秋招面试专栏推荐 :深度学习算法工程师面试问题总结【百面算法工程师】——点击即可跳转
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡
专栏目录 :《YOLOv8改进有效涨点》专栏介绍 & 专栏目录 | 目前已有40+篇内容,内含各种Head检测头、损失函数Loss、Backbone、Neck、NMS等创新点改进——点击即可跳转
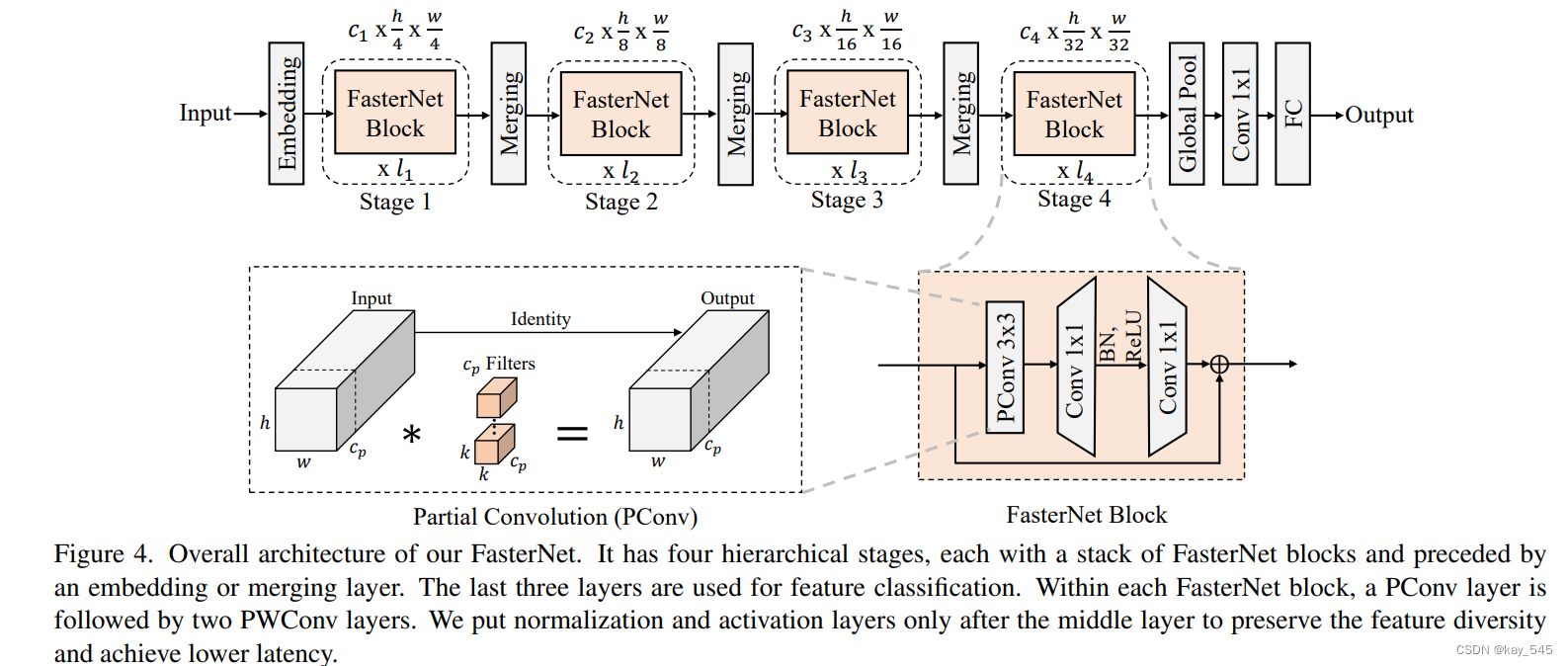
为了设计快速的神经网络,许多研究专注于减少浮点运算(FLOPs)的数量。然而,减少FLOPs并不总是能相应减少延迟,这是因为运算效率低,即每秒浮点运算数(FLOPS)低。这种低效主要是由于运算符频繁的内存访问,尤其是深度可分离卷积。为了解决这个问题,提出了一个新的部分卷积(PConv),它能更有效地提取空间特征,同时减少冗余的计算和内存访问。基于PConv,进一步提出了FasterNet,这是一个新的神经网络家族,它在各种设备上实现了比其他网络更高的运行速度,同时不会在各种视觉任务上牺牲准确性。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
目录
1. 原理
2. 将PConv添加到YOLOv8代码
2.1 PConv代码实现
2.2 更改init.py文件
2.3 新增yaml文件
2.4 注册模块
2.5 执行程序
3. 完整代码分享
4. GFLOPs
5. 进阶
6. 总结
1. 原理

论文地址:Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks ——点击即可跳转
官方代码:官方代码仓库——点击即可跳转
PConv (Partial Convolution) 主要原理
PConv(Partial Convolution)是一种新颖的卷积操作,旨在提高神经网络的计算速度和效率。PConv的设计思路是通过减少冗余计算和内存访问来提升浮点运算速度(FLOPS),从而解决深度卷积(Depthwise Convolution, DWConv)中存在的低FLOPS问题。
主要原理
-
冗余利用:PConv 利用特征图中的冗余。特征图的不同通道之间往往存在高度相似性(如图3所示)。PConv 通过仅对部分输入通道应用常规卷积(Regular Convolution),而对其余通道不进行操作,从而减少了计算量和内存访问。
-
