一、背景
为了控制发版带来的影响面等问题,我们公司基建团队自研灰度发布流程,目前几乎所有服务发版都会严格先走灰度发布验证再上线。当前已支持http、gRPC等接口调用方式进行灰度流量转发,使用消息队列进行业务实现的场景的暂不支持。
ps: 参考过网上诸多消息队列灰度的方案,比较热门的有vivo鲁班RocketMQ系列的文章,但无一例外的是改造量都很大,且需要借助外部配置中心作为流量开关配置,存在很强的定制化和侵入性,而本文所提及的方案设计很好的利用了RocketMQ原生的特性、无外部依赖、只需要改造client端代码(改动量特别小)即可完美的支持灰度消息。
二、当前痛点

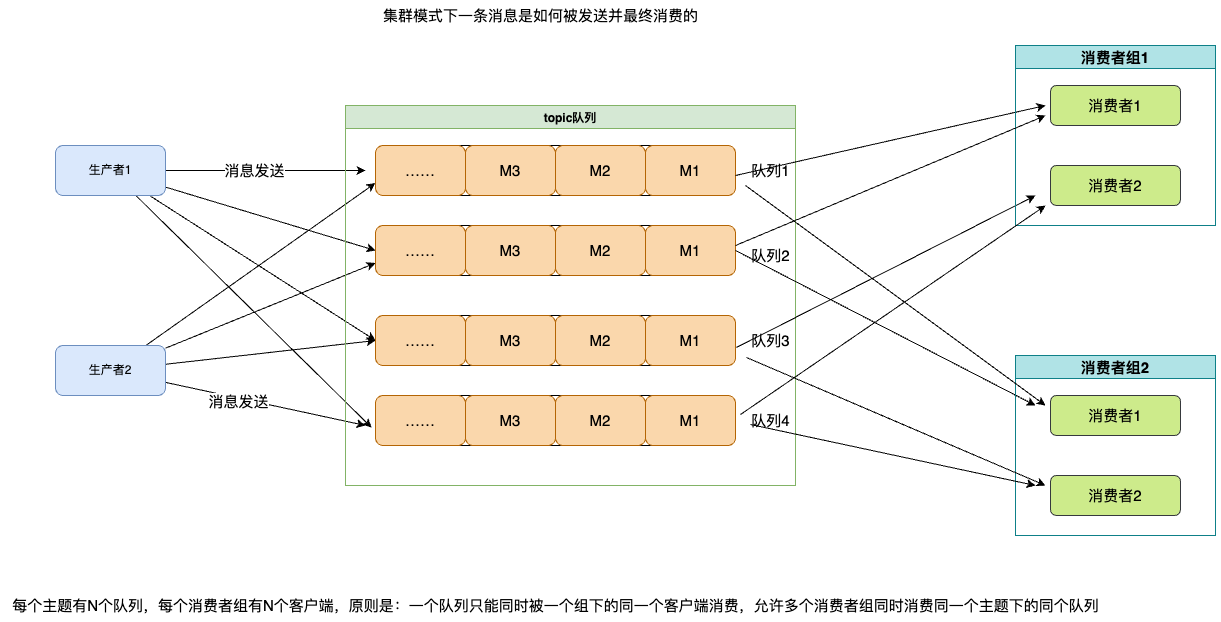
上图是普通业务灰度流程,通常只保证RPC服务之间调用灰度。但正是与引进灰度发布的原因一样,消息队列场景当前不支持灰度验证。因为不管是灰度集群还是线上集群都同时平均消费订阅主题下的队列,在现在的流程中即使当前链路是灰度链路,消息的发送目标依然是不可控的,可能前往灰度集群监听的分区、也可能进入线上集群监听的分区。所以如果涉及到消费逻辑的变更,就需要开发人员在代码设计中做较多的兼容逻辑,但无论怎样的兼容逻辑,只能保证新业务不影响线上,而无法保证灰度流量精准进入灰度消费客户端,从而无法进行严谨有效的灰度验证。同时对开发人员对MQ需要有一定的深入了解,才能避免在平时业务变更时因为某个细节上的变更导致出现不可控的线上业务影响。所以,MQ支持灰度成为一直迫切需要解决但没有很好方案的一个架构问题。
三、目标
以尽量小的改造,结合现有的基建架构,提供一种最快、最简易、最安全的MQ灰度接入方式,包括但不限于以下技术、环境:
- 技术语言: JAVA、PHP、Node、Golang
- 环境:云上版MQ、开源版MQ
- 地域:云上版所有地域(开源版无地域差别)
- 消息类型:普通、顺序、事务、延时/定时等消息
四、基础概念
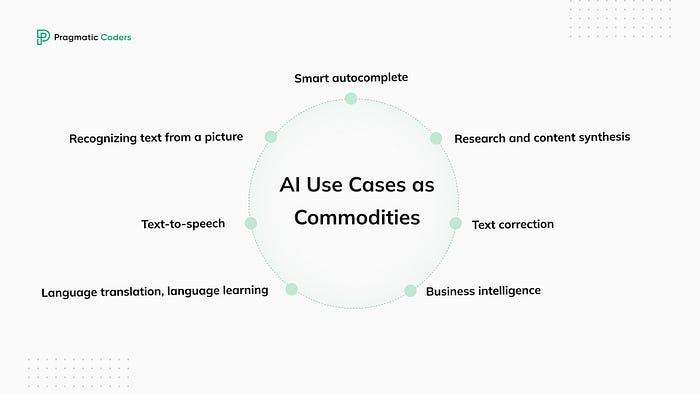
1.RocketMQ存储架构

2. RocketMQ消息收发主要逻辑
3.负载均衡实现

相关概念点
CommitLog:消息体实际存储的地方,当我们发送的任一业务消息的时候,它最终会存储在commitLog上。MQ在Broker进行集群部署(这里为也简洁,不涉及主从部分)时,同一业务消息只会落到集群的某一个Broker节点上。而这个Broker上的commitLog就会存储所有Topic路由到它的消息,当消息数据量到达1个G后会重新生成一个新的commitLog。
Topic:消息主题,表示一类消息的逻辑集合。每条消息只属于一个Topic,Topic中包含多条消息,是MQ进行消息发送订阅的基本单位。属于一级消息类型,偏重于业务逻辑设计。
Tag:消息标签,二级消息类型,每一个具体的消息都可以选择性地附带一个Tag,用于区分同一个Topic中的消息类型,例如订单Topic, 可以使用Tag=tel来区分手机订单,使用Tag=iot来表示智能设备。在生产者发送消息时,可以给这个消息指定一个具体的Tag, 在消费方可以从Broker中订阅获取感兴趣的Tag,而不是全部消息(注:严谨的拉取过程,并不全是在Broker端过滤,也有可能部分在消费方过滤,在这里不展开描述)。
Queue:实际上Topic更像是一个逻辑概念供我们使用,在源码层级看,Topic以Queue的形式分布在多个Broker上,一个topic往往包含多条Queue(注:全局顺序消息的Topic只有一条Queue,所以才能保证全局的顺序性),Queue与commitLog存在映射关系。可以理解为消息的索引,且只有通过指定Topic的具体某个Queue,才能找到消息。(注:熟悉kafka的同学可以类比partition)。
消费组及其ID:表示一类Producer或Consumer,这类Producer或Consumer通常生产或消费同应用域的消息,且消息生产与消费的逻辑一致。每个消费组可以定义全局维一的GroupID来标识,由它来代表消费组。不同的消费组在消费时互相隔离,不会影响彼此的消费位点计算。
负载均衡(这里只谈4.0架构,5.0使用POP模式): RockeMQ使用客户端负载均衡来完成队列分配。集群消费模式下,每个group可能有多个客户端实例,他们在启动时、下线时、运行时每间隔20秒等三处地方,会获取当前group的客户端在线信息以及主题队列情况,然后根据预先设置的负载均衡策略进行队列分配。会保证同一时刻一个队列只能被一个group下的客户端所消费。
消费位点: 同一个group下不同客户端各自拉取不同的队列,集群消费模式下,group对topic下的所有队列的消费进度维护在服务端,关系结构即: 1group->n客户端->n队列→n位点进度,位点进度结构为双层map结构,首层map key为group和topic的组合key,第二层map key为队列id,value为进度数字,每个客户端会间隔一定时间或者优雅下线时向broker上报自己的队列消费位点。
五、方案比较
1.影子topic

