文章目录
- Filebeat
- Filebeat主要特点
- Filebeat使用场景
- ELK简介
- Elasticsearch简介
- Elasticsearch主要特点
- Elasticsearch使用场景
- Logstash简介
- Logstash主要特点
- Logstash使用场景
- Kibana简介
- Kibana主要特点
- Kibana使用场景
- 简单理解
- 环境
- 一、ELK集群部署
- 1.软件安装
- 2.软件配置及启动
- (1).kibana软件配置及启动
- (2).elasticsearch软件配置及启动
- (3).logstash软件配置及启动
- (4).kibana访问
- (5).编写logstash用于收集日志配置文件
- (6).运行logstash
- 二、收集k8s集群节点系统日志
- 1.下载filebeat镜像
- 2.创建filebeat资源清单文件
- 3.应用filebeat资源清单文件
- 4.验证结果
- 5.在kibana中添加索引
本次部署的应用有Filebeat+ELK,让我们先简单了解一下
Filebeat
Filebeat 是一个轻量级的日志数据发送器,作为 ELK 堆栈的一个组件,主要用于从各种来源收集日志数据并将其发送到 Logstash 或 Elasticsearch。它是 Elastic Stack 中 Beats 产品家族的一部分。
Filebeat主要特点
轻量级:
Filebeat 设计简单,资源占用低,非常适合部署在边缘节点或资源受限的环境中。
多种输入源:
Filebeat 支持从文件、Docker 日志、容器日志、系统日志等多种来源收集日志数据。
日志传输:
Filebeat 可以将收集到的日志数据发送到多个目标,包括 Logstash、Elasticsearch、Kafka 等。
日志处理:
Filebeat 具有基本的日志处理能力,可以通过模块化的方式实现常见的日志解析和处理。
可靠性:
具有保证至少一次传递的能力,确保日志数据在传输过程中不会丢失。
模块化:
Filebeat 提供了一系列预配置的模块,用于处理常见的日志格式,如 Nginx、Apache、MySQL、系统日志等。
Filebeat使用场景