减少内存访问:DWConv 通常会导致频繁的内存访问,这是导致低FLOPS的主要原因之一。PConv 通过减少对内存的访问,降低了计算延迟。
-
高效的空间特征提取:PConv 在保留常规卷积提取空间特征能力的同时,减少了冗余计算。相比于常规卷积,PConv 具有更低的FLOPs,而相比于DWConv/GConv,则具有更高的FLOPS。
设计细节
-
部分通道卷积:PConv 在输入特征图的部分通道上应用卷积操作,其他通道保持不变。这种方式既减少了计算量,也降低了内存访问的频率。
-
计算效率优化:通过优化卷积操作的执行,PConv 在减少FLOPs 的同时,能够更好地利用设备的计算能力,从而提高实际运行速度。
应用与性能
基于PConv,作者提出了FasterNet,一种新的神经网络家族,具有较低的延迟和较高的吞吐量。实验结果表明,FasterNet在多种设备上(如GPU、CPU和ARM处理器)都表现出色,能够在不牺牲精度的情况下大幅提高运行速度。
例如,FasterNet-T0在ImageNet-1k上的表现比MobileViT-XXS快2.8倍、3.3倍和2.4倍,同时准确率提高了2.9%。FasterNet-L则在保持与Swin-B相当的准确率(83.5%)的情况下,GPU推理吞吐量提高了36%,CPU计算时间减少了37%。
通过这些优化,PConv和FasterNet展示了在实际应用中提升神经网络计算速度的巨大潜力。
2. 将PConv添加到YOLOv8代码
2.1 PConv代码实现
关键步骤一:将下面代码粘贴到在/ultralytics/ultralytics/nn/modules/conv.py中,并在该文件的__all__中添加“PConv”
class PConv(nn.Module):
def __init__(self, dim, ouc, n_div=4, forward='split_cat'):
super().__init__()
self.dim_conv3 = dim // n_div
self.dim_untouched = dim - self.dim_conv3
self.partial_conv3 = nn.Conv2d(self.dim_conv3, self.dim_conv3, 3, 1, 1, bias=False)
self.conv = Conv(dim, ouc, k=1)
if forward == 'slicing':
self.forward = self.forward_slicing
elif forward == 'split_cat':
