系列文章目录
Kafka第一章:环境搭建
文章目录
- 系列文章目录
- 前言
- 一、环境安装
- 1.前置环境
- 2.软件下载
- 3.上传集群并解压
- 4.编写配置文件
- 5.分发配置文件
- 6.修改参数
- 7.环境变量
- 8.启动服务
- 9.编写启动脚本
- 二、主题命令行操作
- 1.查看topic
- 2.创建 first topic
- 3.查看主题的详情
- 4.修改分区数
- 5.删除 topic
- 三、生产者命令行操作
- 1.发送消息
- 四、消费者命令行操作
- 1.消费 first 主题中的数据
- 2.把主题中所有的数据都读取出来
- 总结
前言
Kafka传 统定义:Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
Kafka最 新定义 : Kafka是 一个开源的 分 布式事件流平台 (Event Streaming Platform),被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用。
简单来说
kafka就是一个队列,用来缓解数据产生和数据上传之间的速度矛盾。当数据产生的速度超过上传速度,需要上传的数据就先进kafka排队等待。
一、环境安装
1.前置环境
安装kafka需要提前安装好zookeeper环境,未来kafka4或许又可能脱离zk运行,但现在还是需要安装。没装的,看前边的博客。
2.软件下载
官方地址
实验采用目前的最新版3.3.2并且用scala2.13编译。
3.上传集群并解压

tar -xvf kafka_2.13-3.3.2.tgz -C /opt/module/
mv kafka_2.13-3.3.2/ kafka

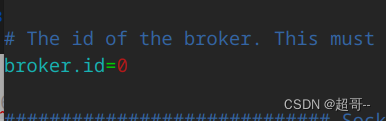
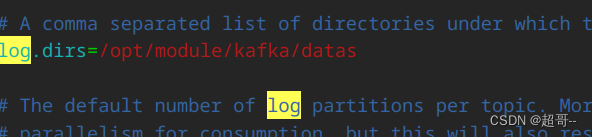
4.编写配置文件
一个需要修改三个参数
vim config/server.properties