2.灰度tag

3.灰度header
与灰度tag流程差不多,只是把标记做在userProperty上,消费端会收到全量的消息,再自己过滤。
4.影子group

5.灰度分区
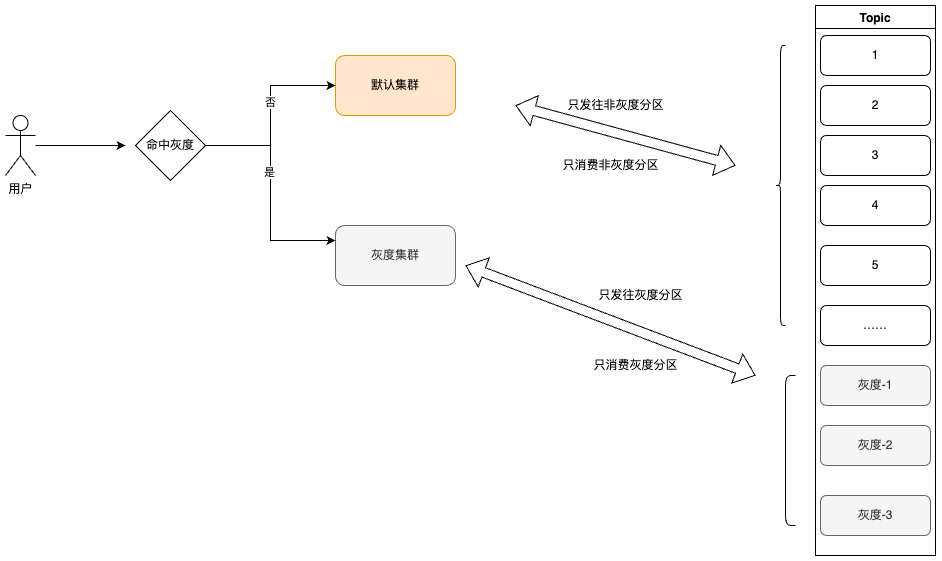

六、灰度分区设计
灰度分区设计实际上利用到以下几点:
devops: 现有流程中,灰度服务的pod容器内部会有 CANARY_RELEASE:canary 的环境变量。
MQ客户端心跳上报: 源码中,RocketMQ客户端启动时会想向所有产生订阅关系的broker发送心跳,心跳中带有clientId,该值主要由实例名、容器ip等组成,可以利用canary环境变量做一层额外的注入
MQ客户端重平衡: 源码中,每隔20秒/客户端上下线,都会触发一次客户端重平衡,RocketMQ提供了默认几种策略,同时支持扩展,我们可以自定义该策略,加入灰度分区平衡逻辑。
MQ客户端发送方: 源码中,RocketMQ发送方每次发送消息都会轮询队列发送,同时加入重试和故障规避的策略,可以通过重写该类来做扩展。
1.消费者灰度前
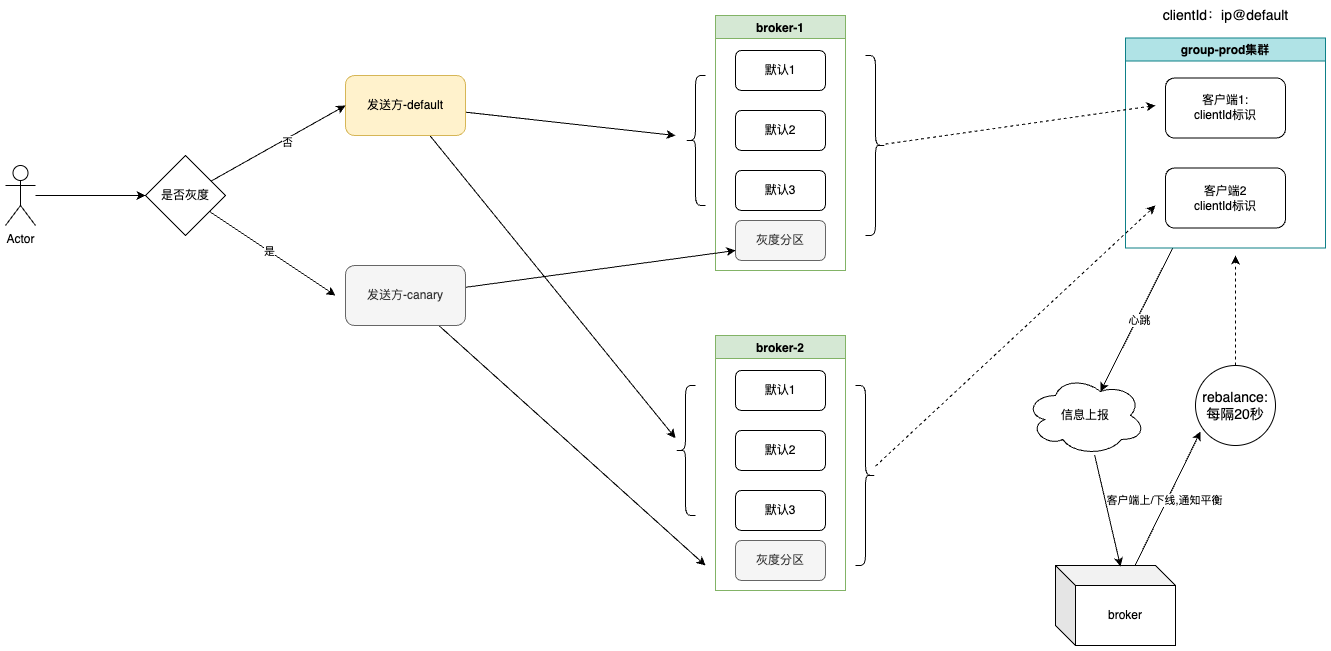
2.消费者灰度中

