运行时字段(runtime fields)是在查询时计算的字段。运行时字段使你能够:
- 向现有文档添加字段而无需重新索引数据
- 开始处理数据而无需了解其结构
- 在查询时覆盖索引字段返回的值
- 定义用于特定用途的字段而无需修改底层架构
你可以像访问其他任何字段一样从 search API 访问运行时字段,Elasticsearch 对运行时字段的看法也一样。你可以在 index mapping 或 search request 中定义运行时字段。你的选择是运行时字段固有灵活性的一部分。
使用 _search API 上的 fields 参数来检索运行时字段的值。运行时字段不会显示在 _source 中,但 fields API 适用于所有字段,即使是那些未作为原始 _source 的一部分发送的字段。
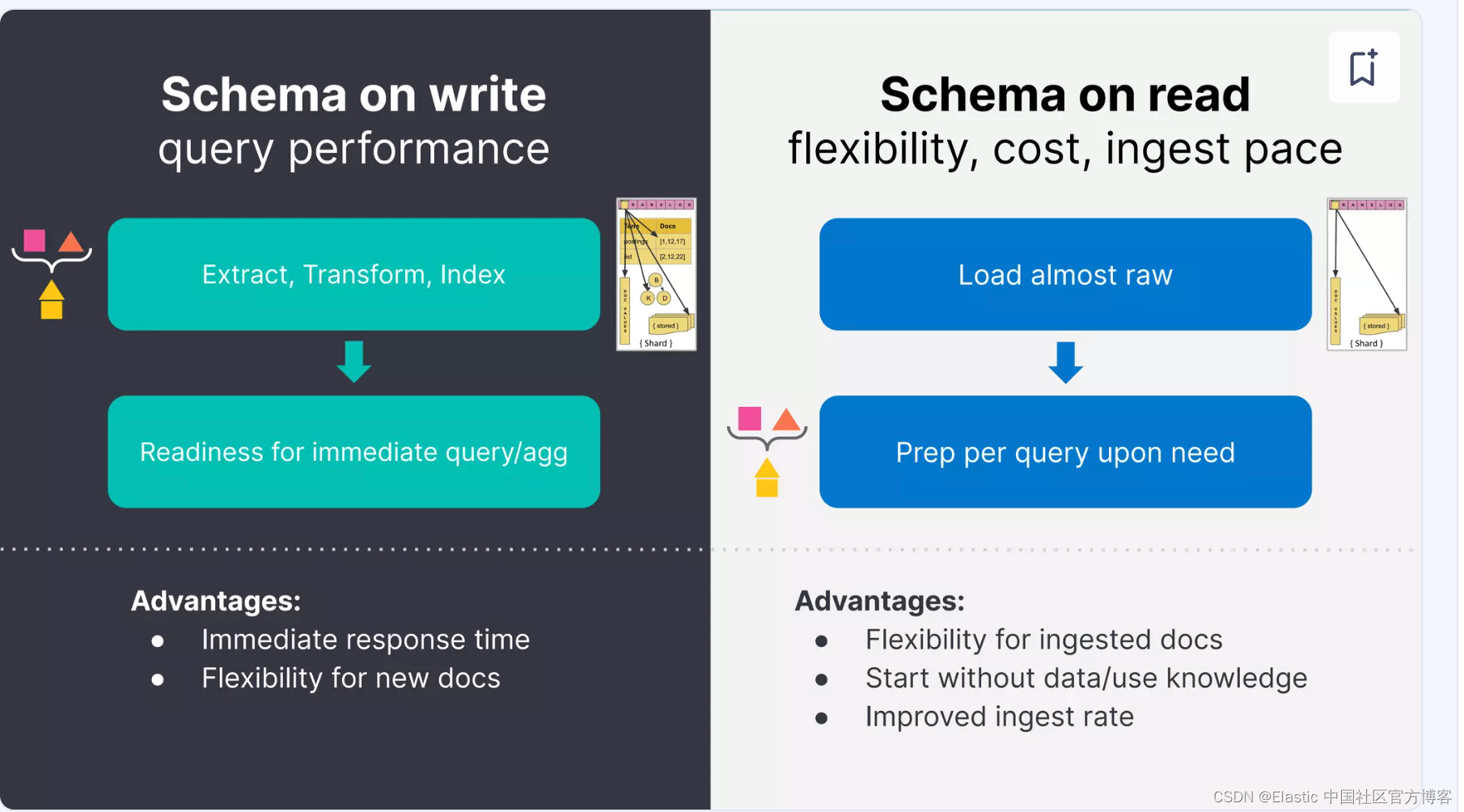
运行时字段在处理日志数据时很有用(参见后面的示例),尤其是当你不确定数据结构时。你的搜索速度会降低,但索引大小会小得多,你可以更快地处理日志而无需索引它们。
使用运行时字段带来的好处
由于运行时字段未编入索引,因此添加运行时字段不会增加索引大小。你可以直接在索引映射中定义运行时字段,从而节省存储成本并提高提取速度。你可以更快地将数据提取到 Elastic Stack 中并立即访问。定义运行时字段后,你可以立即将其用于搜索请求、聚合、过滤和排序。
如果将运行时字段更改为索引字段,则无需修改引用该运行时字段的任何查询。更好的是,你可以引用一些字段是运行时字段的索引,以及字段是索引字段(indexed field)的其他索引。你可以灵活地选择要索引哪些字段以及将哪些字段保留为运行时字段。
从本质上讲,运行时字段最重要的好处是能够在提取字段后将字段添加到文档中。此功能简化了映射决策,因为你不必预先决定如何解析数据,并且可以随时使用运行时字段来修改映射。使用运行时字段允许更小的索引和更快的摄取时间,从而结合使用更少的资源并降低运营成本。

激励
运行时字段可以取代使用 _search API 编写脚本的许多方式。运行时字段的使用方式受所包含脚本所针对的文档数量的影响。例如,如果你使用 _search API 上的 fields 参数来检索运行时字段的值,则脚本只会像脚本字段一样针对热门匹配项运行。
你可以使用脚本字段(script fields)访问 _source 中的值并返回基于脚本估值的计算值。运行时字段具有相同的功能,但提供了更大的灵活性,因为你可以在搜索请求中查询和聚合运行时字段。脚本字段只能获取值。
同样,你可以编写一个 script query,根据脚本过滤搜索请求中的文档。运行时字段提供了一个非常相似的功能,但更加灵活。你编写一个脚本来创建字段值,它们在任何地方都可用,例如 fields、所有查询和聚合。
你还可以使用脚本对搜索结果进行排序,但同一个脚本在运行时字段中的工作方式完全相同。
如果你将脚本从搜索请求中的任何部分移至从相同数量的文档计算值的运行时字段,则性能应该大致相同。这些功能的性能在很大程度上取决于所包含脚本正在运行的计算以及脚本针对多少个文档运行。
折衷
运行时字段占用较少的磁盘空间,并为你提供访问数据的灵活性,但可能会根据运行时脚本中定义的计算影响搜索性能。
