写在前面
【三年面试五年模拟】旨在整理&挖掘AI算法工程师在实习/校招/社招时所需的干货知识点与面试方法,力求让读者在获得心仪offer的同时,增强技术基本面。也欢迎大家提出宝贵的优化建议,一起交流学习💪
欢迎大家关注Rocky的公众号:WeThinkIn
欢迎大家关注Rocky的知乎:Rocky Ding
AIGC算法工程师面试面经秘籍分享:WeThinkIn/Interview-for-Algorithm-Engineer欢迎大家Star~
获取更多AI行业的前沿资讯与干货资源
大家好,我是Rocky。
《三年面试五年模拟》系列作品帮助很多读者获得了心仪的算法岗offer,收到了大家的很多好评,Rocky觉得很开心也很有意义。
在AIGC时代到来后,Rocky对《三年面试五年模拟》整体战略方向进行了重大的优化重构,在秉持着Rocky创办《三年面试五年模拟》项目初心的同时,增加了AIGC时代核心的版块栏目,详细的版本更新内容如下所示:
- 整体架构:分为AIGC知识板块和AI通用知识板块。
- AIGC知识板块:分为AI绘画、AI视频、大模型、AI多模态、数字人这五大AIGC核心方向。
- AI通用知识板块:包含AIGC、传统深度学习、自动驾驶等所有AI核心方向共通的知识点。
Rocky已经将《三年面试五年模拟》项目的完整版构建在Github上:https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer/tree/main,欢迎大家star!
本文是《三年面试五年模拟》项目的第十六式,考虑到易读性与文章篇幅,Rocky本次只从Github完整版项目中摘选了2024年6月10号-2024年6月23号更新的部分经典&干货面试知识点和面试问题,并配以相应的参考答案(精简版),供大家学习探讨。
在《三年面试五年模拟》版本更新白皮书,迎接AIGC时代中我们阐述了《三年面试五年模拟》项目在AIGC时代的愿景与规划,也包含了项目共建计划,感兴趣的朋友可以一起参与本项目的共建!
当然的,本项目中的内容难免有疏漏与错误之处,欢迎大家在文末评论进行补充优化,Rocky将及时更新完善到Github上!
希望《三年面试五年模拟》能陪伴大家度过整个AI行业的职业生涯,并且让大家能够持续获益。
So,enjoy(与本文的BGM一起食用更佳哦):
正文开始
目录先行
AI绘画基础:
-
目前主流的AI绘画框架有哪些?
-
FaceChain的训练和推理流程是什么样的?
AI视频基础:
-
目前主流的AI视频技术框架有哪几种?
-
目前主流的AI视频大模型有哪些?
深度学习基础:
-
什么是Scaling-Law?
-
为什么Transformer的Scaling能力比CNN强?
