前言👀~
上一章我们介绍设计模式中的单例模式,今天我们来讲讲生产者消费模式
阻塞队列(重要)
生产者消费模式(重要)
阻塞队列在生产者消费模型中的作用
标准库的阻塞队列
手动实现阻塞队列
如果各位对文章的内容感兴趣的话,请点点小赞,关注一手不迷路,讲解的内容我会搭配我的理解用我自己的话去解释如果有什么问题的话,欢迎各位评论纠正 🤞🤞🤞
个人主页:N_0050-CSDN博客
相关专栏:java SE_N_0050的博客-CSDN博客 java数据结构_N_0050的博客-CSDN博客 java EE_N_0050的博客-CSDN博客

阻塞队列(重要)
多线程代码中比较常用的一种数据结构
阻塞队列是一种特殊的队列,也遵守 "先进先出" 的原则,阻塞队列是一种线程安全的数据结构, 并且具有以下特性:
1.线程安全
2.带有阻塞特性
1.如果队列为空,出队列就会发生阻塞,阻塞到其他队列往队列里添加元素为止
2.如果队列为满,入队列就会发生堵塞,阻塞到其他队列从队列里取出元素为止
阻塞队列的最大作用,就是可以用来实现"生产者消费模型"(一种常见的多线程代码编写方式)
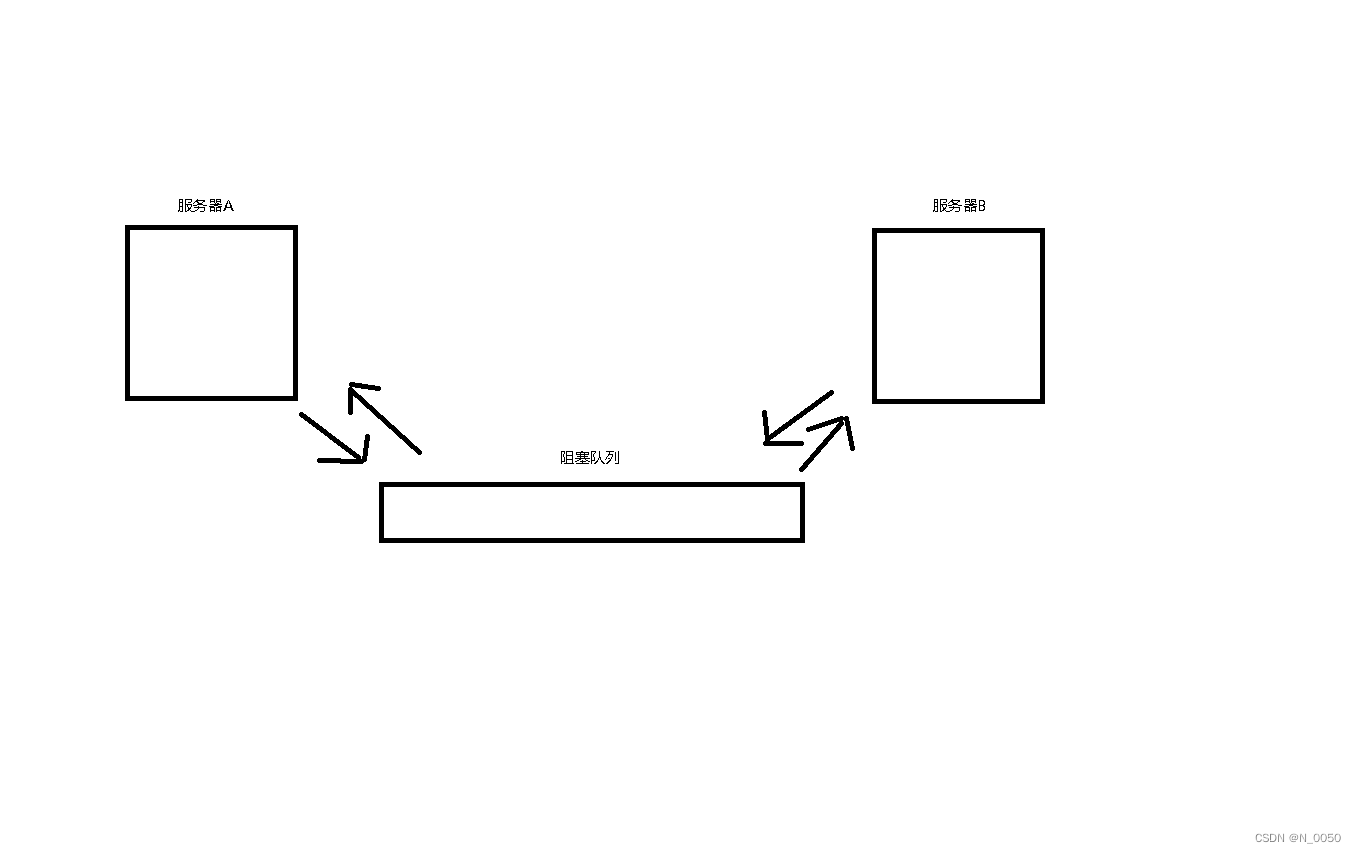
生产者消费模式(重要)
生产者消费者模式:就是通过一个容器来解决生产者和消费者的强耦合问题,这个容器就是阻塞队列。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取
生产者消费模型例子:华莱士或者肯德基
生产者(厨师):负责做汉堡
消费者(顾客):负责吃汉堡
缓冲区(柜台或托盘):存放已经做好的汉堡,等待顾客来取
在这个例子中,厨师会不断生产汉堡放在柜台上,顾客会从柜台取汉堡。厨师和顾客的速度不同,需要有一个存放汉堡的地方(缓冲区)来协调生产和消费的速度。这就是生产者-消费者模型的典型场景。
如果厨师汉堡做的慢,顾客想吃就要等待(队列为空,出队列就会发生阻塞)这倒没什么问题。如果厨师汉堡做的很快都没地方放了,厨师就可以休息会,但是汉堡浪费了多出来了处理不掉(队列为满,入队列就会发生堵塞),这个会造成问题。
阻塞队列在生产者消费模型中的作用
1.阻塞队列也能使生产者和消费者之间解耦合
问题1:对于分布式系统来说,有很大意义,比如在一个分布式系统下,客户端给服务器发送请求,然后服务器A负责接收用户请求并且接收服务器B处理好的请求传回客户端,服务器B负责处理用户请求并且将处理结果传回服务器A,此时服务器A和服务器B之间的耦合度就很高,如果其中一个服务器崩了,可能会影响到客户端这边的体验。此时如果加个服务器C,就要对服务器A代码做出改动和服务器C对接。但是这并不能实质性解决问题,还是可能会出现这样的问题
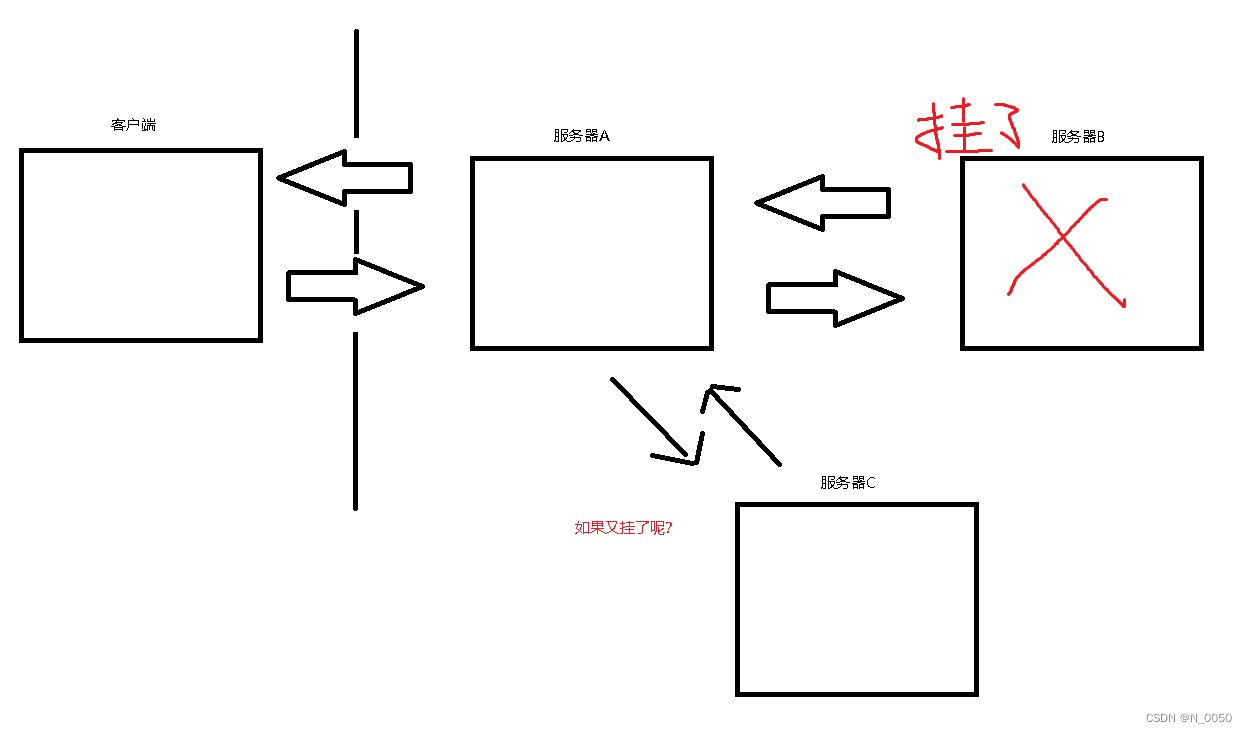
解决办法:在一个分布式系统下,此时客户端给服务器发送请求,然后服务器A还是负责接收用户请求,然后把请求丢到消息队列中,然后服务器B从消息队列中取出请求进行处理,处理后丢回消息队列,接着服务器A从队列中取出处理好的请求再传回客户端。这时候A和B之间没有联系就算服务器A或B出现问题,也不要紧,加个服务C就行了也不需要和服务器A进行对接修改代码啥的

