项目名称与项目简介
图书馆书籍管理系统
本项目是一个计算机管理系统,也就是将传统手工的管理方式转变为智能化、标准化、规范化的管理管理模式,对图书馆中所有的图书、文献资料、音像资料、报刊、期刊等各种类型的资料实现采编、收集图书信息、检索、归档、流通以及一系列相关工作的计算机化、信息化管理。
创建数据库
LibraryDB库——utf8字符集——utf8_general_ci排序规则
先创建库,再去使用下列的DDL语句。
数据库DDL
-- 创建Authors表
CREATE TABLE `authors` (
`AuthorID` int(11) NOT NULL AUTO_INCREMENT COMMENT '作者ID',
`Name` varchar(100) NOT NULL COMMENT '姓名',
`Country` varchar(50) DEFAULT NULL COMMENT '国家',
PRIMARY KEY (`AuthorID`)
);
-- 创建Publishers
CREATE TABLE `publishers` (
`PublisherID` int(11) NOT NULL AUTO_INCREMENT COMMENT '出版社ID',
`Name` varchar(100) NOT NULL COMMENT '出版社名称',
`Country` varchar(50) DEFAULT NULL COMMENT '出版社国家',
PRIMARY KEY (`PublisherID`)
);
-- 创建Categories表
CREATE TABLE `categories` (
`CategoryID` int(11) NOT NULL AUTO_INCREMENT COMMENT '类别ID',
`Name` varchar(50) NOT NULL COMMENT '类别名称',
PRIMARY KEY (`CategoryID`)
);
-- 创建Books表
CREATE TABLE `books` (
`BookID` int(11) NOT NULL AUTO_INCREMENT COMMENT '书籍ID',
`Title` varchar(200) NOT NULL COMMENT '书籍名称',
`AuthorID` int(11) DEFAULT NULL COMMENT '作者ID',
`PublisherID` int(11) DEFAULT NULL COMMENT '出版社ID',
`CategoryID` int(11) DEFAULT NULL COMMENT '类别ID',
`YearPublished` varchar(4) DEFAULT NULL COMMENT '出版年份',
`Stock` int(255) DEFAULT NULL COMMENT '库存',
PRIMARY KEY (`BookID`),
KEY `AuthorID` (`AuthorID`),
KEY `PublisherID` (`PublisherID`),
KEY `CategoryID` (`CategoryID`),
CONSTRAINT `books_ibfk_1` FOREIGN KEY (`AuthorID`) REFERENCES `authors` (`AuthorID`) ON DELETE NO ACTION ON UPDATE NO ACTION,
