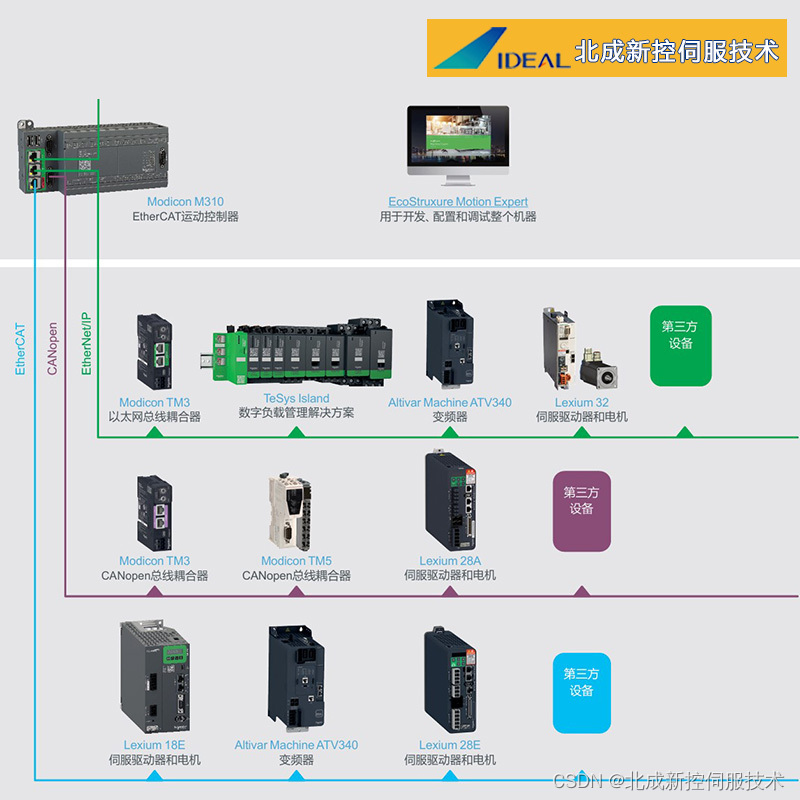
周末听了一场关于Open Search的技术分析,整理如下,供大家参考。OpenSearch,作为ElasticSearch的一个分支,不仅继承了其强大的搜索和分析能力,更在开源社区的驱动下,不断演进和创新。本文将介绍OpenSearch的最新进展,特别是其在语义检索技术方面的突破。
OpenSearch简介
OpenSearch是一个开源的搜索与分析套件,起源于ElasticSearch 7.10.2版本,坚持Apache-2.0开源协议,以开源优先和社区驱动为原则。OpenSearch项目不仅提供了强大的搜索功能,还包括了DataPrepper、Dashboard等组件,广泛应用于搜索、可观测性、安全分析、数据可视化和机器学习等领域。
向量搜索引擎从原始向量做写入、查询,OpenSearch做了很多运行速度、压缩量化方面的优化。到NeuralSearch语义搜索引擎,做的易用性升级,纯文本端到端的写入查询,做了其他的功能优化,比如Hybrid query.多模态、文本切分、rerank。现在:稀疏编码的语义搜索引擎,knn之外又多了一种选择,各自具备自己的优势,适配不同的应用场景
OpenSearch社区
OpenSearch的社区活跃度极高,拥有超过5亿的总下载量,版本更新频繁,合作伙伴和外部贡献者众多。在SlackWorkspace和OpenSearchForum上,有超过7000名成员参与讨论,月浏览量达到30万以上。这种活跃的社区氛围为OpenSearch的持续发展和创新提供了坚实的基础。
OpenSearch使用场景
OpenSearch平台的优势在于其检索功能的沉淀、分布式架构、安全性和数据分析能力。特别是k-NN索引的横向扩展能力,可以在集群中任意扩展数据节点,支持高达16K维度的向量,满足大规模数据集的搜索需求。
