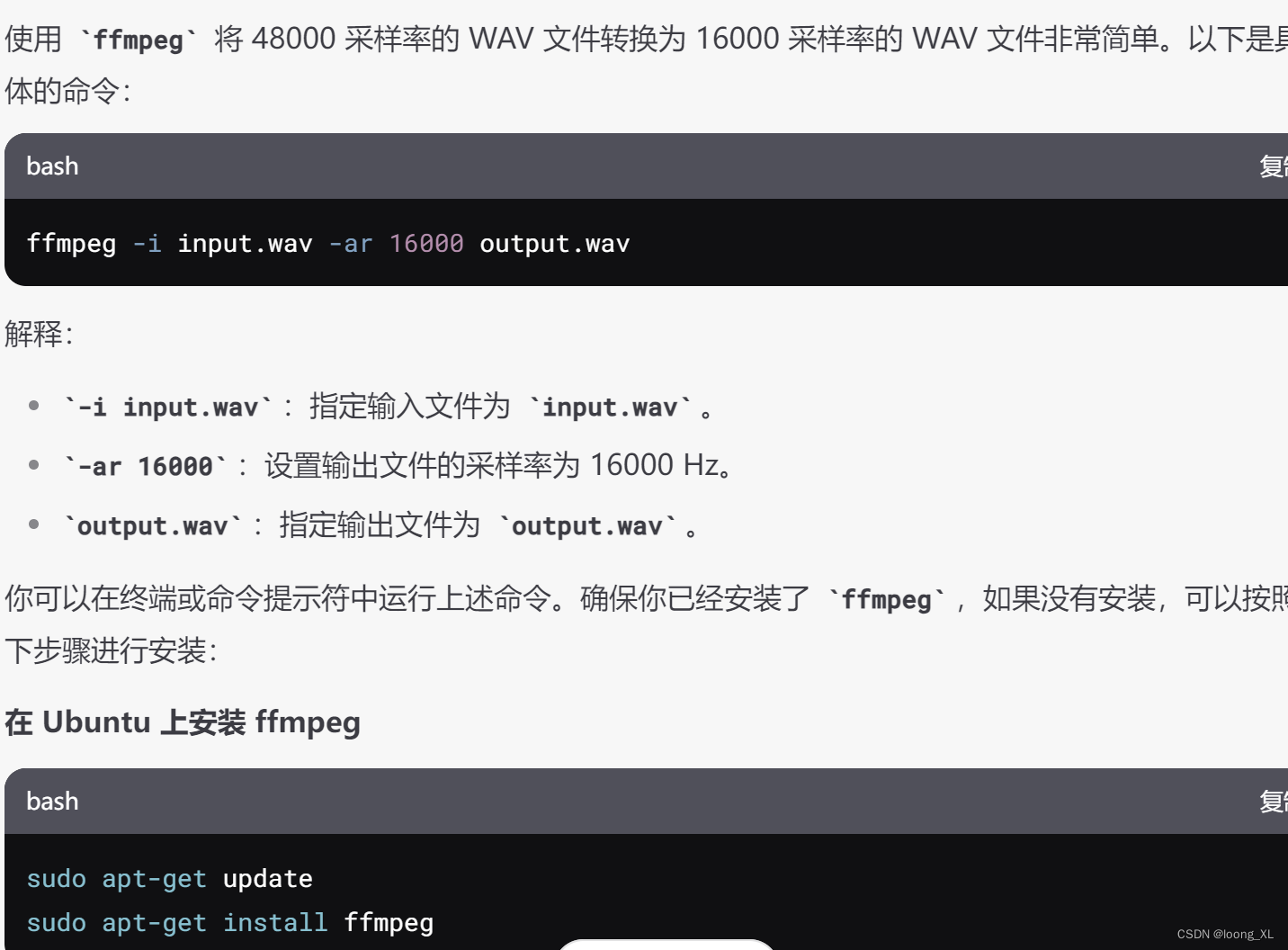
很多大数据开发提供数据给外部系统直接给表结构,这是不好的方式。在不同系统间进行数据交换时,通过API(应用程序编程接口)而非直接访问数据库是现代系统集成的一种最佳实践。
目录
- 为什么要通过API进行数据交换
- 如何通过API进行数据交换
- 实现步骤
- 使用Flask构建RESTful API
- 安装Flask
- API代码示例
- 启动API服务器
- 使用Spring Boot构建RESTful API
- 创建Spring Boot项目并添加依赖
- 创建API控制器
- 创建数据实体和仓库
- 启动Spring Boot应用
- 将大数据平台的数据提供给外部系统
- 使用PySpark读取数据
- 将PySpark数据集成到Flask API
- 总结
为什么要通过API进行数据交换

-
安全性:
- 控制访问:API可以通过认证和授权机制来控制谁可以访问数据。
- 隔离系统:通过API访问数据可以隔离不同系统,减少一个系统的漏洞或故障对其他系统的影响。
-
数据一致性:
- 统一接口:API提供了统一的数据访问接口,可以确保数据的一致性和完整性。
- 减少重复:通过API避免了在多个地方实现相同的数据逻辑,从而减少了重复代码和潜在的错误。