3.上线
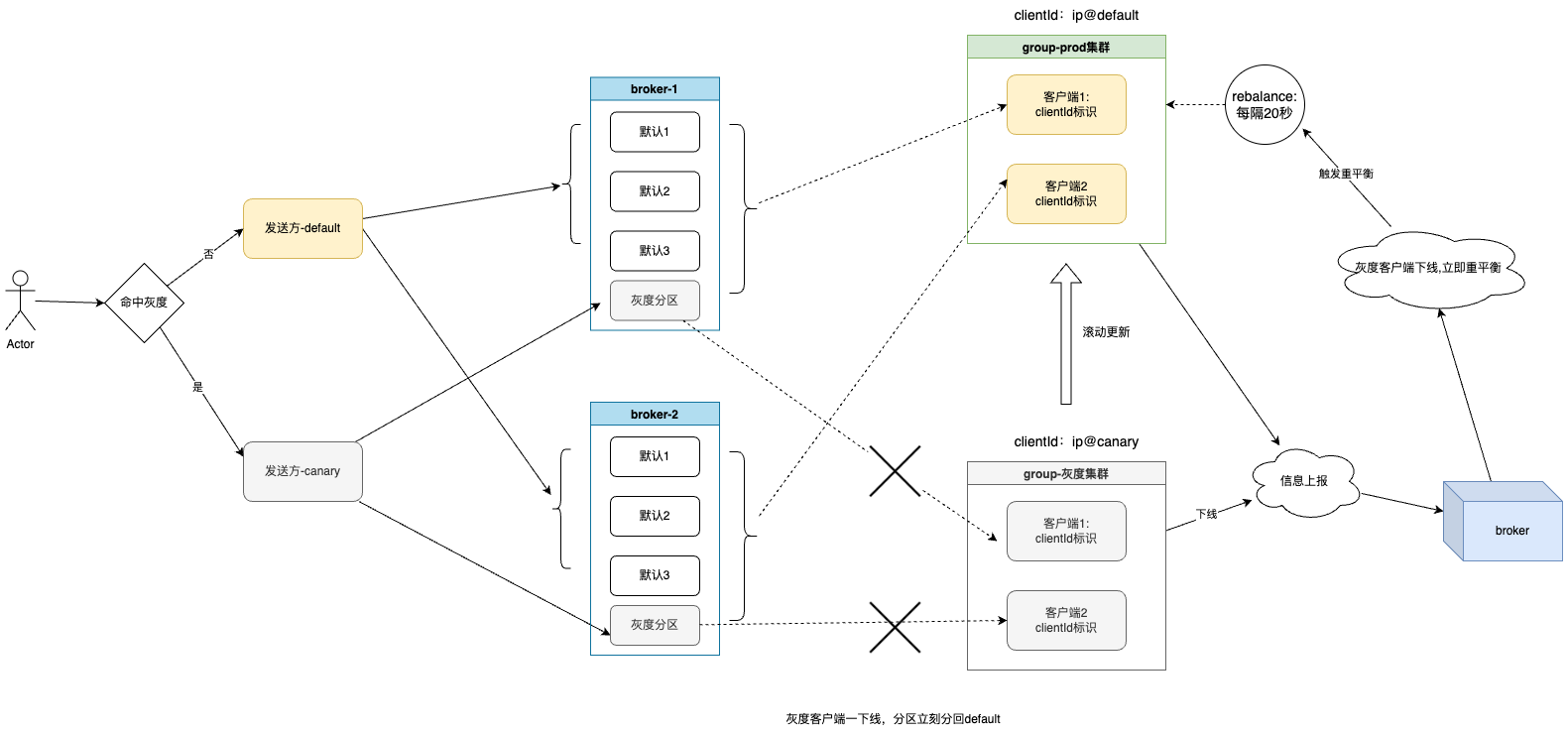
针对以上流程,这里说明下针对发送方以及消费方的改造逻辑。
发送方: 无论何时,只要自己当前环境是灰度(DEVOPS_RELEASE_TYPE=canary)或者当前是灰度链路,则会根据broker分组选择每个集群的最后一个分区作为灰度队列,否则选取其他分区发送,根据RocketMQ的源码,自定义发送策略即可实现。
/**
* mq消息发送故障策略(重写覆盖了rocketmq)
*
* @author mobai
*/
@Slf4j
public class MQFaultStrategy {
private final LatencyFaultTolerance<String> latencyFaultTolerance = new LatencyFaultToleranceImpl();
private boolean sendLatencyFaultEnable = false;
private long[] latencyMax = {50L, 100L, 550L, 1000L, 2000L, 3000L, 15000L};
private long[] notAvailableDuration = {0L, 0L, 30000L, 60000L, 120000L, 180000L, 600000L};
private final ConcurrentHashMap<TopicPublishInfo, TopicPublishInfoCache> topicPublishInfoCacheTable = new ConcurrentHashMap<>();
public long[] getNotAvailableDuration() {
return notAvailableDuration;
}
public void setNotAvailableDuration(final long[] notAvailableDuration) {
this.notAvailableDuration = notAvailableDuration;
}
public long[] getLatencyMax() {
return latencyMax;
}
public void setLatencyMax(final long[] latencyMax) {
this.latencyMax = latencyMax;
}
public boolean isSendLatencyFaultEnable() {
return sendLatencyFaultEnable;
}
public void setSendLatencyFaultEnable(final boolean sendLatencyFaultEnable) {
this.sendLatencyFaultEnable = sendLatencyFaultEnable;
}
private TopicPublishInfoCache checkCacheChanged(TopicPublishInfo topicPublishInfo) {
if (topicPublishInfoCacheTable.containsKey(topicPublishInfo)) {
return topicPublishInfoCacheTable.get(topicPublishInfo);
}
synchronized (this) {
TopicPublishInfoCache cache = new TopicPublishInfoCache();
List<MessageQueue> canaryQueues = MessageStorage.getCanaryQueues(topicPublishInfo.getMessageQueueList());
List<MessageQueue> normalQueues = MessageStorage.getNormalQueues(topicPublishInfo.getMessageQueueList());
Collections.sort(canaryQueues);
Collections.sort(normalQueues);
cache.setCanaryQueueList(canaryQueues);
cache.setNormalQueueList(normalQueues);
topicPublishInfoCacheTable.putIfAbsent(topicPublishInfo, cache);
}
return topicPublishInfoCacheTable.get(topicPublishInfo);
}
/**
* 队列选择策略
* 如果当前是灰度环境,则发送到灰度分区
* 如果开启了故障规避,则选择一个可用的消息队列(不包含灰度分区)
* 如果没有开启故障规避,则选择一个消息队列(不包含灰度分区)
*
* @param tpInfo 消息队列信息
* @param lastBrokerName 上次发送失败的brokerName
* @return 选择的消息队列
*/
public MessageQueue selectOneMessageQueue(final TopicPublishInfo tpInfo, final String lastBrokerName) {
List<MessageQueue> messageQueueList = tpInfo.getMessageQueueList();
TopicPublishInfoCache topicPublishInfoCache = checkCacheChanged(tpInfo);
//灰度的场景下,发送消息到灰度分区
if (MessageStorage.isCanaryRelease()) {
MessageQueue messageQueue = selectDefaultMessageQueue(tpInfo, lastBrokerName, topicPublishInfoCache.getCanaryQueueList());
if (log.isDebugEnabled()) {
log.debug("canary context,send message to canary queue:{}", messageQueue.getBrokerName() + messageQueue.getQueueId());
}
return messageQueue;
} else {
//开启了故障规避
if (this.sendLatencyFaultEnable) {
try {
int index = tpInfo.getSendWhichQueue().incrementAndGet();
int size = topicPublishInfoCache.getNormalQueueList().size();
for (int i = 0; i < size; i++) {
int pos = Math.max(Math.abs(index++) % size, 0);
MessageQueue mq = topicPublishInfoCache.getNormalQueueList().get(pos);
if (latencyFaultTolerance.isAvailable(mq.getBrokerName())) {
return mq;
}
}
//如果没有找到可用的消息队列,则选择一个相对可靠的broker下的消息队列
final String notBestBroker = latencyFaultTolerance.pickOneAtLeast();
int writeQueueNums = tpInfo.getQueueIdByBroker(notBestBroker);
if (writeQueueNums > 0) {
final MessageQueue mq = tpInfo.selectOneMessageQueue();
//避免发送到灰度分区,同时又保留故障规避机制
if (!topicPublishInfoCache.getCanaryQueueList().contains(mq)) {
if (notBestBroker != null) {
mq.setBrokerName(notBestBroker);
mq.setQueueId(tpInfo.getSendWhichQueue().incrementAndGet() % writeQueueNums);
}
return mq;
}
} else {
latencyFaultTolerance.remove(notBestBroker);
}
} catch (Exception e) {
log.error("Error occurred when selecting message queue", e);
}
}
//按递增取模的方式实现轮询选择队列
return selectDefaultMessageQueue(tpInfo, lastBrokerName, topicPublishInfoCache.getNormalQueueList());
}
}
/**
* 默认的消息队列选择策略
* 尽可能避开上次发送失败的brokerName
*
* @param topicPublishInfo 消息队列信息
* @param lastBrokerName 上次发送失败的brokerName
* @return 选择的消息队列
*/
private MessageQueue selectDefaultMessageQueue(final TopicPublishInfo topicPublishInfo, final String lastBrokerName,
List<MessageQueue> queues) {
ThreadLocalIndex sendWhichQueue = topicPublishInfo.getSendWhichQueue();
int size = queues.size();
if (lastBrokerName != null) {
for (int i = 0; i < size; i++) {
int index = sendWhichQueue.incrementAndGet();
int pos = Math.max(Math.abs(index) % size, 0);
MessageQueue mq = queues.get(pos);
//如果不是上次发送失败的brokerName,则返回
if (!mq.getBrokerName().equals(lastBrokerName)) {
return mq;
}
}
}
//如果没有找到不是上次发送失败的brokerName,则随机返回一个
int i = sendWhichQueue.incrementAndGet();
int res = Math.max(Math.abs(i) % size, 0);
if (log.isDebugEnabled()) {
log.debug("selectDefaultMessageQueue, lastBrokerName:{}, res:{}", lastBrokerName, topicPublishInfo.getMessageQueueList().get(res));
}
return queues.get(res);
}
public void updateFaultItem(final String brokerName, final long currentLatency, boolean isolation) {
if (this.sendLatencyFaultEnable) {
long duration = computeNotAvailableDuration(isolation ? 30000 : currentLatency);
this.latencyFaultTolerance.updateFaultItem(brokerName, currentLatency, duration);
}
}
private long computeNotAvailableDuration(final long currentLatency) {
for (int i = latencyMax.length - 1; i >= 0; i--) {
if (currentLatency >= latencyMax[i]) {
return this.notAvailableDuration[i];
}
}
return 0;
}
private static class TopicPublishInfoCache {
/**
* 灰度消息队列列表
*/
private List<MessageQueue> canaryQueueList;
private List<MessageQueue> normalQueueList;
public List<MessageQueue> getCanaryQueueList() {
return canaryQueueList;
}
public void setCanaryQueueList(List<MessageQueue> canaryQueueList) {
this.canaryQueueList = canaryQueueList;
}
public List<MessageQueue> getNormalQueueList() {
return normalQueueList;
}
public void setNormalQueueList(List<MessageQueue> normalQueueList) {
this.normalQueueList = normalQueueList;
}