self.forward = self.forward_split_cat
else:
raise NotImplementedError
def forward_slicing(self, x):
# only for inference
x = x.clone() # !!! Keep the original input intact for the residual connection later
x[:, :self.dim_conv3, :, :] = self.partial_conv3(x[:, :self.dim_conv3, :, :])
x = self.conv(x)
return x
def forward_split_cat(self, x):
# for training/inference
x1, x2 = torch.split(x, [self.dim_conv3, self.dim_untouched], dim=1)
x1 = self.partial_conv3(x1)
x = torch.cat((x1, x2), 1)
x = self.conv(x)
return xPConv是一种通过减少计算冗余和内存访问来高效处理图像的技术。下面是 PConv 处理图像的概述:
PConv 的主要流程
部分卷积应用:
-
PConv 仅对部分输入通道而非全部输入通道应用常规卷积。这种选择性方法利用了不同通道间特征图中的冗余。
-
该过程将第一个或最后一个连续通道视为计算的代表,从而减少了总体计算负荷。
减少计算冗余:
-
通过仅使用通道子集(表示为总通道中 ( c ) 个通道中的 ( c_p ) 个),与常规卷积相比,PConv 的 FLOP(浮点运算)显著减少。
-
例如,在典型的部分比率 ( r = \frac{c_p}{c} = \frac{1}{4} ) 下,PConv 的 FLOP 仅为常规卷积的 1/16。
内存访问优化:
-
PConv 还减少了内存访问。所需内存约为 ( h \times w \times 2c_p ),这仅仅是完整卷积所需内存的一小部分。
-
未卷积的其余通道保持不变,以便在后续层中使用。
与逐点卷积 (PWConv) 结合:
-
为了利用所有通道的信息,PConv 后面是逐点卷积 (PWConv)。这种组合可确保高效利用整个特征图。
-
PConv 和 PWConv 组合的有效感受野类似于 T 形卷积,与均匀处理整个块的常规卷积相比,它更关注中心区域。
效率论证:
-