机器学习基础:
-
什么是AutoML?
-
什么是PEFT技术?
Python编程基础:
-
Python中函数传参时会改变参数本身吗?
-
什么是python的全局解释器锁GIL?
模型部署基础:
-
目前主流的端侧算力芯片有哪些种类?
-
什么是GPU内存带宽?
计算机基础:
-
计算机中同步调用和异步调用有哪些区别?
-
计算机中串行操作和并行操作有哪些区别?
开放性问题:
-
在哪些维度深耕能增强算法工程师的核心竞争力?
-
AI产品和AI算法解决方案涵盖的研发岗位有哪些?
AI绘画基础
【一】目前主流的AI绘画框架有哪些?
Rocky从AIGC时代的工业界、应用界、竞赛界以及学术界出发,总结了目前主流的AI绘画框架:
- Diffusers:
diffusers库提供了一整套用于训练、推理和评估扩散模型的工具。它的设计目标是简化扩散模型的使用和实验,并提供与Hugging Face生态系统的无缝集成,包括其Transformers库和Datasets库。在AIGC时代中,每次里程碑式的模型发布后,Diffusers几乎都在第一时间进行了原生支持。

- Stable Diffusion WebUI:
Stable Diffusion Webui是一个基于Gradio框架的GUI界面,可以方便的使用Stable Diffusion系列模型,使用户能够轻松的进行AI绘画。
- ComfyUI:
ComfyUI也是一个基于Gradio框架的GUI界面,与Stable Diffusion WebUI不同的是,ComfyUI框架中侧重构建AI绘画节点和工作流,用户可以通过连接不同的节点来设计和执行AI绘画功能。
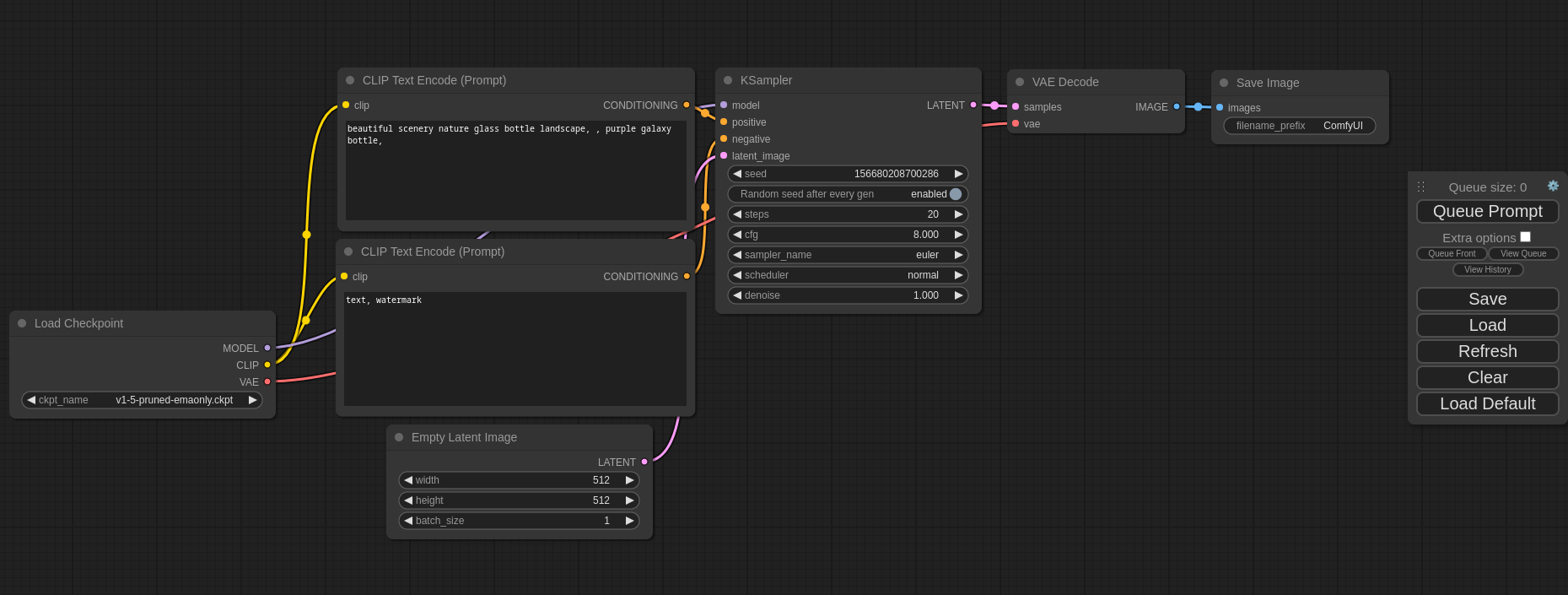
- SD.Next:
SD.Next基于Stable Diffusion WebUI开发,构建提供了更多高级的功能。在支持Stable Diffusion的基础上,还支持Kandinsky、DeepFloyd IF、Lightning、Segmind、Kandinsky、Pixart-α、Pixart-Σ、Stable Cascade、Würstchen、aMUSEd、UniDiffusion、Hyper-SD、HunyuanDiT等AI绘画模型的使用。
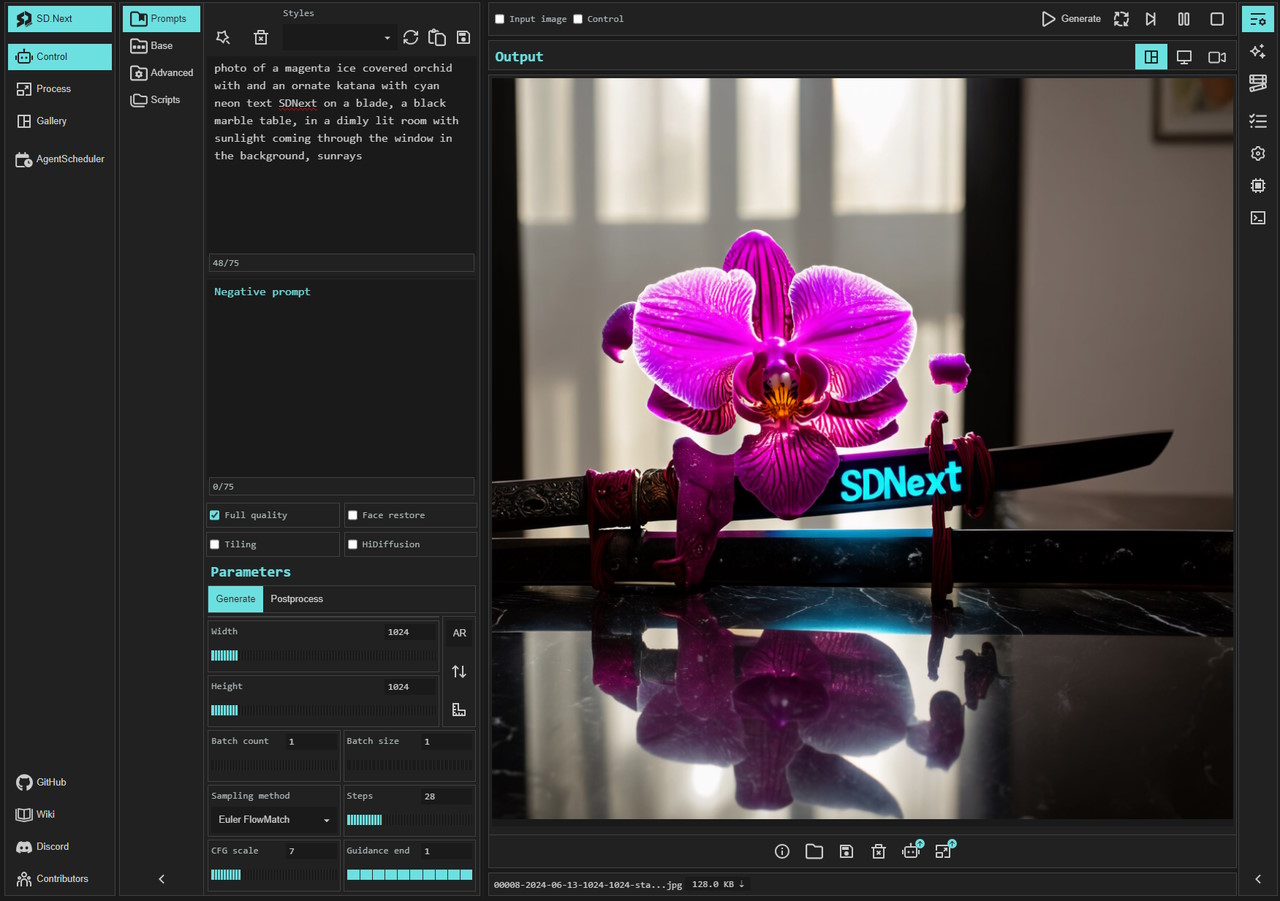
- Fooocus:
Fooocus也是基于Gradio框架的GUI界面,Fooocus借鉴了Stable Diffusion WebUI和Midjourney的优势,具有离线、开源、免费、无需手动调整、用户只需关注提示和图像等特点。
【二】FaceChain的训练和推理流程是什么样的?
