目录
HTTP1.1什么缺点
如何解决头部压缩
静态字典
动态字典
如何解决队头阻塞
Stream
排序
服务器主动推送资源
HTTP1.1什么缺点
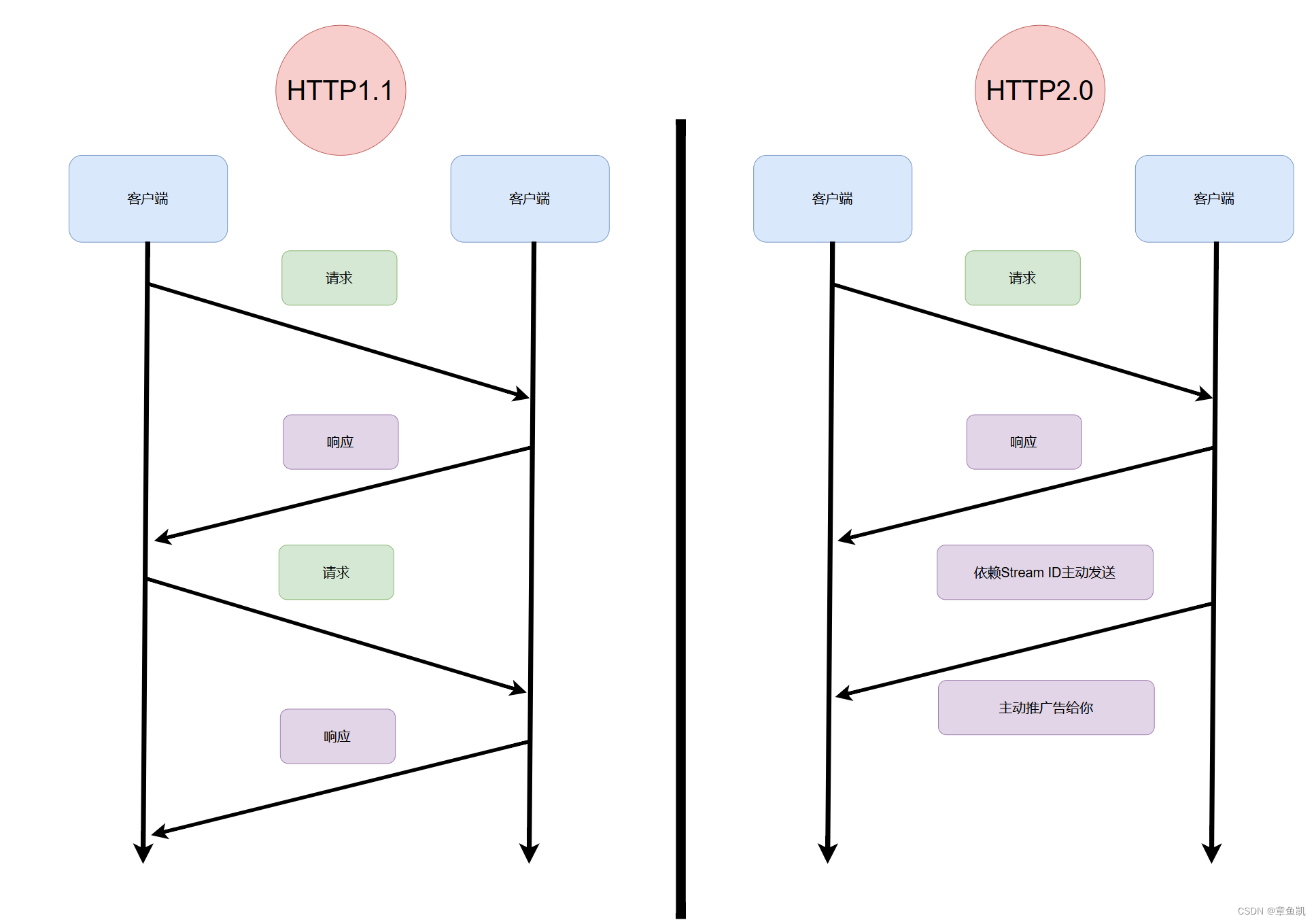
队头阻塞问题
同一连接只能在完成一个 HTTP 事务(请求和响应)后,才能处理下一个事务;(对于应用层http)
HTTP 头部巨大且重复
由于 HTTP 协议是无状态的,每一个请求都得携带 HTTP 头部,特别是对于有携带 Cookie 的部,而 Cookie 的大小通常很大;
不支持服务器推送消息
当客户端需要获取通知时,只能通过定时器不断地拉取消息,这无疑浪费大量了带宽和服务器资源
如何解决头部压缩
HTTP/1.1 报文中 Header 部分存在的问题:
含很多固定的字段,比如 Cookie、User Agent、Accept 等,这些字段加起来也高达几百字节甚至上千字节,所以有必要压缩;
大量的请求和响应的报文里有很多字段值都是重复的,这样会使得大量带宽被这些冗余的数据占用了,所以有必须要避免重复性;