CONSTRAINT `books_ibfk_2` FOREIGN KEY (`PublisherID`) REFERENCES `publishers` (`PublisherID`) ON DELETE NO ACTION ON UPDATE NO ACTION,
CONSTRAINT `books_ibfk_3` FOREIGN KEY (`CategoryID`) REFERENCES `categories` (`CategoryID`) ON DELETE NO ACTION ON UPDATE NO ACTION
);
-- 创建Members表
CREATE TABLE `members` (
`MemberID` int(11) NOT NULL AUTO_INCREMENT COMMENT '用户ID',
`Name` varchar(100) NOT NULL COMMENT '用户姓名',
`Email` varchar(100) NOT NULL COMMENT '邮箱',
`Phone` varchar(15) DEFAULT NULL COMMENT '电话',
PRIMARY KEY (`MemberID`),
UNIQUE KEY `Email` (`Email`)
);
-- 创建Loans表
CREATE TABLE `loans` (
`LoanID` int(11) NOT NULL AUTO_INCREMENT COMMENT '借书ID',
`BookID` int(11) DEFAULT NULL COMMENT '书籍ID',
`MemberID` int(11) DEFAULT NULL COMMENT '用户ID',
`LoanDate` date DEFAULT NULL COMMENT '借书日期',
`ReturnDate` date DEFAULT NULL COMMENT '归还日期',
PRIMARY KEY (`LoanID`),
KEY `BookID` (`BookID`),
KEY `MemberID` (`MemberID`),
CONSTRAINT `loans_ibfk_1` FOREIGN KEY (`BookID`) REFERENCES `books` (`BookID`),
CONSTRAINT `loans_ibfk_2` FOREIGN KEY (`MemberID`) REFERENCES `members` (`MemberID`)
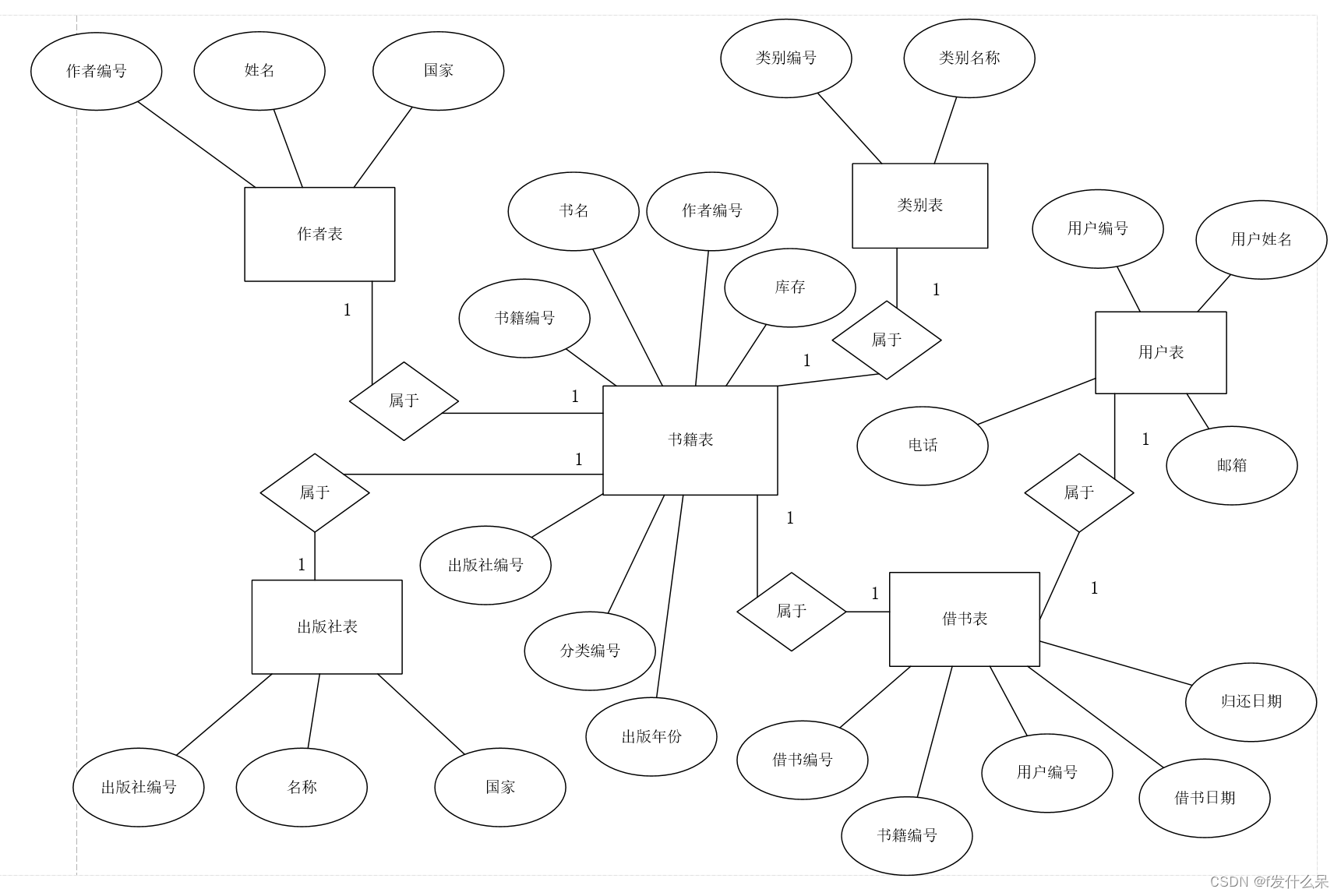
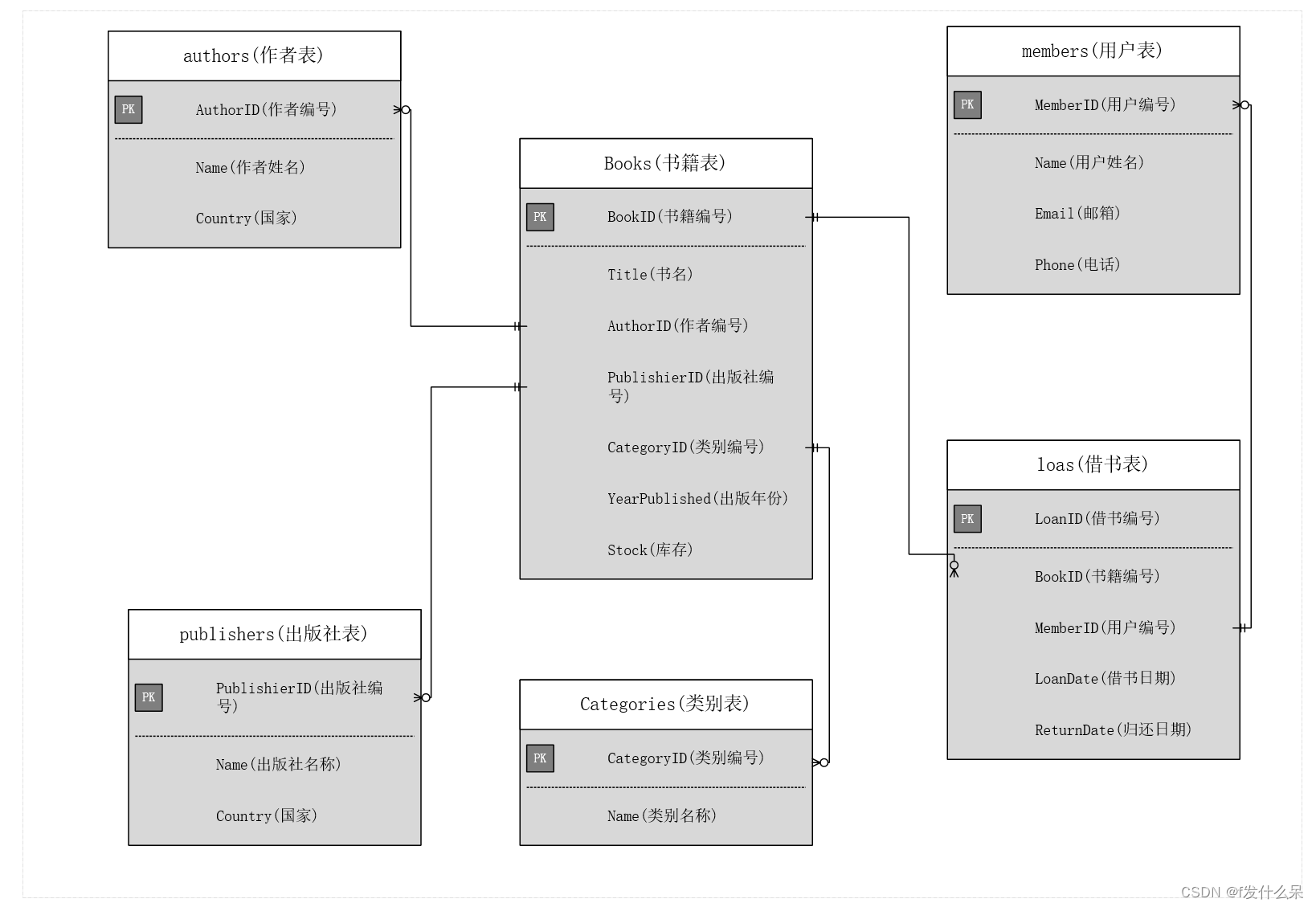
);绘制ER图
插入数据DML
-- 插入 Authors 表的数据
INSERT INTO Authors (Name, Country) VALUES
('鲁迅', 'China'),
('金庸', 'China'),
('莫言', 'China'),
('余华', 'China'),
('曹雪芹', 'China'),
('J.K. Rowling', 'United Kingdom');
-- 插入 Publishers 表的数据