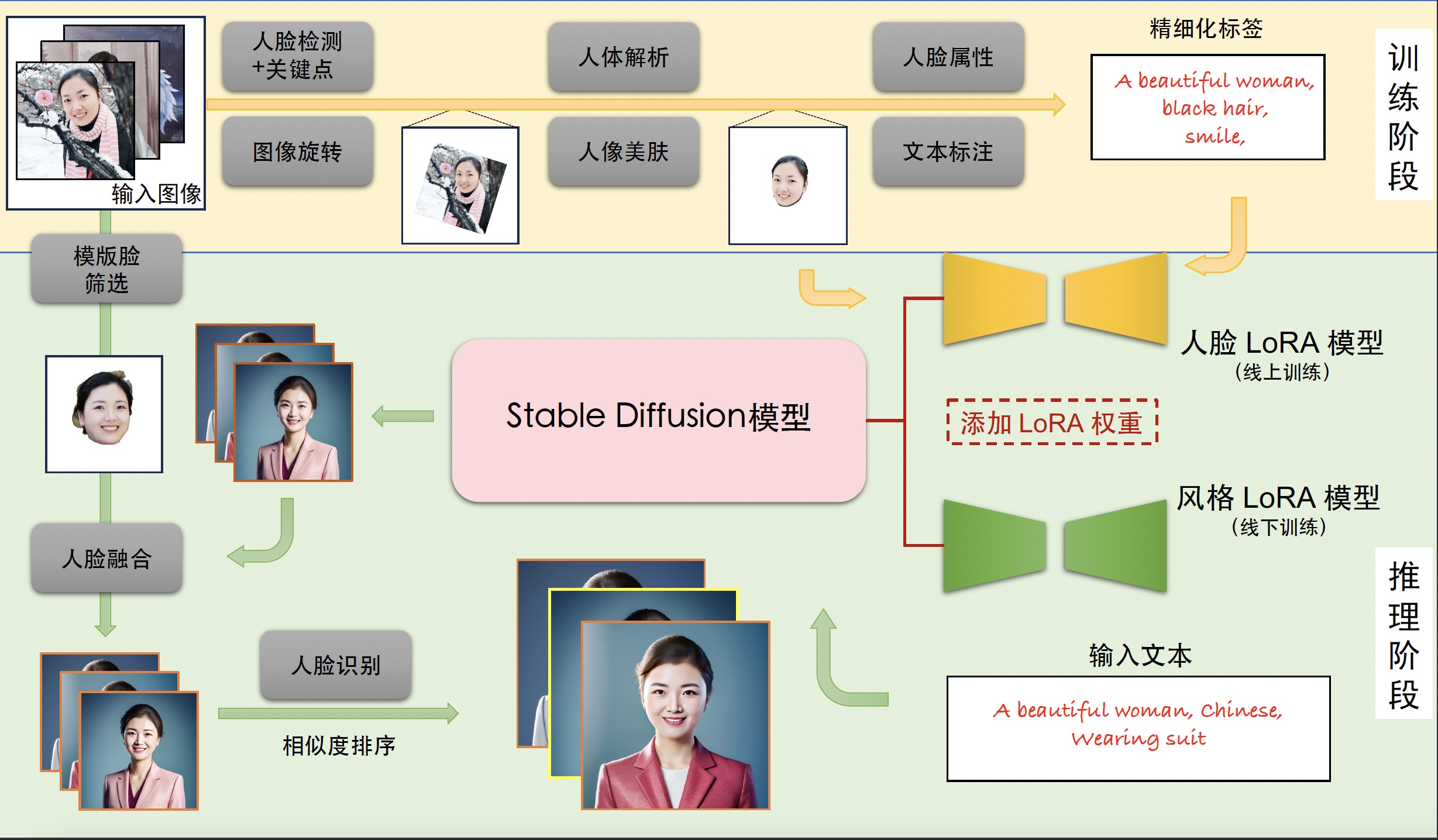
FaceChain是一个功能上近似“秒鸭相机”的技术,我们只需要输入几张人脸图像,FaceChain技术会帮我们合成各种服装、各种场景下的AI数字分身照片。下面Rocky就给大家梳理一下FaceChain的训练和推理流程:
训练阶段
- 输入包含清晰人脸区域的图像。
- 使用基于朝向判断的图像旋转模型+基于人脸检测和关键点模型的人脸精细化旋转方法来处理人脸图像,获取包含正向人脸的图像。
- 使用人体解析模型+人像美肤模型,获得高质量的人脸训练图像。
- 使用人脸属性模型和文本标注模型,再使用标签后处理方法,生成训练图像的精细化标签。
- 使用上述图像和标签数据微调Stable Diffusion模型得到人脸LoRA模型。
- 输出人脸LoRA模型。
推理阶段
- 输入训练阶段的训练图像。
- 设置用于生成个人写真的Prompt提示词。
- 将人脸LoRA模型和风格LoRA模型的权重融合到Stable Diffusion模型中。
- 使用Stable Diffusion模型的文生图功能,基于设置的输入提示词初步生成AI个人写真图像。
- 使用人脸融合模型进一步改善上述写真图像的人脸细节,其中用于融合的模板人脸通过人脸质量评估模型在训练图像中挑选。
- 使用人脸识别模型计算生成的写真图像与模板人脸的相似度,以此对写真图像进行排序,并输出排名靠前的个人写真图像作为最终输出结果。
AI视频基础
【一】目前主流的AI视频技术框架有哪几种?
Rocky梳理总结了AIGC时代到目前为止主流的AI视频技术框架,市面上的所有AI视频产品基本上都是基于以下这些框架:
- 文本生成视频:输入文本,先生成图片或者直接生成视频。主要流程包括工作流前处理+扩散模型+运动模块+条件控制+工作流后处理。
- 图像生成视频:输入图像,先生成前后帧图像,然后使用插帧与语义扩展持续生成前后序列帧图像,最后生成完整视频。主要流程包括工作流前处理+扩散模型+运动模块+条件控制+工作流后处理。
- 视频生成视频:输入视频,提取关键帧,对关键帧进行转绘,然后再进行插帧,从而生成新的视频。主要流程包括工作流前处理+扩散模型+运动模块+条件控制+工作流后处理。
【二】目前主流的AI视频大模型有哪些?
Rocky为大家梳理总结了AIGC时代到目前为主的主流AI视频大模型,如下所示:
- Stable Video Diffusion(SVD)系列
- Sora
- 可灵AI
- LUMA
- Gen系列
- Stable Diffusion系列 + Animatediff
深度学习基础
【一】什么是Scaling-Law?
Scaling Law(缩放法则)是指在AI领域中,描述模型性能如何随着模型规模(如参数数量、训练数据量、计算资源等)变化而变化的一组经验法则。缩放法则提供了一种定量的方式来理解和预测模型在不同规模下的表现,从而帮助AI领域算法研究员和算法工程师设计和优化更大规模的AI模型。
缩放法则的基本形式:Scaling Law的具体形式通常包括模型参数数量、训练数据量和计算资源三个方面,每个方面的缩放法则可以通过经验公式来描述。
1. 参数数量与性能
模型的性能通常随着参数数量的增加而提升。假设模型的损失函数 L L L 与参数数量 N N N 的关系如下:
L ( N ) = a N − b + c L(N) = aN^{-b} + c L(N)=aN−b+c
其中, a a a 、 b b b 和 c c c 是拟合得到的常数。这个公式表明,随着参数数量 N N N 的增加,损失函数 L L L 会按照一定的规律减小。
2. 数据量与性能
类似地,模型性能也会随着训练数据量的增加而提升。假设模型的损失函数 L L L 与训练数据量 D D D 的关系如下:
L ( D ) = a D − b + c L(D) = aD^{-b} + c L(D)=aD−b+c
其中, a a a 、 b b b 和 c c c 是拟合得到的常数。这个公式表明,随着训练数据量 D D D 的增加,损失函数 L L L 会按照一定的规律减小。
3. 计算资源与性能
模型的性能也会随着计算资源(如训练时间和计算能力)的增加而提升。假设模型的损失函数 L L L 与计算资源 C C C 的关系如下:
L ( C ) = a C − b + c L(C) = aC^{-b} + c L(C)=aC−b+c
其中, a a a 、 b b b 和 c c c 是拟合得到的常数。这个公式表明,随着计算资源 C C C 的增加,损失函数 L L L 会按照一定的规律减小。
Scaling Law 的实例研究
OpenAI 的研究人员在论文《Scaling Laws for Neural Language Models》中详细探讨了这些缩放法则。他们发现,对于AI语言模型,损失函数 L L L 与参数数量 N N N、训练数据量 D D D 以及计算量 C C C 之间存在如下关系:
L ( N , D , C ) = ( N N 0 ) − a + ( D D 0 ) − b + ( C C 0 ) − c + L 0 L(N, D, C) = \left( \frac{N}{N_0} \right)^{-a} + \left( \frac{D}{D_0} \right)^{-b} + \left( \frac{C}{C_0} \right)^{-c} + L_0 L(N,D,C)=(N0N)−a+(D0D)−b+(C0C)−c+L0
其中, a a a 、 b b b 、 c c c 、 N 0 N_0 N0 、 D 0 D_0 D0 、 C 0 C_0 C0 和 L 0 L_0 L0 是通过实验拟合得到的常数。
Scaling Law 的实际应用
-
设计更大规模的模型
- 缩放法则可以指导研究人员如何设计和训练更大规模的模型,以实现更高的性能。例如,在设计GPT-3时,研究人员根据缩放法则预测了在不同规模下模型的性能,并进行了相应的设计和优化。
-
优化资源分配
- 缩放法则帮助决策者在资源有限的情况下做出更好的决策。例如,确定是否应增加模型参数数量、增加训练数据量,还是增加计算资源,以实现最优的性能提升。
-
预测性能
- 根据现有模型的性能和缩放法则,可以预测更大规模模型的性能。这对于规划研究和开发路线图非常有用。
缩放法则的优势与挑战