}
}
消费方: 其实最大的问题在于消费方如何动态的感知灰度的状态流转,这也是产生之前灰度分区方案的临界问题的根本原因。但是通过源码的深入探索,发现其实我们可以通过改造ClientId和自定义负载均衡策略来实现,具体改造如下:
RocketMQ客户端启动的时候,会构建本地客户端id(包括实例名、ip名等),然后向broker注册自己。我们可以通过devops注入的环境变量DEVOPS_RELEASE_TYPE来做改造,即灰度服务clientId后面追加canary表示,default服务后面追加default标识,代码如下:
public String buildMQClientId() {
StringBuilder sb = new StringBuilder();
sb.append(this.getClientIP());
sb.append("@");
sb.append(this.getInstanceName());
if (!UtilAll.isBlank(this.unitName)) {
sb.append("@");
sb.append(this.unitName);
}
if (enableStreamRequestType) {
sb.append("@");
sb.append(RequestType.STREAM);
}
//关键在此处
if (MessageStorage.isCanaryRelease()) {
log.info("canary release mode, add canary tag to client id.");
sb.append("@canary");
} else {
sb.append("@default");
}
return sb.toString();
}
然后自定义负载均衡策略的实现,因为我们没有特殊的需求,所以只需要继承原来的平均分配策略即可,改造的逻辑是: 只要当前group在broker端有灰度的客户端(通过第一点的clientId可以得知),就让正常的客户端去分配前面的分区,而灰度的客户端去瓜分灰度分区,否则按默认的平均分配即可。
public class CanaryAllocateMessageQueueStrategyImpl implements AllocateMessageQueueStrategy {
/**
* 负载均衡策略
* 若存在客户端为灰度客户端,则按照灰度客户端进行分配
* 若所有客户端不存在灰度客户端,则按照平均分配策略进行分配
*
* @param consumerGroup current consumer group
* @param currentCID current consumer id
* @param mqAll message queue set in current topic
* @param cidAll consumer set in current consumer group
* @return
*/
@Override
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll, List<String> cidAll) {
if (!check(consumerGroup, currentCID, mqAll, cidAll)) {
return Collections.emptyList();
}
//重试的消息队列不参与灰度负载均衡,走默认的rocketmq策略
//因为重试的消息是由客户端重新发送回broker的,走的不是默认的send逻辑,写到的是group的retry topic,写到哪个队列我们也不知道,所以无法进行灰度负载均衡
if (mqAll.stream().anyMatch(mq -> mq.getTopic().startsWith(MixAll.RETRY_GROUP_TOPIC_PREFIX))) {
return allocateByAvg(consumerGroup, currentCID, mqAll, cidAll);
}
//如果不存在灰度服务,则按照平均分配策略进行分配
if (!MessageStorage.hasCanaryRelease(cidAll)) {
List<MessageQueue> allocate = allocateByAvg(consumerGroup, currentCID, mqAll, cidAll);
if (log.isDebugEnabled()) {
log.debug("topic:{} reBalance, no canary release client, allocate {} message queue by average strategy.\n" +
"current cid:{}\n" +
"result:\n{}",
mqAll.get(0).getTopic(),
allocate.size(),
currentCID,
allocate.stream()
.collect(Collectors.groupingBy(MessageQueue::getBrokerName))
.entrySet().stream()
.map(e -> e.getKey() + ": " + e.getValue().stream()
.map(m -> String.valueOf(m.getQueueId()))
.collect(Collectors.joining(", ")))
.collect(Collectors.joining("\n")));
}
return allocate;
}
//如果当前group只有灰度客户端,说明当前这个订阅关系(包括group)是新加的,那么则不走灰度逻辑(线上没有这层订阅关系),不然会导致消息大量堆积
if (MessageStorage.allCanaryRelease(cidAll)) {
List<MessageQueue> messageQueues = super.balanceAllocate(consumerGroup, currentCID, mqAll, cidAll);
log.info("[canary allocate]: group:{} sub topic:{} has all canary release client,maybe the sub is new,use the default avg strategy.\n" +
"current cid:{}\n" +
"allocate total {} message queue\n" +
"result:\n{}",
consumerGroup,
mqAll.get(0).getTopic(),
messageQueues.size(),
currentCID,
MessageStorage.joinMessageQueue(messageQueues));
return messageQueues;
}
//说明当前存在灰度客户端,则让灰度客户端瓜分灰度队列,其他客户端按照平均分配策略进行分配非灰度队列
List<String> canaryCids = MessageStorage.getCanaryCids(cidAll);
List<String> normalCids = MessageStorage.getNormalCids(cidAll);
List<MessageQueue> canaryQueues = MessageStorage.getCanaryQueues(mqAll);
List<MessageQueue> normalQueues = MessageStorage.getNormalQueues(mqAll);
Collections.sort(canaryCids);
Collections.sort(normalCids);
Collections.sort(normalQueues);
Collections.sort(canaryQueues);
List<MessageQueue> result = null;
if (canaryCids.contains(currentCID)) {
result = allocateByAvg(consumerGroup, currentCID, canaryQueues, canaryCids);
} else {
result = allocateByAvg(consumerGroup, currentCID, normalQueues, normalCids);
}
if (log.isDebugEnabled()) {
log.debug("topic:{} reBalance, has canary release client, allocate {} message queue by canary release strategy.\n" +
"current cid:{}\n" +
"result:\n{}",
mqAll.get(0).getTopic(),
result.size(),
currentCID,
result.stream()
.collect(Collectors.groupingBy(MessageQueue::getBrokerName))
.entrySet().stream()
.map(e -> e.getKey() + ": " + e.getValue().stream()
.map(m -> String.valueOf(m.getQueueId()))
.collect(Collectors.joining(", ")))
.collect(Collectors.joining("\n")));
}
return result;
}
/**
* 按照平均策略分配消息队列给消费者。这个方法的目标是尽可能平均地将所有的消息队列分配给所有的消费者。
* <p>
* 如果消息队列的数量少于或等于消费者的数量,那么每个消费者将获得一个消息队列。如果消息队列的数量多于消费者的数量,那么每个消费者将获得消息队列总数除以消费者数的商个消息队列,余数会从前到后分配给消费者。
* <p>
* 例如,如果有10个消息队列和3个消费者,那么每个消费者将获得3个消息队列,剩下的1个消息队列会分配给第一个消费者。
*
* @param consumerGroup 消费者组名
* @param currentCID 当前消费者的ID
* @param mqAll 所有的消息队列
* @param cidAll 所有消费者的ID列表
* @return 分配给当前消费者的消息队列列表
*/
private List<MessageQueue> allocateByAvg(String consumerGroup, String currentCID, List<MessageQueue> mqAll,
List<String> cidAll) {
List<MessageQueue> result = new ArrayList<MessageQueue>();
if (!check(consumerGroup, currentCID, mqAll, cidAll)) {
return result;
}
int index = cidAll.indexOf(currentCID);
int mod = mqAll.size() % cidAll.size();
int averageSize =
mqAll.size() <= cidAll.size() ? 1 : (mod > 0 && index < mod ? mqAll.size() / cidAll.size()
+ 1 : mqAll.size() / cidAll.size());
int startIndex = (mod > 0 && index < mod) ? index * averageSize : index * averageSize + mod;
int range = Math.min(averageSize, mqAll.size() - startIndex);
for (int i = 0; i < range; i++) {
result.add(mqAll.get((startIndex + i) % mqAll.size()));
}
return result;
}
@Override
public String getName() {
return "CANARY";
}
public boolean check(String consumerGroup, String currentCID, List<MessageQueue> mqAll,
List<String> cidAll) {
if (StringUtils.isEmpty(currentCID)) {
throw new IllegalArgumentException("currentCID is empty");
}
if (CollectionUtils.isEmpty(mqAll)) {
throw new IllegalArgumentException("mqAll is null or mqAll empty");
}
if (CollectionUtils.isEmpty(cidAll)) {
throw new IllegalArgumentException("cidAll is null or cidAll empty");
}
if (!cidAll.contains(currentCID)) {
log.info("[BUG] ConsumerGroup: {} The consumerId: {} not in cidAll: {}",
consumerGroup,
currentCID,
cidAll);
return false;
}
return true;
}
}
只需要做这几点改造即可。
验证过程:
### 1.前置准备:

消费端代码:
public class CanaryListener {
@StreamListener(CanaryConfig.TOPIC)
public void listen(MessageExt messageExt) {
String body = new String(messageExt.getBody());
CanaryMessage canaryMessage = JSON.parseObject(body, CanaryMessage.class);
if (canaryMessage.isCanary()) {
log.info("canary message from queue:{}", messageExt.getBrokerName() + ":" + messageExt.getQueueId());
} else {
log.info("normal message from queue:{}", messageExt.getBrokerName() + ":" + messageExt.getQueueId());
}
}
}
发送方代码:
@RequestMapping("/msg")
public void test() {
boolean canaryRelease = MessageStorage.isCanaryRelease();
CanaryMessage canaryMessage = new CanaryMessage(canaryRelease);
for (Integer i = 0; i < number; i++) {
log.info("发送消息,环境:{}", canaryRelease ? "灰度" : "正式");
messageService.send(canaryMessage);
}
}
2.验证
2.1 消费端无灰度,发送端灰度/无灰度发送消息
队列负载:

队列分配情况如下:
-
10.27.0.233 : cn-hangzhou-share-11-0:(0,1,2,3,4,5,6,7), cn-hangzhou-share-11-1:(0,1,2,3) 共计12个队列
-
10.27.12.24: cn-hangzhou-share-11-1:(4,5,6,7), cn-hangzhou-share-11-2:(0,1,2,3,4,5,6,7) 也是12个分片。
请求接口,发送1000条普通消息:


消费端近乎平均的瓜分了消息,符合预期。
接下来发送几100条带灰度的消息:
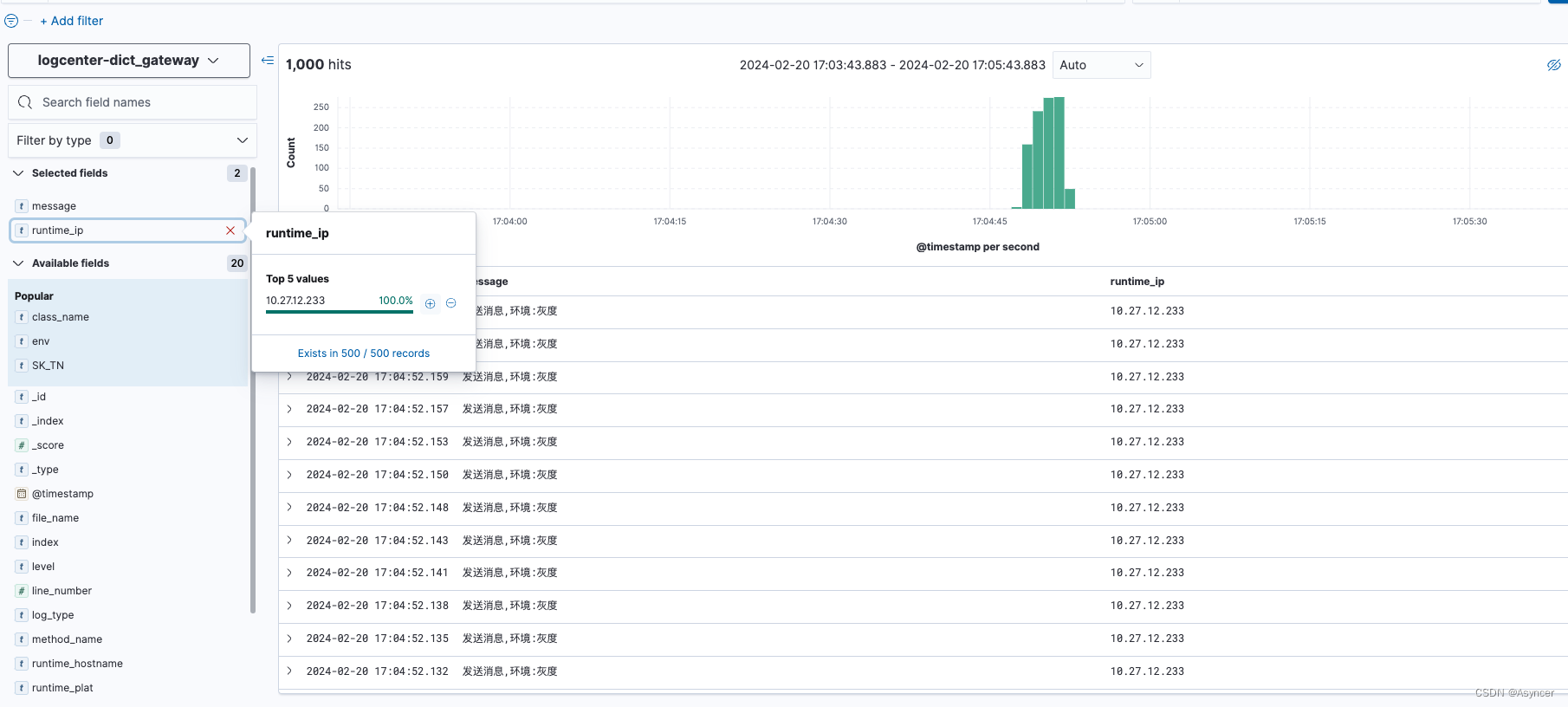
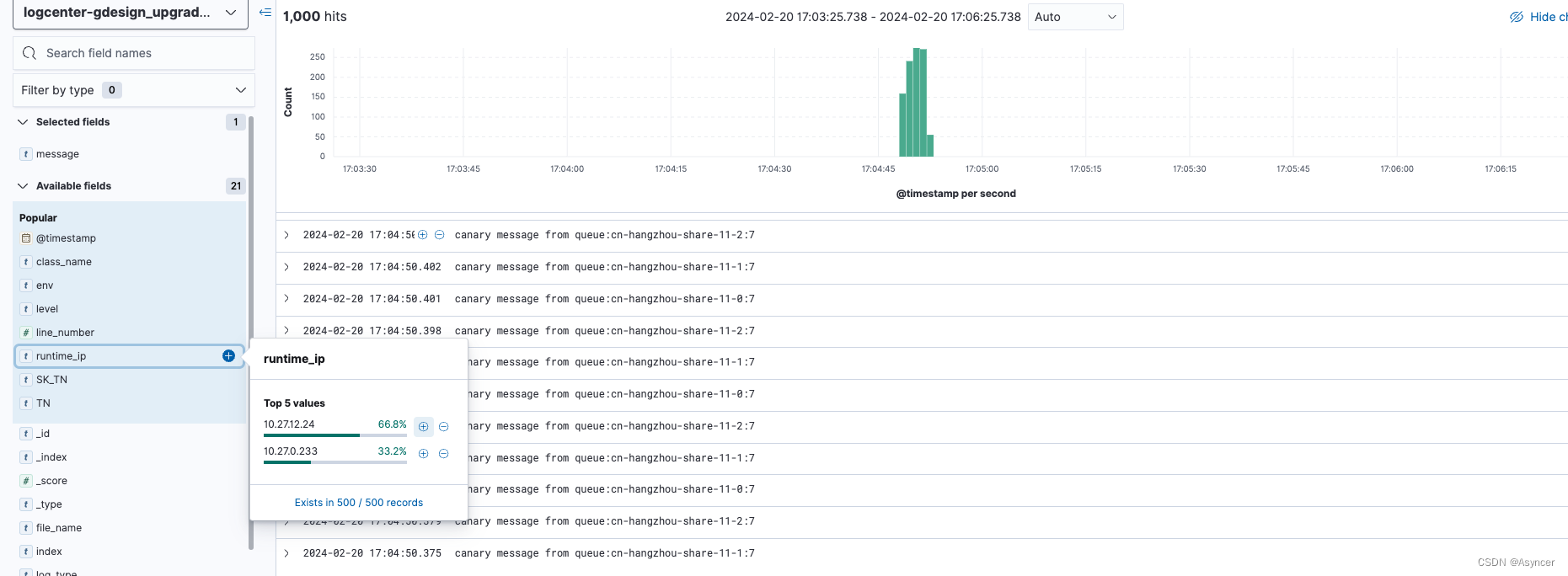