INSERT INTO Publishers (Name, Country) VALUES
('人民文学出版社', 'China'),
('中华书局', 'China'),
('作家出版社', 'China'),
('上海译文出版社', 'China'),
('中国青年出版社', 'China'),
('Bloomsbury', 'UK');
-- 插入 Categories 表的数据
INSERT INTO Categories (Name) VALUES
('小说'),
('历史'),
('散文'),
('科幻'),
('文学');
-- 插入 Books 表的数据
INSERT INTO Books (Title, AuthorID, PublisherID, CategoryID, YearPublished,Stock) VALUES
('呐喊', 1, 1, 5, 1923, 30),
('射雕英雄传', 2, 2, 1, 1957, 28),
('红高粱家族', 3, 3, 1, 1986, 25),
('活着', 4, 4, 1, 1993, 44),
('红楼梦', 5, 5, 1, 1791, 36),
('Harry Potter and the Philosopher''s Stone', 6, 6, 4, '1997', 50);
-- 插入 Members 表的数据
INSERT INTO Members (Name, Email, Phone) VALUES
('张伟', 'zhang.wei@example.com', '1234561234'),
('李娜', 'li.na@example.com', '1234565678'),
('王芳', 'wang.fang@example.com', '1234568765'),
('刘强', 'liu.qiang@example.com', '1234564321'),
('陈静', 'chen.jing@example.com', '1234566789');
-- 插入 Loans 表的数据
INSERT INTO Loans (BookID, MemberID, LoanDate, ReturnDate) VALUES
(1, 1, '2024-06-01', '2024-06-15'),
(2, 2, '2024-06-02', '2024-06-16'),
(3, 3, '2024-06-03', '2024-06-17'),
(4, 4, '2024-06-04', '2024-06-18'),
(5, 3, '2024-06-05', '2024-06-19');
(2, 3, '2024-06-11', '2024-06-25'),
(3, 4, '2024-06-12', '2024-06-26'),
(4, 5, '2024-06-13', '2024-06-27'),
(5, 1, '2024-06-14', '2024-06-28'),
(1, 3, '2024-06-15', '2024-06-29'),
(2, 4, '2024-06-16', '2024-06-30'),
(3, 5, '2024-06-17', '2024-07-01'),
(4, 1, '2024-06-18', '2024-07-02'),
(5, 2, '2024-06-19', '2024-07-03');基础查询