优势
- 指导大规模模型的设计:通过缩放法则,可以合理预测不同规模下模型的性能,从而指导大规模模型的设计。
- 优化资源使用:缩放法则可以帮助在资源有限的情况下,合理分配资源以最大化性能提升。
- 性能预测:可以根据现有数据和经验法则,预测更大规模模型的性能。
挑战
- 参数拟合:缩放法则的精确形式和参数需要通过大量实验数据来拟合和验证。
- 适用范围:缩放法则通常基于特定任务和模型,对于不同任务和模型可能需要调整和重新验证。
- 资源需求:验证和应用缩放法则本身需要大量的计算资源和实验数据。
总结
Scaling Laws(缩放法则)在AI领域中提供了一种定量的方法,描述了模型性能如何随着模型规模的扩展而变化。通过理解和应用缩放法则,我们可以更有效地设计、训练和优化大规模模型,推动AI技术的发展和应用。
【二】为什么Transformer的Scaling能力比CNN强?
Transformer模型的Scaling能力比卷积神经网络(CNN)强,主要原因在于Transformer的架构设计能够更有效地利用增加的参数、数据和计算资源。这些特性使得Transformer在大规模数据和模型训练中表现出色,特别是在AIGC时代的生成式模型中。以下是Transformer相对于CNN在Scaling能力上的几个关键优势:
1. 全局注意力机制
Transformer:
- 全局上下文捕捉:Transformer的自注意力机制(Self-Attention Mechanism)能够在计算每个位置的表示时考虑整个输入序列的所有位置。这使得Transformer可以捕捉长距离的依赖关系和全局上下文信息。
- 灵活性:由于自注意力机制的全局特性,Transformer可以灵活处理不同长度的输入数据,而不受局部感受野的限制。
CNN:
- 局部感受野:CNN依赖于卷积核的局部感受野,在处理长距离依赖关系时需要多层卷积和池化操作,这使得捕捉全局信息变得困难。
- 层数依赖:为了捕捉全局特征,CNN需要堆叠更多层,这增加了模型复杂度和计算成本。
2. 可并行化计算
Transformer:
- 完全并行化:Transformer的自注意力机制允许在计算每个位置的表示时进行完全并行化,这显著提高了计算效率。所有位置的表示可以同时计算,这对GPU等并行计算设备非常友好。
- 训练速度:由于可以并行计算,Transformer在处理大规模数据集时具有更快的训练速度。
CNN:
- 层级依赖:CNN的卷积操作是层级依赖的,即每一层的输出是下一层的输入,这导致并行化受限,需要逐层计算。
- 计算效率:尽管卷积操作本身可以并行计算,但整体的层级依赖限制了并行化的效率。
3. 参数效率
Transformer:
- 参数共享:自注意力机制中的参数共享使得Transformer可以在增加参数的同时高效地捕捉全局信息。这使得增加参数量对模型性能的提升更加明显。
- 灵活的层数扩展:Transformer可以通过增加层数和注意力头数来灵活扩展模型,而这种扩展通常能够显著提升模型性能。
CNN:
- 卷积核的限制:CNN的参数量主要受卷积核大小和层数的限制。增加卷积核大小和层数会显著增加计算复杂度和参数量,但性能提升不一定明显。
- 局部参数:卷积核参数是局部的,对全局信息的捕捉有限,参数效率较低。
4. 处理复杂依赖关系
Transformer:
- 复杂依赖关系:Transformer的自注意力机制能够自然地处理复杂的依赖关系,包括长距离和跨模态的依赖。这使得Transformer在处理复杂任务时具有优势,如多任务学习和多模态数据处理。
- 多头注意力:多头注意力机制允许模型在不同的子空间中学习不同的特征,这进一步增强了模型捕捉复杂依赖关系的能力。
CNN:
- 局部特征捕捉:CNN擅长捕捉局部特征,对于处理长距离和复杂依赖关系有一定的局限性。
- 层次结构:尽管通过层次结构可以逐步捕捉更高层次的特征,但处理复杂依赖关系仍然需要大量层数和参数。
机器学习基础
【一】什么是AutoML?
AutoML(Automated Machine Learning)是指通过自动化技术来简化和加速机器学习模型开发、优化和部署的过程。AutoML技术的目标是让我们能够轻松构建高性能的机器学习模型,而不需要具备深厚的AI专业知识。以下是Rocky对AutoML的详细讲解:
一、AutoML的基本概念
-
自动化数据预处理
- 数据清洗:处理缺失值、异常值和重复数据。
- 特征工程:自动化数据增强、特征选择、数据优化等。
- 数据分割:自动化数据集划分为训练集、验证集和测试集。
-
自动化模型选择
- 算法选择:根据数据集特点自动选择适合的AI模型,如CNN、Transformer、扩散模型、自回归模型等。
- 超参数调优:自动搜索最佳的超参数组合,如学习率、正则化参数、迭代次数等。
-
自动化模型训练和评估
- 模型训练:自动化训练模型并评估其性能。
- 模型评估:自动选择评估指标(如准确率、精确率、召回率、F1分数等)并优化模型。
-
自动化模型部署
- 模型导出:自动化将训练好的模型导出为可部署的格式。
- 模型部署:自动化将模型部署到生产环境中进行预测服务。
二、AutoML的核心技术
- 超参数优化(Hyperparameter Optimization, HPO)
- 神经架构搜索(Neural Architecture Search, NAS)
- 自动特征工程(Automated Feature Engineering)
- 模型集成(Model Ensemble)
三、AutoML的优缺点
优点:
- 简化机器学习流程:降低了模型开发的门槛,使非专家用户也能构建高性能模型。
- 提高生产效率:减少了模型开发时间和成本,快速迭代模型。
- 自动化优化:通过自动化超参数调优和架构搜索,提升模型性能。
缺点:
- 计算资源消耗:自动化搜索和调优过程可能需要大量计算资源。
- 解释性不足:自动生成的模型和特征可能难以解释,影响透明度。
四、AutoML的应用领域
- AIGC
- 传统深度学习
- 自动驾驶
总结
AutoML通过自动化数据预处理、模型选择、超参数调优、模型训练和部署,极大地简化了机器学习模型的开发过程,提高了模型的性能和开发效率。虽然仍存在一些挑战和限制,但随着技术的不断进步,AutoML在各个领域的应用前景十分广阔,将推动AI领域的持续发展。
【二】什么是PEFT技术?