1.结合OpenSearch丰富的检索功能,与OpenSearch DSL结合完成复杂的查询过程
- a. 比如加入复杂的过滤条件;
- b. 与其他查询结合,e.g.BM25
2.基于OpenSearch分布式平台,高可靠性、高扩展性、高性能,平台确保分布式查询和写入 的负载均衡。
3.安全性:基于OpenSearch的安全插件,实现api级别鉴权,多用户访问控制,安全审计日志
4.数据分析:OpenSearch dashboards拥有丰富的数据可视化工具,数据进行可视化分析。dashboards上的搜索比较工具进行可视化的搜索效果比较,进行case
研究分析
使用场景:

OpenSearch向量数据库
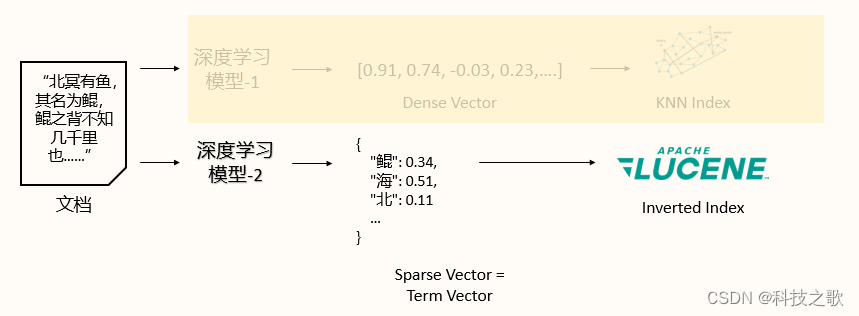
在深度学习时代,万物皆可Embedding,无论是图像、文本、视频还是音乐,都可以通过向量化的方式进行高效的索引和检索。OpenSearch通过k-NN插件,实现了向量引擎的适配,支持NMSLiB、Faiss、Lucene等多种向量库,以及HNSW和IVF等索引结构,为用户提供了强大的向量搜索能力。
k-NN插件
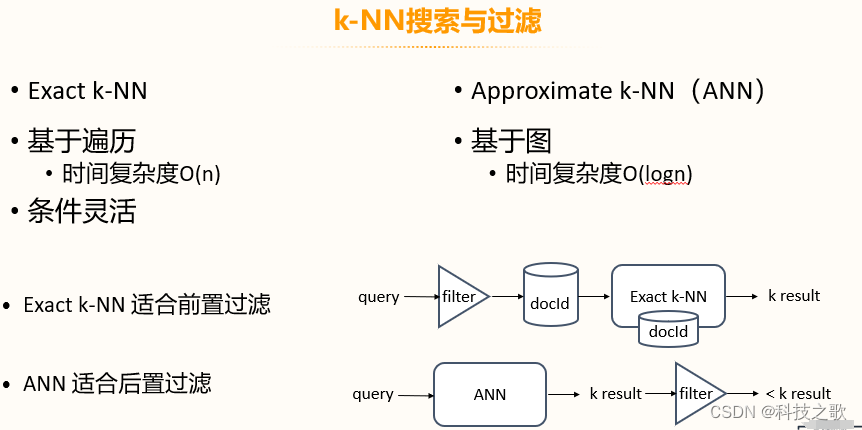
OpenSearch支持Exact k-NN和Approximate k-NN (ANN)搜索,以及基于遍历和基于图的过滤方式。Exact k-NN适合前置过滤,而ANN适合后置过滤。OpenSearch还能够在搜索时进行过滤,打通了Lucene、JNI和向量引擎,智能决定k-NN类型,权衡代价与精度。
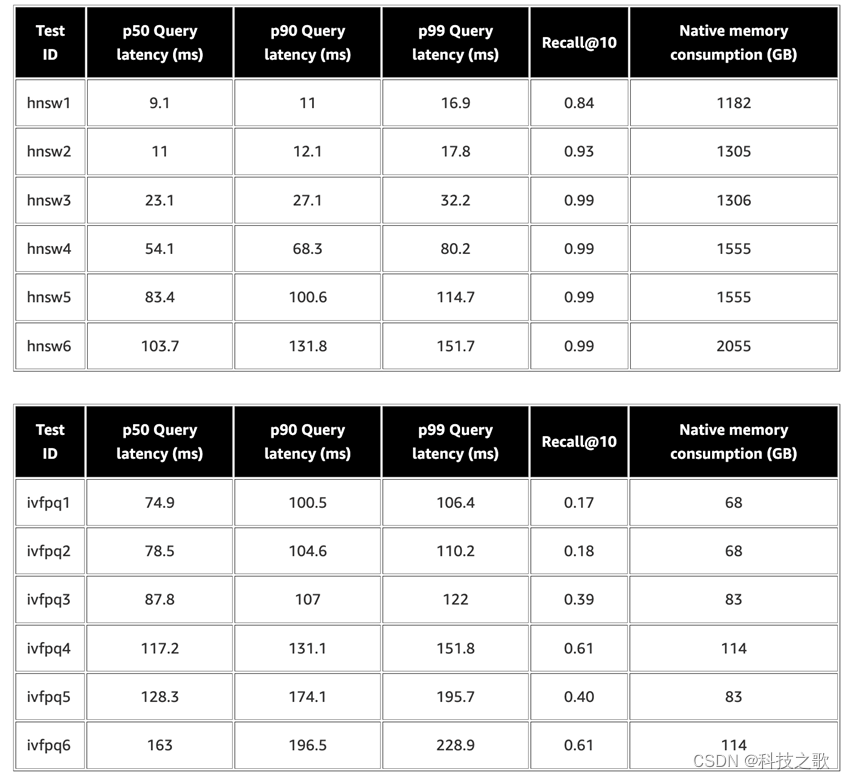
数据评测:性能与召回率的平衡