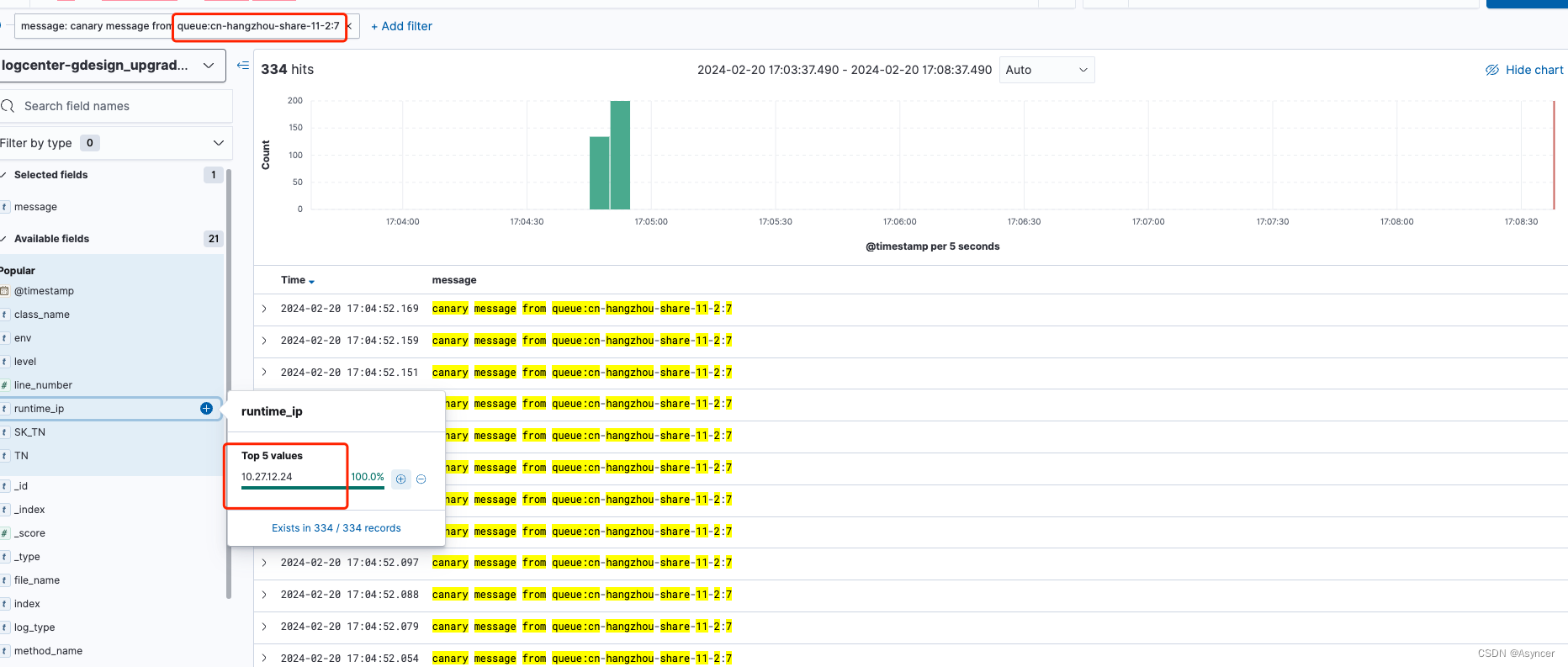

可以看到虽然消费端没有灰度,但是发送方灰度的时候每次都发到每个broker的最后一个分区,因为上面有看到负载情况,
-
cn-hangzhou-share-11-0:7有333条消息,全都被10.27.0.233消费
-
cn-hangzhou-share-11-1:7和cn-hangzhou-share-11-2:7各有334,333条消息,全都被10.27.12.24消费。
测试结果: 在消费端无灰度的情况下,发送方灰度与否消息都会被消费端全部消费到,除灰度外负载情况接近平衡,灰度受pod和分区个数影响。
2.2 消费端开启灰度,发送端发送灰度/无灰度消息
消费者端启动一个灰度实例,然后查看队列负载情况:

可以看到由于部署了一个灰度pod,此时触发了客户端重平衡,且他们的时间几乎是同一时刻触发的.原来的分配情况发生了变化,此时队列分配情况如下:
-
10.27.0.233: cn-hangzhou-share-11-0: (0, 1, 2, 3, 4, 5, 6 ),cn-hangzhou-share-11-1: (0, 1, 2, 3 )
-
10.27.12.24: cn-hangzhou-share-11-1: (4, 5, 6),cn-hangzhou-share-11-2: (0, 1, 2, 3, 4, 5, 6)
-
10.27.12.234(灰度): cn-hangzhou-share-11-0: 7,cn-hangzhou-share-11-1: 7, cn-hangzhou-share-11-2: 7 —----- 分配到了所有broker的最后一个队列
然后我们模拟此时前台非灰度用户请求,发送1000条普通消息:

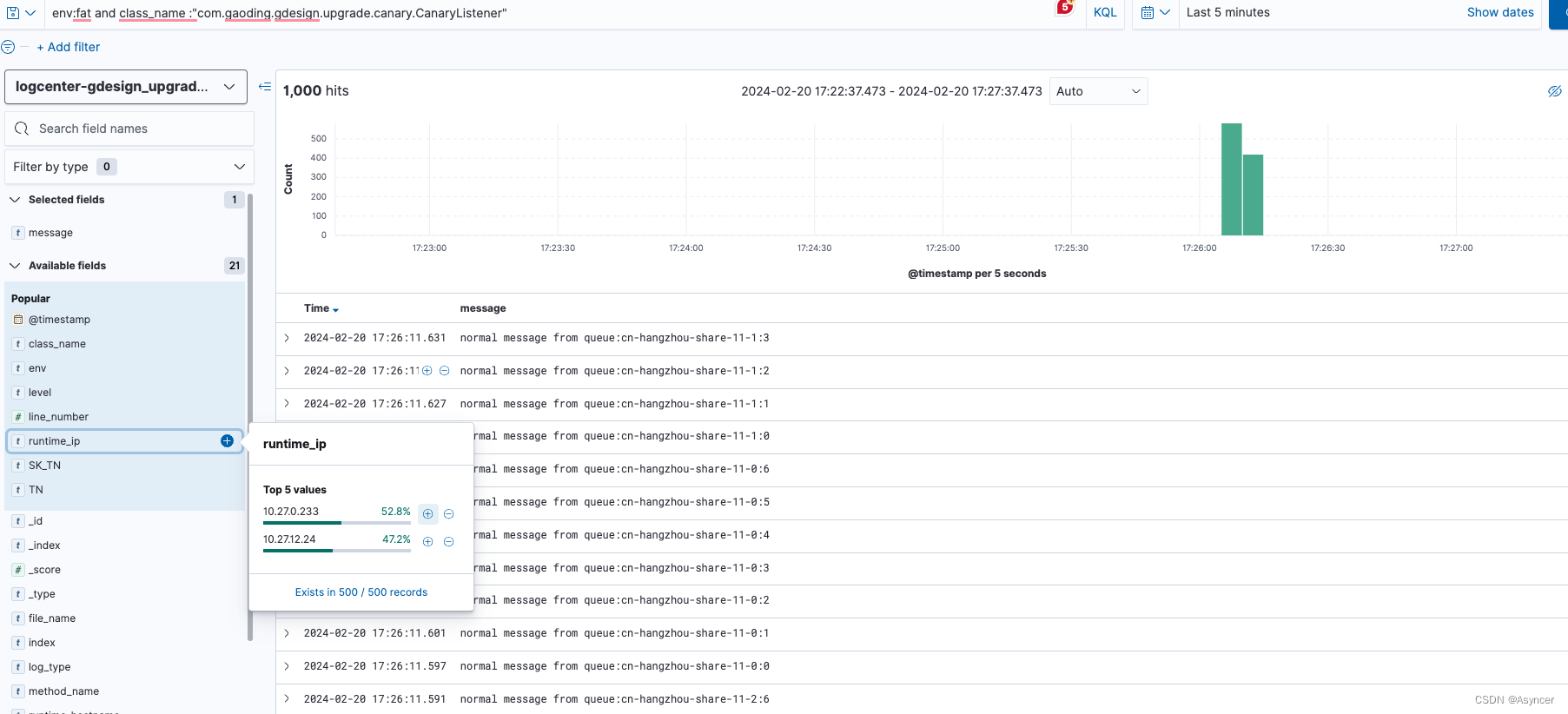
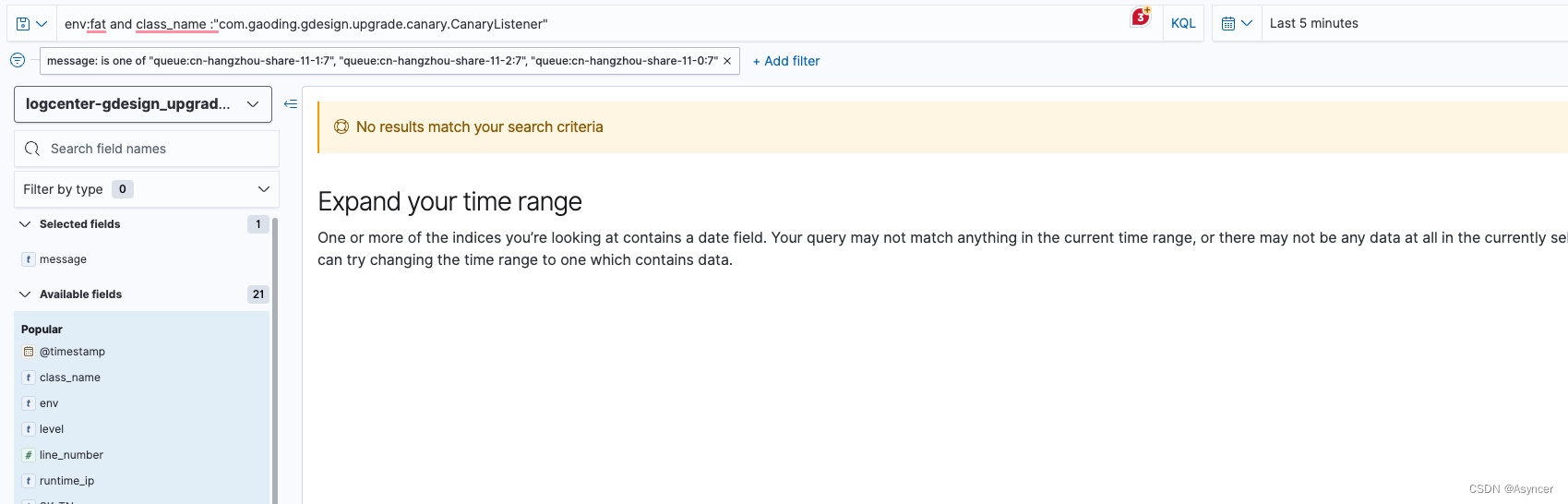
可以看到,消息被成功发出去了,消费端也消费到了,消费端在10.27.0.233和10.27.12.24这两个default集群的pod间负载均衡,灰度服务并没有消费到消息,也没有任何消息被发往broker的分区7。
然后我们再发送1000条灰度消息:
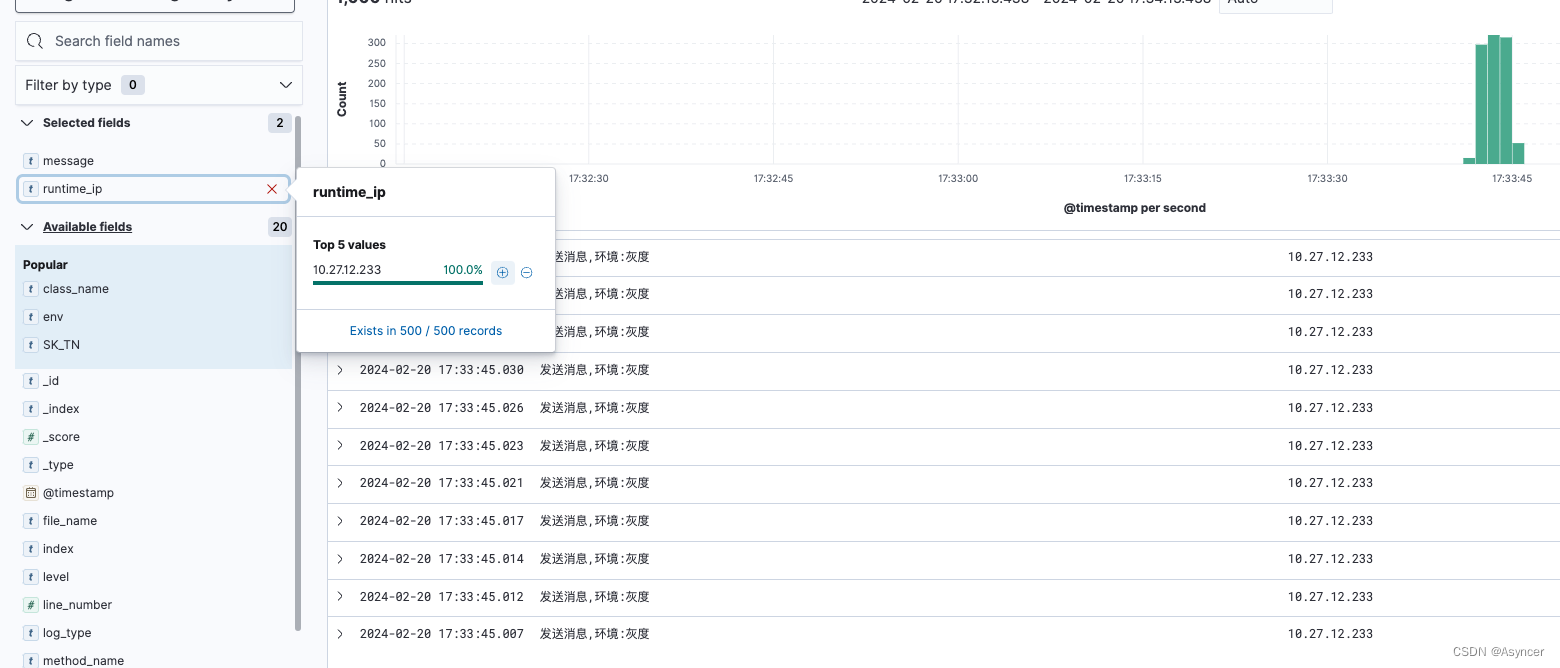