PEFT(Parameter-Efficient Fine-Tuning,参数高效微调)是一种在AI模型上进行微调的技术,旨在提高模型在小样本数据上的性能,同时减少训练和推理的计算资源消耗。PEFT技术通过仅更新模型的一部分参数或通过使用更高效的参数更新策略来达到这些目标。以下是Rocky对PEFT技术的详细讲解:
我们为什么需要PEFT技术
在实际应用中,深度学习模型往往需要针对特定任务或数据集进行微调。然而,微调整个模型的所有参数不仅计算成本高,而且容易导致过拟合,特别是在训练数据有限的情况下。PEFT 通过优化参数更新策略,可以在保持高性能的同时显著减少计算资源需求。
PEFT的主要方法
PEFT包括多种具体的方法和策略,以下是一些常见的PEFT技术:
1. 微调部分层(Layer-wise Fine-Tuning)
概述:仅微调模型的某些特定层,而保持其他层的参数不变。
方法:
- 冻结部分层:在训练过程中保持某些层的参数固定,只更新特定层的参数。
- 选择性微调:根据任务的需求和模型的特性,选择重要或高层次的层进行微调。
优点:减少计算量和过拟合风险,同时保留模型的预训练知识。
2. 低秩分解(Low-Rank Factorization)
概述:将模型参数矩阵分解为几个低秩矩阵,只更新低秩矩阵的参数。
方法:
- 使用奇异值分解(SVD)等分解技术,将高维参数矩阵分解为低秩矩阵。
- 在训练过程中,只更新这些低秩矩阵的参数。
优点:减少参数数量和计算复杂度,提高训练效率。
3. 子网络选择(Subnetwork Selection)
概述:从预训练模型中选择一个子网络进行微调,而不改变整个模型。
方法:
- Lottery Ticket Hypothesis:通过训练,发现预训练模型中存在一个子网络(Lottery Ticket),能够在小样本情况下表现良好。
- 激活特定子网络:在训练和推理过程中,仅激活并微调模型的某些子网络。
优点:充分利用预训练模型的潜力,减少计算资源需求。
4. 权重共享和参数重用(Weight Sharing and Parameter Reuse)
概述:在模型中共享权重或重用参数,以减少训练和推理的计算量。
方法:
- 在多任务学习中,多个任务共享部分模型参数。
- 使用权重共享技术,如Transformer中的共享注意力头。
优点:提高参数利用率,减少模型参数数量。
PEFT的应用场景
- AIGC
- 传统深度学习
- 自动驾驶
PEFT 的优势和挑战
优势
- 减少计算资源需求:通过只更新一部分参数,显著减少训练和推理的计算资源需求。
- 提高训练效率:通过参数高效更新策略,加快模型的训练速度。
- 减少过拟合风险:在小样本数据上训练时,减少过拟合的风险,提高模型的泛化能力。
挑战
- 选择合适的策略:需要根据具体任务和数据特点,选择合适的PEFT策略。
- 模型复杂性:某些PEFT方法可能会增加模型的实现复杂性,需要更多的工程实践。
- 参数调优:需要精细调优模型参数和训练超参数,以达到最佳效果。
PEFT技术实际案例
以下是一个简单的示例,展示我们如何应用PEFT技术进行模型微调:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
# 加载预训练模型
model = models.resnet50(pretrained=True)
# 冻结所有层的参数
for param in model.parameters():
param.requires_grad = False
# 替换最后的全连接层
model.fc = nn.Linear(model.fc.in_features, 10) # 假设有10个分类
# 仅微调最后的全连接层
optimizer = optim.Adam(model.fc.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
# 加载数据
transform = transforms.Compose([transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor()])
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True)
# 训练模型
model.train()
for epoch in range(10): # 假设训练10个epoch
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print("微调完成")
在这个示例中,我们加载了一个预训练的ResNet 50模型,仅微调了最后的全连接层以适应新的分类任务(CIFAR-10数据集)。通过冻结其他层的参数,我们实现了PEFT,提高了训练效率并减少了过拟合风险。
总结
PEFT(参数高效微调)技术通过优化参数更新策略,在保持模型性能的同时,显著减少了计算资源需求和过拟合风险。PEFT在AIGC、传统深度学习、自动驾驶等领域具有广泛应用前景。选择合适的PEFT策略并进行精细调优,可以让我们在小样本数据上实现高效且高性能的模型微调。
Python编程基础
【一】Python中函数传参时会改变参数本身吗?
在Python中,函数传参是否会改变参数本身取决于参数的数据类型和传递方式。这涉及到Python的参数传递机制,通常被称为“传引用的值”(pass-by-reference value)或者“传对象引用”(pass-by-object-reference)。这里的一些基本规则和示例将帮助大家理解这一概念:
可变与不可变对象
-
不可变对象:包括整数、浮点数、字符串、元组等。这些类型的数据不允许被修改。
- 当我们传递一个不可变对象给函数时,虽然函数内部可以使用这个对象的值,但任何试图改变该对象的操作都将在本地创建一个新对象。外部原始对象不会被改变。
def modify(x): x = 10 return x a = 5 modify(a) print(a) # 输出 5,原始值未改变 -
可变对象:包括列表、字典、集合等。这些类型的数据可以被修改。
- 当你传递一个可变对象给函数时,函数内部对这个对象的任何修改都会反映到原始对象上。
def modify(lst): lst.append(3) my_list = [1, 2] modify(my_list) print(my_list) # 输出 [1, 2, 3],原始列表被修改
函数参数的工作方式
- 在Python中,所有的函数参数都是按“引用传递”的。但实际上,这意味着当对象传递给函数时,传递的是对象的引用(内存地址),而不是对象的实际拷贝。对于不可变对象,由于不能被改变,所以任何修改都会导致创建一个新的本地对象;而对于可变对象,则可以在原地址上进行修改。
- 对于列表和字典这样的可变对象,如果你不希望函数中的操作影响到原始数据,你可以传递一个拷贝给函数,而不是原始对象本身。
import copy
def modify(lst):
lst.append(3)
original_list = [1, 2]
new_list = copy.deepcopy(original_list)
modify(new_list)
print(original_list) # 输出 [1, 2]
print(new_list) # 输出 [1, 2, 3]
总结
在Python中,函数的行为取决于传入参数的类型。不可变对象(如整数、字符串和元组)不会在函数调用中被修改,而可变对象(如列表和字典)可以被修改。了解这些差异有助于我们更好地管理函数中数据的状态和行为。
【二】什么是python的全局解释器锁GIL?