集中式日志管理: 在分布式系统中集中收集各个节点的日志。
实时日志分析: 通过 Filebeat 将日志数据实时发送到 Elasticsearch,进行实时搜索和分析。
监控和报警: 结合 ELK 堆栈,实现日志数据的实时监控和报警。
ELK简介
ELK 是 Elasticsearch、Logstash 和 Kibana 三个开源工具的组合,常用于数据搜索、日志管理和数据可视化
Elasticsearch简介
Elasticsearch 是一个分布式搜索和分析引擎,基于 Apache Lucene 构建,主要用于存储、搜索和分析大量数据。
Elasticsearch主要特点
实时搜索和分析: 支持实时的数据存储和检索。
分布式: 能够在多个节点上分布数据,提供高可用性和扩展性。
全文搜索: 支持复杂的查询语法,能够进行高效的全文搜索。
RESTful API: 通过 RESTful API 进行数据操作,便于集成和扩展。
Elasticsearch使用场景
日志和事件数据分析: 集中管理和分析日志数据。
全文搜索: 如网站的搜索功能。
监控和报警: 实时监控数据变化并触发报警。
Logstash简介
Logstash 是一个数据收集引擎,能够从多个来源收集数据,进行过滤和转换,然后将数据发送到存储引擎(如 Elasticsearch)。
Logstash主要特点
数据收集: 支持从多种数据源(如文件、数据库、消息队列等)收集数据。
数据处理: 通过过滤器对数据进行处理和转换,如解析日志格式、添加字段等。
数据输出: 将处理后的数据发送到多个目标(如 Elasticsearch、文件、数据库等)。
Logstash使用场景
日志收集和处理: 收集和处理分布在不同系统和应用中的日志。
数据转换: 对原始数据进行格式转换、过滤和增强。
Kibana简介
Kibana 是一个数据可视化和分析平台,专为与 Elasticsearch 一起使用而设计。它提供强大的图形界面,帮助用户进行数据分析和可视化。
Kibana主要特点
**数据可视化:**通过图表、地图、表格等方式展示数据。
**仪表盘:**创建和共享动态仪表盘,实时监控数据变化。
**查询和分析:**通过简单的界面进行数据查询和分析。
Kibana使用场景
