作者:来自 Elastic Madhusudhan Konda
如何以自定义方式组合多个稀疏、密集和地理字段

Elasticsearch 是一款强大的工具,可用于近乎实时地搜索和分析数据。作为开发人员,我们经常会遇到包含各种不同字段的数据集。有些字段是必填字段,或者包含的数据超过平均水平,而有些字段则很少。缺少许多值的字段称为 “稀疏(sparse)” 字段,而存在大多数值的字段称为 “密集(dense)” 字段。当然,我们还有那些表示地理位置数据的地理位置字段。
在本文中,我们将介绍如何查询具有不同字段的数据。我们将探索稀疏、密集和地理字段的集成,以增强你的搜索功能。我们将介绍实际示例(使用我最喜欢的 books 索引 :) ),通过 Kibana DevTools 将示例数据导入 Elasticsearch 并执行词汇和地理搜索。
在详细介绍如何组合这些字段以提取更深层次的分析能力之前,让我们先定义这些字段。
稀疏字段 - Sparse fields
稀疏字段是并非在每个文档中都存在的字段。
例如,考虑由各种类型的书籍组成的书籍索引。我们的书籍索引中的 special_edition 字段是稀疏的,因为并非所有书籍都以特别版的形式发布。同样,可能还有其他字段(例如 category 或 sales_info)不一定适用于所有书籍。稀疏字段对于根据只有数据集子集拥有的属性来过滤结果很有用。
密集字段 - Dense fields
相反,密集字段是预期会出现在所有或大多数文档中的字段。我们 books 索引中的 title、author、number_of_pages 和 publication_date 等字段被视为密集字段。它们适用于大多数(如果不是所有)图书,并且是每个文档的核心。它们有助于提供可靠的搜索查询。
地理字段 - Geo fields
地理字段允许索引地理数据,从而实现基于位置或地理区域的搜索。在我们的 books 索引中,topic_location 是一个地理字段,可以表示各种基于位置的属性。示例包括作者所在地、图书原版印刷地等。
组合各种字段
以自定义方式组合这些字段可以显著增强搜索功能并提供更相关的结果。在很多用例中,我们想要查询稀疏填充字段与密集字段以及地理字段的组合。
Elasticsearch 的强大之处在于它能够处理组合各种数据类型的复杂查询。通过了解稀疏、密集和地理位置字段的特征,我们可以设计满足特定用户需求的有针对性的搜索查询。
让我们通过实际示例来了解如何使用各种数据字段。
创建 “books” 索引
首先,让我们定义一个 books 索引,其中包含可应用于在线书店的各种字段类型。
正如您在下面的 PUT 请求中看到的,books 索引的映射由一些标准书籍属性组成。但是,你也可以找到一些可能不适用于每本书的字段,例如:
- available_copies
- special_edition
这些属性被认为是稀疏的,因为它们不一定需要填充到每本书中。其他字段 title、author、publication_date 字段等预计会出现在每本(或大多数)书籍中。
我们希望将这些字段与可以表示书籍主题位置的地理点字段结合起来:
# Creating books mapping schema
PUT /books
{
"mappings": {
"properties": {
"title": { "type": "text" },
"author": { "type": "text" },
"price": { "type": "float" },
"tags": { "type": "keyword" },
"publication_date": { "type": "date" },
"available_copies": { "type": "integer" },
"special_edition": { "type": "boolean" },
"topic_location": { "type": "geo_point" },
"genre": { "type": "keyword" },
"language": { "type": "keyword" }
}
}
}
上面的代码片段向我们展示了图书索引的映射模式。它由多种字段组成 - 稀疏字段、密集字段和地理位置字段。
复制代码片段并将其粘贴到 Kibana 控制台中。执行它将创建我们的 books 索引。
现在我们已经创建了映射,让我们索引一些示例数据。
索引示例数据
我们想索引几本包含代表我们需求的数据的书籍。以下示例文档添加了具有以下属性的书籍:
# Omitting special_edition and technology
# Note the location is Silicon Valley
POST /books/_doc/1
{
"title": "Head First Java: A Brain-Friendly Guide",
"author": " Kathy Sierra, Bert Bates, Trisha Gee",
"price": 43.99,
"tags": ["programming", "Java", "advanced"],
"publication_date": "2024-03-20",
"available_copies": 10,
"topic_location": { "lat": 37.3861, "lon": -122.0839 },
"genre": "Technology",
"language": "English",
"technology": "Java"
}
# Omitting 'special_edition'
# Note the location is London
POST /books/_doc/2
{
"title": "Elasticsearch in Action 2e",
"author": "Madhusudhan Konda",
"price": 39.99,
"tags": ["Elasticsearch", "Search", "Technology", "2nd Edition"],
"publication_date": "2022-07-01",
"available_copies": 10,
"topic_location": { "lat": 51.5074, "lon": -0.1278 },
"genre": "Technology",
"special_edition": true,
"language": "English",
"technology": "Elasticsearch"
}
# Omitting 'available_copies', 'special_edition', and 'topic_location'
POST /books/_doc/3
{
"title": "Functional Programming in Java",
"author": "Venkat Subramaniam",
"price": 36.99,
"tags": ["Java", "Functional Programming", "Software Development"],
"publication_date": "2018-03-15",
"genre": "Technology",
"language": "English",
"technology": "Java"
}
如你所见,我们有四本不同的书,每本都有一些字段缺失,从而展示了稀疏字段的概念。
数据准备完成后,下一步是编写有效的查询,让这些不同的字段产生出色的分析见解。
我们将编写以下查询:
- 查找特定位置附近的 Java 书籍
- 获取特别版搜索技术书籍
- 搜索多种语言的最新 IT 书籍
本文的其余部分将介绍如何创建结合稀疏、密集和地理字段的查询。
查找技术中心附近的 Java 书籍
假设我们想查找某个地点(例如 SFO)附近的 Java 书籍。我们想编写一个 bool 查询来匹配某个地理区域内的 Java 书籍。以下查询可完成此任务:
在这里,我们查找硅谷附近的 Java 相关书籍:
# Searching for Java books in Silicon Valley
GET /books/_search
{
"query": {
"bool": {
"must": [
{ "match": { "technology": "Java" } }
],
"filter": [
{ "geo_distance": { "distance": "100km", "topic_location": { "lat": 37.7749, "lon": -122.4194 } } }
]
}
}
}
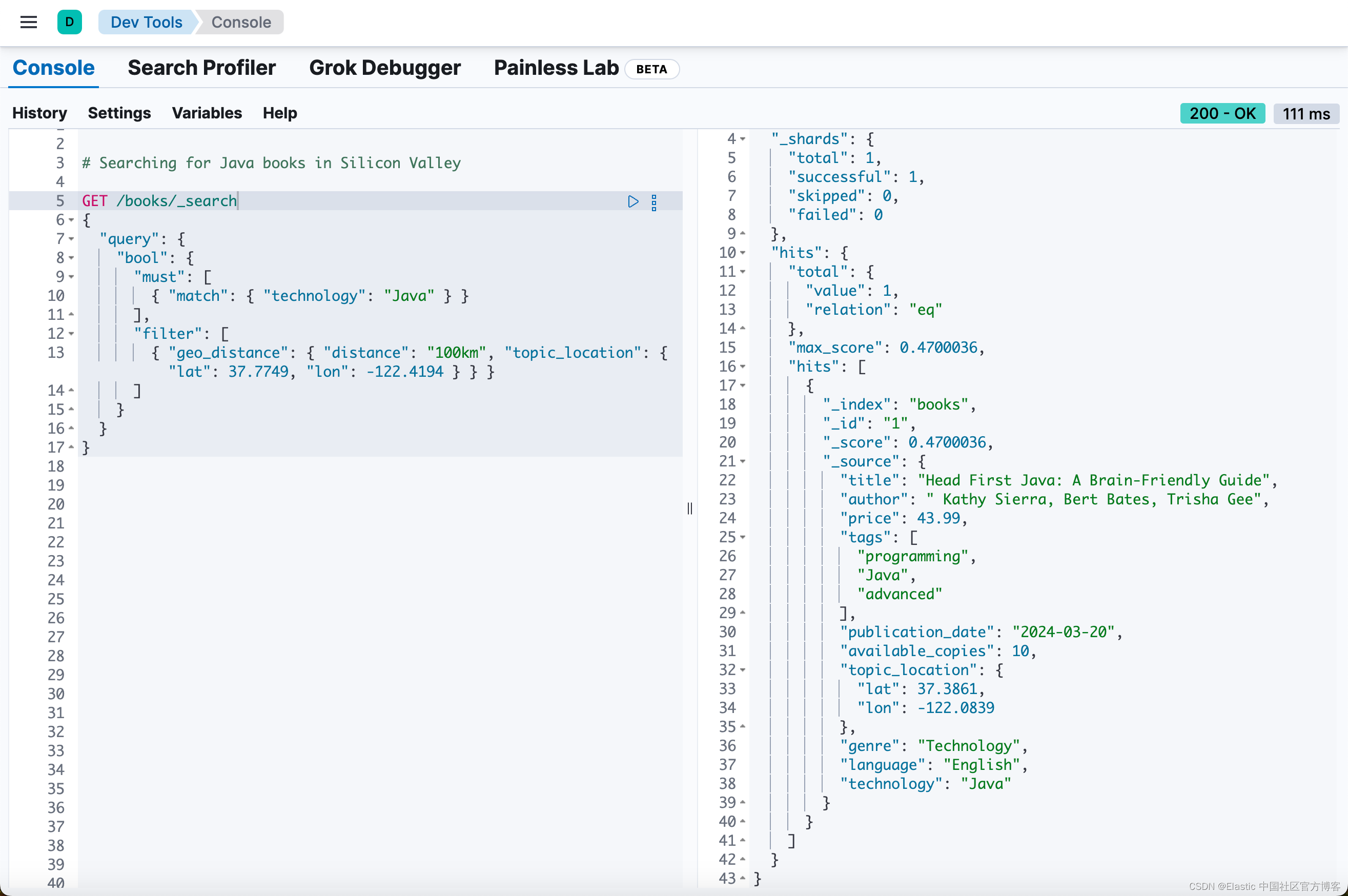
执行此查询将返回 “Slilicon Valley - 硅谷” 及其周边(半径约 100 公里)的 “Java” 书籍。在本例中,将返回 “Head First Java”。
查询结合了字段类型以实现有针对性的搜索目标。查询查找与 “Java”(technology 字段)特别相关的书籍,但这些书籍可能与索引中的所有条目无关。这是一个稀疏字段场景,因为并非所有书籍都填充了 technology 字段。