为了平衡搜索性能和灵活性,请索引你经常搜索和过滤的字段,例如时间戳。Elasticsearch 在运行查询时会自动首先使用这些索引字段,从而缩短响应时间。然后,你可以使用运行时字段来限制 Elasticsearch 需要计算值的字段数量。将索引字段与运行时字段结合使用,可以灵活地索引数据以及如何定义其他字段的查询。
使用 asynchronous search API 运行包含运行时字段的搜索。这种搜索方法有助于抵消计算每个包含该字段的文档中的运行时字段值对性能的影响。如果查询无法同步返回结果集,你将在结果可用时异步获得结果。
重要:针对运行时字段的查询被认为是昂贵的。如果 search.allow_expensive_queries 设置为 false,则不允许昂贵的查询,并且 Elasticsearch 将拒绝任何针对运行时字段的查询。
映射运行时字段
通过在映射定义下添加运行时部分并定义 Painless 脚本,可以映射运行时字段。此脚本可以访问文档的整个上下文,包括通过 params._source 访问的原始 _source 以及任何映射字段及其值。在查询时,脚本会运行并为查询所需的每个脚本字段生成值。
发出运行时字段值
在定义用于运行时字段的 Painless 脚本时,必须包含 emit 方法来发出计算值。
例如,以下请求中的脚本从 @timestamp 字段(定义为日期类型)计算星期几。该脚本根据 timestamp 的值计算星期几,并使用 emit 返回计算值。
PUT my-index-000001
{
"mappings": {
"runtime": {
"day_of_week": {
"type": "keyword",
"script": {
"source": "emit(doc['@timestamp'].value.dayOfWeekEnum.getDisplayName(TextStyle.FULL, Locale.ROOT))"
}
}
},
"properties": {
"@timestamp": {"type": "date"}
}
}
}
PUT my-index-000001/_doc/1
{
"@timestamp": "2024-06-24T04:54:59"
}我们可以使用如下的命令来查看我们的索引:
GET my-index-000001/_search
{
"fields": [
"day_of_week"
]
}上面的命令返回的结果为:
{
"took": 19,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "my-index-000001",
"_id": "1",
"_score": 1,
"_source": {
"@timestamp": "2024-06-24T04:54:59"
},
"fields": {
"day_of_week": [
"Monday"
]
}
}
]
}
}在上面,我们可以看到 day_of_week 的字段值为 Monday。
runtime 部分可以是以下任何一种数据类型:
booleancompositedatedoublegeo_pointipkeywordlong- lookup
具有日期类型的运行时字段可以接受与 date 字段类型完全相同的 format 参数。