日志分析: 可视化分析日志数据,快速发现问题。
业务监控: 创建业务指标的实时监控仪表盘。
安全分析: 用于安全信息和事件管理(SIEM)解决方案。
简单理解
看不懂上面的,没关系,看懂下面就行
Filebeat: 部署在个节点,收集日志
Logstash: 过滤,格式化日志
Elasticsearch: 存储、搜索、分析日志
Kibana: 图形化界面,展示日志、监控系统状态
环境
虚拟机
| Ip | 主机名 | cpu | 内存 | 硬盘 |
|---|---|---|---|---|
| 192.168.10.11 | master01 | 2cpu双核 | 4G | 100G |
| 192.168.10.12 | worker01 | 2cpu双核 | 4G | 100G |
| 192.168.10.13 | worker02 | 2cpu双核 | 4G | 100G |
| 192.168.10.17 | ELK | 1cpu双核 | 4G | 40G |
版本 centos7.9
已部署k8s-1.27
注:如果有条件,可以ELK分别放在三台主机上,我这里是资源有限,所以才全放在一台主机上了
一、ELK集群部署
elk主机部署
1.软件安装
安装jdk
可考虑使用openjdk也可以使用oracle jdk
yum -y install java-11-openjdk
安装kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.17.2-x86_64.rpm
yum -y install kibana-7.17.2-x86_64.rpm
安装elasticsearch
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.2-x86_64.rpm
yum -y install elasticsearch-7.17.2-x86_64.rpm
安装logstash
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.17.2-x86_64.rpm
yum -y install logstash-7.17.2-x86_64.rpm
2.软件配置及启动
(1).kibana软件配置及启动