字段是 ASCII 编码的,虽然易于人类观察,但效率低,所以有必要改成二进制编码;
HTTP/2开发了 HPACK 算法,HPACK 算法主要包含三个组成部分:
静态字典
动态字典
Huffman 编码(压缩算法)
静态字典
HTTP/2 为高频出现在头部的字符串和字段建立了一张静态表,它是写入到 HTTP/2 框架里的
不会变化的,静态表里共有 61 组
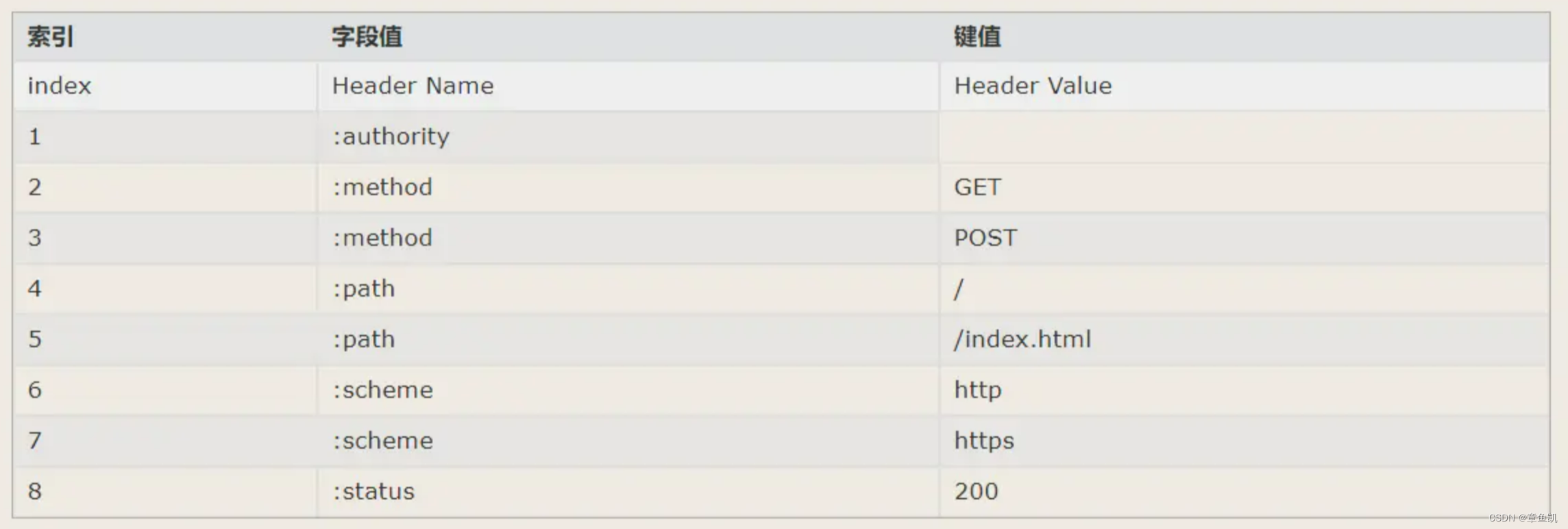
表中的 Index 表示索引(Key)
Header Value 表示索引对应的 Value
Header Name 表示字段的名字,比如 Index 为 2 代表 GET
Index 为 8 代表状态码 200。
动态字典
经过 Huffman 编码发送出去后,客户端和服务器双方都会更新自己的动态表,添加一个新的 Index 那么在下一次发送的时候,就不用重复发这个字段的数据了,只用发 1 个字节的 Index 号就好了,因为双方都可以根据自己的动态表获取到字段的数据。