具有 lookup 类型的运行时字段允许从相关索引中检索字段。请详细参阅之后的章节。如果启用了 dynamic field mapping,其中 dynamic 参数设置为 runtime,则新字段将自动作为运行时字段添加到索引映射中:
PUT my-index-000001
{
"mappings": {
"dynamic": "runtime",
"properties": {
"@timestamp": {
"type": "date"
}
}
}
}定义运行时字段而不使用脚本
运行时字段通常包含一个 Painless 脚本,该脚本以某种方式操纵数据。但是,有些情况下,你可能会定义一个运行时字段而不使用脚本。例如,如果你想从 _source 中检索单个字段而不进行更改,则不需要脚本。你可以创建一个没有脚本的运行时字段,例如 day_of_week:
PUT my-index-000001/
{
"mappings": {
"runtime": {
"day_of_week": {
"type": "keyword"
}
}
}
}如果未提供脚本,Elasticsearch 会在查询时隐式地在 _source 中查找与运行时字段同名的字段,并返回一个值(如果存在)。如果不存在同名的字段,则响应不包含该运行时字段的任何值。
在大多数情况下,尽可能通过 doc_values 检索字段值。由于数据从 Lucene 加载的方式,使用运行时字段访问 doc_values 比从 _source 检索值更快。
但是,在某些情况下,从 _source 检索字段是必要的。例如,文本字段默认没有可用的 doc_values,因此你必须从 _source 检索值。在其他情况下,你可以选择在特定字段上禁用 doc_values。
注意:你也可以在要检索值的字段前加上 params._source 前缀(例如 params._source.day_of_week)。为简单起见,建议尽可能在映射定义中定义运行时字段而不使用脚本。
忽略运行时字段上的脚本错误
脚本可能会在运行时抛出错误,例如访问文档中缺失或无效的值或执行无效操作时。当发生这种情况时,on_script_error 参数可用于控制错误行为。将此参数设置为 continue 将默认忽略此运行时字段上的所有错误。默认失败值将导致分片失败,并在搜索响应中报告。
更新和删除运行时字段
你可以随时更新或删除运行时字段。要替换现有运行时字段,请将新运行时字段添加到同名映射中。要从映射中删除运行时字段,请将运行时字段的值设置为 null:
PUT my-index-000001/_mapping
{
"runtime": {
"day_of_week": null
}
}下游影响 - Downstream impacts
在依赖查询运行时更新或删除运行时字段可能会返回不一致的结果。每个分片可能有权访问脚本的不同版本,具体取决于映射更改的生效时间。
警告:如果你删除或更新字段,则 Kibana 中依赖于运行时字段的现有查询或可视化可能会失败。例如,如果将类型更改为布尔值或删除运行时字段,则使用 ip 类型运行时字段的条形图可视化将会失败。
在搜索请求中定义运行时字段
你可以在搜索请求中指定一个 runtime_mappings 部分,以创建仅作为查询的一部分存在的运行时字段。你可以将脚本指定为 runtime_mappings 部分的一部分,就像将运行时字段添加到映射一样。