1、查询所有书籍信息,仅显示书籍的名称和出版年份
SELECT Title AS '书籍名称', YearPublished AS '出版年份' FROM books;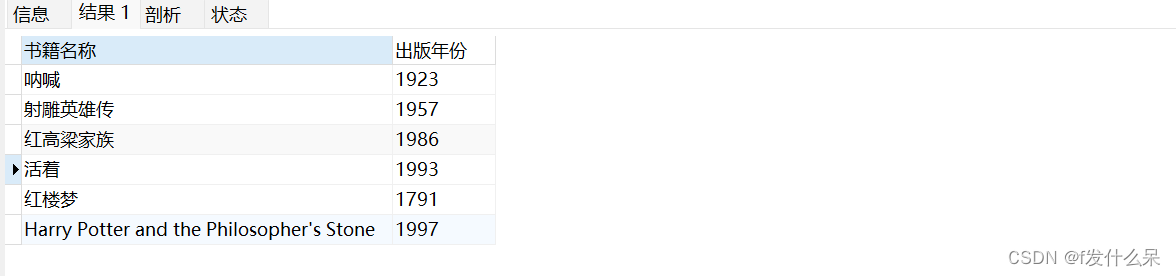
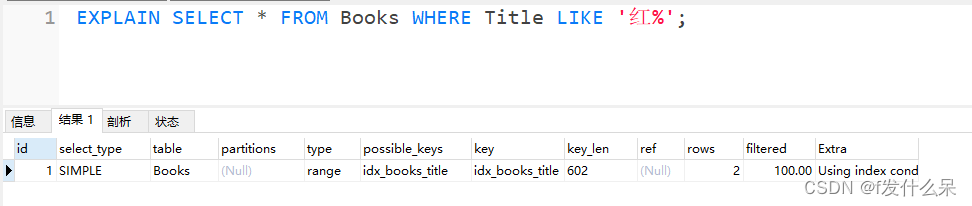
2、模糊查询
根据书籍名称进行模糊查询,模糊查询需要可以走索引,需要给出explain语句。使用explain测试给出的查询语句,需要显示走了索引查询。
创建索引
CREATE INDEX idx_books_title ON Books(Title);
使用EXPLAIN进行模糊查询
EXPLAIN SELECT * FROM Books WHERE Title LIKE '红%';
3、统计书籍信息,查询所有书籍的出版年份,并按照年份从早到晚排列
SELECT Title AS '书名', YearPublished AS '出版年份'
FROM Books
ORDER BY YearPublished ASC;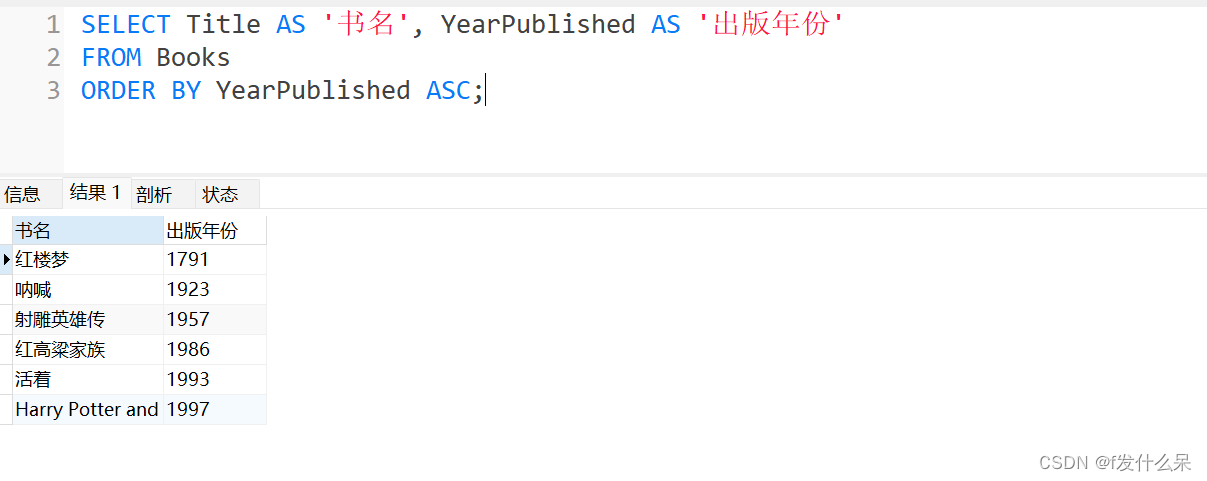
3、复杂查询
1、查询书籍的所有信息(书名、作者名、出版商名、分类、出版年份)
SELECT
Books.Title AS 书名,
Authors.Name AS 作者,
Publishers.Name AS 出版社名称,
Categories.Name AS 分类,
Books.YearPublished AS 出版年份
FROM Books
JOIN Authors ON Books.AuthorID = Authors.AuthorID
JOIN Publishers ON Books.PublisherID = Publishers.PublisherID
JOIN Categories ON Books.CategoryID = Categories.CategoryID;
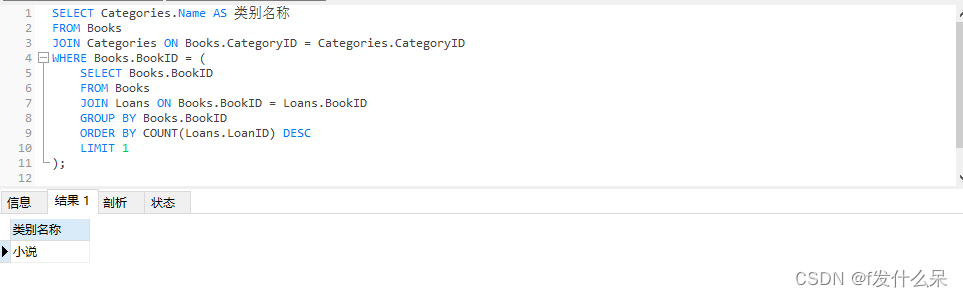
2、查询书籍中被借出去最多的书籍对应的类别名称
SELECT Categories.Name AS 类别名称
FROM Books
JOIN Categories ON Books.CategoryID = Categories.CategoryID
WHERE Books.BookID = (
SELECT Books.BookID
FROM Books
JOIN Loans ON Books.BookID = Loans.BookID
GROUP BY Books.BookID
ORDER BY COUNT(Loans.LoanID) DESC
LIMIT 1
);
3、查询借书数量最多的用户,并查询用户借书的书籍名称
SELECT
Members.Name AS 用户姓名,
Books.Title AS 书名
FROM Members
JOIN Loans ON Members.MemberID = Loans.MemberID
JOIN Books ON Loans.BookID = Books.BookID
WHERE Members.MemberID = (
SELECT Loans.MemberID
FROM Loans