此示例演示了 Elasticsearch 如何将各种数据类型集成到一个有凝聚力的搜索策略中。
查询特别版搜索技术书籍
假设我们的目标是在我们的数据库中识别特别版书籍,并且这些书籍与 Elasticsearch 等搜索技术有关。此查询会提取可能与有兴趣深入学习该技术的特定受众特别相关的书籍。
我们再次使用 bool 查询来筛选与搜索技术相关的特别版书籍:
# Special edition Technology books
GET /books/_search
{
"query": {
"bool": {
"must": [
{ "match": { "special_edition": true } },
{ "match": { "technology": "Elasticsearch" } }
],
"should": [
{ "match": { "language": "English" } }
],
"must_not": [
{ "range": { "publication_date": { "lt": "2015-01-01" } } }
],
"minimum_should_match": 1
}
}
}
此查询根据 special_edition 字段(稀疏)和 genre 字段(密集)过滤图书。由于 genre 字段可能存在于每个图书文档中,因此查询在整个数据集中变得更具普遍适用性,使其成为密集字段。
除了上述要求外,我们希望图书以英文出版(尽管由于 minimum_should_match 设置为 1,因此这不是严格要求)。这意味着如果图书不是以英文出版的,则不会将其排除在搜索结果之外。但是,如果以 English 出版,这些图书在搜索结果中的排名会更高。
为了完整起见,我还添加了 must_not 子句 - 这将排除 2015 年之前出版的图书。这使我们能够专注于较新的出版物。
本质上,此查询提供了一种平衡的搜索方法:
- 使用严格的标准按版本和类型过滤图书,
- 设置对英语的偏好以提高相关性,并且
- 过滤掉不是最近的(2015 年之前出版)图书以确保仅显示最近的副本。
搜索多种语言的最新 IT 书籍
假设我们的用户可能正在寻找最新的资源(书籍)以了解技术领域的最新动态,但需要以他们的母语(特定)语言访问的材料。这在教育环境、跨国公司或双语人口地区很常见。虽然我不读 “Telugu - 泰卢固语”(一种南印度语言 - 我的家乡 :))的技术书籍,但我知道我的一些朋友希望用他们的母语解释技术内容。
假设我们想找到英语和西班牙语的最新 IT 书籍,这可能表明更广泛的教育价值:
# Recent IT Books Available in Multiple Languages
GET /books/_search
{
"query": {
"bool": {
"must": [
{ "range": { "publication_date": { "gte": "now-2y" } } }
],
"filter": [
{ "terms": { "language": ["English", "Spanish"] } },
{ "match": { "genre": "Technology" } }
]
}
}
}
让我在 “combined/diverse” 字段的上下文中解释一下查询:
publication_date 可能是一个密集字段,因为它是每本书籍记录中都应有的标准属性。通过使用范围查询,我们关注过去两年内出版的书籍。
同样,genre 通常是书籍数据库中的密集字段,因为书籍通常按类型分类。查询专门针对 “Technology” 类型中的书籍进行过滤。这确保了与 IT 主题相关的书籍。
language 字段可以根据数据集被视为稀疏字段。在全球数据集中,书籍可能有多种语言版本,但并非所有书籍都提供多种语言版本。
通过使用多种语言(在本例中为英语和西班牙语)的 terms 查询进行过滤,我们正在获取迎合多语言受众的书籍。
总结
总结。在本文中,我们了解了各种数据字段(例如稀疏字段、密集字段和地理字段)以及将它们组合起来对我们的数据进行深入分析的机制。
准备好自己尝试一下了吗?开始免费试用。
想要获得 Elastic 认证吗?了解下一期 Elasticsearch 工程师培训何时举行!
原文:Sparse, dense and geo fields: How to combine them efficiently in Elasticsearch — Elastic Search Labs