在搜索请求中定义运行时字段使用的格式与在索引映射中定义运行时字段的格式相同。只需将字段定义从索引映射中的运行时复制到搜索请求的 runtime_mappings 部分即可。
以下搜索请求将 day_of_week 字段添加到 runtime_mappings 部分。字段值将动态计算,并且仅在此搜索请求的上下文中计算:
DELETE my-index-000001
PUT my-index-000001/_doc/1
{
"@timestamp": "2024-06-24T04:54:59"
}
GET my-index-000001/_search
{
"runtime_mappings": {
"day_of_week": {
"type": "keyword",
"script": {
"source": "emit(doc['@timestamp'].value.dayOfWeekEnum.getDisplayName(TextStyle.FULL, Locale.ROOT))"
}
}
},
"aggs": {
"day_of_week": {
"terms": {
"field": "day_of_week"
}
}
}
}上面查询请求的结果为:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "my-index-000001",
"_id": "1",
"_score": 1,
"_source": {
"@timestamp": "2024-06-24T04:54:59"
}
}
]
},
"aggregations": {
"day_of_week": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "Monday",
"doc_count": 1
}
]
}
}
}创建使用其他运行时字段的运行时字段
你甚至可以在搜索请求中定义运行时字段,以返回来自其他运行时字段的值。例如,假设你批量索引一些传感器数据:
DELETE my-index-000001
POST my-index-000001/_bulk?refresh=true
{"index":{}}
{"@timestamp":1516729294000,"model_number":"QVKC92Q","measures":{"voltage":"5.2","start": "300","end":"8675309"}}
{"index":{}}
{"@timestamp":1516642894000,"model_number":"QVKC92Q","measures":{"voltage":"5.8","start": "300","end":"8675309"}}
{"index":{}}
{"@timestamp":1516556494000,"model_number":"QVKC92Q","measures":{"voltage":"5.1","start": "300","end":"8675309"}}
{"index":{}}