阻塞队列也可能是个单独的服务器程序,把阻塞队列封装成单独的服务器程序部署到特定的机器上,这个时候把这个队列称为"消息队列"。消息队列应该是包含阻塞队列的,想让阻塞队列转变成消息队列,需要额外的实现一些功能。这个特定的机器上面有其他的功能,我们只是省下了功能,只不过是交给了机器去完成了。如果不进行封装,你想让阻塞队列变成消息队列,那么就需要咱们手动去加一些功能
2.阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力(想想618以及双11的情况下,阻塞队列的作用就很明显),也可以称削峰填谷,峰(短时间内请求量很多)谷(请求量少)
问题2:比如在一个分布式系统下,客户端给服务器发送了大量的请求,然后服务器A接收这些大量的请求立即发送给服务器B,所以A扛多少的访问量B也扛的也是一样。但是呢不同的服务器处理的业务不同,比如说服务器A就负责接收和发送请求,而服务器B呢不仅负责接收请求还要负责处理这些请求,在处理这些请求的时候,可能要去数据库拿数据再进行处理,服务器B呢可能处理不过来直接崩了,想想618以及双11的情况

解决办法:在一个分布式系统下,此时客户端给服务器发送了大量的请求,然后服务器A接收这些大量的请求,然后丢到消息队列中,然后服务器B从消息队列中取出请求进行处理,此时注意虽然有很大的请求需要处理,但是呢有消息队列扛着,服务器B可以按原先的速度处理这些请求,可能效率没那么高但是呢能保证会有响应,保证能对这些请求进行处理。总比直接把B搞崩了好,况且这种大量的请求场景持续的时间不久也就一下子,例如618和双11也就那一个时间点。所以这个消息队列在这种场景下能保证服务器能正常执行
标准库的阻塞队列
之前的Queue的方法,BlockingQueue也可以实现,但是这些方法没有阻塞的特点
1.基于数组
BlockingQueue<Integer> blockingQueue = new ArrayBlockingQueue<>(100);2.基于链表
BlockingQueue<Integer> blockingQueue = new LinkedBlockingQueue<>();put方法阻塞式的入队列,take方法阻塞式的出队列
public class Test {
public static void main(String[] args) throws InterruptedException {
BlockingQueue<Integer> blockingQueue = new LinkedBlockingQueue<>();
blockingQueue.put(1);
blockingQueue.put(2);
blockingQueue.put(3);
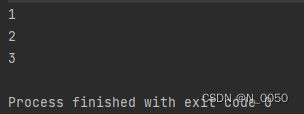
System.out.println(blockingQueue.take());
System.out.println(blockingQueue.take());
System.out.println(blockingQueue.take());
}
}输出结果
手动实现阻塞队列
基于一个普通队列加上线程安全、阻塞即可,这里使用基于数组(循环队列)手动实现阻塞队列
和之前我们实现循环队列一样,需要一个头来出元素,一个尾来放入元素,在这里只不过需要加入阻塞也就是我们的wait方法,以及保证线程安全加上锁,下面是代码的实现