在1亿数据集的评测中,OpenSearch展现出了稳定支持10亿数据的能力,以及优秀的召回率和低延迟。例如,在r5.12xlarge实例上,p90查询延迟仅为16.9毫秒,召回率达到0.99。这表明OpenSearch在处理大规模数据集时,能够保持良好的性能和高准确度。
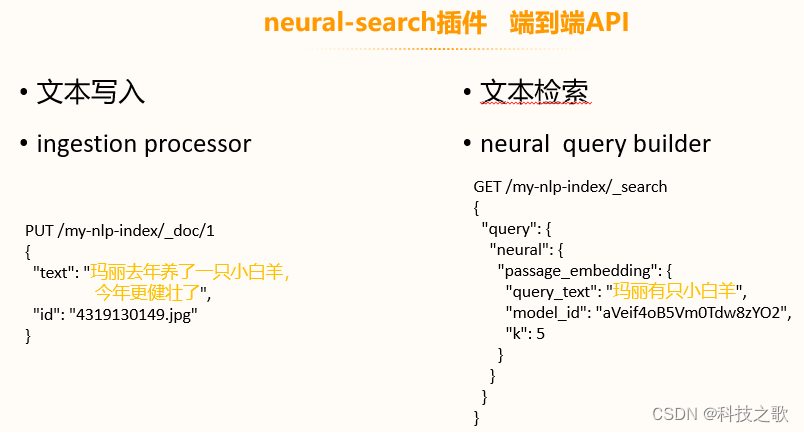
端到端的文本语义检索
对于期望实现语义检索的用户,OpenSearch提供了neural-search插件,这是一个端到端的API,支持文本写入和检索。通过ingestion processor和neural query builder,用户可以轻松实现文本的语义检索。
ml-commons插件:模型全流程托管
ml-commons插件为语义检索提供了强大的支持,实现了模型的全流程托管,包括一键部署、节点级部署、负载均衡和GPU支持。此外,它还支持远程连接到SageMaker、Bedrock、Cohere、OpenAI等服务,以及通过AgentFramework连接大模型,助力RAG。
OpenSearch提供了可视化查询比较工具,允许用户使用相同的搜索测试不同的查询,比较结果的差异。这有助于用户更好地理解不同查询方式的效果,优化搜索策略。
k-NN算法中的性能取舍
在k-NN算法中,性能和召回率往往需要权衡。例如,HNSW算法虽然召回率高达99%,但延时和内存占用相对较高;而IVF+PQ算法虽然召回率较低,但延时和内存占用更优。OpenSearch通过智能选择算法,帮助用户在性能和精度之间找到最佳平衡。

稀疏编码:鱼和熊掌兼得
稀疏编码(neural sparse)是一种既能保证高相关性,又能节省存储空间、保证速度的语义检索方法。通过深度学习模型,稀疏编码能够将文档和查询转换为稀疏向量,实现高效的语义匹配。
稀疏编码的鲁棒性