-
维护性和扩展性:
- 模块化设计:API使得系统更加模块化,便于维护和扩展。
- 易于升级:通过API可以更容易地进行系统的升级和更新,而不影响其他系统。

-
日志和监控:
- 跟踪访问记录:API可以记录所有的请求和响应,便于监控和审计。
- 性能监控:通过API可以更容易地监控系统性能,发现和解决瓶颈问题。

如何通过API进行数据交换
-
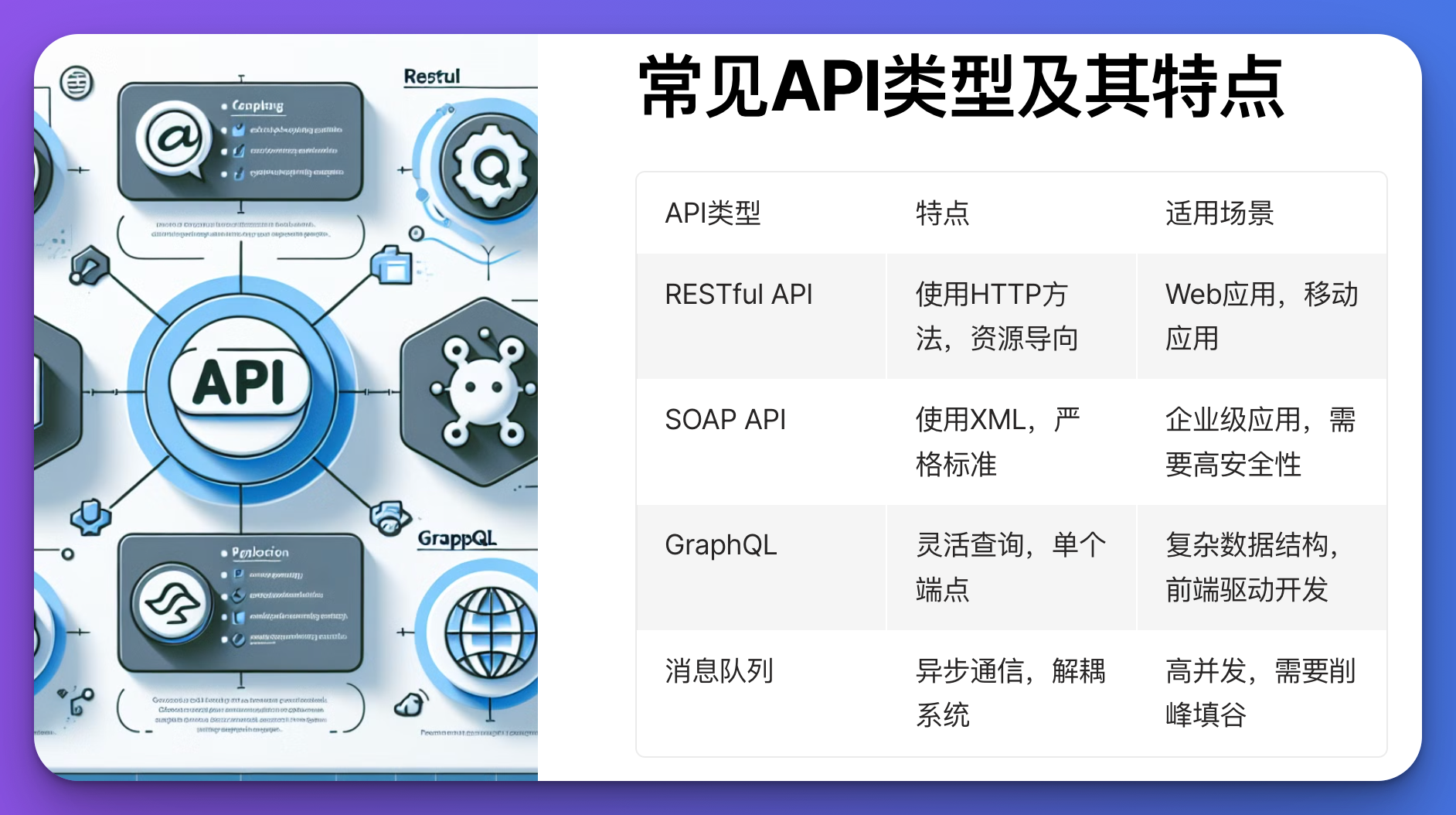
RESTful API:
- 定义资源:每个API端点代表一个资源,如用户、订单等。
- 使用HTTP方法:GET、POST、PUT、DELETE等方法对应于读取、创建、更新、删除操作。
-
SOAP API:
- 使用XML:SOAP(简单对象访问协议)使用XML格式来定义消息结构。
- 更严格的标准:SOAP提供了更严格的协议和标准,适用于需要高安全性和事务处理的场景。
-
GraphQL:
- 灵活查询:允许客户端指定需要的数据结构,减少数据传输量。
- 单个端点:通过单个端点提供数据查询和操作,简化接口管理。
-
消息队列:
- 异步通信:使用消息队列(如RabbitMQ、Kafka)可以实现系统间的异步数据传输。
- 解耦系统:通过消息队列可以解耦生产者和消费者,提升系统的扩展性和可靠性。
实现步骤