class MyBlockingQueue {
public int[] array;
public int head;//头
public int tail;//尾
public int usedSize;
public MyBlockingQueue() {
array = new int[1000];
}
public void put(int val) throws InterruptedException {
synchronized (this) {
if (usedSize == array.length) {
this.wait();
}
array[tail] = val;
tail++;
if (tail == array.length) {//放元素的时候要注意数组满了的情况tail要重置
tail = 0;
}
usedSize++;
this.notify();
}
}
public int take() throws InterruptedException {
synchronized (this) {
if (usedSize == 0) {
this.wait();
}
int value = array[head];
head++;
usedSize--;
this.notify();
return value;
}
}
}上述代码这么写,不会出现什么问题,但是呢put方法如果是下面这样写的话可能会出现问题,什么问题呢?当一个线程使用notify方法或者interrupt方法来唤醒wait方法的时候,此时数组还是满的,然后唤醒后捕获到异常,它会接着往下执行,会把最后一个元素覆盖掉,并且usedSize++,这就出现问题了。之所以上面的代码不会出现问题是因为即使wait被唤醒,它会直接抛出异常然后线程退出。记住wait除了可以使用notify唤醒,还可以使用interrupt方法中断wait的状态
public void put(int val) {
synchronized (this) {
if (usedSize == array.length) {
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
array[tail] = val;
tail++;
if (tail == array.length) {//放元素的时候要注意数组满了的情况tail要重置
tail = 0;
}
usedSize++;
this.notify();
}
}解决办法:你可以在捕获异常后直接return返回,但是更推荐直接把if语句改成while循环,并且java官方也是推荐使用while循环的
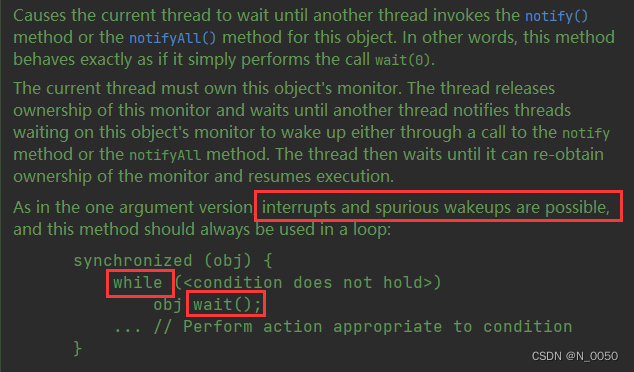
public void put(int val) {
synchronized (this) {
while (usedSize == array.length) {
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
array[tail] = val;
tail++;
if (tail == array.length) {//放元素的时候要注意数组满了的情况tail要重置