稀疏编码在真实数据服从训练数据分布时表现出色,模型能够使用稀疏准确的向量表征,产出精确的结果。即使在支持论据不足的情况下,稀疏编码也能保持较高的搜索相关性。
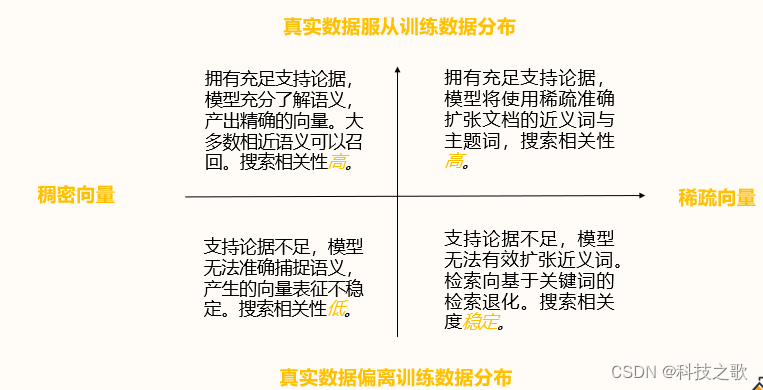
稀疏编码语义检索的计算方法
稀疏编码通过点积计算查询和文档之间的分数,结合权重和语义模型,实现高效的语义匹配。

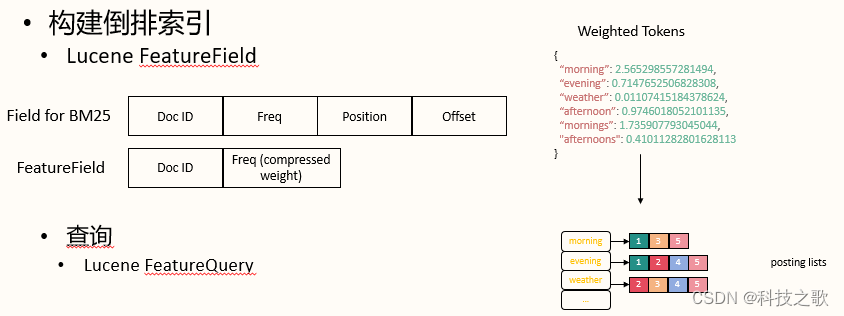
稀疏编码与Lucene的结合
OpenSearch将稀疏编码与Lucene结合,构建了倒排索引和FeatureField,实现了高效的检索。
Doc-only模式:极致速度
OpenSearch的Doc-only模式通过减少模型推理和索引遍历,实现了极致的搜索速度,同时保持了较高的搜索精度。

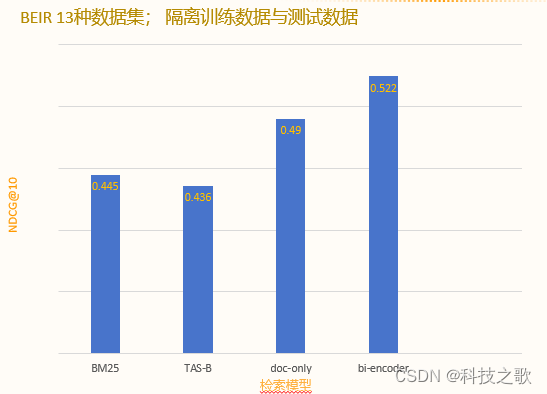
稀疏编码性能测试结果
OpenSearch的稀疏编码模型在性能测试中表现出色,无论是搜索精度还是速度,都远超传统的BM25模型。
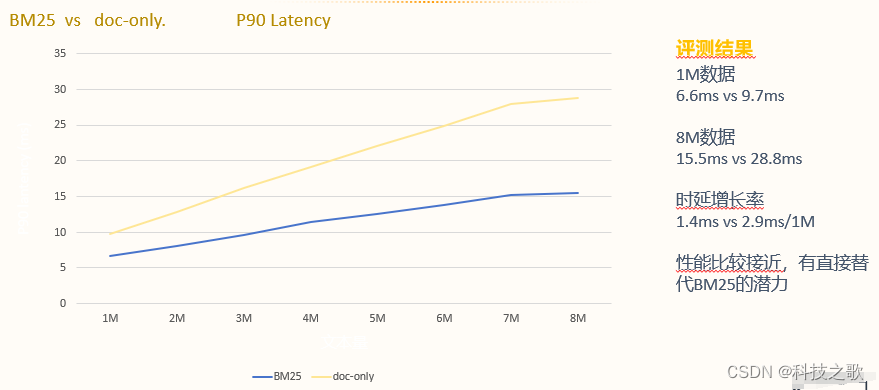
稀疏编码资源消耗
稀疏编码模型在资源消耗方面也具有优势,索引大小和峰值内存占用都远低于稠密索引模型。

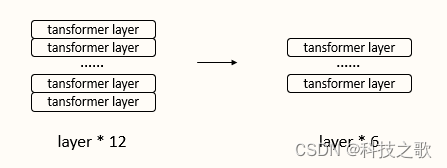
稀疏编码持续优化
OpenSearch团队持续优化稀疏编码模型,通过预训练和知识蒸馏,减小模型尺寸,提高搜索精度,降低ingestion代价。
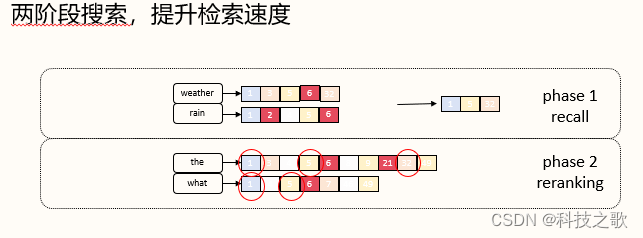
集成多路召回
OpenSearch还支持集成多路召回,通过BM25与k-NN的集成,以及更复杂的查询组合,进一步提升搜索精度。
结语
OpenSearch作为一个活跃的开源项目,其在语义检索技术方面的创新和优化,提供了一个高效、准确、可扩展的搜索平台。