GROUP BY Loans.MemberID
ORDER BY COUNT(Loans.LoanID) DESC
LIMIT 1
);
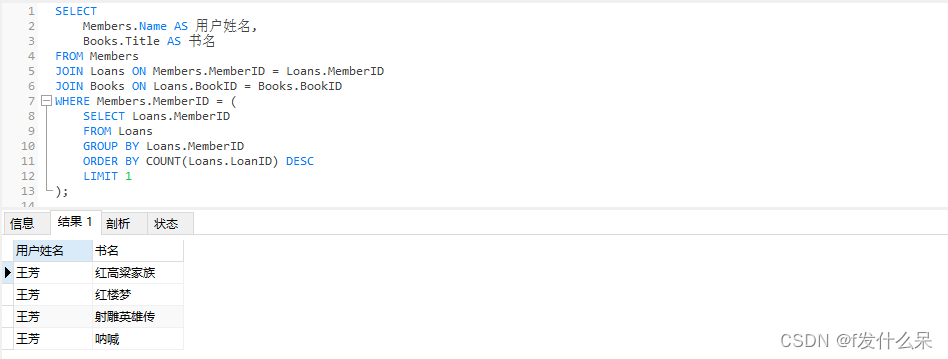
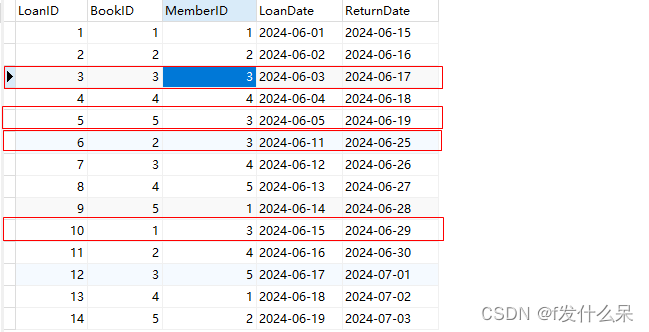
对应3号是王芳,结果正确,没有问题。
触发器
1、书籍表添加语句添加触发器,要求在添加书籍信息时同时初始化作者表数据。触发器应该在插入新书籍信息时,检查作者表中是否已存在相同的作者,如果不存在,则插入新的作者信息。
-- 触发器名称:after_book_insert
-- 功能描述:插入新书籍信息时,检查作者表中是否已存在相同的作者,如果不存在,则插入新的作者信息。
-- 触发时机:AFTER INSERT
-- 触发对象:books表
-- 触发行为:FOR EACH ROW(对每一行插入操作触发)
DELIMITER $$ -- 更改默认的语句分隔符为$$,这样可以在触发器内部使用分号
CREATE TRIGGER after_book_insert -- 创建一个名为after_book_insert的触发器
AFTER INSERT ON books -- 触发器在Books表发生INSERT操作之后触发
FOR EACH ROW -- 触发器对每一行插入操作都执行一次
BEGIN -- 触发器开始
DECLARE authorID INT;
-- 检查是否存在相同作者名字的记录
SELECT AuthorID INTO authorID
FROM authors
WHERE Name = NEW.Title;
-- 如果作者不存在,则插入新的作者信息
IF authorID IS NULL THEN
INSERT INTO authors (Name, Country)
VALUES (NEW.Title, 'Unknown');
-- 获取新插入的作者的ID
SET authorID = LAST_INSERT_ID();
END IF;
-- 更新 Books 表中的 AuthorID 字段
UPDATE books
SET AuthorID = authorID
WHERE BookID = NEW.BookID;
END; -- 触发器结束
$$ -- 触发器定义结束,使用新的分隔符
DELIMITER ; -- 将语句分隔符改回为分号测试语句
-- 向 books 表插入新书籍信息
INSERT INTO books (Title, PublisherID, CategoryID, YearPublished)
VALUES ('活着', 1, 1, '1993');
测试结果

2、书籍表修改语句添加触发器,要求在修改库存时不允许上下浮动超过10%
DELIMITER $$ -- 更改默认的语句分隔符为$$,这样可以在触发器内部使用分号
CREATE TRIGGER Before_Stock_Update -- 创建一个名为Before_Stock_Update的触发器
BEFORE UPDATE ON books -- 触发器在books表发生UPDATE操作之前触发
FOR EACH ROW -- 触发器对每一行更改操作都执行一次
BEGIN -- 触发器开始
DECLARE old_stock INT; -- 声明变量