在Python中,全局解释器锁(Global Interpreter Lock,简称GIL)是一个重要的概念,特别是在涉及多线程执行时。GIL 是一个互斥锁,保证同一时间内只有一个线程可以执行Python字节码。简而言之,尽管在多核处理器上运行,Python 的标准实现 CPython 在执行多线程应用时,并不能有效地利用多核处理器的优势。
GIL 的目的
- 简化内存管理:CPython 使用引用计数来管理内存,这种方法在多线程环境中容易产生问题。GIL 通过确保一次只有一个线程运行,避免了常见的并发访问问题,如竞态条件。
- 保护CPython的内部数据结构:没有GIL,程序员必须采用其他并发控制技术,如细粒度锁,这可能会使CPython的实现更复杂。
GIL 的影响
尽管GIL简化了内存管理和内部数据结构的保护,但它也限制了Python程序在多核处理器上的并行执行能力:
- 多线程局限性:在CPU密集型程序中,GIL成为性能瓶颈,因为线程不能在多个CPU核心上同时执行计算任务。
- I/O密集型应用的表现更好:I/O操作不需要大量CPU计算,线程可能会在等待I/O操作完成时释放GIL,从而让其他线程有机会执行。
绕过GIL
虽然GIL在多线程编程中存在局限性,但Python社区提供了多种方法来绕过这些限制:
- 使用多进程:通过
multiprocessing模块,可以创建多个进程,每个进程拥有自己的Python解释器和内存空间,从而不受GIL的限制。 - 使用其他实现:如Jython和IronPython,这些Python实现没有GIL,可以更好地利用多核处理器。
- 使用特定库:一些库设计可以在底层进行多线程或多进程操作,从而绕过GIL的限制,例如NumPy和其他与C语言库交互的扩展。
模型部署基础
【一】目前主流的端侧算力芯片有哪些种类?
AI端侧算力设备(如NPU、TPU、VPU、FPGA等)目前正在快速发展,这些设备专门设计用于加速AIGC、传统深度学习、自动驾驶等领域任务。它们在性能和效率方面大大超过了传统的CPU和GPU。以下是Rocky对这些AI端侧算力的详细介绍:
1. NPU(Neural Processing Unit)
NPU,即神经处理单元,是一种专门用于加速神经网络计算的处理器。NPU通常集成在移动设备、物联网设备和其他嵌入式系统中,以提升AI应用的性能。
特点与优势:
- 高效能耗比:NPU在进行神经网络计算时具有高能效,适用于资源受限的设备。
- 专用硬件设计:为了优化矩阵运算和卷积操作,NPU设计了专门的硬件加速器。
- 实时处理:NPU能实现低延迟的实时AI推理,非常适合智能手机、摄像头等需要实时处理的设备。
- 集成性强:NPU常与其他处理单元(如CPU、GPU)集成在同一个芯片上(如SoC),以提供全面的计算能力。
2. TPU(Tensor Processing Unit)
TPU,即张量处理单元,是Google开发的一种专用AI加速器,主要用于加速TensorFlow框架下的机器学习任务。
特点与优势:
- 高性能:TPU能够提供极高的计算能力,特别是在处理大规模矩阵运算和深度学习模型训练时。
- 定制化设计:TPU为特定的AI工作负载(如矩阵乘法、卷积运算)进行了优化,显著提升了性能。
- 大规模部署:TPU被广泛部署在Google的数据中心,用于支持Google的各项AI服务,如搜索、广告、翻译等。
版本和架构:
- TPU v1:主要用于推理任务,每秒可执行92万亿次浮点运算(92 TFLOPS)。
- TPU v2和TPU v3:增强了训练能力,分别具有每秒180 TFLOPS和420 TFLOPS的计算能力。
- TPU v4:最新版本,进一步提升了性能和能效,适用于更大规模、更复杂的AI任务。
3. VPU(Vision Processing Unit)
VPU,即视觉处理单元,是一种专门设计用于计算机视觉和人工智能任务的处理器。VPUs的主要目标是以高效的能耗比处理复杂的视觉计算任务,适用于各种嵌入式和边缘设备。
特点与优势:
- VPU专注于低功耗的计算机视觉任务,适用于嵌入式系统和边缘设备。
- 提供高效的图像处理和神经网络推理能力。
4. FPGA(Field Programmable Gate Array)
FPGA,即现场可编程门阵列,是一种高度可编程的集成电路,可以根据特定应用的需求重新配置其硬件电路。FPGA在AI和机器学习中广泛应用于需要高灵活性和低延迟的任务。
特点与优势:
- FPGA具有高度灵活性,可根据需求重新配置电路结构。
- 提供较低的延迟和高效的能耗比,适用于特定AI任务的加速。
- 能够实现高度并行计算,适用于实时处理应用。
5. Huawei Ascend
华为昇腾系列AI处理器包括适用于云端和边缘计算的多种型号,提供高性能的AI计算能力。
特点与优势:
- 华为的昇腾系列AI芯片,包括适用于云端和边缘计算的不同版本,如Ascend 910(高性能)和Ascend 310(边缘计算)。
- 提供高度集成的AI计算能力,支持多种AI框架和模型。
6. Graphcore IPU(Intelligence Processing Unit)
Graphcore IPU是一种专门设计用于机器智能任务的处理器,采用全新的计算架构,优化了计算和内存访问。
特点与优势:
- IPU专为机器智能任务设计,采用了全新的计算架构,优化了计算和内存访问。
- 能够高效处理稀疏计算和动态计算图,适用于复杂的AI模型。
总结
这些AI端侧设备显著提升了AIGC、传统深度学习、自动驾驶任务的性能和能效,推动了AI技术的快速发展和应用扩展。不同的加速器在设计上各有侧重,适用于不同的应用场景,满足了多样化的AI计算需求。
【二】什么是GPU内存带宽?