通过使用 Frobenius 范数评估位置重要性来证明 T 形感受野的合理性,这表明中心位置往往更重要。
-
该方法有效地节省了计算资源并保持了特征信息流的完整性。
总之,PConv 通过部分卷积输入通道并将其与 PWConv 相结合以有效利用整个特征图,从而减少了计算和内存开销。
2.2 更改init.py文件
关键步骤二:修改modules文件夹下的__init__.py文件,先导入函数
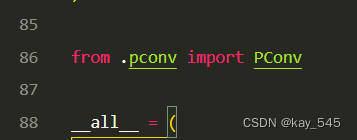
然后在下面的__all__中声明函数

2.3 新增yaml文件
关键步骤三:在 \ultralytics\ultralytics\cfg\models\v8下新建文件 yolov8_PConv.yaml并将下面代码复制进去
# Ultralytics YOLO 🚀, GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [-1, 1, PConv, [1024]] # 21 (P5/32-large)
- [[15, 18, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)温馨提示:因为本文只是对yolov8基础上添加模块,如果要对yolov8n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple。
# YOLOv8n
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
max_channels: 1024 # max_channels
# YOLOv8s
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
max_channels: 1024 # max_channels
# YOLOv8l
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
max_channels: 512 # max_channels
# YOLOv8m
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
max_channels: 768 # max_channels
# YOLOv8x
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple
max_channels: 512 # max_channels2.4 注册模块
