三国演义词频统计与词云图绘制
import jieba
import wordcloud
def analysis():
txt = open("三国演义.txt",'r',encoding='utf-8').read()
words = jieba.lcut(txt)#精确模式
counts = {}
for word in words:
if len(word) == 1:
continue
elif word =="诸葛亮" or word == "孔明曰":
rword = "孔明"
elif word == "关公" or word == "云长":
rword = "关羽"
elif word == "玄德" or word == "玄德曰":
rword = "刘备"
elif word == "孟德" or word == "丞相曰":
rword = "曹操"
elif word == "翼德" or word == "翼德曰":
rword = "张飞"
else:
rword =word
counts[rword] = counts.get(rword,0)+1
items = list(counts.items())
items.sort(key=lambda x :x[1],reverse=True)
txt1 = ''
for i in range(10):
word,count = items[i]#注意这是一个二维列表
print("{0:<10}{1:>5}".format(word,count))
analysis()
# GovRptWordCloudV1.py
f = open("三国演义.txt", "r", encoding="utf-8")
txt = f.read()
f.close()
ls = jieba.lcut(txt) # 分词
length = len(ls)
number = 0
for i in range(length): # 筛选一个字的分词并去掉它
if len(ls[i - number]) == 1:
del ls[i - number]
number += 1
else:
continue
ls = " ".join(ls) # 添加空格分隔符
w = wordcloud.WordCloud(font_path="msyh.ttc", \
width=1000, \
height=700, \
background_color="white", \
max_words=100)
w.generate(ls)
w.to_file("三国演义.png")


分析:主要功能是对《三国演义》文本进行中文分词和词频统计,并生成词云图。以下是代码的主要步骤:
import jieba 和 import wordcloud:引入了jieba库用于中文分词,wordcloud库用于生成词云图片。
def analysis() 定义了一个函数,该函数执行以下操作:
a. 读取文件 “三国演义.txt” 并使用UTF-8编码。
b. 使用jieba库的 lcut() 函数对文本进行精确模式的分词,并将结果存储在变量 words 中。
c. 遍历分词结果,对特定人物名字进行替换(如诸葛亮、曹操等),并将计数存入字典 counts。
d. 将字典中的词频按降序排序,并打印出前10个最常见的词语及其频率。
在函数外部,打开文本文件,再次分词并筛选掉单个字符的词语,然后使用 WordCloud 类创建词云图,设置参数后保存为 “三国演义.png” 图片。
雷达图绘制
mport numpy as np
import matplotlib.pyplot as plt
import matplotlib
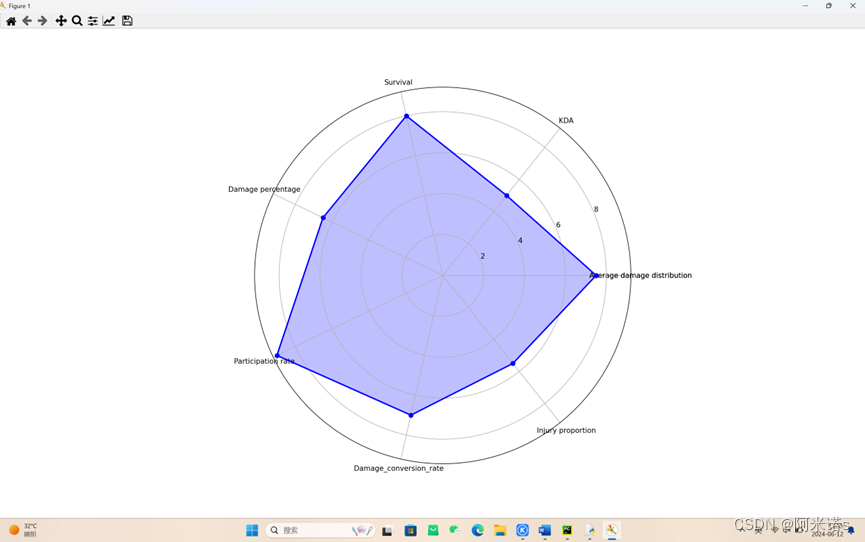
labels = np.array(['X','KDA','Survival','Damage percentage','Participation rate','Damage_conversion_rate','Injury proportion','Average damage distribution'])
nAttr = 7
data = np.array([7.5,5.0,8.0,6.5,9.0,7.0,5.5])
angles = np.linspace(0,2 * np.pi,nAttr,endpoint = False)
data = np.concatenate((data,[data[0]]))