-
需求分析:
- 确定需要交换的数据和操作,设计API接口和数据模型。
-
API设计:
- 选择合适的API风格(RESTful、SOAP、GraphQL等)。
- 定义API端点、请求方法、参数和响应格式。
-
安全机制:
- 实现认证(如OAuth、JWT)和授权机制。
- 确保数据传输的安全性(如HTTPS)。
-
开发和测试:
- 开发API,并进行单元测试和集成测试。
- 使用工具(如Postman、Swagger)进行测试和文档编写。
-
部署和监控:
- 部署API服务,并设置日志和监控系统。
- 定期检查和优化API性能和安全性。
通过API进行数据交换不仅提高了系统的安全性和维护性,还增强了系统的扩展能力和灵活性,是现代系统架构设计中的重要实践。

其实开发接口 也不难,以下是一些代码示例和步骤,展示如何使用不同技术栈实现API,并将大数据平台的数据提供给外部系统。
使用Flask构建RESTful API
安装Flask
pip install Flask
API代码示例
from flask import Flask, request, jsonify
import pandas as pd
import json
app = Flask(__name__)
# 示例数据,实际情况中应从大数据平台读取数据
data = {
'id': [1, 2, 3],
'name': ['Alice', 'Bob', 'Charlie'],
'score': [85, 90, 78]
}
df = pd.DataFrame(data)
@app.route('/api/data', methods=['GET'])
def get_data():
result = df.to_dict(orient='records')
return jsonify(result)
@app.route('/api/data/<int:id>', methods=['GET'])
def get_data_by_id(id):
result = df[df['id'] == id].to_dict(orient='records')
if not result:
return jsonify({'error': 'Data not found'}), 404
return jsonify(result[0])
@app.route('/api/data', methods=['POST'])
def add_data():
new_data = request.json
df.append(new_data, ignore_index=True)
return jsonify({'message': 'Data added successfully'}), 201
if __name__ == '__main__':
app.run(debug=True)
启动API服务器
python app.py
使用Spring Boot构建RESTful API
创建Spring Boot项目并添加依赖
在pom.xml文件中添加以下依赖:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>
创建API控制器
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
import java.util.Optional;
@RestController
@RequestMapping("/api/data")
public class DataController {
@Autowired
private DataRepository dataRepository;
@GetMapping
public List<Data> getAllData() {
return dataRepository.findAll();
}
@GetMapping("/{id}")
public Data getDataById(@PathVariable Long id) {
Optional<Data> data = dataRepository.findById(id);
if (data.isPresent()) {
return data.get();
} else {
throw new ResourceNotFoundException("Data not found with id " + id);
}
}
@PostMapping
public Data addData(@RequestBody Data data) {
return dataRepository.save(data);
}
}
创建数据实体和仓库
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class Data {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String name;
private int score;
// getters and setters
}
import org.springframework.data.jpa.repository.JpaRepository;
public interface DataRepository extends JpaRepository<Data, Long> {
}
启动Spring Boot应用
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
将大数据平台的数据提供给外部系统
假设数据存储在Hadoop HDFS中,我们可以使用PySpark读取数据并通过API提供给外部系统。
使用PySpark读取数据
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("Data API") \
.getOrCreate()
# 读取HDFS中的数据
df = spark.read.csv("hdfs://path/to/data.csv", header=True, inferSchema=True)
# 将数据转换为Pandas DataFrame以便使用Flask
pandas_df = df.toPandas()
将PySpark数据集成到Flask API
from flask import Flask, request, jsonify
import pandas as pd
import json
from pyspark.sql import SparkSession
app = Flask(__name__)
# 创建Spark会话
spark = SparkSession.builder \
.appName("Data API") \
.getOrCreate()
# 读取HDFS中的数据
df = spark.read.csv("hdfs://path/to/data.csv", header=True, inferSchema=True)
pandas_df = df.toPandas()
@app.route('/api/data', methods=['GET'])
def get_data():
result = pandas_df.to_dict(orient='records')
return jsonify(result)
@app.route('/api/data/<int:id>', methods=['GET'])
def get_data_by_id(id):
result = pandas_df[pandas_df['id'] == id].to_dict(orient='records')
if not result:
return jsonify({'error': 'Data not found'}), 404
return jsonify(result[0])
if __name__ == '__main__':
app.run(debug=True)
总结

通过构建API,可以安全、有效地将大数据平台的数据提供给外部系统。无论是使用Flask还是Spring Boot,都可以实现RESTful API的构建。同时,结合大数据平台的读取能力(如Hadoop HDFS和PySpark),可以轻松实现数据的获取和提供。