GPU内存带宽(Memory Bandwidth)是指GPU从其内存 (vRAM)中读取或写入数据的速度,通常以每秒千兆字节(GB/s)为单位。这一指标非常重要,因为它直接影响到GPU在处理复杂计算任务时的数据传输效率,进而影响整体性能。
内存带宽的组成
GPU内存带宽由以下几个部分组成:
- 时钟频率:内存的工作频率,通常以MHz或GHz为单位。更高的频率意味着更快的数据传输速度。
- 内存总线宽度:内存总线的宽度,通常以位(bits)为单位。常见的总线宽度有256位、384位等。总线越宽,数据传输能力越强。
- 内存类型:不同类型的显存(如GDDR5、GDDR6、HBM等)具有不同的性能和效率。新型内存通常具有更高的频率和更宽的总线。
计算公式
内存带宽的计算公式为:
内存带宽 = 内存频率 × 总线宽度 × 数据传输速率 \text{内存带宽} = \text{内存频率} \times \text{总线宽度} \times \text{数据传输速率} 内存带宽=内存频率×总线宽度×数据传输速率
对于双倍数据速率(DDR)的内存,每个时钟周期传输两次数据,因此数据传输速率为2。
举个例子,如果一个GPU使用GDDR6显存,频率为1750 MHz,总线宽度为256位,那么它的内存带宽计算如下:
内存带宽 = 1750 MHz × 256 bits × 2 / 8 (bits to bytes) = 112 GB/s \text{内存带宽} = 1750 \, \text{MHz} \times 256 \, \text{bits} \times 2 / 8 \, \text{(bits to bytes)} = 112 \, \text{GB/s} 内存带宽=1750MHz×256bits×2/8(bits to bytes)=112GB/s
内存带宽的重要性
内存带宽对于GPU的性能至关重要,尤其是在以下应用场景中:
- 高性能计算(HPC):在进行科学计算、金融建模等高性能计算任务时,内存带宽影响数据的快速传输和处理。
- 图形渲染:复杂的图形渲染任务,如实时光线追踪(Ray Tracing),需要高带宽来处理大量的纹理和图像数据。
- AI领域(AIGC、传统深度学习、自动驾驶):训练和推理AI模型需要频繁访问大量数据,高内存带宽可以提高训练速度和推理效率。
Rocky认为我们通过理解和优化GPU内存带宽,可以显著提升计算任务的效率和性能,尤其在高要求的AI模型训练与推理任务中尤为重要。
计算机基础
Rocky从工业界、应用界、竞赛界以及学术界角度出发,总结沉淀AI行业中需要用到的实用计算机基础知识,不仅能在面试中帮助到我们,还能让我们在日常工作中提高效率。
【一】计算机中同步调用和异步调用有哪些区别?
在计算机编程中,同步调用和异步调用是两种处理任务的方式,它们在处理任务的机制、使用场景和效率上有显著的区别。Rocky认为我们了解这两种调用方式的区别对于编写高效、响应迅速的程序非常重要。
同步调用
定义
同步调用是一种阻塞的调用方式。在执行同步调用时,程序会等待调用的任务完成之后再继续执行后续的代码。也就是说,在同步调用中,任务是按顺序执行的,前一个任务完成后才会执行下一个任务。
特点
- 阻塞:调用线程会被阻塞,直到任务完成。
- 简单直观:代码执行顺序与编写顺序一致,易于理解和调试。
- 适用于简单任务:在不需要并发处理的简单任务中,同步调用更直观。
示例
假设我们有一个函数 do_task,需要执行两次任务,每次任务耗时2秒。
import time
def do_task(task_name):
print(f"Starting {task_name}")
time.sleep(2) # 模拟任务耗时
print(f"Finished {task_name}")
# 同步调用
do_task("Task 1")
do_task("Task 2")
在上述代码中,Task 2 只有在 Task 1 完成后才会开始执行。
异步调用
定义
异步调用是一种非阻塞的调用方式。在执行异步调用时,程序不必等待任务完成便可以继续执行后续的代码。异步调用通常使用回调函数、Promise(如 JavaScript 中的 Promise)、Future 或 async/await 机制来处理任务完成后的操作。
特点
- 非阻塞:调用线程不会被阻塞,可以继续执行其他任务。
- 并发处理:可以同时处理多个任务,提高程序的响应速度和效率。
- 更复杂:异步编程相对复杂,需要处理回调、事件循环等机制。
示例
使用 Python 中的 asyncio 库实现异步调用:
import asyncio
async def do_task(task_name):
print(f"Starting {task_name}")
await asyncio.sleep(2) # 模拟异步任务耗时
print(f"Finished {task_name}")
# 异步调用
async def main():
await asyncio.gather(
do_task("Task 1"),
do_task("Task 2")
)
# 运行异步任务
asyncio.run(main())
在上述代码中,Task 1 和 Task 2 是同时启动的,并且在2秒后几乎同时完成。
同步与异步的区别总结
-
执行顺序:
- 同步调用:任务按顺序执行,前一个任务完成后才会执行下一个任务。
- 异步调用:任务可以同时启动,程序可以在等待任务完成期间执行其他操作。
-
阻塞行为:
- 同步调用:调用线程被阻塞,直到任务完成。
- 异步调用:调用线程不会被阻塞,可以继续执行其他任务。
-
效率和响应速度:
- 同步调用:适用于简单、顺序的任务,易于理解和调试。
- 异步调用:适用于需要并发处理的任务,提高程序的效率和响应速度,但编程复杂度较高。
-
复杂度:
- 同步调用:代码逻辑直观,容易调试和维护。
- 异步调用:需要处理回调、事件循环等机制,复杂度较高,但能显著提高性能。
使用场景
-
同步调用:
- 适用于简单的任务顺序执行,如读取本地文件、顺序执行的计算任务等。
- 当程序不需要处理并发任务,且性能要求不高时,使用同步调用更为合适。
-
异步调用:
- 适用于需要高并发处理的场景,如网络请求、I/O 操作、并行计算等。
- 当程序需要在等待某些任务(如网络请求、数据库查询)时继续执行其他任务,异步调用能够显著提高效率和响应速度。
理解同步调用和异步调用的区别,有助于我们在合适的场景下选择合适的编程模式,编写出高效、可靠的程序。
【二】计算机中串行操作和并行操作有哪些区别?