5.分发配置文件

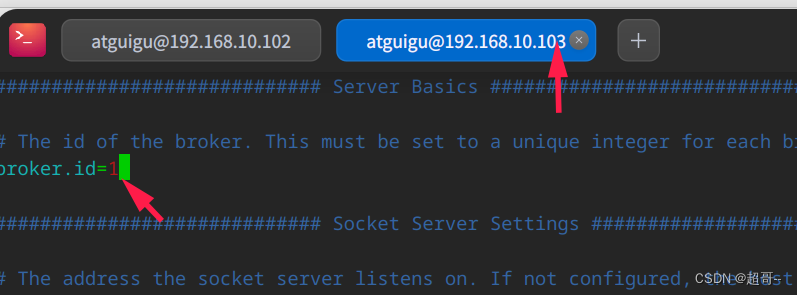
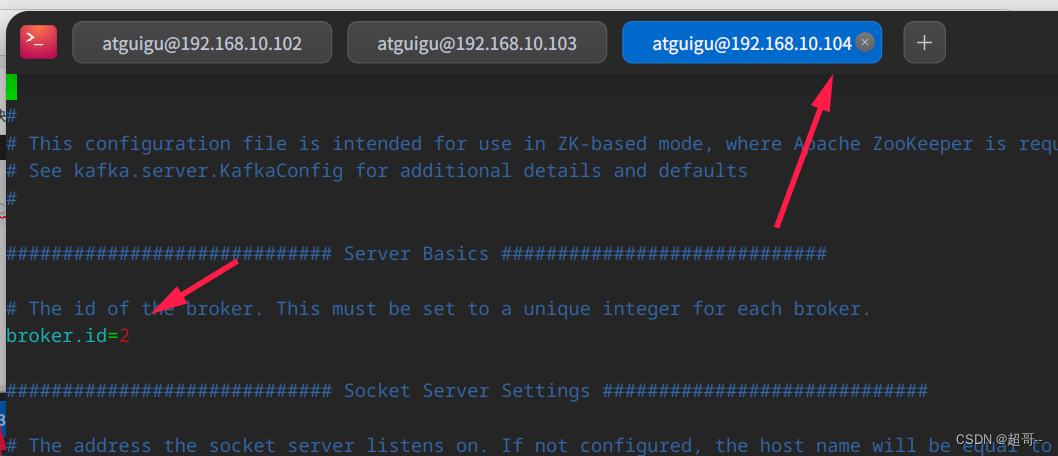
6.修改参数
在另外两台机器上修改参数
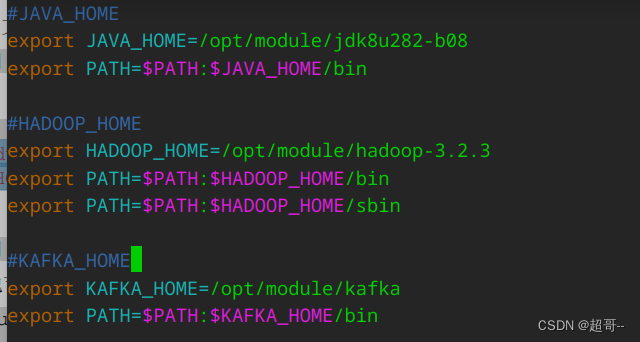
7.环境变量
sudo vim /etc/profile.d/my_env.sh
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
分发文件并且在每台机器source环境变量
sudo xsync /etc/profile.d/my_env.sh
source /etc/profile.d/my_env.sh
8.启动服务
先启动zk
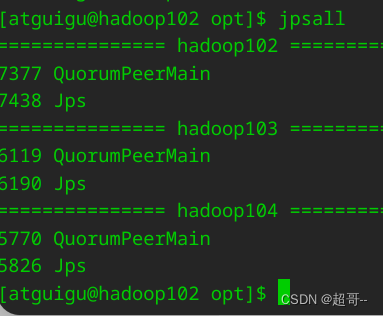
在每个节点的kafka目录使用如下命令。
bin/kafka-server-start.sh -daemon config/server.properties
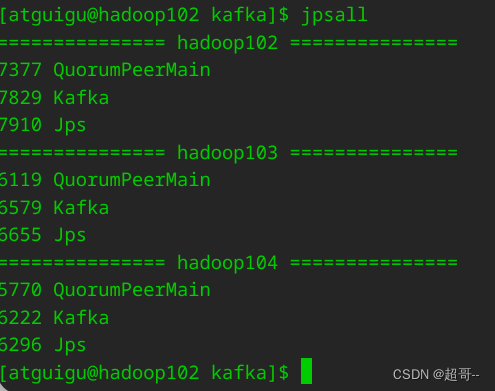
9.编写启动脚本
在/home/atguigu/bin 目录下创建文件 kf.sh 脚本文件
#! /bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------启动 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo " --------停止 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh "
done
};;
esac
为脚本添加权限。
chmod 777 kf.sh
chmod +x kf.sh
现在关闭kafka服务。
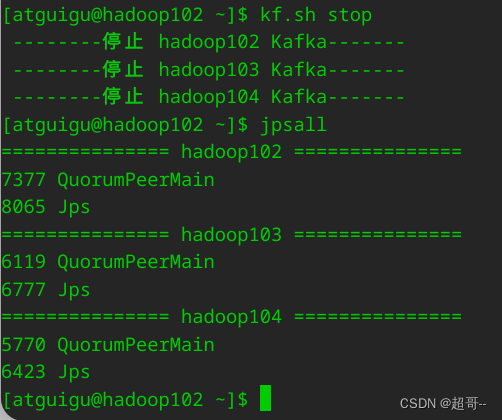
到现在位置kafka的环境安装完成,建议现在保存快照。
二、主题命令行操作
1.查看topic
现在是什么都没有的
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --list

2.创建 first topic
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --partitions 1 --replication-factor 3 --topic first
–topic 定义 topic 名
–replication-factor 定义副本数
–partitions 定义分区数