DECLARE new_stock INT;
DECLARE max_allowed INT;
DECLARE min_allowed INT;
-- 获取旧的库存和新的库存
SET old_stock = OLD.Stock;
SET new_stock = NEW.Stock;
-- 计算允许的最大和最小库存变化
SET max_allowed = old_stock + (old_stock * 0.10);
SET min_allowed = old_stock - (old_stock * 0.10);
-- 如果新的库存超出允许的变化范围,则抛出错误
IF new_stock > max_allowed OR new_stock < min_allowed THEN
SIGNAL SQLSTATE '45000'
SET MESSAGE_TEXT = '库存变化不能超过10%';
END IF;
END; -- 触发器结束
$$ -- 触发器定义结束,使用新的分隔符
DELIMITER ; -- 将语句分隔符改回为分号
测试语句
-- 合法的库存更新(变化不超过10%)
UPDATE books SET Stock = 33 WHERE BookID = 1;
-- 非法的库存更新(变化超过10%)
UPDATE books SET Stock = 50 WHERE BookID = 1;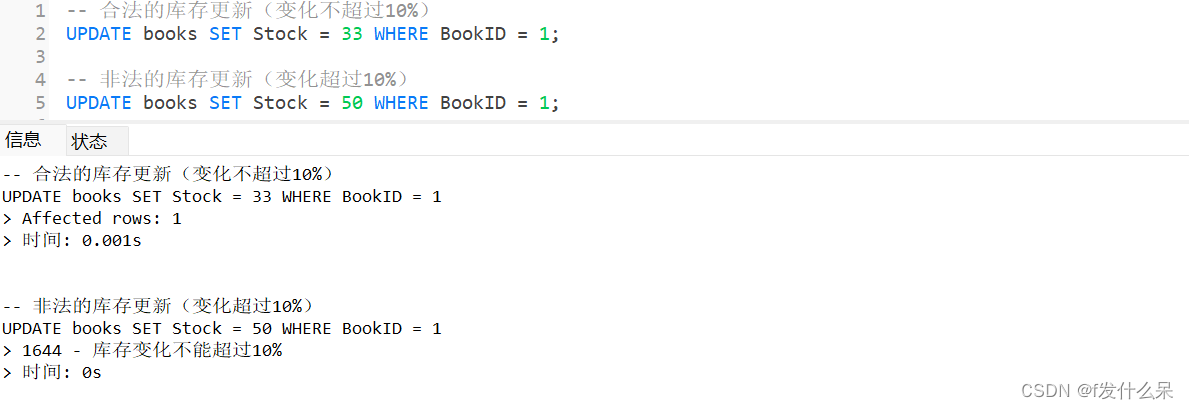

3、用户表删除语句添加触发器,要求在删除用户信息时先删除借书表中的用户信息。
DELIMITER $$ -- 更改默认的语句分隔符为$$,这样可以在触发器内部使用分号
CREATE TRIGGER Before_Member_Delete -- 创建一个名为Before_Member_Delete的触发器
BEFORE DELETE ON members -- 触发器在members表发生DELETE操作之前触发
FOR EACH ROW -- 触发器对每一行更改操作都执行一次
BEGIN -- 触发器开始
-- 删除与该用户相关的所有借书记录
DELETE FROM loans WHERE MemberID = OLD.MemberID;
END; -- 触发器结束
$$ -- 触发器定义结束,使用新的分隔符
DELIMITER ; -- 将语句分隔符改回为分号测试语句
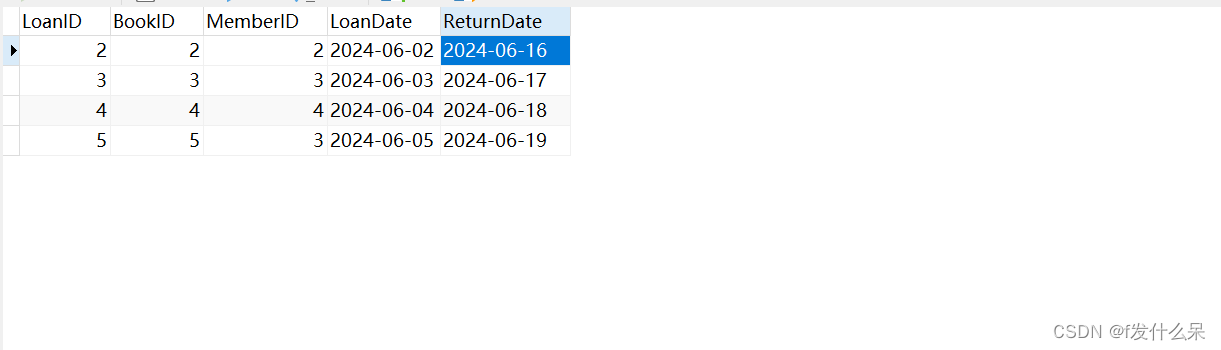
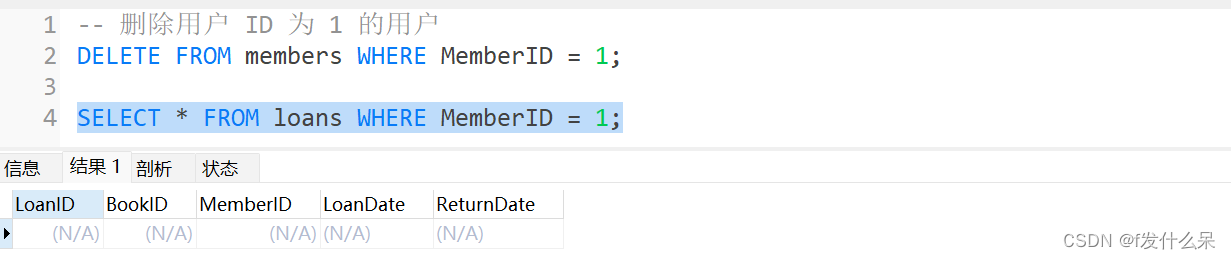
-- 删除用户 ID 为 1 的用户
DELETE FROM members WHERE MemberID = 1;检查loans表,确保删除的用户ID为1借书记录已被删除。
存储过程创建
DELIMITER $$ -- 更改默认的语句分隔符为$$,
CREATE PROCEDURE AddBook( -- 创建名为 AddBook 的存储过程
IN p_Title VARCHAR(200), -- 书籍名称
IN p_AuthorName VARCHAR(100), -- 作者姓名
IN p_PublisherName VARCHAR(100), -- 出版社名称
IN p_CategoryName VARCHAR(50), -- 类别名称
