目录
- 前言
- 归并排序的思想
- 归并排序的递归法
- 归并排序的非递归法
- 归并排序的时间复杂度与适用场景
- 总结
前言
好久不见, 前面我们了解到了快速排序, 那么本篇旨在介绍另外一种排序, 它和快速排序的思想雷同, 但又有区别, 这就是归并排序, 如下图, 我们对比快速排序与归并排序.

本章也会深入介绍归并排序的两种写法, 递归版本的归并排序与非递归版本的归并排序.
博客主页:酷酷学!!!
您的支持是我更新的最大动力!
归并排序的思想
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide andConquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。 归并排序核心步骤:

归并排序的步骤如下:
- 将待排序序列分为两个子序列,直到每个子序列只有一个元素为止。
- 比较两个子序列的首个元素,将较小的元素放入一个新的临时序列中。
- 如果其中一个子序列已经被遍历完,则将另一个子序列中剩余的元素依次放入临时序列中。
- 将临时序列中的元素复制回原始序列的相应位置,得到已经排序好的子序列。
- 重复步骤2-4,直到所有的子序列都已经归并完成。
- 返回最终排序好的序列。

归并排序的递归法
首先我们需要具备这样一个思想, 如果两组数据有序, 我们就可以进行归并, 取小的数据进行依次排列, 那么我们就需要一个临时的数组进行存放, 首先动态申请块与数组空间大小相同的空间, 然后进行内层函数的递归调用, 不能直接调用外层函数, 因为会重复申请空间.
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail");
return;
}
_MergeSort(a, tmp, 0, n - 1);
free(tmp);
tmp = NULL;
}
接着, 我们来写内层函数, 首先需要给定一段区间, 用来进行此区间的排序, 我们进行递归的调用,直至区间中只有一个元素, 我们默认它为有序, 此时就可以进行归并排序, 这里与数组和链表将两个有序链表合成一个有序链表的思路是相通的, 这也可见学习算法是具有连贯性和螺旋式上升的一个过程, 接着我们需要拷贝临时数组的数据到原数组中, 每次归并一小段区间就要拷贝一次, 以免有不必要的麻烦, 到此我们的归并排序已经完成.是不是比较简单.
void _MergeSort(int* a, int* tmp, int begin, int end)
{
if (begin >= end)
{
return;
}
int mid = (begin + end) / 2;
_MergeSort(a, tmp, begin, mid);
_MergeSort(a, tmp, mid + 1, end);
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
int j = begin;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[j++] = a[begin1++];
}
else
{
tmp[j++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[j++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = a[begin2++];
}
memcpy(a+begin, tmp+begin, sizeof(int) * (end - begin + 1));
}
归并排序的非递归法
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int)*n);
if (tmp == NULL)
{
perror("malloc fail");
return;
}
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += gap*2)
{
int j = i;
int begin1 = i,end1 = i + gap -1;
int begin2 = i + gap, end2 = i + gap * 2 - 1;
if (begin2 >= n)
{
break;
}
if (end2 >= n)
{
end2 = n - 1;
}
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[j++] = a[begin1++];
}
else
{
tmp[j++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[j++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = a[begin2++];
}
memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));
}
gap *= 2;
}
free(tmp);
tmp = NULL;
}
非递归法与递归法的思路是一模一样的,只不过呈现的形式有所不同, 首先我们来回忆一下递归法的过程, 就是先递归让数组的区间元素个数为1, 认为为有序数组, 然后依次回退进行归并, 我们这里也可以这样, 首先模拟一个元素为一个区间, 进行归并, 然后两个有序元素进行归并, 然后变成四个, 八个, 直到归并区间个数大于等于N.
第一步, 我们先分gap组, gap为每组归并的个数, 比如gap为1,那么每组就归并一个数据, 我们我们先看内层for循环, 进行第一次gap为1的归并, 此时一个数据与一个数据进行归并, 归并成含有两个数据的有序数组, 此时我们的目的就完成了, 这个思想与归并排序的思路是一致的, 此时有同学会问, 为什么i要+=gap*2, 因为每次归并一段区间, 比如第一次下标为0与下标为1进行归并, 第二次下标为2和下标为3进行归并, 所以每次要跳过两个组,然后进行下两组数据的归并.
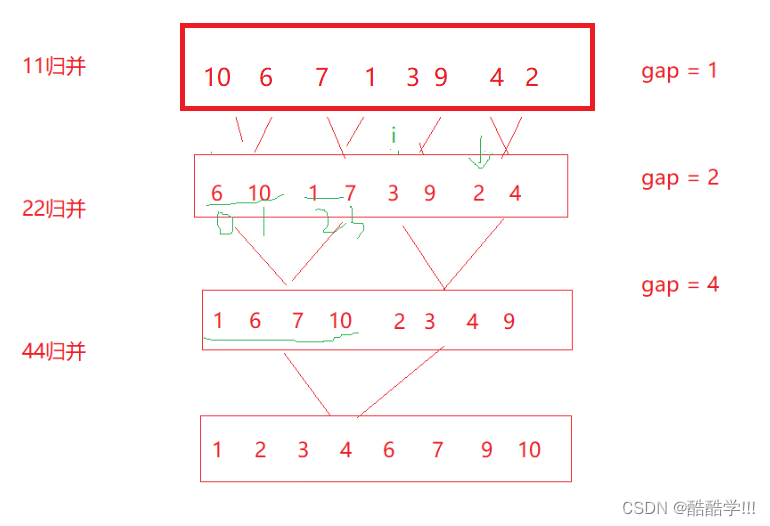
i代表每组的起始位置,第一次归并完成之后, 我们进行第二次归并, gap为2, 进行22归并,然后44归并, 知道gap>=n, 但是这种也存在越界风险, 比如下图
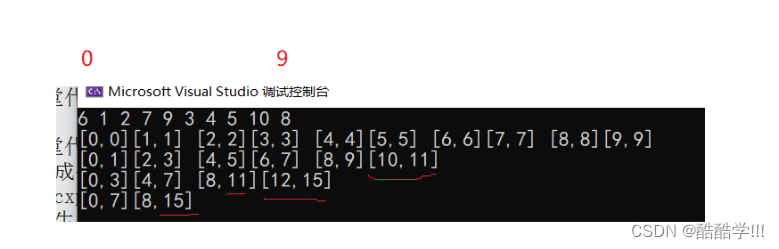
我们对上面一组数据进行排序,发现十个数据, 进行排序, 除了begin1不会越界, 其他都有可能越界的风险,处理方法