angles = np.concatenate((angles,[angles[0]]))
fig = plt.figure(facecolor = "white")
plt.subplot(111,polar = True)
plt.plot(angles,data,'bo-',color = 'b',linewidth = 2)
plt.fill(angles,data,facecolor = 'b',alpha = 0.25)
plt.thetagrids(angles*180/np.pi,labels)
plt.grid(True)
plt.savefig('6.2.jpg')
plt.show()
分析:
import numpy as np 和 import matplotlib.pyplot as plt:导入了numpy和matplotlib.pyplot模块,numpy用于数值计算,matplotlib.pyplot用于创建图形。
import matplotlib:这个导入通常是为了使用matplotlib的全部功能,包括颜色、字体等配置。
Labels=np.array(['X','KDA','Survival','Damagepercentage','Participationrate','Damage_conversion_rate','Injuryproportion','Averagedamagedistribution']):定义了一个包含数据标签的数组,表示饼图的各个部分。
nAttr = 7:设置饼图有7个部分。
data = np.array([7.5,5.0,8.0,6.5,9.0,7.0,5.5]):定义了每个部分的数据值。
angles = np.linspace(0, 2 * np.pi, nAttr, endpoint=False):生成一个从0到2π的等分数组,用作饼图的角度。
data = np.concatenate((data,[data])) 和 angles = np.concatenate((angles,[angles])):添加一个完整的圈作为饼图的开始和结束,这样看起来更自然。
fig = plt.figure(facecolor="white"):创建一个新的图形窗口,背景色设为白色。
plt.subplot(111, polar=True):设置子图类型为极坐标,创建一个饼图。
plt.plot(angles,data,'bo-',color='b', linewidth=2):绘制实际的饼图,蓝色圆点连接线。
plt.fill(angles,data,facecolor='b',alpha=0.25):填充饼图区域,带有一定的透明度。
plt.thetagrids(angles * 180 / np.pi, labels):在角度上添加标签,将角度单位从弧度转换为度数。
plt.grid(True):添加网格线。
plt.savefig('6.2.jpg'):保存图像到名为"6.2.jpg"的文件。
plt.show():最后显示创建的图形。
爬取百度翻译结果
题目:
用python实现输入英文单词,爬取百度翻译对此单词的翻译结果并输出
示例:

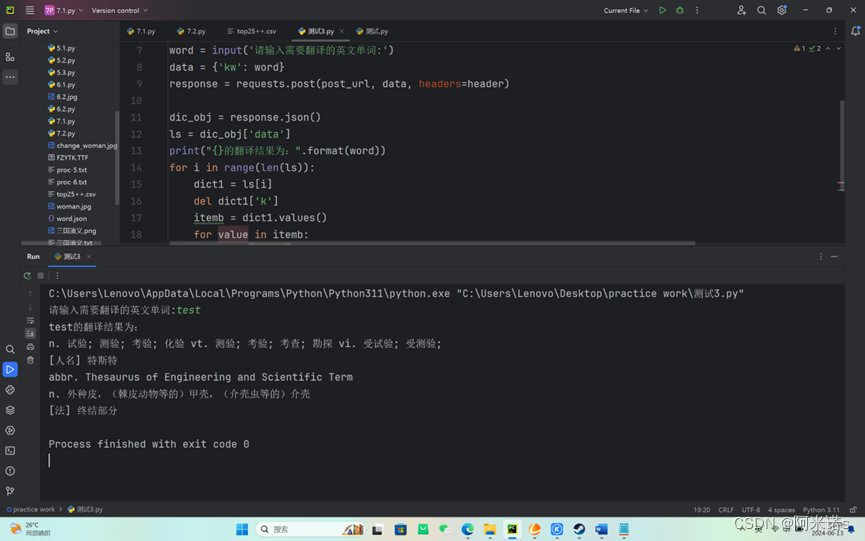
import requests
post_url = 'https://fanyi.baidu.com/sug'
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0"}
word = input('请输入需要翻译的英文单词:')
data = {'kw': word}
response = requests.post(post_url, data, headers=header)
dic_obj = response.json()
ls = dic_obj['data']
print("{}的翻译结果为:".format(word))
for i in range(len(ls)):
dict1 = ls[i]
del dict1['k']
itemb = dict1.values()
for value in itemb:
print(value)
分析:使用了requests模块来实现的功能是发送一个POST请求到百度翻译的API接口(fanyi.baidu.com),post_url 是你想要发送请求的目标网址,这里是百度翻译的搜索服务地址。header 定义了一个HTTP头部,包含User-Agent信息,模拟浏览器客户端以避免被服务端识别为机器人并限制访问。