3.查看主题的详情
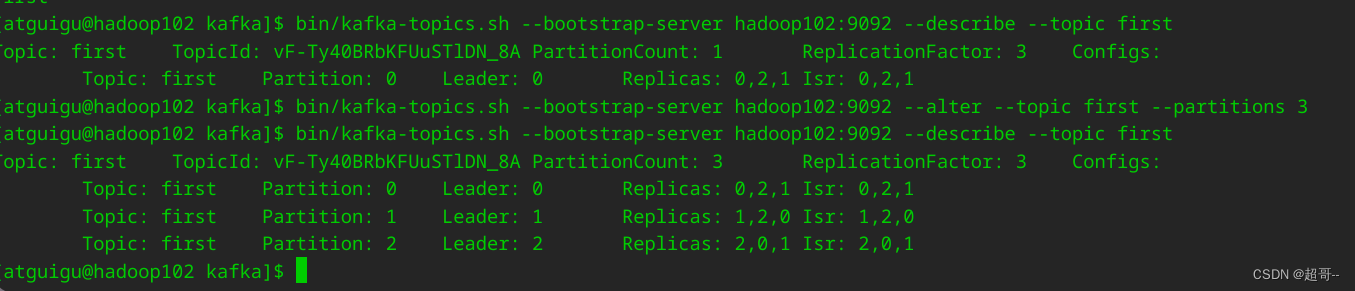
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic first

4.修改分区数
注:分区数只能增加,不能减少
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --alter --topic first --partitions 3
5.删除 topic
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --delete --topic first

三、生产者命令行操作
先创建一个first

1.发送消息
bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first

四、消费者命令行操作
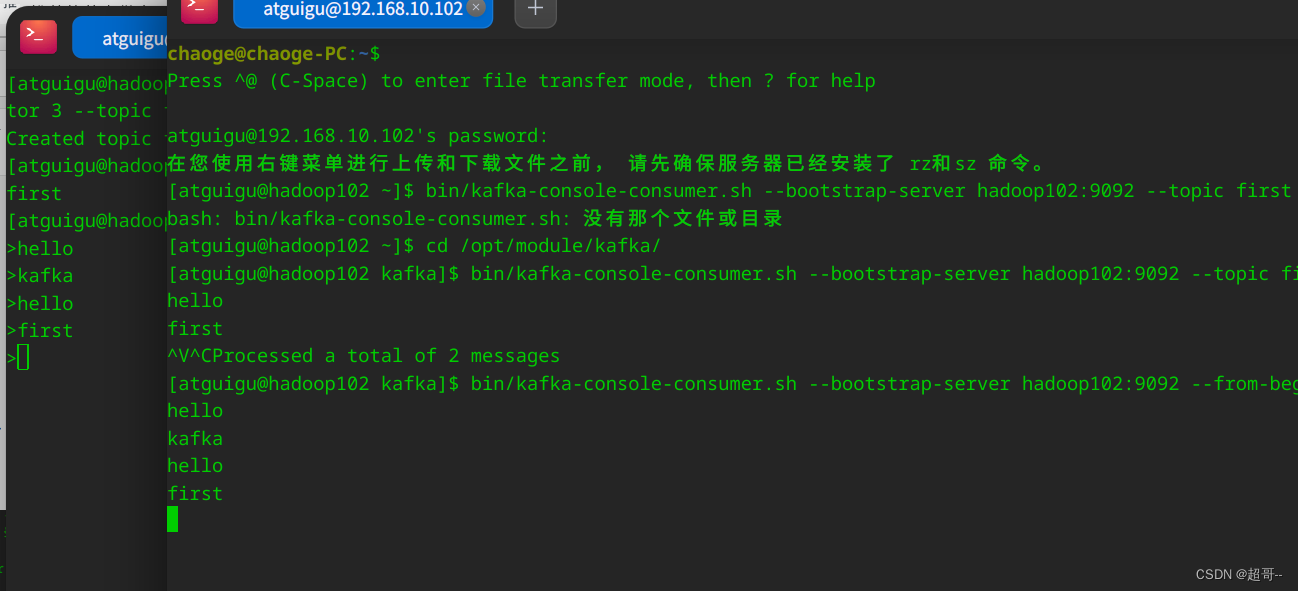
1.消费 first 主题中的数据
我们再开一个窗口进行消费者操作
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first

2.把主题中所有的数据都读取出来
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic first
总结
kafka也是hadoop核心生态中一个比较重要的组件,还是需要学习。
![[kubernetes]-k8s通过psp限制nvidia-plugin插件的使用](https://img-blog.csdnimg.cn/img_convert/fbeb9e31f760cd029406a2c286bdfe63.png)