计算机中的串行和并行操作是两种处理任务的方式,它们在任务执行的顺序、效率和应用场景上有显著的区别。Rocky认为我们理解这两种操作模式有助于设计和优化计算机程序,以提高性能和效率。
串行操作
定义
串行操作是一种按顺序执行任务的方式。每个任务必须在前一个任务完成之后才能开始执行,这意味着任务是一个接一个地进行,没有重叠。
特点
- 顺序执行:任务按先后顺序逐一执行。
- 简单直观:代码逻辑清晰,容易编写和调试。
- 无竞争条件:因为只有一个任务在运行,不会发生资源竞争或冲突。
示例
假设我们有三个任务:Task 1、Task 2 和 Task 3,它们必须按顺序执行。
def task1():
print("Executing Task 1")
def task2():
print("Executing Task 2")
def task3():
print("Executing Task 3")
# 串行执行
task1()
task2()
task3()
在上述代码中,Task 1 完成后才会开始 Task 2,然后是 Task 3。
优缺点
-
优点:
- 实现简单,逻辑清晰。
- 易于调试和维护。
-
缺点:
- 处理大量任务时效率低。
- 不能充分利用多核处理器的计算能力。
并行操作
定义
并行操作是一种同时执行多个任务的方式,通常利用多核处理器或多台计算机来同时处理多个任务,从而提高效率。
特点
- 同时执行:多个任务可以同时开始并执行。
- 复杂性:代码逻辑复杂,需要处理同步、资源共享和竞争条件等问题。
- 高效利用资源:能够充分利用多核处理器和分布式计算资源。
示例
假设我们有三个任务:Task 1、Task 2 和 Task 3,它们可以同时执行。我们可以使用 Python 的 concurrent.futures 模块来实现并行操作。
import concurrent.futures
def task1():
print("Executing Task 1")
def task2():
print("Executing Task 2")
def task3():
print("Executing Task 3")
# 并行执行
with concurrent.futures.ThreadPoolExecutor() as executor:
futures = [executor.submit(task) for task in [task1, task2, task3]]
for future in concurrent.futures.as_completed(futures):
future.result()
在上述代码中,Task 1、Task 2 和 Task 3 会同时开始执行,利用线程池实现并行处理。
优缺点
-
优点:
- 高效处理大量任务。
- 能充分利用多核处理器和分布式计算资源,提高整体性能。
-
缺点:
- 实现复杂,需要处理同步和资源共享问题。
- 存在资源竞争和死锁风险。
比较和应用场景
1. 执行顺序
- 串行操作:任务按顺序逐一执行。
- 并行操作:多个任务可以同时执行。
2. 适用场景
- 串行操作:适用于简单的、无需高并发的任务,如顺序文件处理、简单的计算任务等。
- 并行操作:适用于需要高并发处理的任务,如大规模数据处理、图像处理、网络请求等。
3. 资源利用
- 串行操作:通常只能利用单个处理器核,无法充分利用多核处理器的优势。
- 并行操作:能够利用多核处理器或多台计算机,提高资源利用率和任务处理效率。
4. 代码复杂度
- 串行操作:实现简单,代码逻辑直观。
- 并行操作:实现复杂,需要处理任务同步、资源共享和竞争条件等问题。
总结
串行操作和并行操作在计算机科学中不仅代表了两种不同的技术实现方式,更深层次上反映了不同的哲学思想:
- 时间观念:线性 vs 非线性。
- 资源利用:单任务专注 vs 多任务并行。
- 复杂性:秩序和简单 vs 复杂性管理。
- 任务关系:协作和依赖 vs 竞争和协同。
开放性问题
Rocky从工业界、应用界、竞赛界以及学术界角度出发,思考总结AI行业的一些开放性问题,这些问题不仅能够用于面试官的提问,也可以用作面试者的提问,在面试的最后阶段让面试双方进入更深入的探讨与交流。
与此同时,这些开放性问题也是贯穿我们职业生涯的本质问题,需要我们持续的思考感悟。这些问题没有标准答案,Rocky相信大家心中都有自己对于AI行业的认知与判断,欢迎大家在留言区分享与评论。
【一】在哪些维度深耕能增强算法工程师的核心竞争力?
Rocky认为这是一个直击所有AI行业算法工程师灵魂的问题,也是伴随所有算法工程师完整职业生涯的问题,需要我们不断思考,不断更新认知。
Rocky在这里为大家抛砖引玉的总结一些维度,大家也可以留言补充:
- 算法技术能力
- 算法竞赛能力
- 算法工程能力
- 算法学术能力
- AI行业的知识广度能力
- AI行业的本质思考能力
- 等等
【二】AI产品和AI算法解决方案涵盖的研发岗位有哪些?
在AI领域,Rocky认为我们不仅仅要了解算法岗位的工作内容,也要了解其他相关研发岗位的工作内容,这样才能更好的配合和评估成本与周期,所以这是一个非常有价值的问题。
Rocky在这里为大家抛砖引玉的进行总结,大家也可以留言补充:
- AI产品:算法岗+前端岗+后端岗+测试岗+运维岗+产品岗+运营岗等
- AI算法解决方案:算法岗+前端岗+后端岗+测试岗+运维岗+嵌入式岗等
推荐阅读
1、加入AIGCmagic社区知识星球
AIGCmagic社区知识星球不同于市面上其他的AI知识星球,AIGCmagic社区知识星球是国内首个以AIGC全栈技术与商业变现为主线的学习交流平台,涉及AI绘画、AI视频、ChatGPT等大模型、AI多模态、数字人、全行业AIGC赋能等50+应用方向,内部包含海量学习资源、专业问答、前沿资讯、内推招聘、AIGC模型、AIGC数据集和源码等。
那该如何加入星球呢?很简单,我们只需要扫下方的二维码即可。知识星球原价:299元/年,前200名限量活动价,终身优惠只需199元/年。大家只需要扫描下面的星球优惠卷即可享受初始居民的最大优惠:


2、Stable Diffusion XL核心基础知识,从0到1搭建使用Stable Diffusion XL进行AI绘画,从0到1上手使用Stable Diffusion XL训练自己的AI绘画模型,AI绘画领域的未来发展等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
Stable Diffusion XL文章地址:https://zhuanlan.zhihu.com/p/643420260
3、Stable DiffusionV1-V2核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用Stable Diffusion进行AI绘画,从0到1上手使用Stable Diffusion训练自己的AI绘画模型,Stable Diffusion性能优化等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
Stable Diffusion文章地址:https://zhuanlan.zhihu.com/p/632809634
4、ControlNet核心基础知识,核心网络结构,从0到1使用ControlNet进行AI绘画,从0到1上手构建ControlNet高级应用等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
ControlNet文章地址:https://zhuanlan.zhihu.com/p/660924126
5、LoRA系列模型核心基础知识,从0到1使用LoRA模型进行AI绘画,从0到1上手训练自己的LoRA模型,LoRA变体模型介绍,优质LoRA推荐等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
LoRA文章地址:https://zhuanlan.zhihu.com/p/639229126
6、最全面的AIGC面经《手把手教你成为AIGC算法工程师,斩获AIGC算法offer!(2024年版)》文章正式发布
码字不易,欢迎大家多多点赞:
AIGC面经文章地址:https://zhuanlan.zhihu.com/p/651076114
7、10万字大汇总《“三年面试五年模拟”之算法工程师的求职面试“独孤九剑”秘籍》文章正式发布
码字不易,欢迎大家多多点赞:
算法工程师三年面试五年模拟文章地址:https://zhuanlan.zhihu.com/p/545374303
《三年面试五年模拟》github项目地址(希望大家能给个star):https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer
8、Stable Diffusion WebUI、ComfyUI、Fooocus三大主流AI绘画框架核心知识,从0到1搭建AI绘画框架,从0到1使用AI绘画框架的保姆级教程,深入浅出介绍AI绘画框架的各模块功能,深入浅出介绍AI绘画框架的高阶用法等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
AI绘画框架文章地址:https://zhuanlan.zhihu.com/p/673439761
9、其他
Rocky将YOLOv1-v7全系列大解析文章也制作成相应的pdf版本,大家可以关注公众号WeThinkIn,并在后台 【精华干货】菜单或者回复关键词“YOLO” 进行取用。
Rocky一直在运营技术交流群(WeThinkIn-技术交流群),这个群的初心主要聚焦于技术话题的讨论与学习,包括但不限于算法,开发,竞赛,科研以及工作求职等。群里有很多人工智能行业的大牛,欢迎大家入群一起学习交流~(请添加小助手微信Jarvis8866,拉你进群~)