IN p_YearPublished VARCHAR(4), -- 出版年份
IN p_Stock INT -- 库存
)
BEGIN
-- 声明变量
DECLARE v_AuthorID INT;
DECLARE v_PublisherID INT;
DECLARE v_CategoryID INT;
-- 检查并插入作者信息:
SELECT AuthorID INTO v_AuthorID FROM authors WHERE Name = p_AuthorName;
IF v_AuthorID IS NULL THEN
INSERT INTO authors (Name) VALUES (p_AuthorName);
SET v_AuthorID = LAST_INSERT_ID();
END IF;
-- 检查并插入出版社信息:
SELECT PublisherID INTO v_PublisherID FROM publishers WHERE Name = p_PublisherName;
IF v_PublisherID IS NULL THEN
INSERT INTO publishers (Name) VALUES (p_PublisherName);
SET v_PublisherID = LAST_INSERT_ID();
END IF;
-- 检查并插入类别信息:
SELECT CategoryID INTO v_CategoryID FROM categories WHERE Name = p_CategoryName;
IF v_CategoryID IS NULL THEN
INSERT INTO categories (Name) VALUES (p_CategoryName);
SET v_CategoryID = LAST_INSERT_ID();
END IF;
-- 插入书籍信息
INSERT INTO books (Title, AuthorID, PublisherID, CategoryID, YearPublished, Stock)
VALUES (p_Title, v_AuthorID, v_PublisherID, v_CategoryID, p_YearPublished, p_Stock);
END $$ -- 分隔符终止
DELIMITER ; -- 分隔符结束详细解析
DELIMITER $$ -- 更改默认的语句分隔符为$$
CREATE PROCEDURE AddBook
创建名为
AddBook的存储过程,接收以下输入参数:
p_Title: 书籍名称
p_AuthorName: 作者姓名
p_PublisherName: 出版社名称
p_CategoryName: 类别名称
p_YearPublished: 出版年份
p_Stock: 库存
BEGIN -- 开始存储过程的主体部分
DECLARE v_AuthorID INT;
DECLARE v_PublisherID INT;
DECLARE v_CategoryID INT;声明
v_AuthorID、v_PublisherID和v_CategoryID变量,用于存储对应表中的ID。
SELECT AuthorID INTO v_AuthorID FROM authors WHERE Name = p_AuthorName;