vim /etc/kibana/kibana.yml
修改如下内容
行号 + 修改后的结果
有的只需要去#号即可
有的不需要更改
2 server.port: 5601
7 server.host: "192.168.10.17"
32 elasticsearch.hosts: ["http://192.168.10.17:9200"]
115 i18n.locale: "zh-CN"
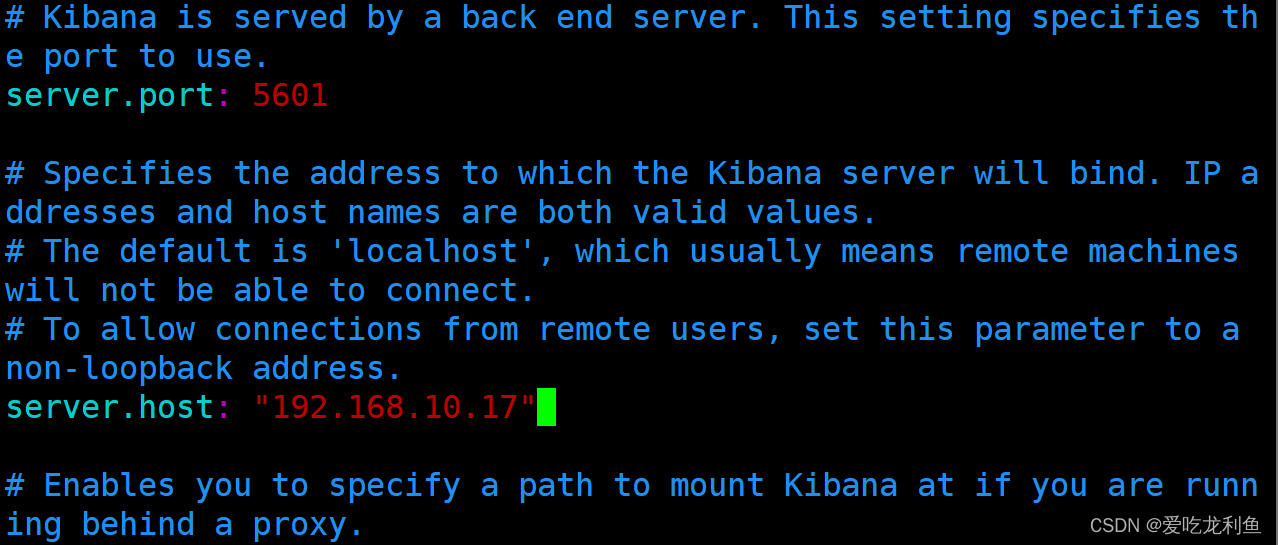


说明:
server.port 是开启kibana监听端口
server.host 设置远程连接主机IP地址,用于远程访问使用
elasticsearch.hosts 设置elasticsearch.hosts主机IP,用于连接elasticsearch主机,可以为多个值
i18n.locale 设置语言支持,不需要再汉化,直接修改后即可支持中文
启动服务并验证
systemctl enable kibana
systemctl start kibana
ss -anput | grep ":5601"

(2).elasticsearch软件配置及启动
vim /etc/elasticsearch/elasticsearch.yml
同上
17 cluster.name: k8s-elastic
23 node.name: elastic
33 path.data: /var/lib/elasticsearch
37 path.logs: /var/log/elasticsearch
56 network.host: 192.168.10.17
61 http.port: 9200
70 discovery.seed_hosts: ["192.168.10.17"]
74 cluster.initial_master_nodes: ["192.168.10.17"]
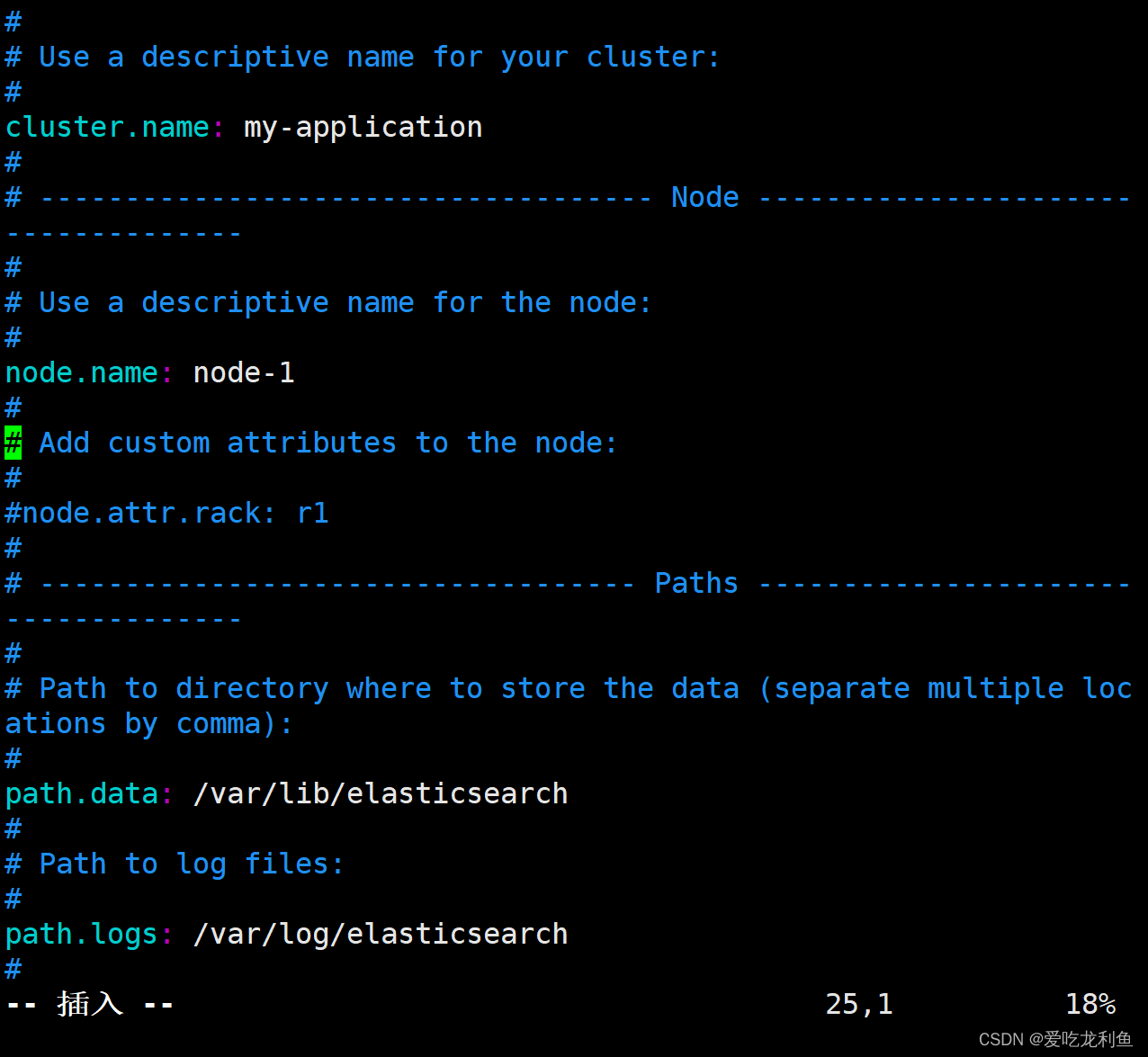
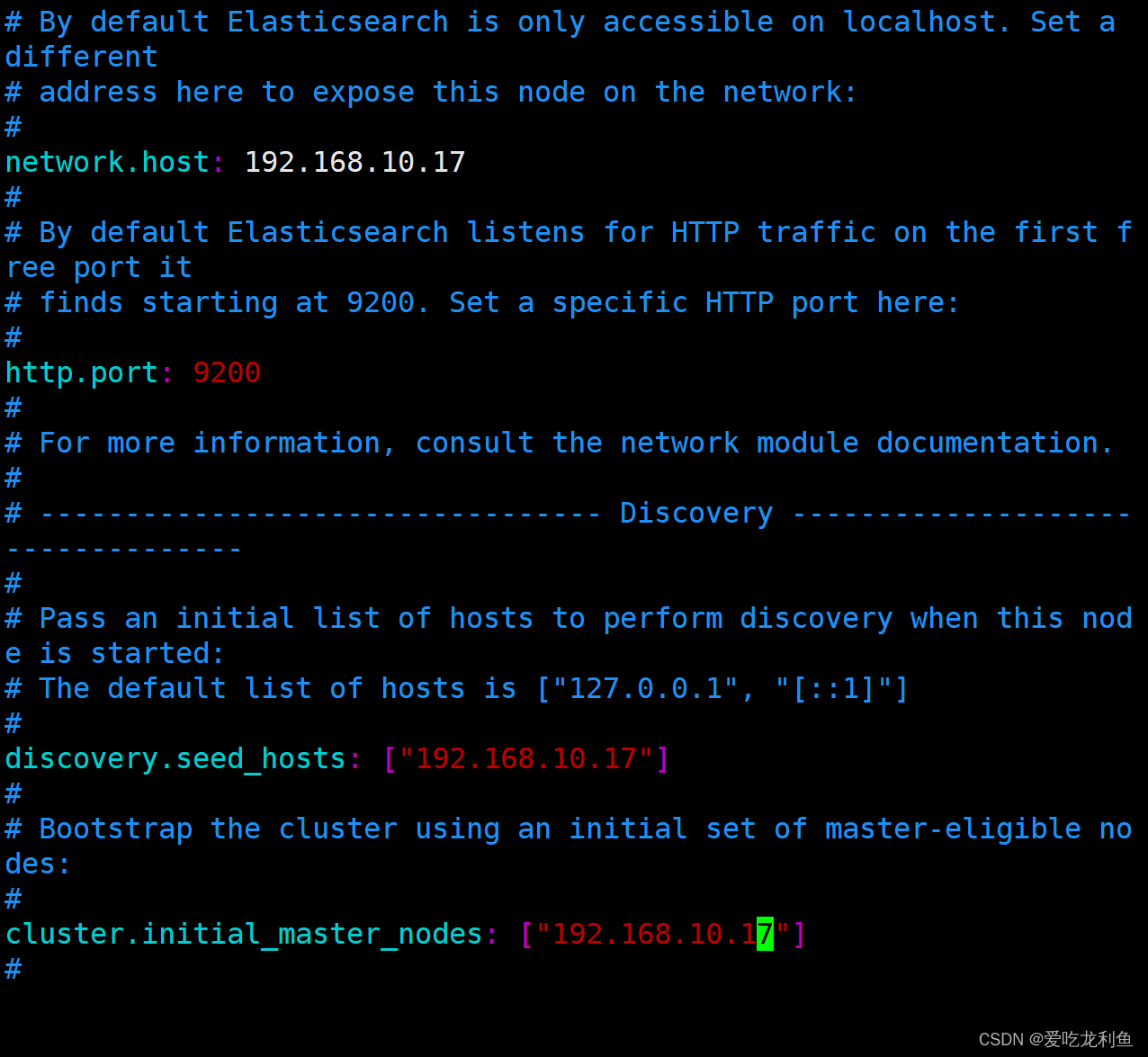
说明
cluster.name 集群名称
node.name 节点名称
path.data 数据目录