比如有新的字段不在字典中,那么双方的动态字典就会为这个字典添加一个新的 Index
动态表生效有一个前提:必须同一个连接上,重复传输完全相同的 HTTP 头部。
问题:
1,他们的 Index如何同步的? 他们都是按顺序从静态字典的结束 62号开始 顺序生成
2,动态表越来越大怎么办?
如果占用了太多内存,是会影响服务器性能的,因此 Web 服务器都会提供类似 http2_max_requests 的配置,用于限制一个连接上能够传输的请求数量,避免动态表无限增大,请求数量到达上限后,就会关闭 HTTP/2 连接来释放内存。
Huffman 编码(压缩算法)不过多介绍,有兴趣可以自行了解
如何解决队头阻塞
队头阻塞的问题。
我们都知道 HTTP/1.1 的实现是基于请求-响应模型的。
同一个连接中,HTTP 完成一个事务才能处理下一个事务,也就是说在发出请求等待响应的过中,是没办法做其他事情的,如果响应迟迟不来,那么后续的请求是无法发送的
Stream
HTTP/2 通过 Stream 这个设计,多个 Stream 复用一条 TCP 连接,达到并发的效果,解决了 HTTP/1.1 队头阻塞的问题,提高了 HTTP 传输的吞吐量。
为了理解 HTTP/2 的并发是怎样实现的,我们先来理解 HTTP/2 中的 Stream、Message、Frame
整体如下
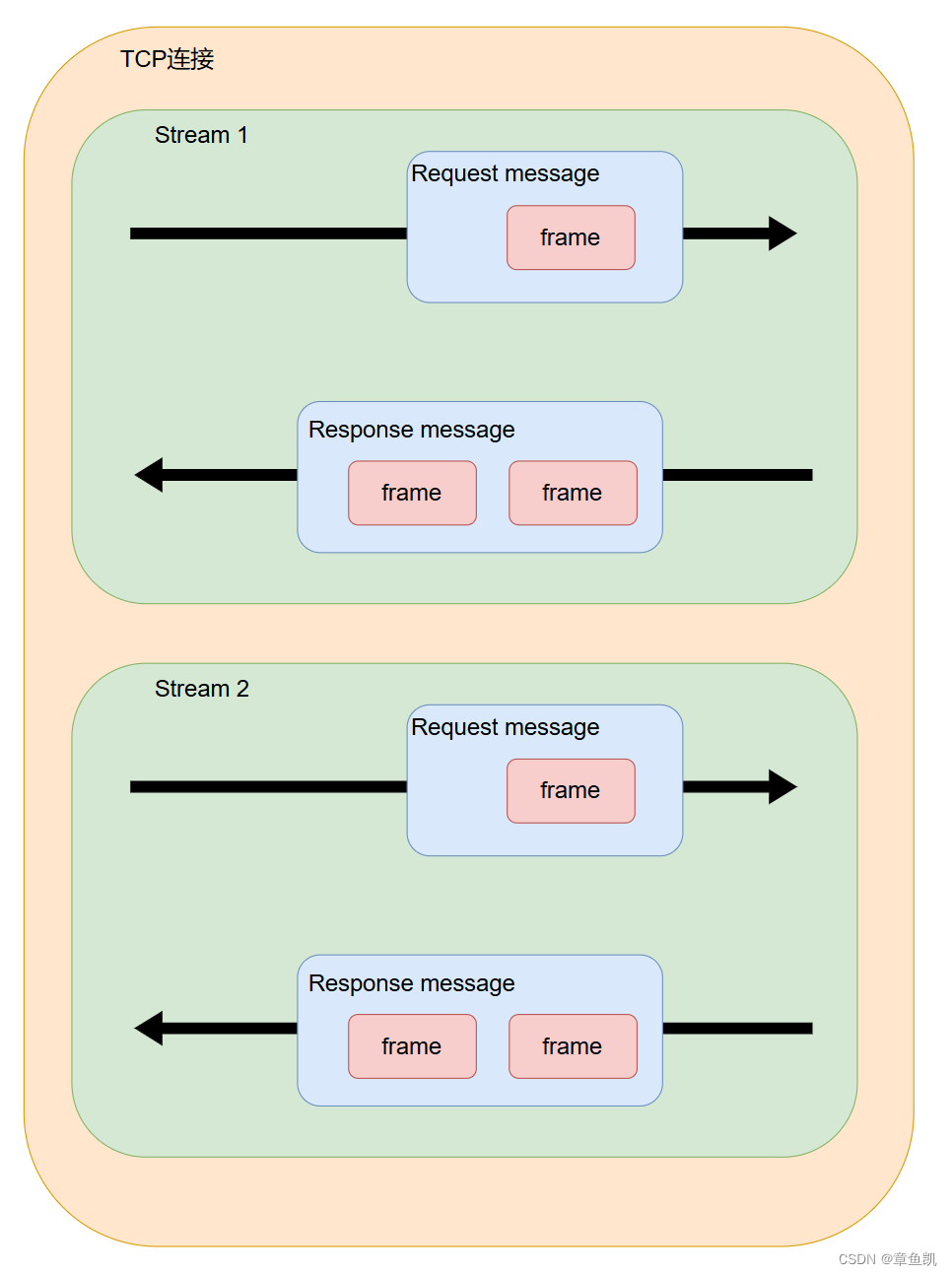
1 个 TCP 连接包含一个或者多个 Stream,Stream 是 HTTP/2 并发的关键技术;
Stream里可以包含1个或多个 Message,Message对应HTTP/1中的请求或响应;
Message 里包含一条或者多个 Frame,Frame 是 HTTP/2 最小单位,以二进制压缩格式存放内容;
排序
在 HTTP/2 连接上,不同 Stream 的帧是可以乱序发送的(因此可以并发不同的 Stream )
因为每个帧的头部会携带 Stream ID 信息,所以接收端可以通过 Stream ID 有序组装成