100条灰度的消息从灰度的发送方发出,每一条都落到了每个broker的最后一个分区上,而消费端只有灰度服务才稳稳的消费到了这1000条消息。
**测试结果: 在消费端开启灰度的情况下,正常情况下灰度的消息一定且只会被灰度的服务所消费到,非灰度的消息一定不会被灰度的服务消费到**
2.4 灰度服务异常下线,消息位点未提交
这边测试一个极端的场景: 当前后端都全部在灰度时,如果灰度服务突然下线,灰度分区中的消息将会如何处理? 因为消费代码比较简单,为了模拟出最真实的【消费还未完成,位点还未上报,服务异常下线】 情况,这边采用远程断点的方式,debug出灰度服务的pod消费代码:



IDEA debug被中断

可以看到灰度服务重启了

消息被消费了,但是ip是普通服务的ip
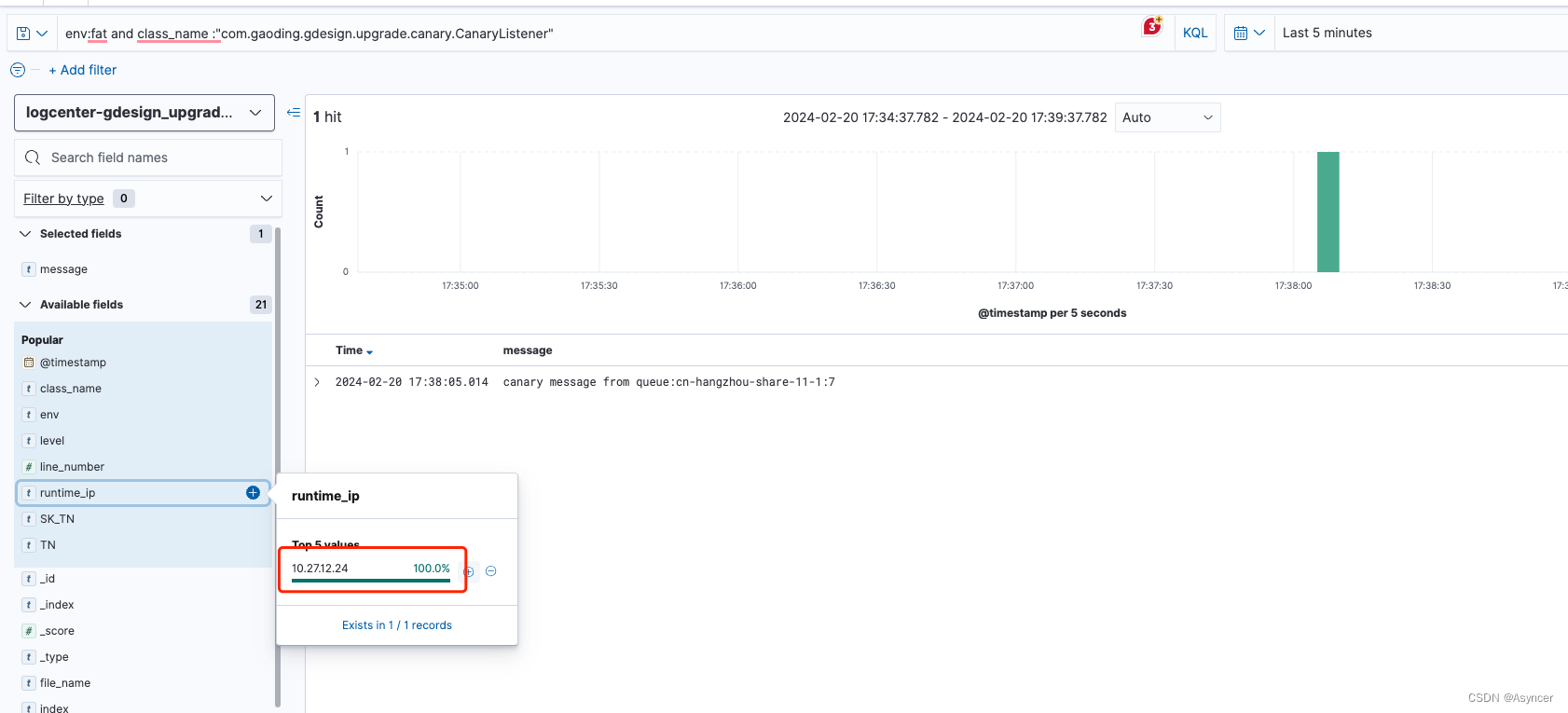
重启的瞬间,10.27.12.24这个pod瞬间接管了消息所在的分区,所有灰度分区被两个普通的pod重启瓜分

灰度pod重启后,重新变回开头的独立分布情况。

测试结果: 在消费端开启灰度的情况下,灰度服务异常下线,消息一定不会出现丢失,会被其他正常的服务立刻接管消费。
2.3 消费端灰度结束,发送端发送灰度/无灰度消息
在drms平台上将灰度中的服务点击验证通过,然后等待滚动更新,灰度服务下线:

灰度验证通过后可以从日志中看到,在服务滚动的过程中,每一个服务的上下线都会触发客户端重平衡,分区也一直在变换拥有者,但唯一不变的是24个分区同一时刻都会被分走,不会出现空队列无人消费的情况。直到最后灰度服务下线后,两个新的验证通过的默认集群pod启动成功,此时分区的平衡情况如下:
- 10.27.12.36: cn-hangzhou-share-11-0: (0, 1, 2, 3, 4, 5, 6, 7),cn-hangzhou-share-11-1: (0, 1, 2, 3) 12个队列
- 10.27.6.181: cn-hangzhou-share-11-1: (4, 5, 6, 7),cn-hangzhou-share-11-2: (0, 1, 2, 3, 4, 5, 6, 7) 12个队列
此时重新发送1000条普通消息:


普通消息如正常预期,被新启动的两个默认集群服务所平均消费。
再发送1000条灰度消息,模拟出当后端已经灰度完成,前端仍在灰度的场景:


灰度消息仍然精准的进到每个broker最后一个分区,同时因为没有灰度服务的原因,所以灰度分区被default集群的服务所瓜分,成功消费。
测试结果: 在消费端灰度验证通过上线的情况下,下游服务无论发送灰度还是非灰度消息,都会被新的消费端default集群服务消费,消息一定不会丢失
综上验证, 此方案是可以落地的、安全、高效的MQ灰度方案。
六、常见问题
Q1: 消费端和发送端如果没有同时升级,会怎样?
A1: 综合上面的讲解,其实很容易可以理解出来,这里用一个表格来描述这俩升级的不同情况:
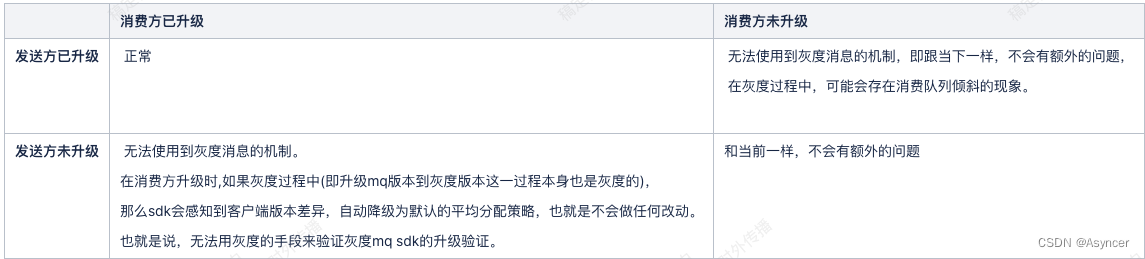
七、总结
本文是来自 稿定科技 内部技术分享文章,笔者为该文章作者,已隐去相关隐私代码,只为分享该方案而开放文档,此方案全网首发,不存在内容剽窃,若有雷同,请联系本人。