path.logs 日志目录
network.host 主机IP
http.port 监听端口
discovery.seed_hosts 主机发现列表
cluster.initial_master_nodes 集群master节点
启动服务并验证
systemctl enable elasticsearch
systemctl start elasticsearch
ss -anput | grep ":9200"
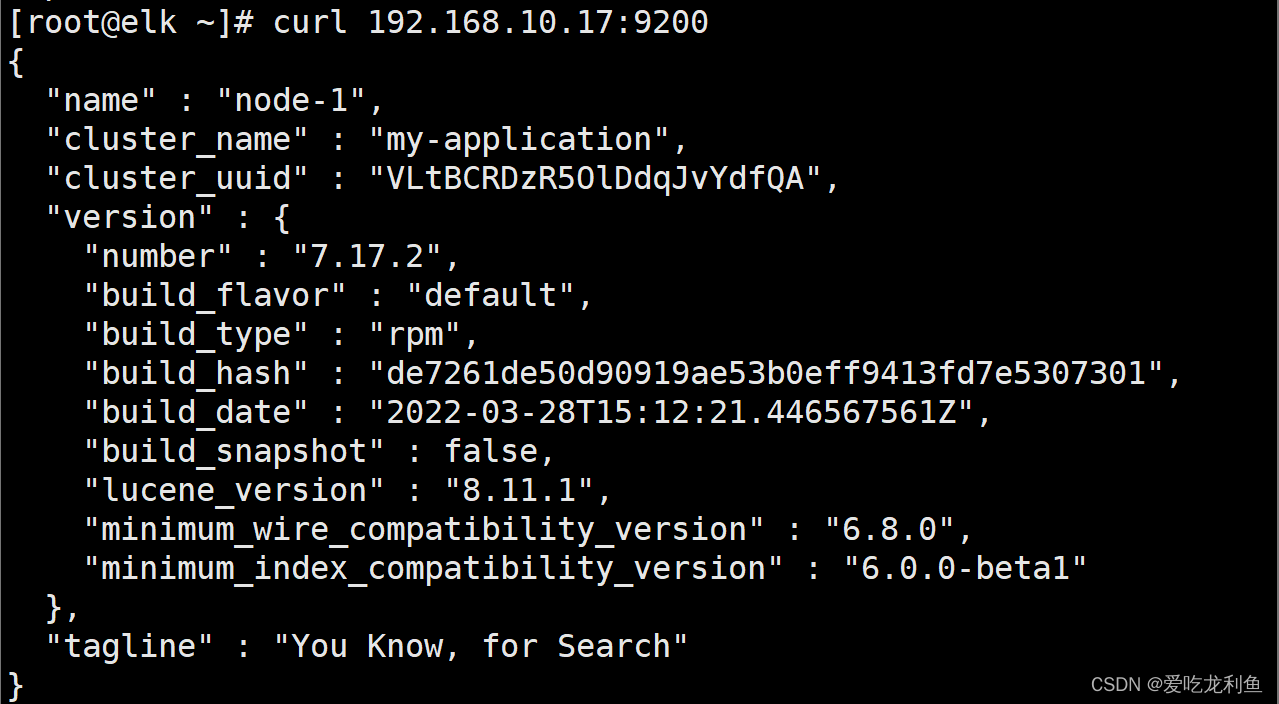
curl http://192.168.10.17:9200
(3).logstash软件配置及启动
vim /etc/logstash/logstash.yml
同上
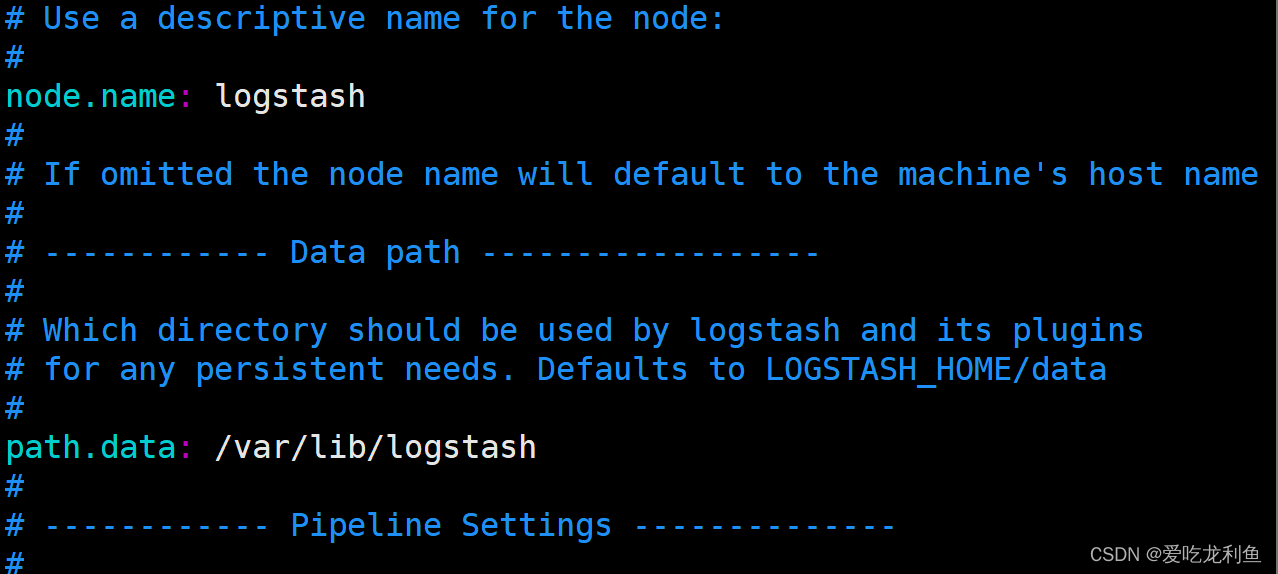
19 node.name: logstash
28 path.data: /var/lib/logstash
133 api.http.host: 192.168.10.17
139 api.http.port: 9600-9700
280 path.logs: /var/log/logstash
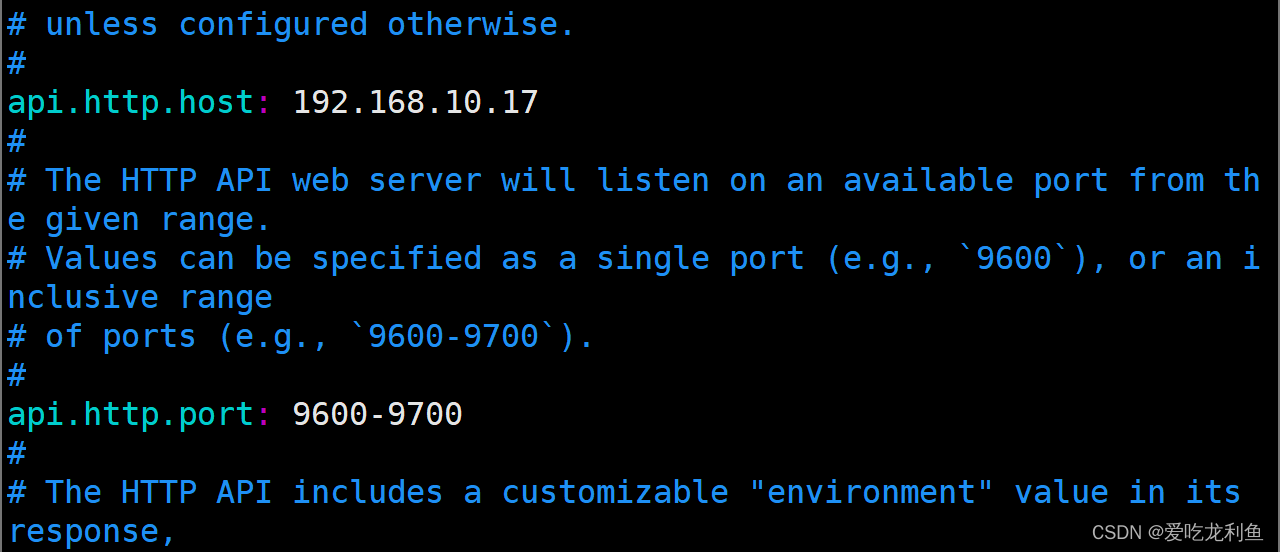

启动服务
logstash进程不用预先启动,使用时启动即可
现在先不启动
验证logstash可用性
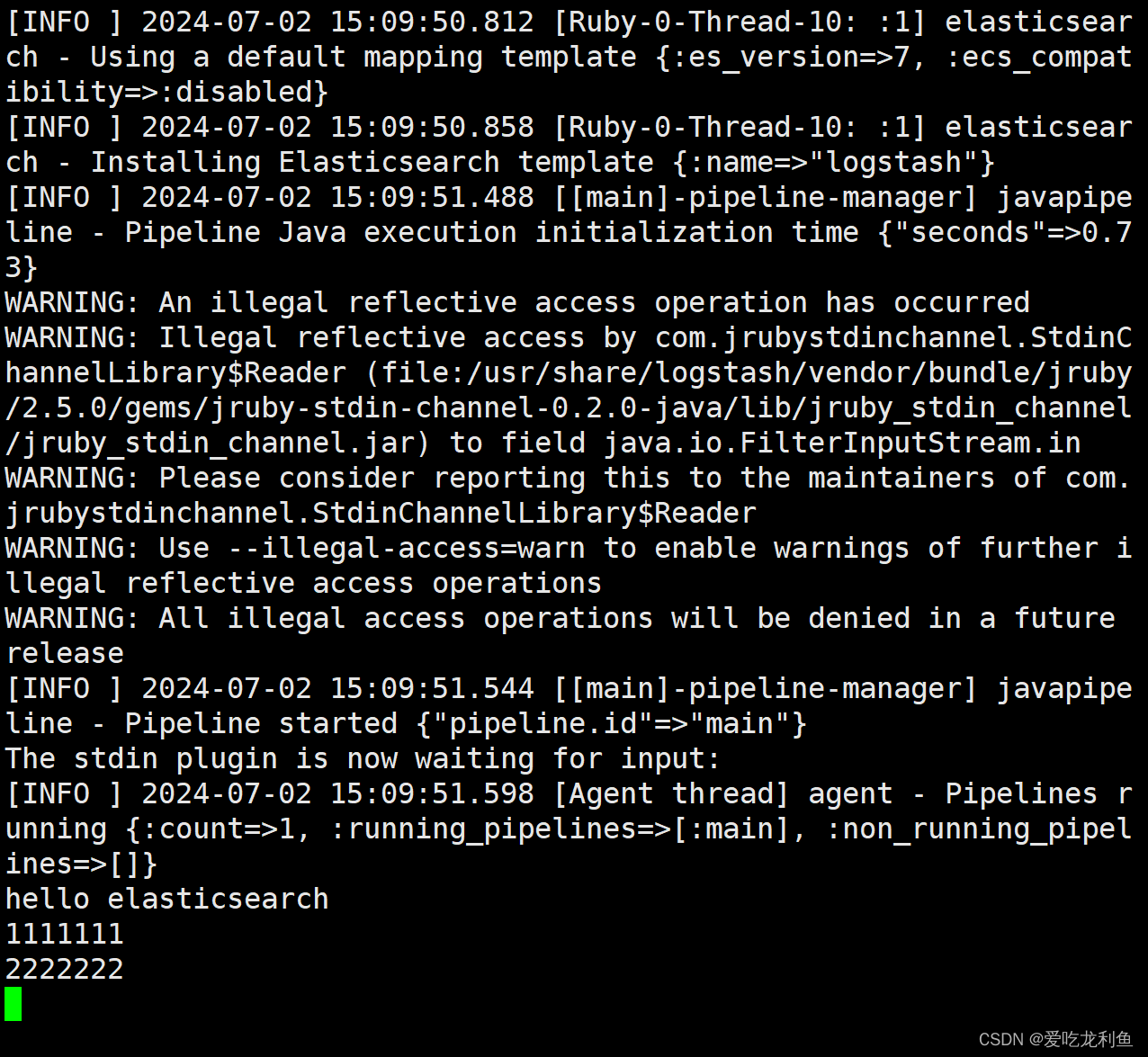
/usr/share/logstash/bin/logstash -e 'input {stdin{} } output {stdout {} }'
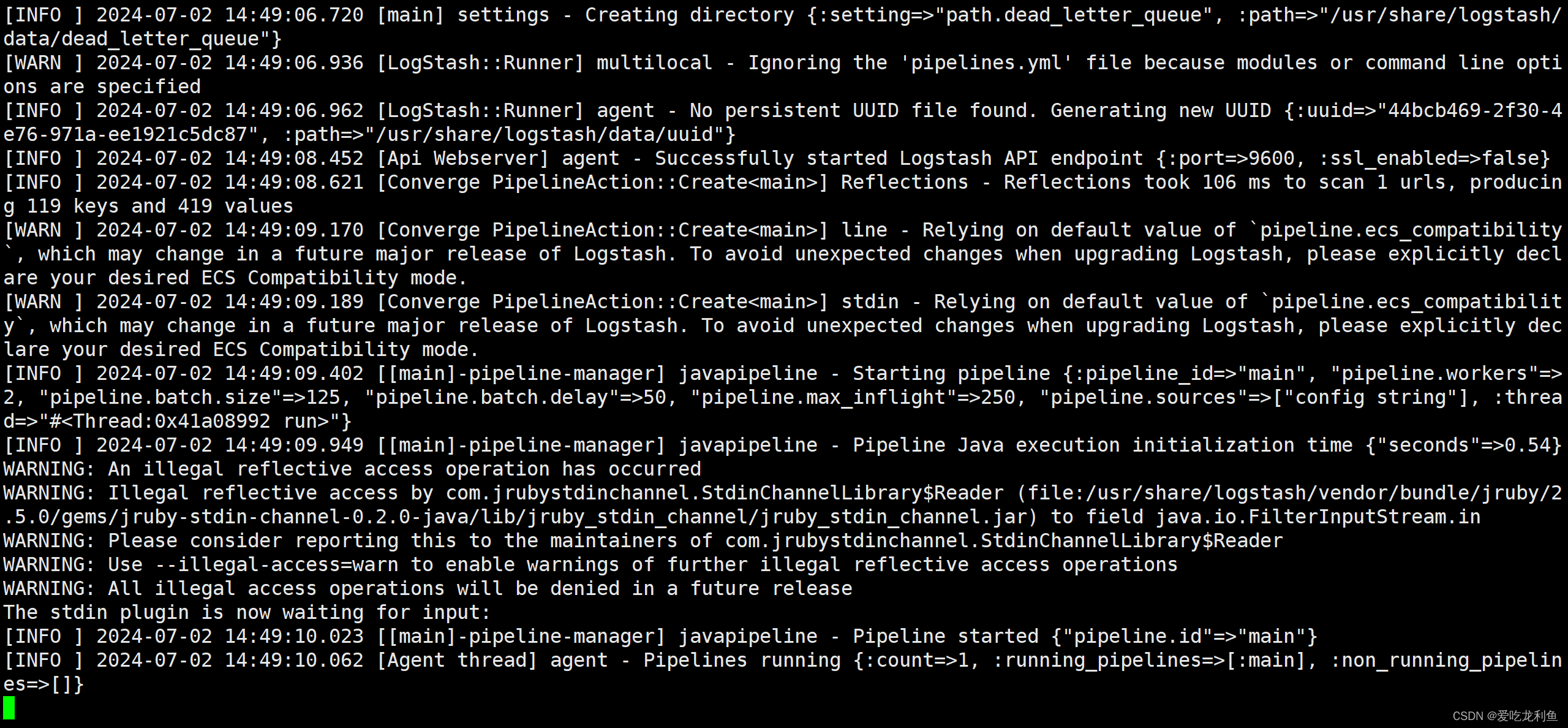
输入abc,查看输出内容
abc
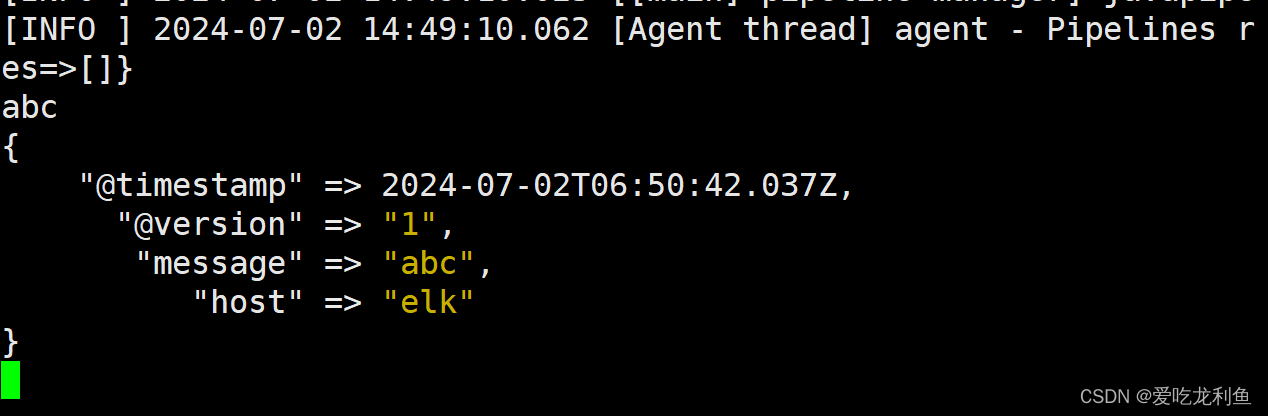
ctrl +c 退出
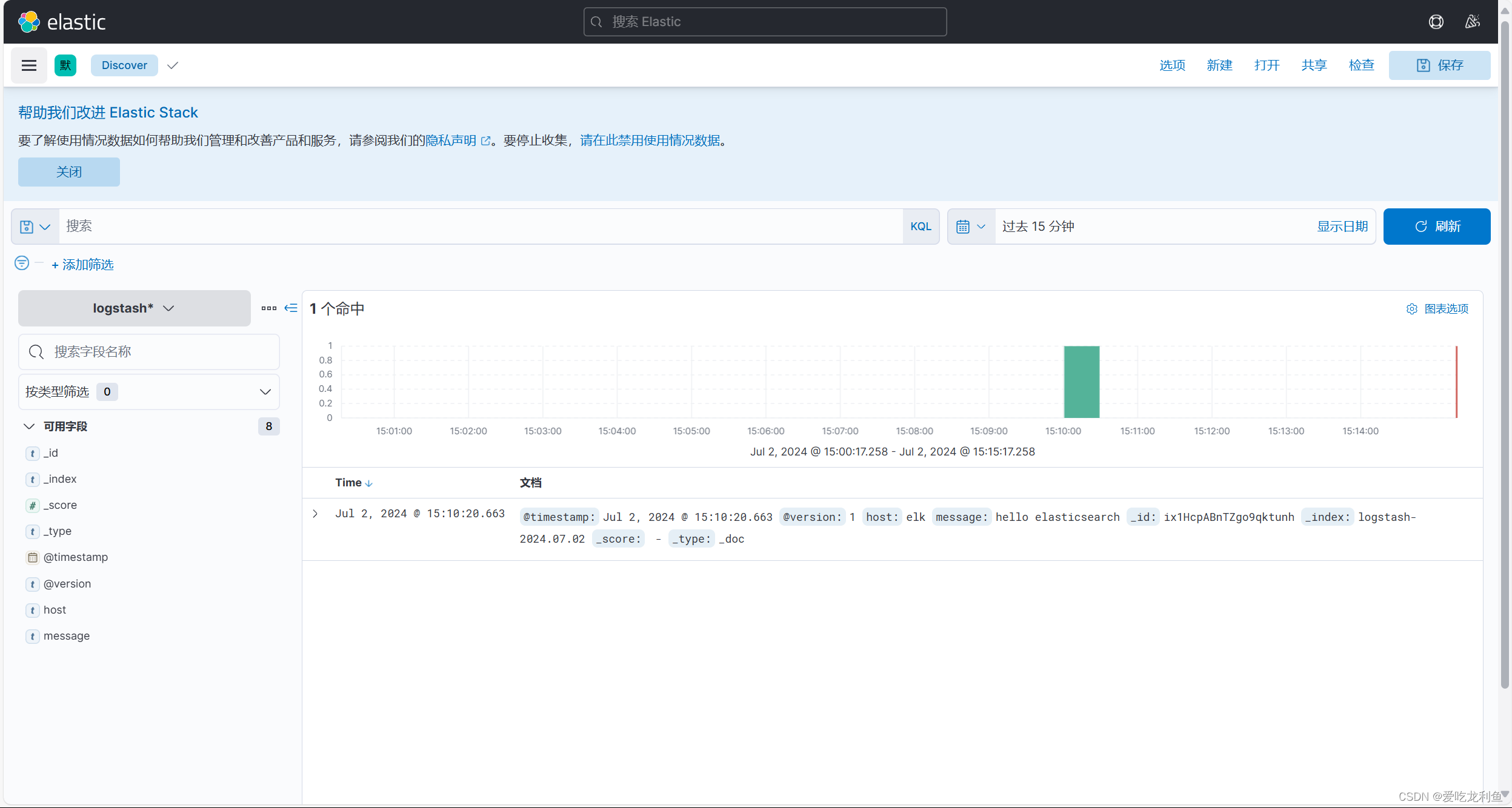
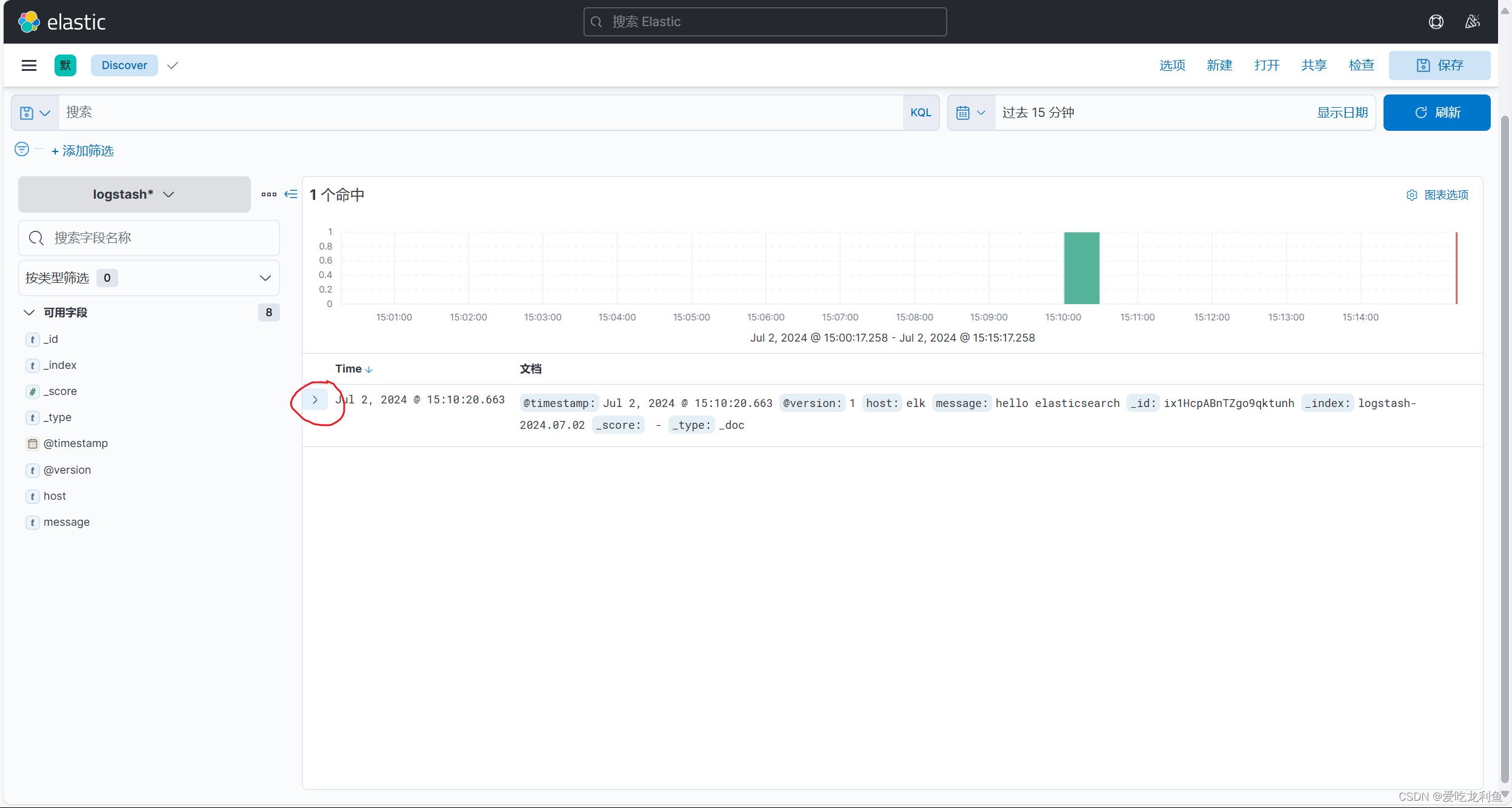
使用logstash输入内容到elasticsearch验证