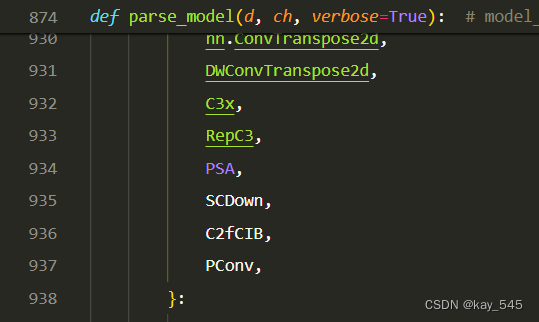
关键步骤四:在parse_model函数中进行注册,添加PConv,
2.5 执行程序
在train.py中,将model的参数路径设置为yolov8_PConv.yaml的路径
建议大家写绝对路径,确保一定能找到
from ultralytics import YOLO
# Load a model
# model = YOLO('yolov8n.yaml') # build a new model from YAML
# model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
model = YOLO(r'/projects/ultralytics/ultralytics/cfg/models/v8/yolov8_PConv.yaml') # build from YAML and transfer weights
# Train the model
model.train(batch=16)🚀运行程序,如果出现下面的内容则说明添加成功🚀
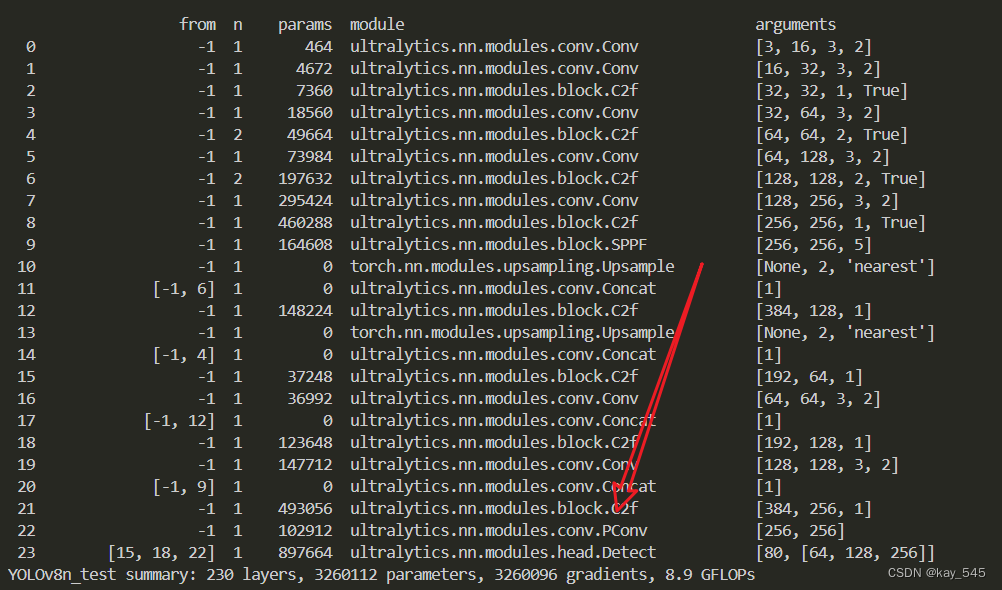
3. 完整代码分享
https://pan.baidu.com/s/1hDebfGjMj0k0GQUbRnB7HA?pwd=sen6提取码: sen6
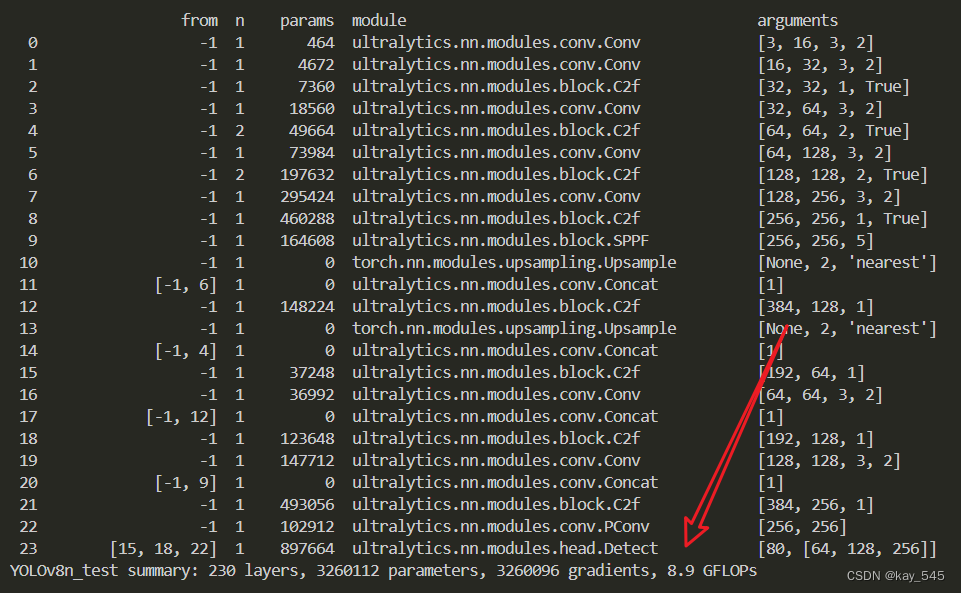
4. GFLOPs
关于GFLOPs的计算方式可以查看:百面算法工程师 | 卷积基础知识——Convolution
未改进的YOLOv8nGFLOPs
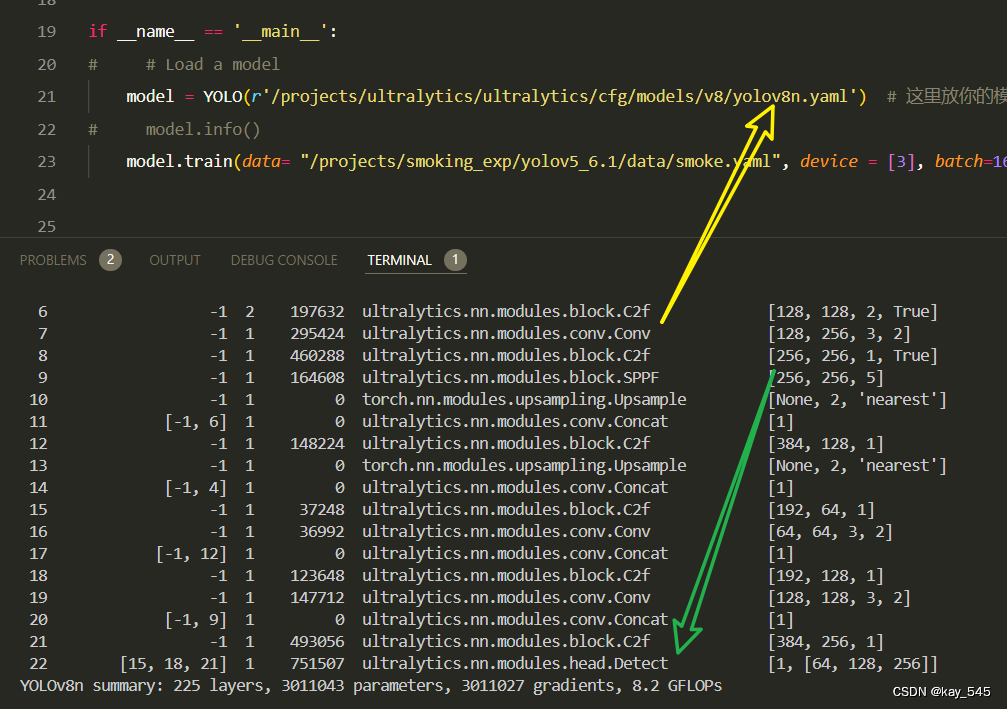
改进后的GFLOPs
5. 进阶
可以与其他的注意力机制或者损失函数等结合,进一步提升检测效果
6. 总结
PConv (Partial Convolution) 是一种优化神经网络计算效率的方法,通过仅对部分输入通道应用卷积操作来减少计算量和内存访问。具体来说,PConv 在特征图的部分通道上进行常规卷积,而保留其他通道不变,从而减少了计算冗余和内存访问频率。随后,通过点卷积(Pointwise Convolution, PWConv)结合这些部分卷积结果,确保所有特征通道的信息得以有效利用。PConv 这种选择性卷积的设计利用了特征图中不同通道之间的冗余性,显著提升了计算效率和速度,同时保持了特征提取的完整性和精度。