tail = 0;
}
usedSize++;
this.notify();
}
}这样改后,就保守多了,不会出现上述提到的问题,但是注意可能会出现内存可见性问题,因为我们的变量又涉及到读又涉及到修改又涉及到比较的操作,谨慎为主给变量加上volatile关键字
public volatile int head;//头
public volatile int tail;//尾
public volatile int usedSize;
完整阻塞队列代码
class MyBlockingQueue {
public int[] array;
public volatile int head;//头
public volatile int tail;//尾
public volatile int usedSize;
public MyBlockingQueue() {
array = new int[1000];
}
public void put(int val) throws InterruptedException {
synchronized (this) {
while (usedSize == array.length) {
this.wait();
}
array[tail] = val;
tail++;
if (tail == array.length) {//放元素的时候要注意数组满了的情况tail要重置
tail = 0;
}
usedSize++;
this.notify();
}
}
public int take() throws InterruptedException {
synchronized (this) {
while (usedSize == 0) {
this.wait();
}
int value = array[head];
head++;
usedSize--;
this.notify();
return value;
}
}
}
public class Test1 {
public static int i = 0;
public static void main(String[] args) {
MyBlockingQueue blockingQueue = new MyBlockingQueue();
Thread t1 = new Thread(() -> {
while (true) {
try {
System.out.println("生产:" + i);
blockingQueue.put(i);
i++;
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
t1.start();
Thread t2 = new Thread(() -> {
while (true) {
try {
System.out.println("消费:" + blockingQueue.take());
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
t2.start();
}
}以上便是本章生产者消费模式的内容,在我们的日常开发中还是比较常见的,好好掌握,我们下一章还是讲解有关多线程的内容再见💕