HTTP 消息,而同一 Stream 内部的帧必须是严格有序的。
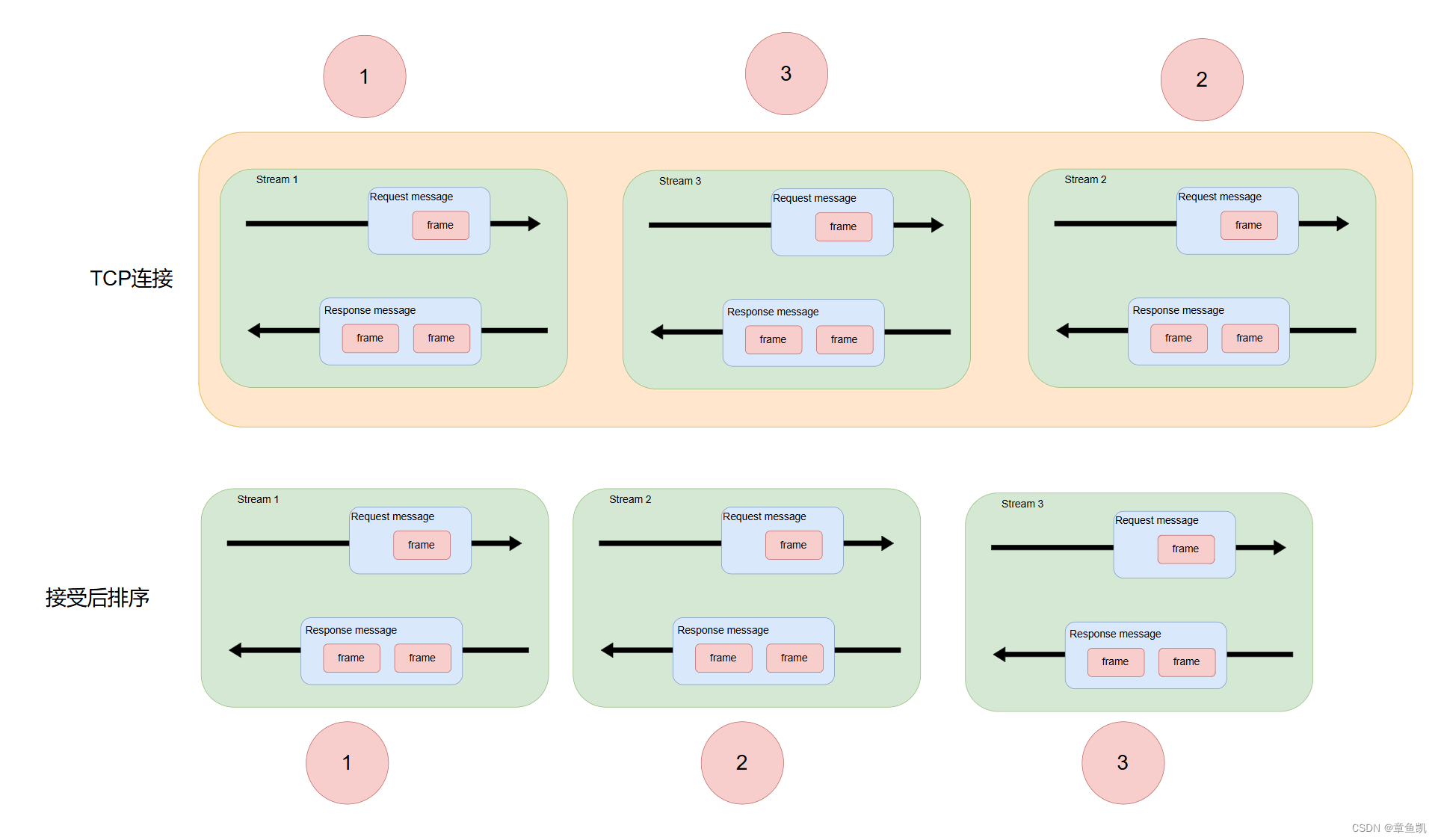
同一个连接中的 Stream ID 是不能复用的,只能顺序递增
所以当 Stream ID 耗尽时,需要发一个控制帧 GOAWAY,用来关闭 TCP 连接。
服务器主动推送资源
客户端和服务器双方都可以建立 Stream,因为服务端可以主动推送资源给客户端
客户端建立的 Stream 必须是奇数号,而服务器建立的 Stream 必须是偶数号
服务器在推送资源时,会通过 PUSH_PROMISE 帧传输 HTTP 头部,
并通过帧中的 Promised Stream ID 字段告知客户端,接下来会在哪个偶数号 Stream 中发送包体。


![[C++]——同步异步日志系统(1)](https://img-blog.csdnimg.cn/direct/aeb54ccef61d4748a73264d678e001fc.png)