{"@timestamp":1516470094000,"model_number":"QVKC92Q","measures":{"voltage":"5.6","start": "300","end":"8675309"}}
{"index":{}}
{"@timestamp":1516383694000,"model_number":"HG537PU","measures":{"voltage":"4.2","start": "400","end":"8625309"}}
{"index":{}}
{"@timestamp":1516297294000,"model_number":"HG537PU","measures":{"voltage":"4.0","start": "400","end":"8625309"}}索引后,你意识到你的数字数据被映射为 text 类型。你想在 measures.start 和 measures.end 字段上进行聚合,但聚合失败,因为你无法在文本类型的字段上进行聚合。运行时字段来拯救你!你可以添加与索引字段同名的运行时字段并修改数据类型:
PUT my-index-000001/_mapping
{
"runtime": {
"measures.start": {
"type": "long"
},
"measures.end": {
"type": "long"
}
}
}运行时字段优先于索引映射中用相同名称定义的字段。这种灵活性允许你隐藏现有字段并计算不同的值,而无需修改字段本身。如果你在索引映射中犯了错误,则可以使用运行时字段来计算在搜索请求期间覆盖映射中的值的值。
现在,你可以轻松地对 measures.start 和 measures.end 字段运行平均聚合:
GET my-index-000001/_search
{
"size": 0,
"aggs": {
"avg_start": {
"avg": {
"field": "measures.start"
}
},
"avg_end": {
"avg": {
"field": "measures.end"
}
}
}
}响应包括聚合结果,但不改变基础数据的值:

此外,你可以将运行时字段定义为计算值的搜索查询的一部分,然后在同一查询中对该字段运行统计聚合。
duration 运行时字段在索引映射中不存在,但我们仍然可以在该字段上进行搜索和聚合。以下查询返回持续时间字段的计算值,并运行统计聚合以计算从聚合文档中提取的数值的统计信息。
GET my-index-000001/_search
{
"size": 0,
"runtime_mappings": {
"duration": {
"type": "long",
"script": {
"source": """
emit(doc['measures.end'].value - doc['measures.start'].value);
"""
}
}
},
"aggs": {
"duration_stats": {
"stats": {
"field": "duration"
}
}
}
}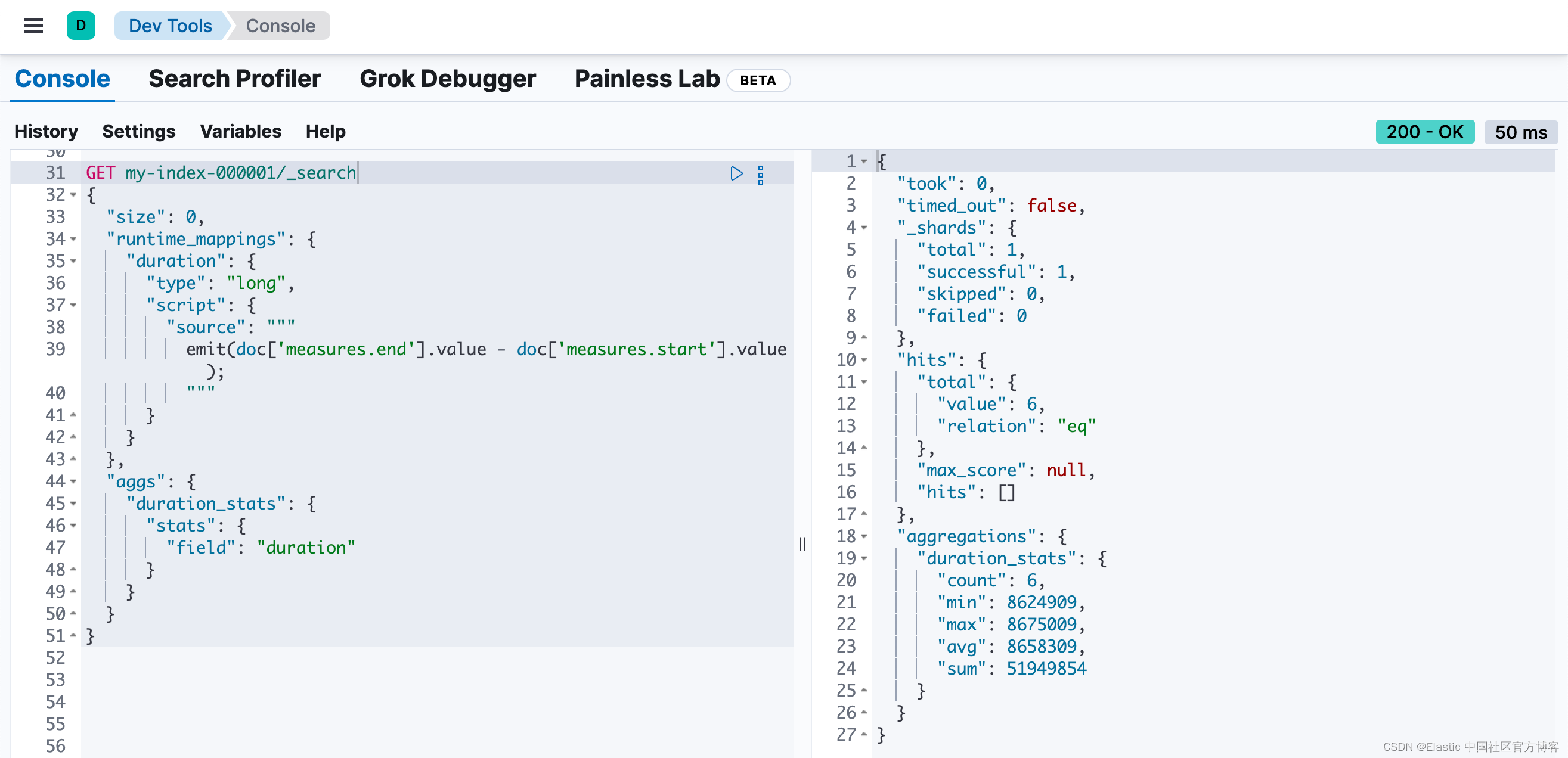
即使 duration 运行时字段仅存在于搜索查询的上下文中,你也可以搜索并聚合该字段。这种灵活性非常强大,使你能够在单个搜索请求中纠正索引映射中的错误并动态完成计算。