IF v_AuthorID IS NULL THEN
INSERT INTO authors (Name) VALUES (p_AuthorName);
SET v_AuthorID = LAST_INSERT_ID();
END IF;检查并插入作者信息:
使用
SELECT查询authors表中是否存在输入的作者姓名。如果不存在(
v_AuthorID为 NULL),则插入新的作者记录,并获取新插入的作者ID。
SELECT PublisherID INTO v_PublisherID FROM publishers WHERE Name = p_PublisherName;
IF v_PublisherID IS NULL THEN
INSERT INTO publishers (Name) VALUES (p_PublisherName);
SET v_PublisherID = LAST_INSERT_ID();
END IF;检查并插入出版社信息:
使用
SELECT查询publishers表中是否存在输入的出版社名称。如果不存在(
v_PublisherID为 NULL),则插入新的出版社记录,并获取新插入的出版社ID。
SELECT CategoryID INTO v_CategoryID FROM categories WHERE Name = p_CategoryName;
IF v_CategoryID IS NULL THEN
INSERT INTO categories (Name) VALUES (p_CategoryName);
SET v_CategoryID = LAST_INSERT_ID();
END IF;检查并插入类别信息:
使用
SELECT查询categories表中是否存在输入的类别名称。如果不存在(
v_CategoryID为 NULL),则插入新的类别记录,并获取新插入的类别ID。
INSERT INTO books (Title, AuthorID, PublisherID, CategoryID, YearPublished, Stock)
VALUES (p_Title, v_AuthorID, v_PublisherID, v_CategoryID, p_YearPublished, p_Stock);插入书籍信息:
将书籍信息插入
books表中,使用上面获取的AuthorID、PublisherID和CategoryID,以及输入的书籍名称、出版年份和库存。
测试语句
CALL AddBook(
'西游记',
'吴承恩',
'人民文学出版社',
'小说',
'1592',
40
);
-- 检查插入的作者
SELECT * FROM authors WHERE Name IN ('吴承恩');
-- 检查插入的出版社
SELECT * FROM publishers WHERE Name IN ('人民文学出版社');
-- 检查插入的书籍
SELECT * FROM books WHERE Title IN ('西游记');










![[单master节点k8s部署]16.监控系统构建(一)Prometheus介绍](https://img-blog.csdnimg.cn/direct/376c2e4e40bb4d029dc56f77b235178c.jpeg)