对于begin2和end1越界, 那么我们就不需要归并了, 如果end2越界, 我们只需要重新调整一下区间, 代码如下:
if (begin2 >= n)
{
break;
}
if (end2 >= n)
{
end2 = n - 1;
}
如此非递归版的归并排序我们也完成了.
归并排序的时间复杂度与适用场景
- 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(N)
- 稳定性:稳定
对于时间复杂度我们可以理解为递归深度, 就正如二叉树类似, 不难算出时间复杂度.
适用场景:
- 当需要对一个较大规模的数据集进行排序时,归并排序是一种比较高效的排序算法。它的时间复杂度相对较低,且具有稳定性,不会改变相同元素的相对次序。
- 归并排序适用于对链表进行排序。由于链表的特殊结构,使用归并排序在空间上更加节省,且对链表进行合并操作非常方便。
- 当数据集的存储方式不支持随机访问时,如外部排序,归并排序也是一个很好的选择。它可以对数据集进行分块读取,然后进行排序和合并。
总结
归并排序是一种经典的排序算法,它的基本思想是将待排序的序列分成两个子序列,分别进行递归地排序,然后将两个排好序的子序列合并成一个有序序列。
归并排序的具体步骤如下:
- 将待排序序列不断地划分,直到每个子序列只有一个元素。
- 对相邻的两个子序列进行合并,得到一个有序的子序列。
- 不断地合并子序列,直到最终得到一个有序的序列。
归并排序的时间复杂度为O(nlogn),其中n是待排序序列的长度。它的空间复杂度为O(n),因为在合并子序列的过程中需要额外的空间来存储临时结果。
归并排序是一种稳定的排序算法,它的优点是可以保持原序列中相同元素的相对顺序不变。它适用于对大规模数据进行排序,但由于需要额外的空间,所以对于内存有限的情况下可能不太适用。
总的来说,归并排序是一种简单而高效的排序算法,它的实现也相对容易理解。在实际应用中,可以根据具体情况选择是否使用归并排序来解决排序问题。
完
感谢关注, 如有疑问欢迎留言, 留言必回!!!

![[Labview] 二维数组写入表格](https://img-blog.csdnimg.cn/direct/47661d4596d34fa2915897cfdf1fdee8.png)