/usr/share/logstash/bin/logstash -e 'input { stdin{} } output { elasticsearch { hosts => ["192.168.10.17:9200"] index => "logstash-%{+YYYY.MM.dd}" } }'
输入
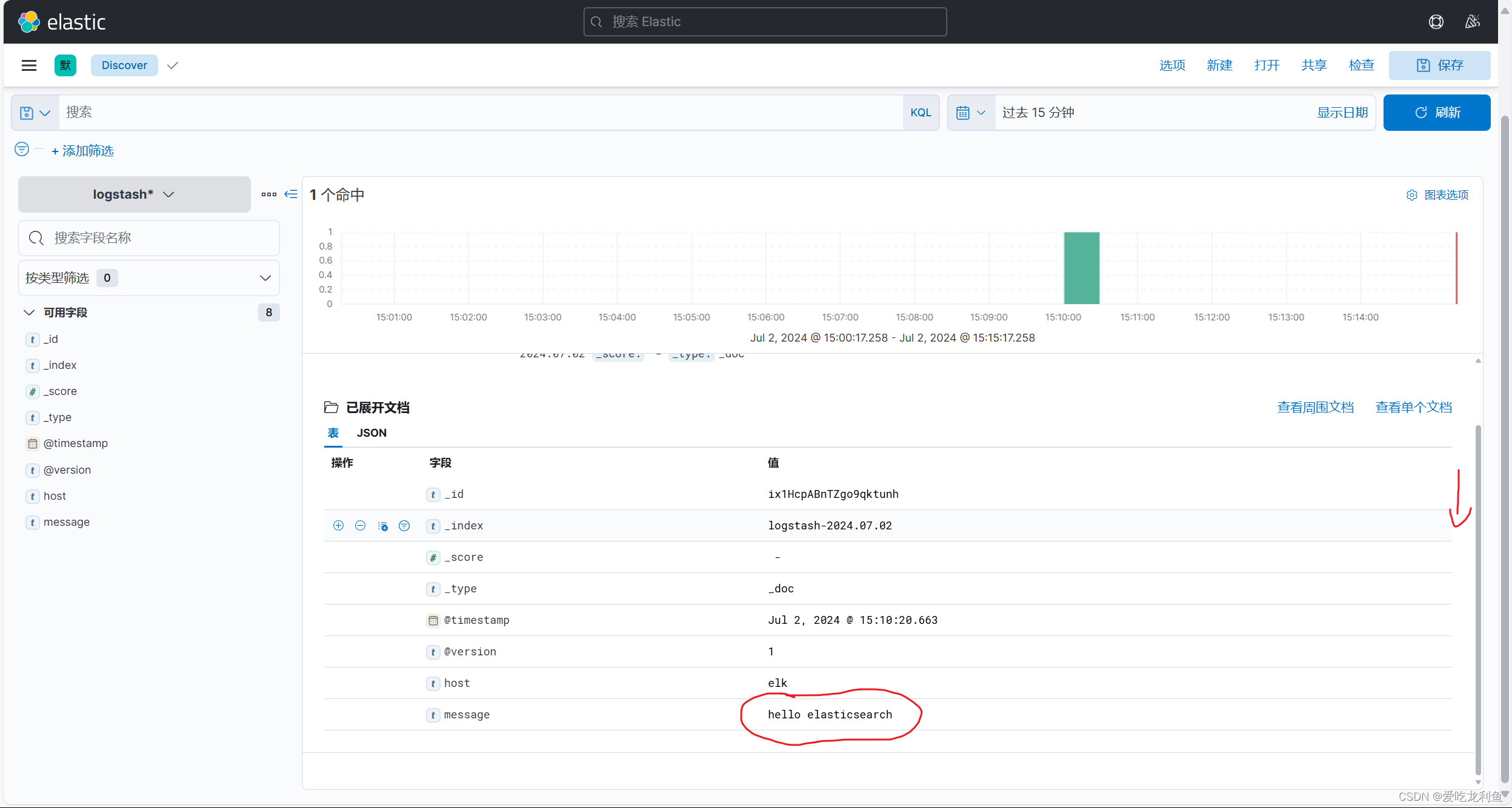
hello elasticsearch
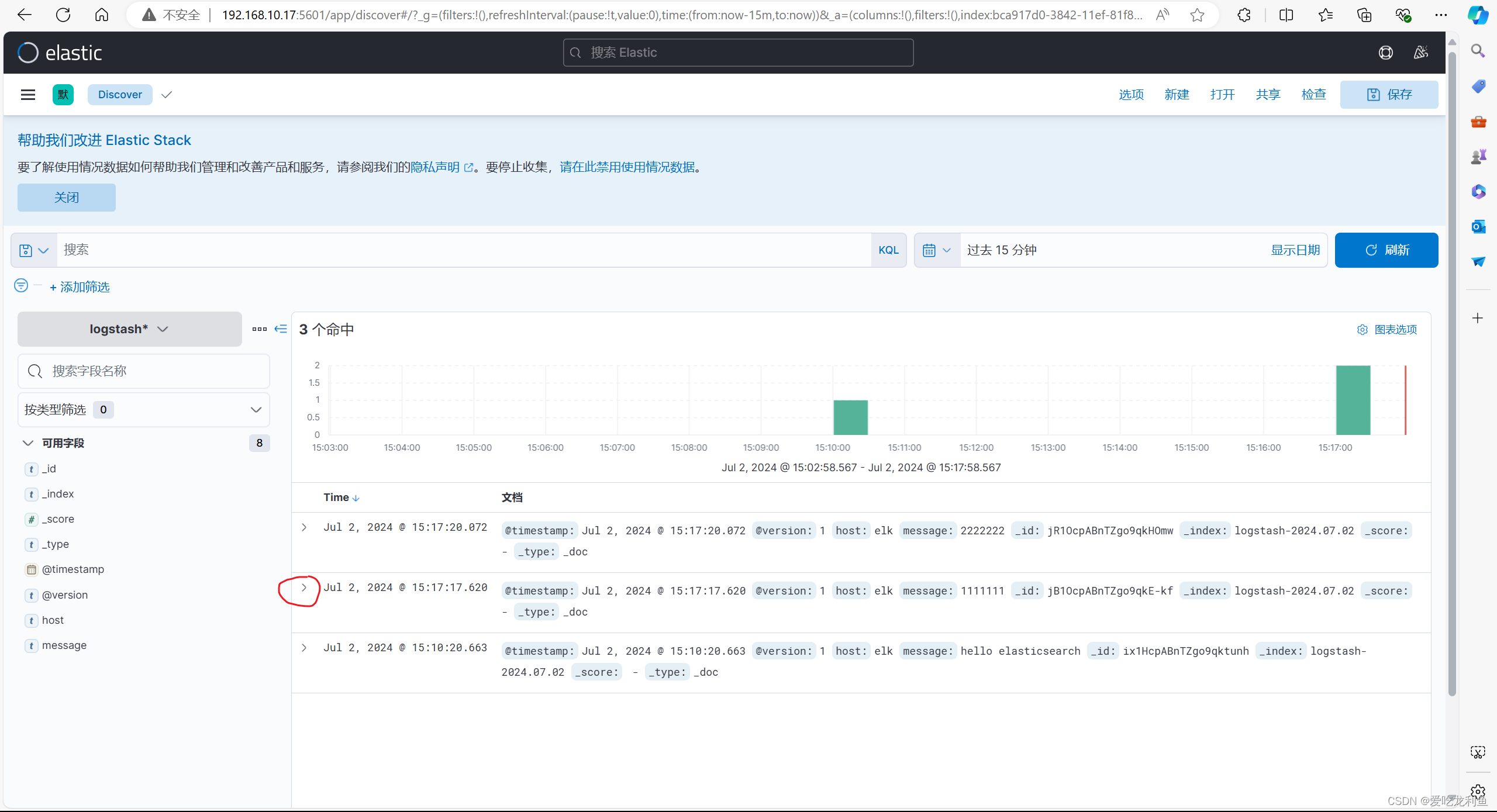
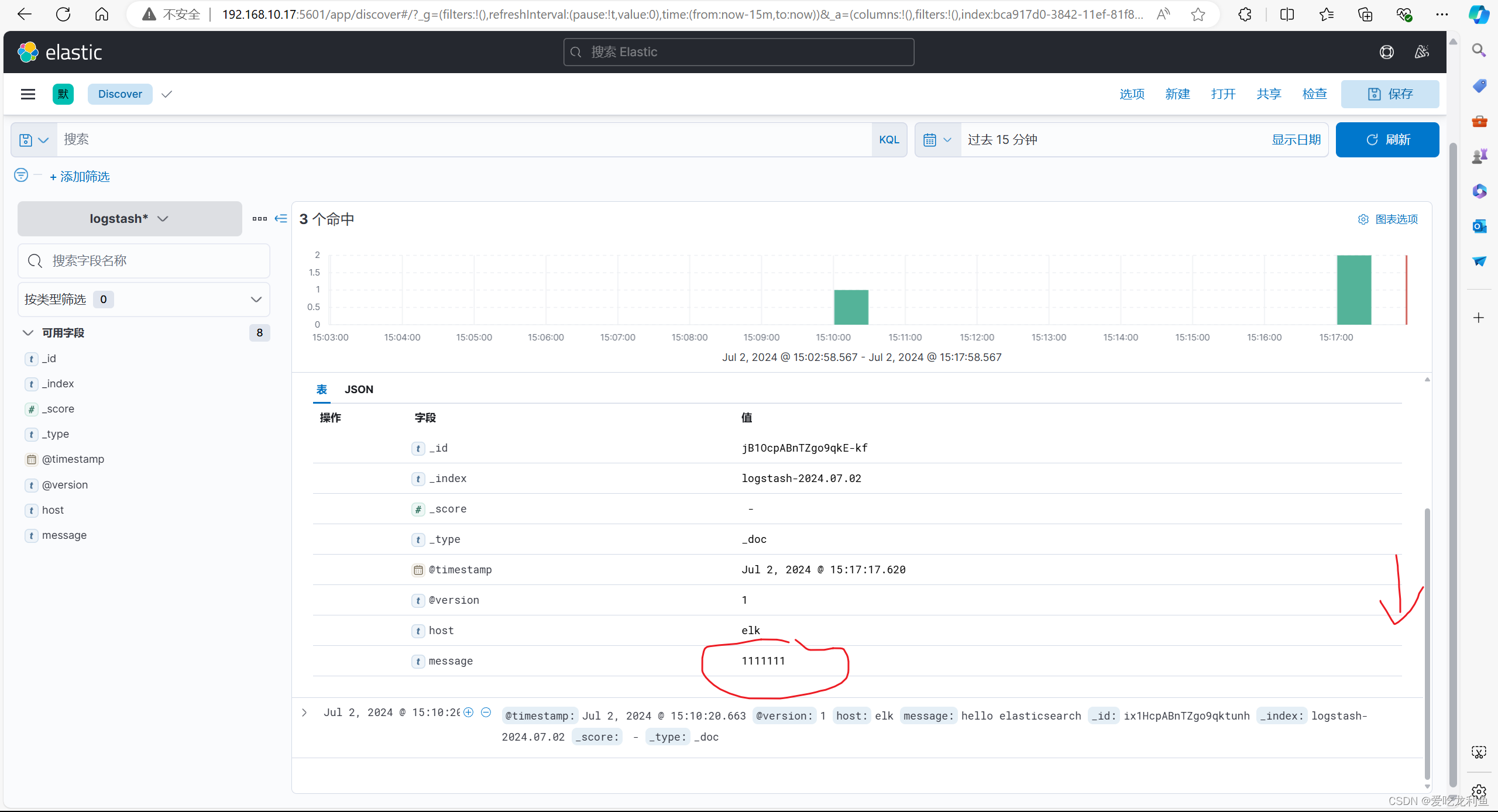
此内容将会通过kibana页面中的索引看到,但是需要在kibana页面中添加索引

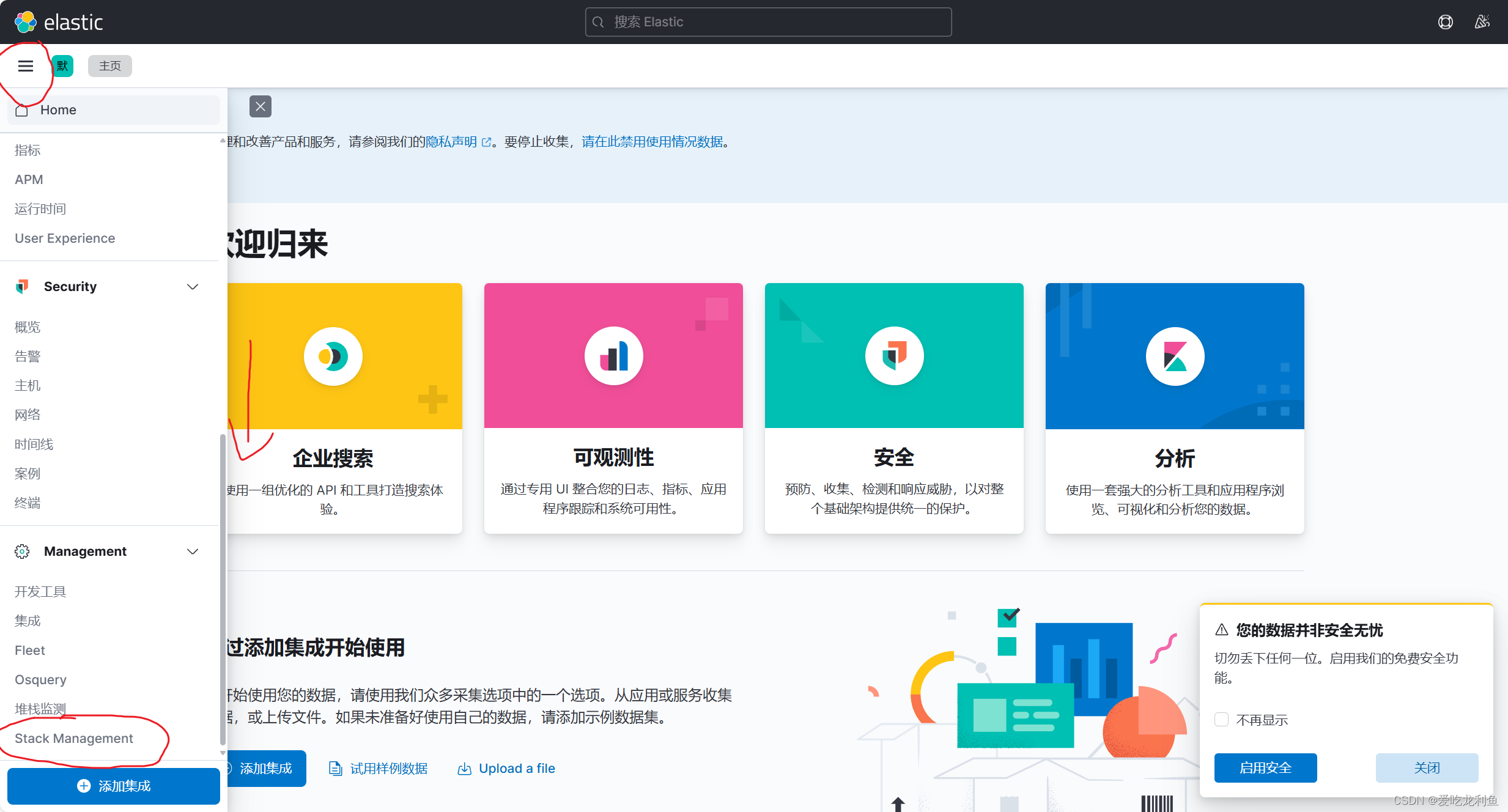
(4).kibana访问
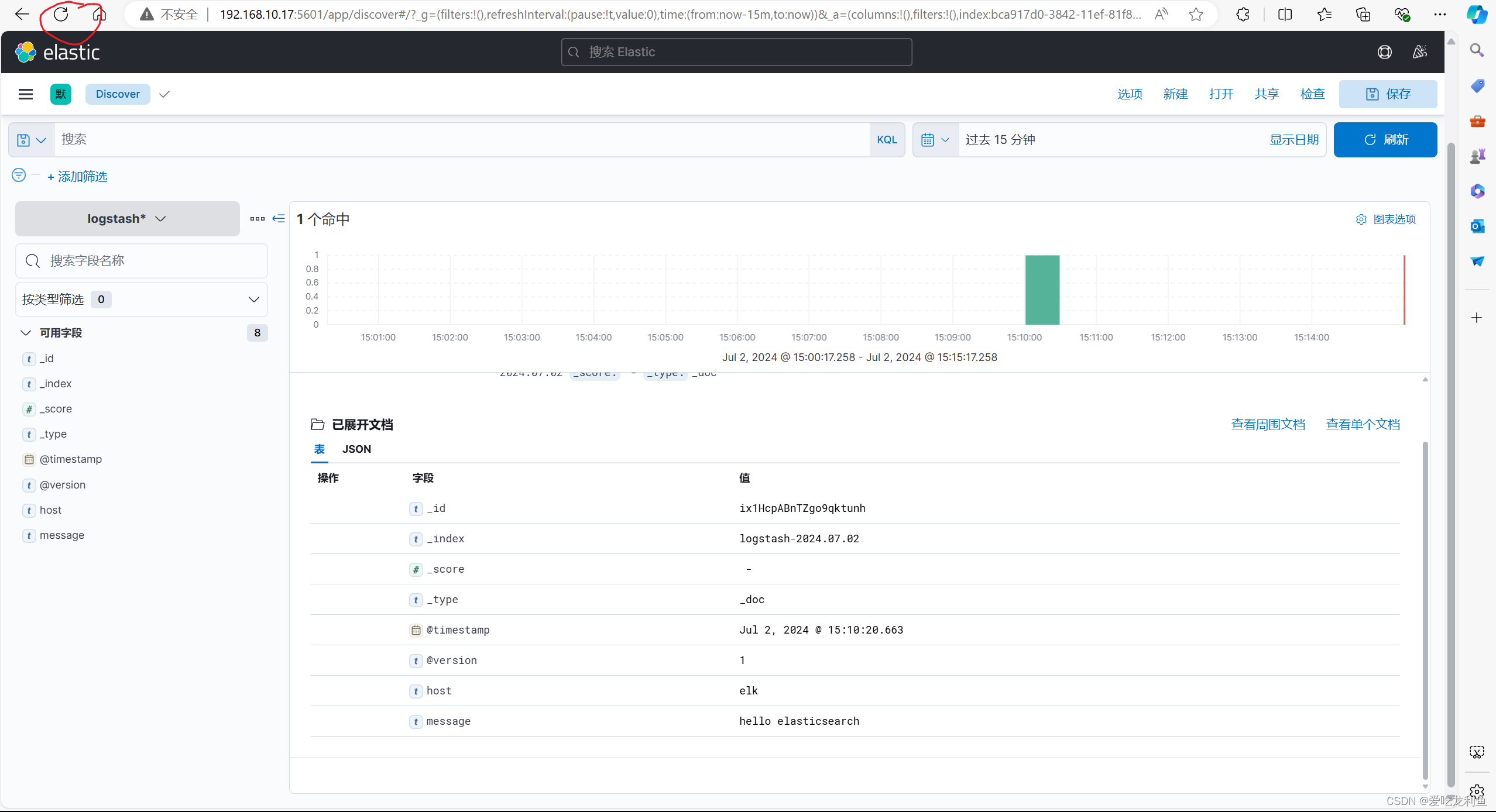
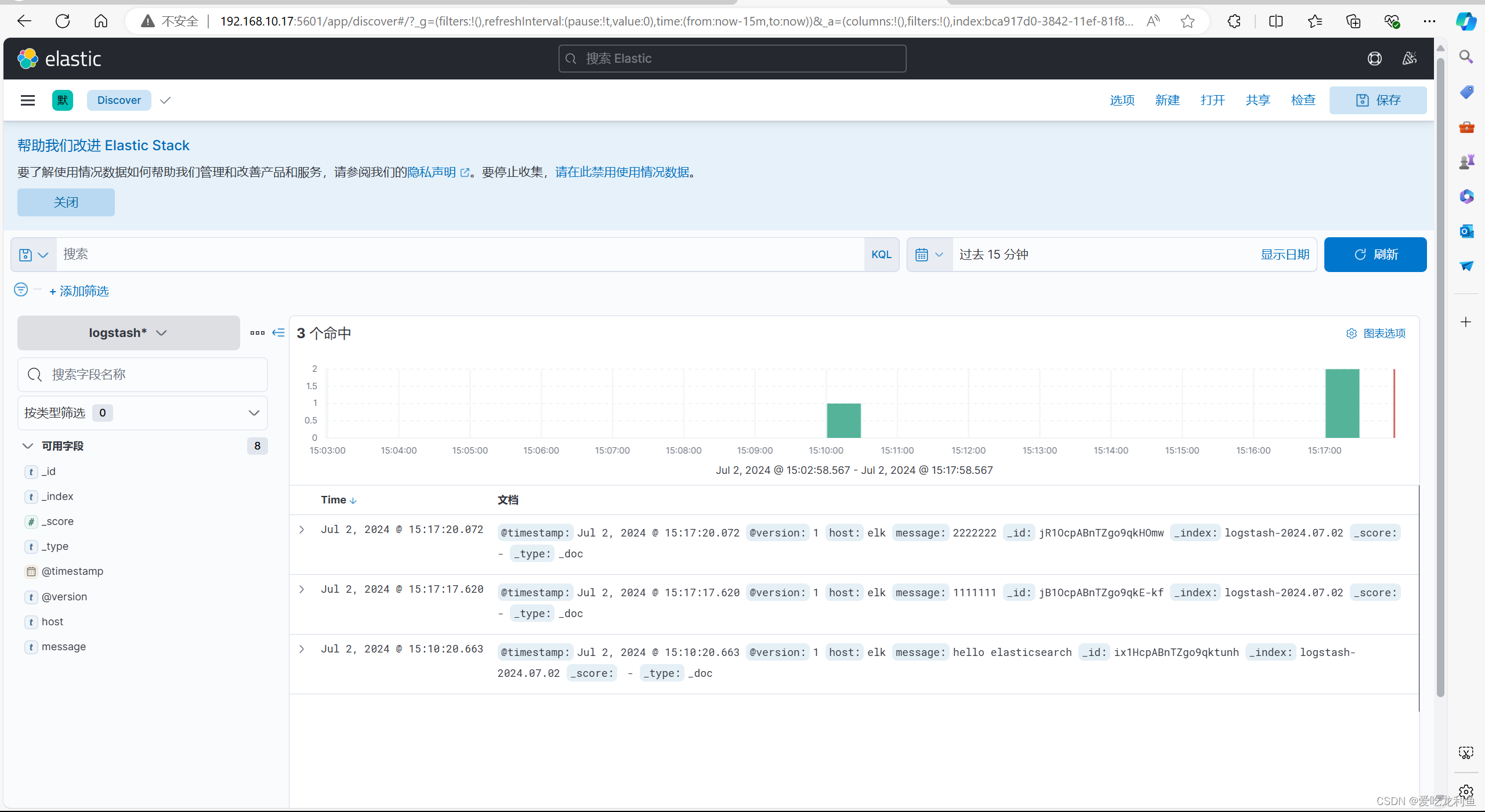
宿主机浏览器访问
192.168.10.17:5601
在欢迎界面选择自己浏览后会进入主界面
(5).编写logstash用于收集日志配置文件
通过filebeat进行收集
vim /etc/logstash/conf.d/logstash-to-elastic.conf
input {
beats {
host => "0.0.0.0"
port => "5044"
}
}
filter {
}
output {
elasticsearch {
hosts => "192.168.10.17:9200"
index => "k8s-%{+YYYY.MM.dd}"
}
}
(6).运行logstash
如果不涉及多个配置文件,可以直接使用systemctl start logstash;如果有多个配置文件,只想启动一个配置文件,可以使用如下方法。
直接在后台运行
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/logstash-to-elastic.conf --path.data /usr/share/logstash/data1 &
不输出内容后按两下回车
看看端口
