_gc() # 执行GPU内存清理
return answer # 返回响应
# 主函数入口
if __name__ == '__main__':
# 加载预训练的分词器和模型
model_name_or_path = '/root/autodl-tmp/qwen/Qwen2-7B-Instruct'
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map="auto", torch_dtype=torch.bfloat16)
# 启动FastAPI应用
# 用6006端口可以将autodl的端口映射到本地,从而在本地使用api
uvicorn.run(app, host='0.0.0.0', port=6006, workers=1) # 在指定端口和主机上启动应用
以上代码首先设置了使用CUDA的设备参数,并定义了一个清理GPU内存的函数torch_gc。然后创建了一个FastAPI应用,并定义了一个处理POST请求的端点,用于接收用户的输入提示,并利用加载的模型生成回答。最后,启动了Uvicorn服务器来运行我们的FastAPI应用。
四、API 部署
通过在终端执行以下命令,启动FastAPI应用:
cd /root/autodl-tmp
python fastapi_Demo.py
执行该命令后,如果一切配置正确,你将看到应用启动成功的日志信息。

五、API 测试
一旦API服务启动,我们可以通过curl或python的requests库进行测试调用。
1、使用curl调用API
curl -X POST "http://127.0.0.1:6006" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好"}'
这条命令通过curl工具向我们的API发送一个POST请求,并附带了一个简单的输入提示“你好”。

2、使用python的requests库调用API
这段Python脚本定义了一个函数get_completion,它使用requests库向API发送POST请求,并打印出返回的回答。
import requests
import json
def get_completion(prompt):
headers = {'Content-Type': 'application/json'}
data = {"prompt": prompt}
response = requests.post(url='http://127.0.0.1:6006', headers=headers, data=json.dumps(data))
return response.json()['response']
response=get_completion('你好')
response
输出:
'你好!很高兴能为你提供帮助。有什么我可以为你做的吗?'
问题:你是谁?
response=get_completion('你是谁?')
response
输出:
'我是阿里云开发的一款超大规模语言模型,我叫通义千问。'
问题:AI大模型是什么?
response=get_completion('AI大模型是什么?')
response
输出:
'AI大模型指的是使用大规模数据和计算资源训练的深度学习模型。这些模型通常包含数以百万计或数以十亿计的参数,可以处理复杂的数据结构和任务,如自然语言处理、图像识别、语音识别等。它们能够从大量数据中学习到通用的表示和规律,并在各种下游任务上取得出色的表现。由于其强大的泛化能力和可扩展性,AI大模型在近年来吸引了广泛的关注和研究。'
问题:通义千问这个名字是什么意思?
response=get_completion('通义千问这个名字是什么意思?')
Response
输出:
'“通义千问”这个名字蕴含了阿里云大模型的几个关键特性。首先,“通义”二字取自“通达明智”,意在表达模型能够帮助用户获得知识、理解概念、解决疑惑,提供智慧和洞察力。同时,“通义”也意味着模型具有广泛适用性和跨领域的通用性,能够理解和回答各种主题的问题。\n\n其次,“千问”代表了模型的强大问答能力。它经过大量训练,能够处理和回应包括但不限于历史、科学、技术、艺术、文化等众多领域内的问题,并且能够持续学习和进化,不断提升其回答问题的质量和准确性。\n\n综上所述,“通义千问”不仅体现了阿里云大模型在知识广度和深度上的优势,也寓意着其致力于为用户提供全面、准确、有启发性的信息和支持。'
结语
通过本文的介绍,我们成功地在AutoDL平台上部署了Qwen2-7B-Instruct模型,并通过FastAPI创建了一个高效的API服务。这不仅展示了开源大模型的强大能力,也为开发者提供了一种快速部署和调用大型语言模型的方法。随着技术的不断进步,我们期待开源大模型在未来能够更加深入地融入到我们的学习和工作中,推动人工智能技术的进一步发展。

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:我是寻道AI小兵,资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索。
📖 技术交流:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,加入技术交流群,开启编程探索之旅。
💘精心准备📚500本编程经典书籍、💎AI专业教程,以及高效AI工具。等你加入,与我们一同成长,共铸辉煌未来。
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!