word 是用户输入的需要翻译的单词。data 是要发送的数据,这里包含关键字kw及其值。response = requests.post(post_url, data, headers=header) 这行代码执行实际的POST请求,并将结果存储在response变量中。response.json() 将接收到的HTTP响应转化为JSON格式的数据。dic_obj['data'] 是从JSON数据中提取出的翻译建议列表。
循环遍历ls(list of dictionaries),去掉每个字典中的键’k’,然后打印剩余的值(翻译结果)。
爬取豆瓣电影网址Top250的前25电影的各种信息并写入csv
将其电影名称、电影信息以及电影评分写入名为Top25.csv文件中,
电影名称,电影信息以及电影评分三者用“,”隔开(csv文件格式)
示例:
#豆瓣前25电影:名称+时间+国家+类型+评分
import requests
from bs4 import BeautifulSoup
f1 = open("top25++.csv",'w+',encoding='utf-8')
head = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0"}#把爬虫程序伪装成用户
response = requests.get("http://movie.douban.com/top250",headers= head )
html = response.text
soup = BeautifulSoup(html,"html.parser")
items = soup.find_all('div', class_='item')
articles = []
for item in items:
title = item.find('span', class_='title').text
actors = item.find('div', class_='bd').p.text.split()
rating = item.find('span', class_='rating_num').text
for i in range(len(actors)):
if ord('1') <= ord(actors[i][0]) <= ord('9'):
actors = actors[i::]
break
else:
continue
year = actors[0]
flag1 = actors.index('/')
flag2 = actors.index('/',flag1+1,-1)
if flag1+2 == flag2:
country = actors[flag1+1]
else:
country = actors[flag1+1:flag2-1]
types = actors[flag2+1::]
information = str(title)+','+str(year)+','+str(''.join(country))+','+str(''.join(types))+','+str(rating)
articles.append(information+'\n')
f1.writelines(articles)
f1.close()
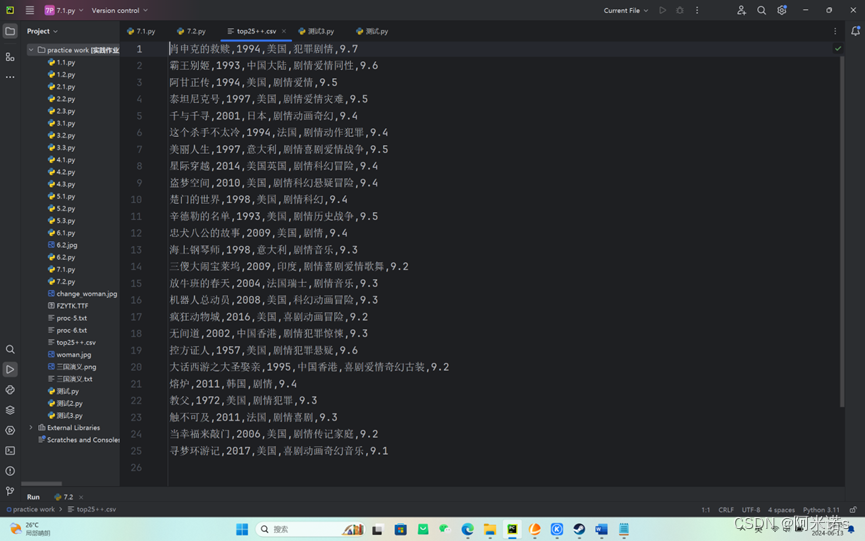
分析:定义了请求头(User-Agent),用来模拟浏览器访问,防止被网站识别为爬虫。使用requests库发送GET请求到豆瓣电影Top 250的URL,并获取响应内容。
使用BeautifulSoup库解析HTML响应,找到包含电影信息的<div>元素,它们具有class='item'的CSS选择器。遍历每个电影条目,提取电影标题、演员(包括年份、国家和类型)、评分等信息。标题:使用span元素的class_='title'查找。年份、国家和类型:通过查找div元素内的文本并根据特定字符分割来提取。评分:使用span元素的class_='rating_num'查找。将提取的信息整理成字符串,格式化为CSV行,然后添加到articles列表中。最后将所有文章写入CSV文件f1,关闭文件。






![[Labview] 二维数组写入表格](https://img-blog.csdnimg.cn/direct/47661d4596d34fa2915897cfdf1fdee8.png)