netstat -lntp | grep :5044

二、收集k8s集群节点系统日志
通过在work节点以DaemonSet方法运行filebeat应用实现
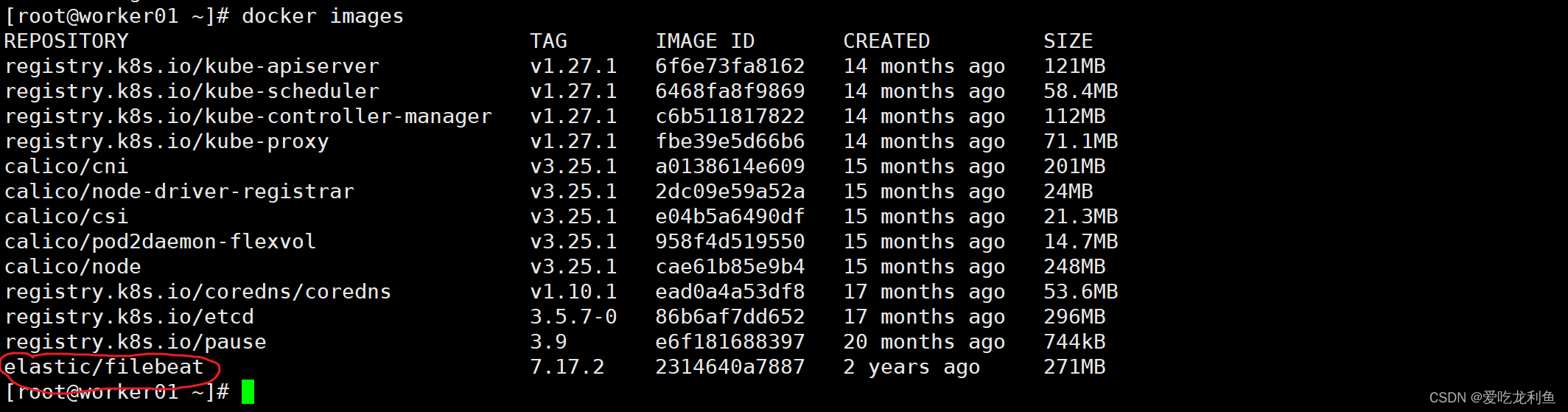
1.下载filebeat镜像
所有worker节点
下载filebeat镜像
docker pull elastic/filebeat:7.17.2
docker images
master节点
2.创建filebeat资源清单文件
vim filebeat-to-logstash.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: k8s-logs-filebeat-config
namespace: kube-system
data:
filebeat.yml: |
filebeat.inputs:
- type: log
paths:
- /var/log/messages
fields:
app: k8s
type: module
fields_under_root: true
setup.ilm.enabled: false
setup.template.name: "k8s-module"
setup.template.pattern: "k8s-module-*"
output.logstash:
hosts: ['192.168.10.17:5044']
index: "k8s-module-%{+yyyy.MM.dd}"
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: k8s-logs
namespace: kube-system
spec:
selector:
matchLabels:
project: k8s
app: filebeat
template:
metadata:
labels:
project: k8s
app: filebeat
spec:
containers:
- name: filebeat
image: docker.io/elastic/filebeat:7.17.2
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 500m
memory: 500Mi
securityContext:
runAsUser: 0
volumeMounts:
- name: filebeat-config
mountPath: /etc/filebeat.yml
subPath: filebeat.yml
- name: k8s-logs
mountPath: /var/log/messages
volumes:
- name: k8s-logs
hostPath:
path: /var/log/messages
- name: filebeat-config
configMap:
name: k8s-logs-filebeat-config
3.应用filebeat资源清单文件
kubectl apply -f filebeat-to-logstash.yaml
4.验证结果
kubectl get pod -n kube-system -o wide
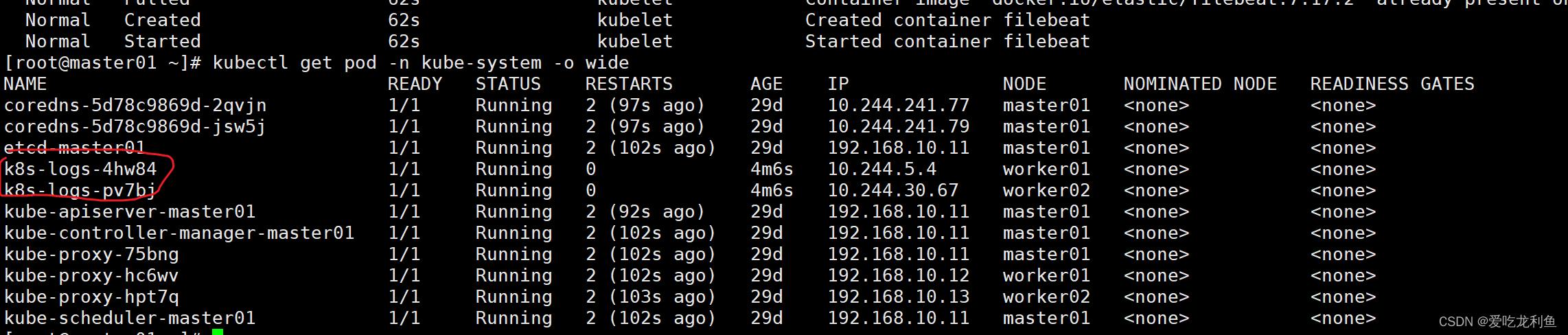
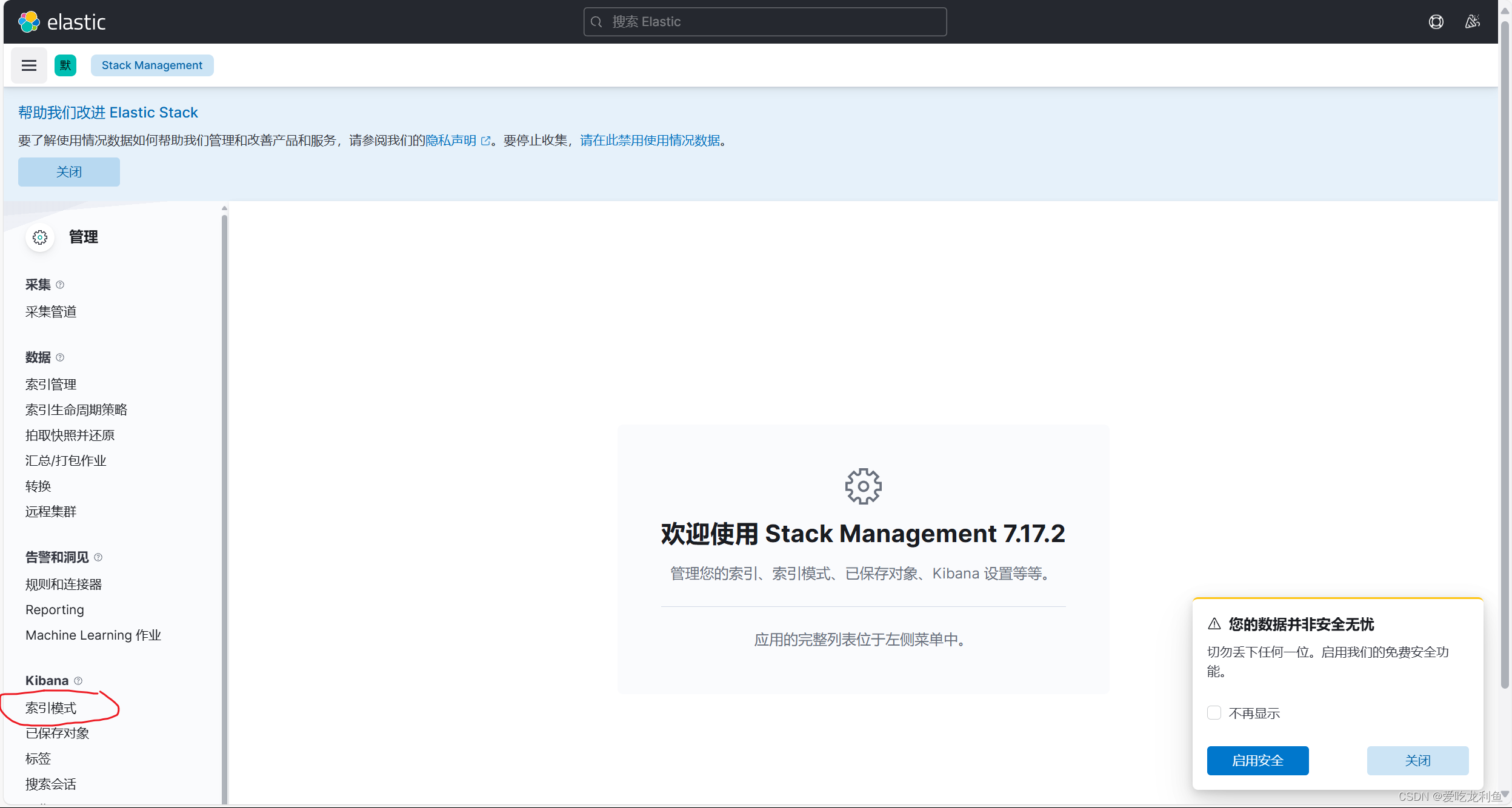
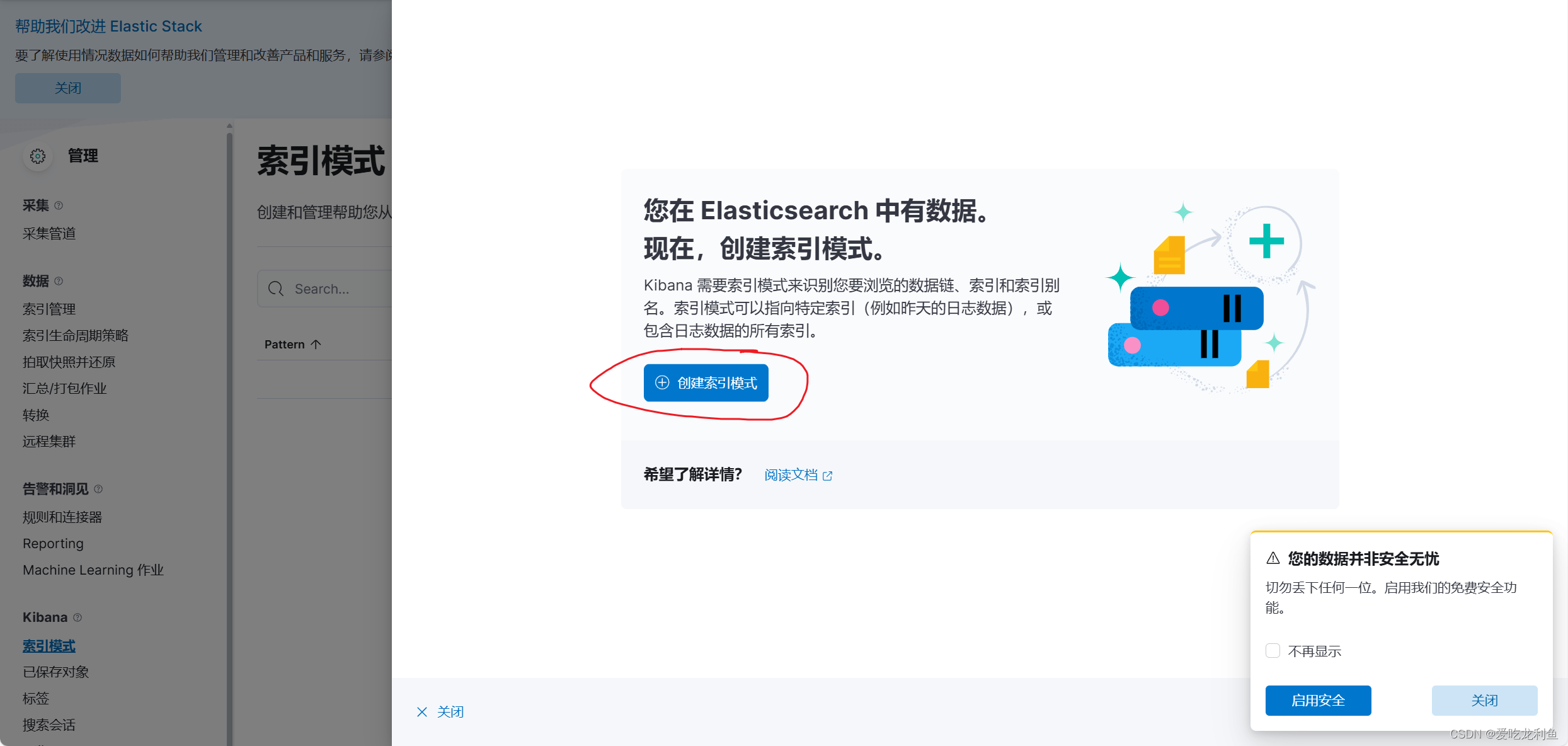
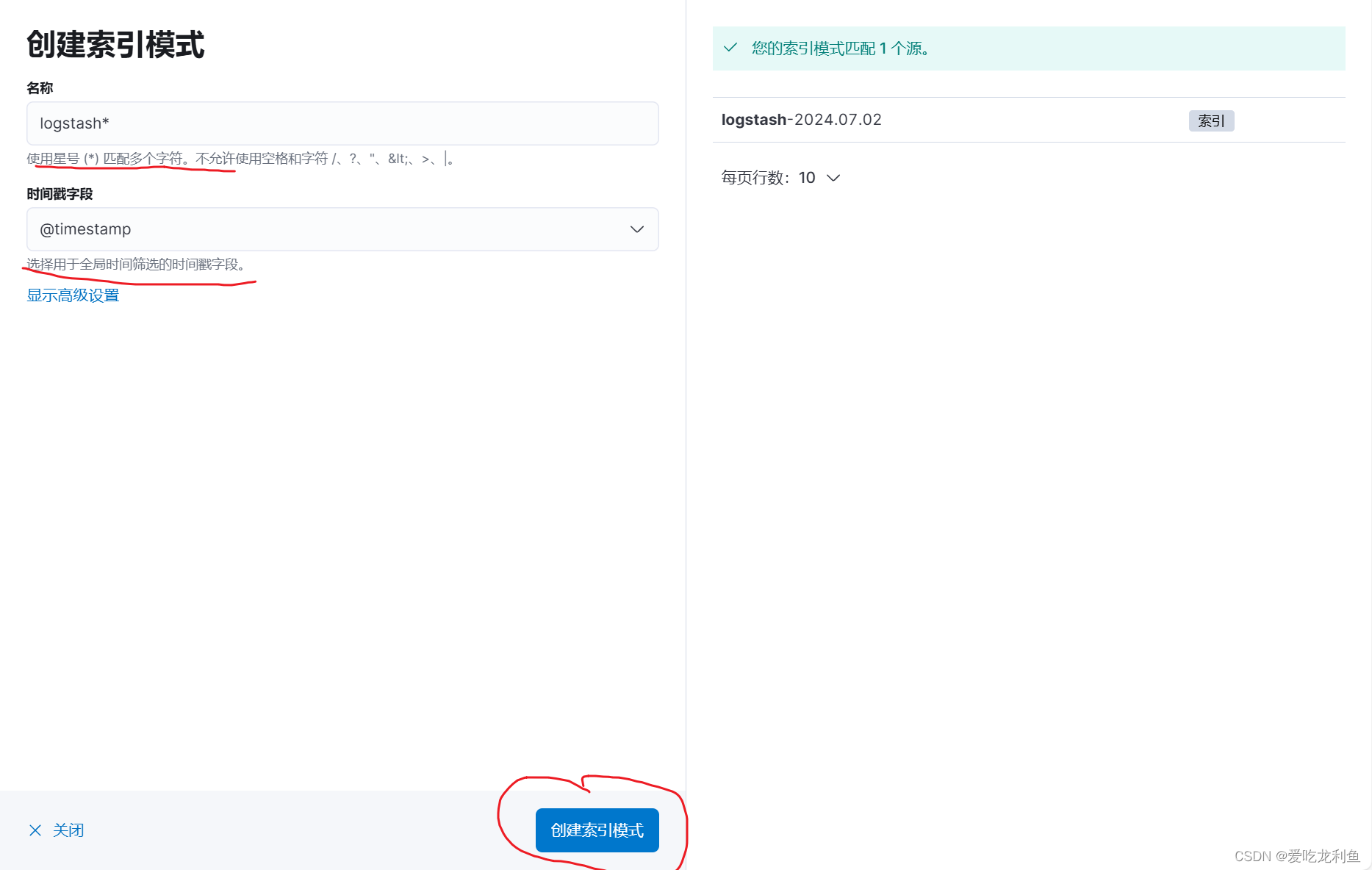
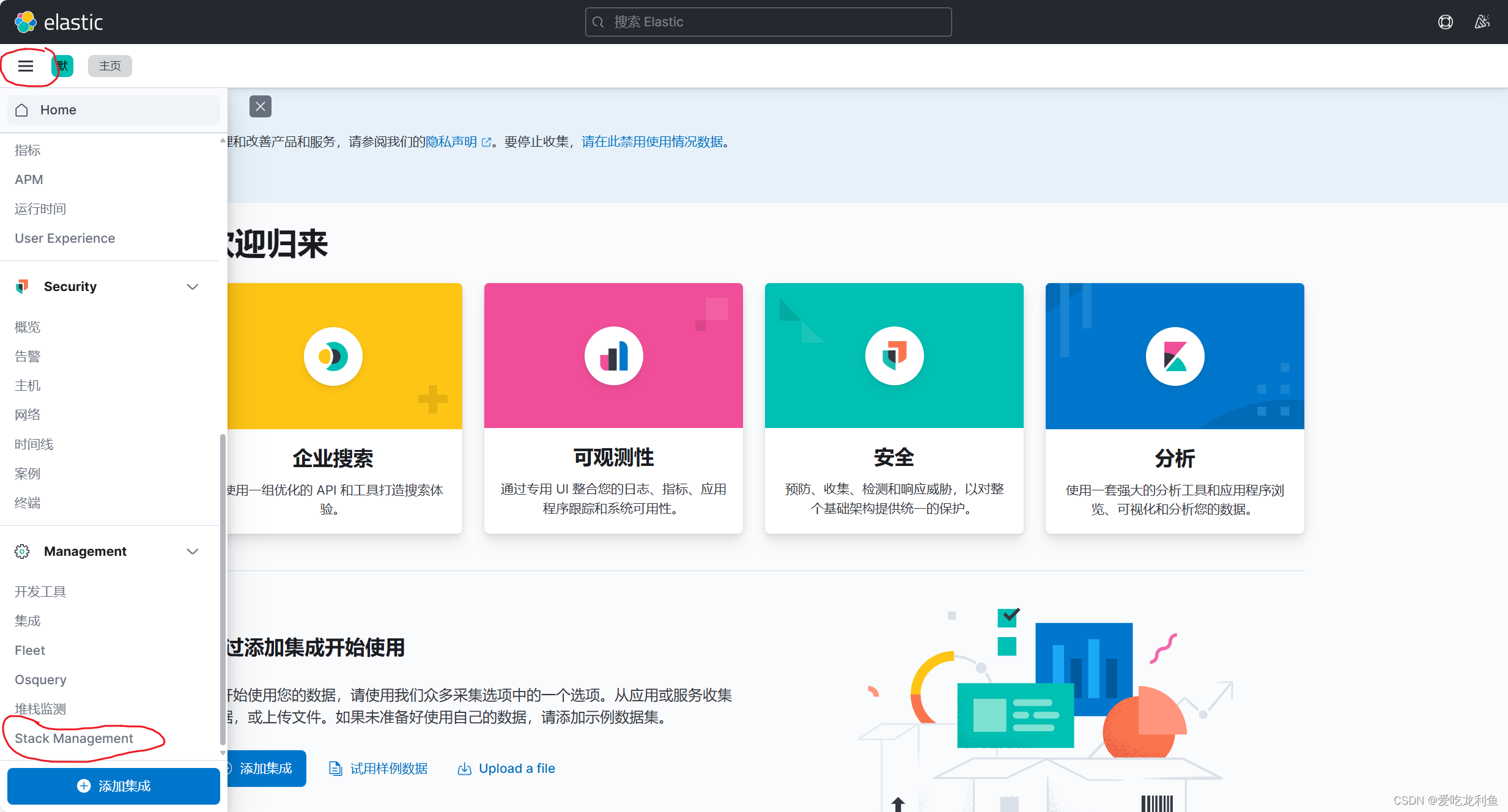
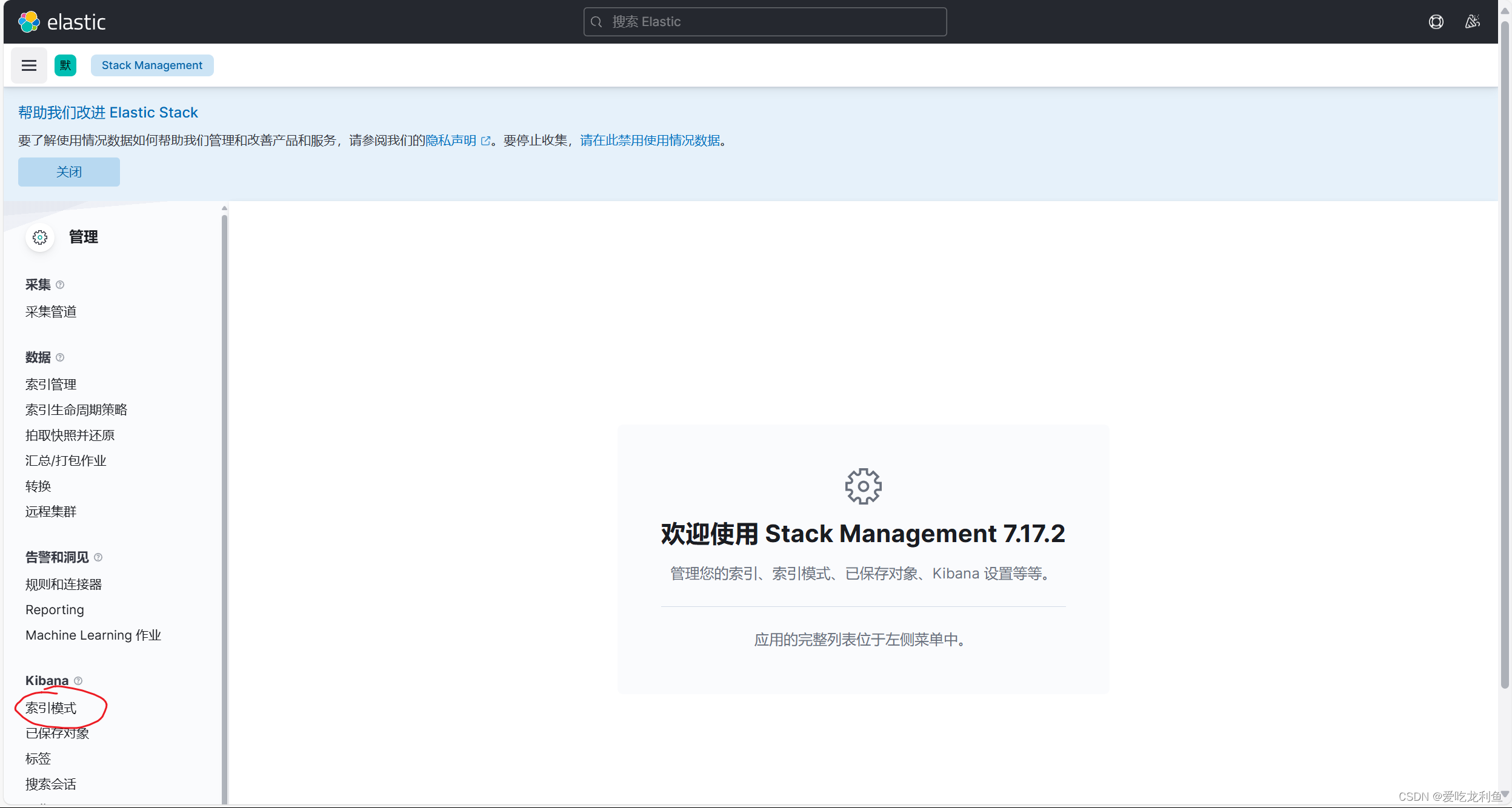
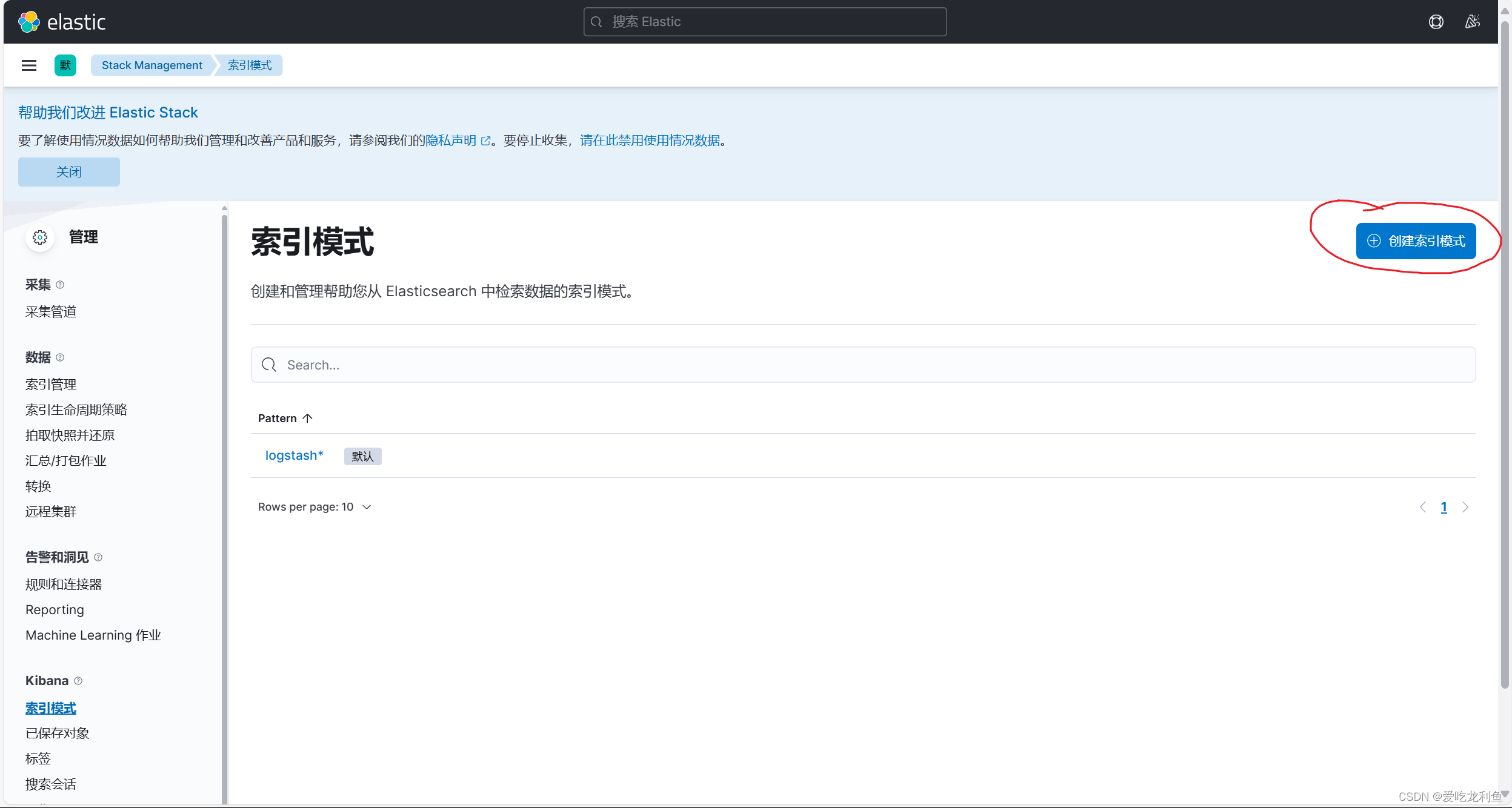
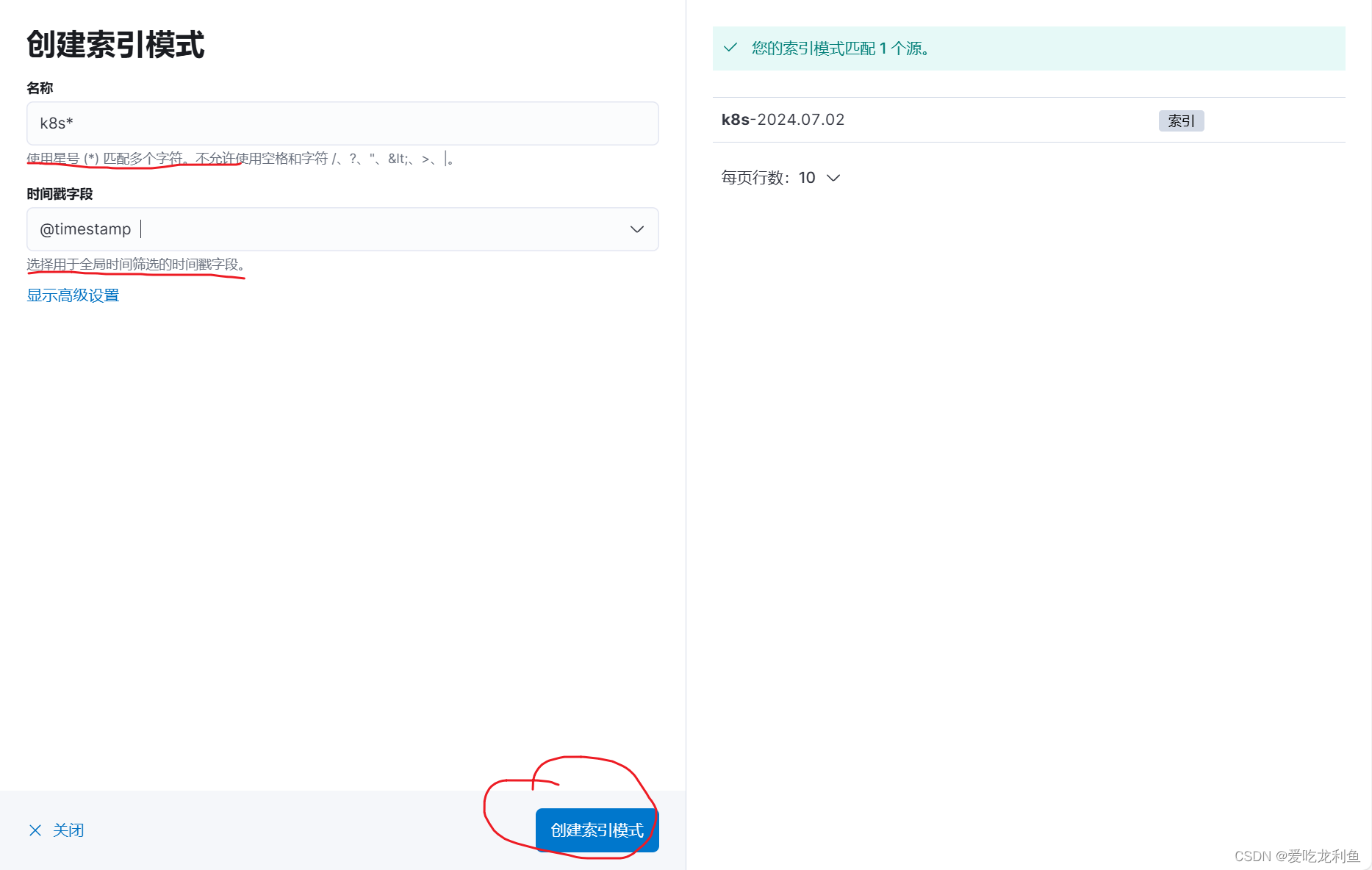
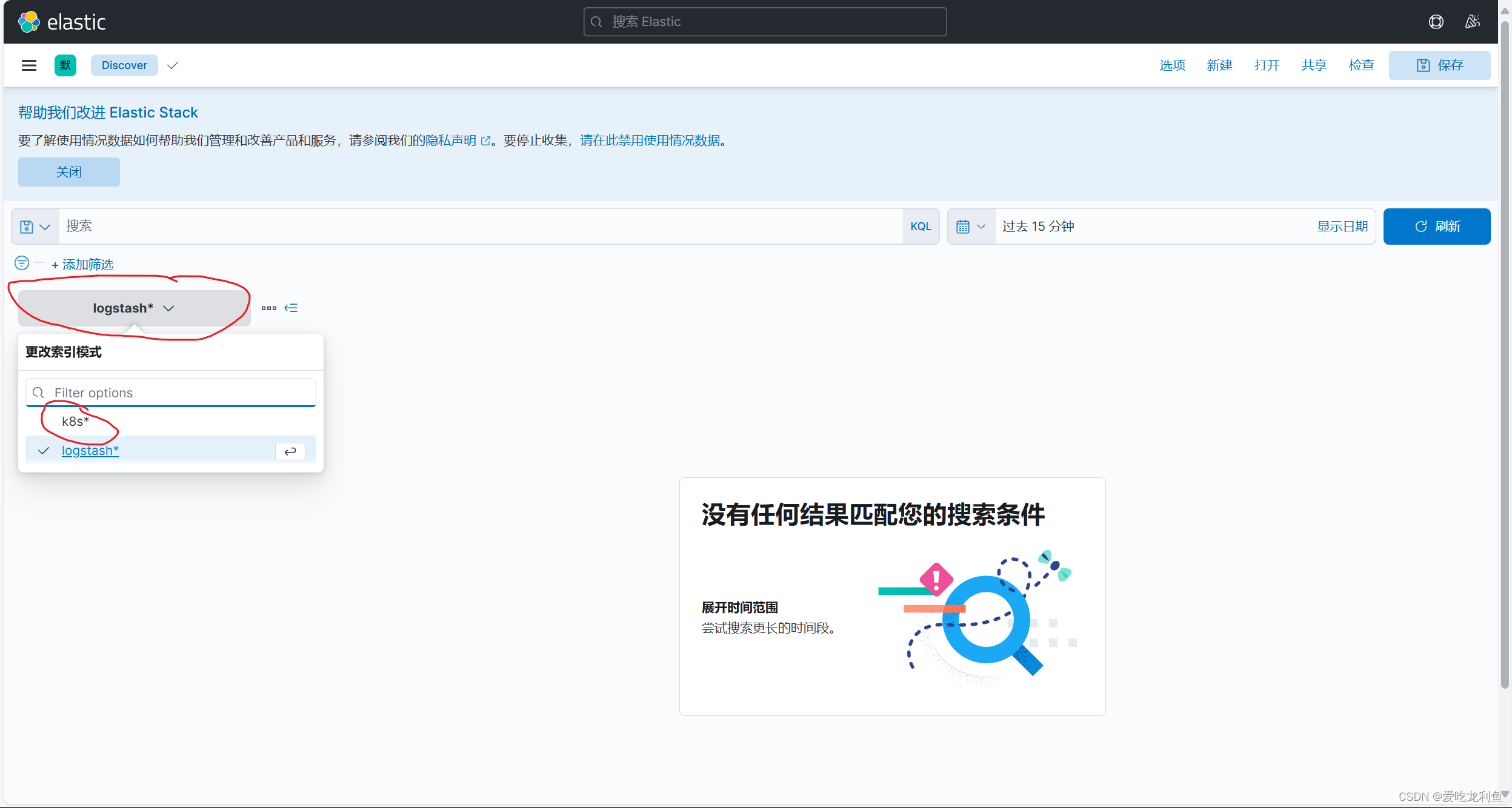
5.在kibana中添加索引
宿主机浏览器访问192.168.10.17:5601
web页面操作
基本和上次一样

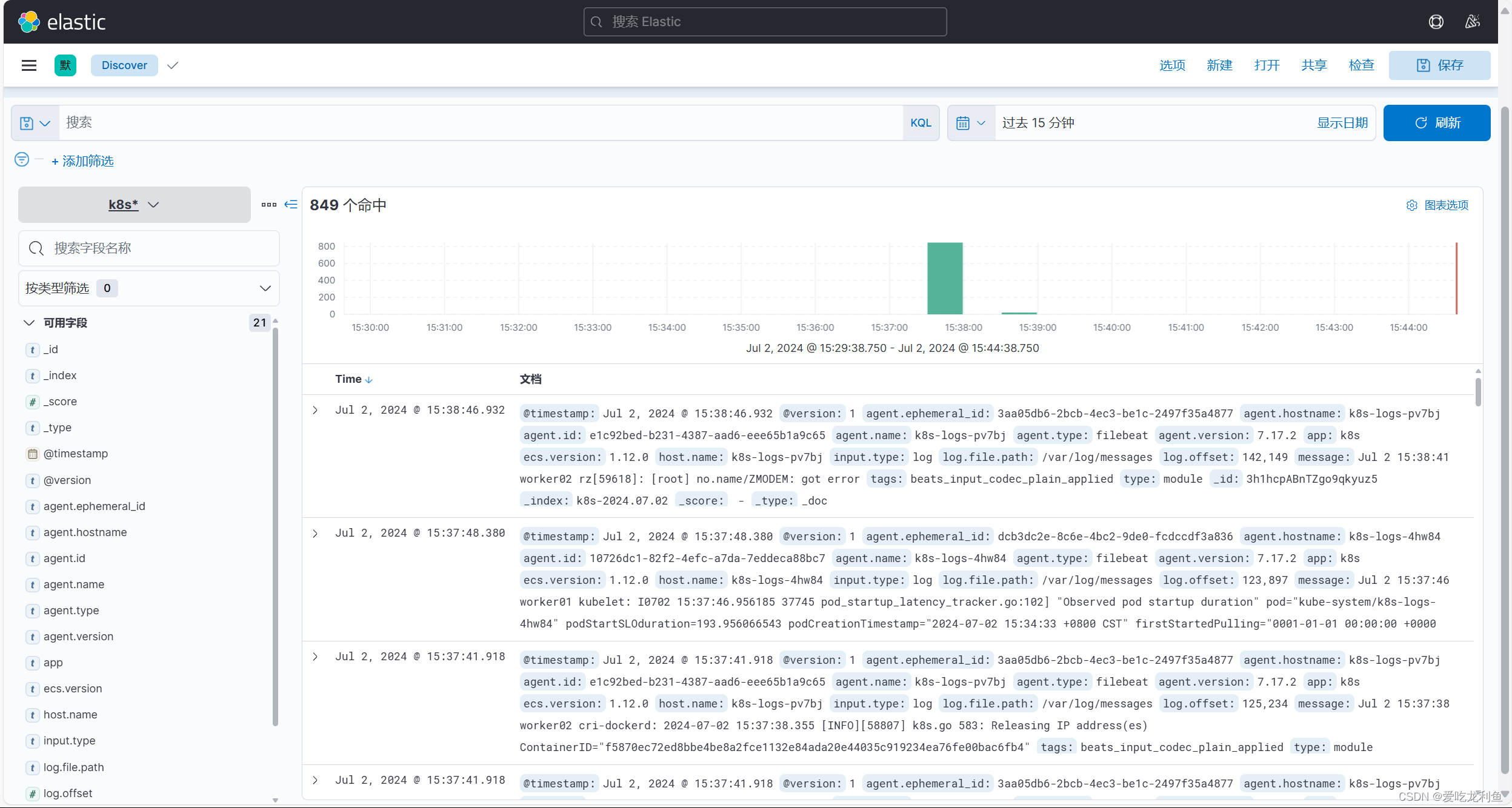
现在就能看到日志了
这是系统日志
后面还会写怎么看应用程序的日志
以及容器内部署的应用程序日志
写完已经快噶了
应该会隔一天
如果对您有帮助可以点下关注