C++是在C的基础之上,容纳进去了面向对象编程思想,并增加了许多有用的库,以及编程范式 等。熟悉C语言之后,对C++学习有一定的帮助,本篇博客主要目标: 1. 补充C语言语法的不足,以及C++是如何对C语言设计不合理的地方进行优化的,比如:作用域方面、IO方面、函数方面、指针方面、宏方面等。 2. 为后续类和对象学习打基础。
目录
一、C++的初始化
二、 C++的输入和输出
2.1 正式介绍
2.2 字符串的输出
2.3 字符串的输入
2.4 总结
三、const关键字(重点)
3.1 const变量
3.2 const与指针的关系
3.3 常变量与指针
3.4 指针的兼容规程
四、引用/别名(重点)
4.0 复习两个运算符
4.1 引用的概念
4.2 引用的特点
4.2.1 总结引用的特点
4.2.2 C++11相关概念:左值、右值、将亡值
4.2.3 引用的分类
4.2.4 总结
4.3 const引用(常引用)
4.3.1 总结
4.4 使用场景
4.4.1 引用作为形参替代指针
4.5 其他引用形式
4.5.1 数组的引用(数组的别名)
4.5.2 指针的引用(指针的别名)
4.5.3 练习题
4.6 指针与引用的区别(面试)
4.7 引用作为函数的返回值类型
4.8 传值、传引用效率比较
一、C++的初始化
C++是在C语言的基础之上发展过来的,但是C++的初始化方式相比于C语言出现更多的形式,如下代码所示:
#include <iostream> //C++标准输入输出流
using namespace std; //命名空间
struct Student
{
char s_id[20];
char s_name[20];
int s_age;
};
int main()
{
//1、C++初始化方式
int a = 10; //等号 = 赋值初始化
int b(20); //圆括号 () 初始化
int* p(NULL);
int* s(&a);
//数组和结构体用花括号进行初始化
int arr[] = { 1,2,3,4,5};
Student s1 = { "2024001","张三",12 };
return 0;
}
可以看到:上述初始化方式一共有3种,等号赋值、圆括号、花括号,那么为了方便使用C++有没有一种统一化的初始化方案,答案是有的,C++11提出了统一的初始化方案,如下:
#include <iostream> //C++标准输入输出流
using namespace std; //命名空间
int main()
{
//1、C++初始化方案/统一初始化
int a{ 10 };
int* p{ &a };
double dx{ 12.25 };
char ch{}; /*未初始化,默认给'\0'值*/
int b{}; /*未初始化,默认给0值*/
int arr[]{ 1,2,3,4,5 };
int brr[] = { 1,2,3,4,5 };
Student s1{ "2024001","张三",12 };
Student s1 = { "2024002","张三",12 };
return 0;
}注意: 花括号相比等号赋值初始化,它具有更强的类型限制!如下:
//花括号相比等号赋值初始化,它具有更强的类型限制!
int a=10 ;
int b=12.25; //等号赋值会进行隐式的强制转换,数据截断将12赋值给b;编译器不会报错。
int a{10} ;
int b{12.25}; //花括号赋值,编译器会报错!不会通过!!!
总结:
C++11标准中对变量初始化进行了统一规定:无论是什么数据类型(基本数据类型还是构造数据类型),直接在变量名后面跟上花括号,初始化值填在花括号内部, 逗号分隔,如果不填初始值就是类型对应的默认值,即:花括号可以初始化任意类型的数据!这样更加方便,并且它可以区分是函数声明和变量定义。
二、 C++的输入和输出
2.1 正式介绍
在学习C++的输入和输出之前,我们简单复习与输入输出相关的知识点,扩充知识体系。学习过C语言,我们知道,要进行输入和输出,需要引入标准头文件:#include <stdio.h>,因为里面有三个标准设备:标准输入流:stdin、标准输出流:stdout、标准错误流:stderr,与此C++进行输入输出,需要引入标准头文件: #include <iostream>和使用对应的命名空间using namespace std;
注意:
早期标准库将所有功能在全局域中实现,声明在.h后缀的头文件中,使用时只需包含对应头文件即可,后来将其实现在std命名空间下,为了和C头文件区分,也为了正确使用命名空间, 规定C++头文件不带.h;旧编译器(vc 6.0)中还支持格式,后续编译器已不支持,因此推荐使用 #include <iostream>+std的方式。当然,也可以在.cpp文件中引入C语言的库,如:#include <cstdio>。它里面也有相应的标准设备与C语言对应,如下:
- 输入流设备:键盘 cin ==>stdin : 带有缓冲区buffer
- 输出流设备:屏幕cout ==>stdout :带有缓冲区buffer
- 输出流设备:屏幕cerr ==>stderr : 不带缓冲区buffer,直接刷新到屏幕,打印错误信息。
- 输出流设备:屏幕clog ==>stdout : 带有缓冲区buffer,打印的是日志信息。
缓冲区:
在我们输出时,首先将数据放到缓冲区buffer,然后遇到\n,才会将缓冲区数据刷新到屏幕显示!可以将缓冲区理解为暂时存放数据的一块内存空间!
C语言的输入和输出
#include <stdio.h>
int main()
{
int a{};
char ch{};
scanf("%d%c", &a, &ch); //C语言中,数据类型发生变化,scanf和printf的格式控制符也要跟着发生变化,
printf("a=%d ch=%c\n", a, ch);
return 0;
}#include <iostream>
using namespace std; //命名空间
int main()
{
int a{};
char ch{};
cin >> a >> ch; //可以自动识别变量的类型
cout << a << " " << ch << endl; //可以自动识别变量的类型
return 0;
}注意:
- 两个大于号:>>是提取符,它是从标准输入设备键盘提取数据给a和ch, cin >> a, ch; 这样的写法不可以!!每个变量数据之前必须有一个提取符或者插入符!
- 两个小于号:<<是插入符,它是将a的数据值插入到屏幕显示,endl等同于C语言中的\n,即:换行。
可以看出:C++中,数据类型发生变化,cin和cout的代码语句不用发生变化。
2.2 字符串的输出
无论是cout还是printf,输出字符串的时候,都是以'\0'作为字符串输出结束标志!,因此字符串必须要带上'\0'。否则,会出现问题。
#include <iostream>
using namespace std; //命名空间
int main()
{
const int len = 128;
char str[len]{};
cin >> str;
cout << str << endl;
printf("%s\n", str);
return 0;
}2.3 字符串的输入
#include <iostream>
using namespace std; //命名空间
int main()
{
const int len = 128;
char str[len];
cin >> str;
cout << str<<endl;
cin.getline(str, len);
cout << str<<endl;
cin.getline(str, len,'#');
cout << str << endl;
return 0;
}
- cin和scanf输入字符串默认都是以空格作为字符串输入的结束符,如果一个字符串有空格,那么空格后的字符串将不会获取到。
- cout和prntf输出默认都是以'\0'作为字符串输出结束符;
- cin.getline方法可以从键盘输入字符串,默认是以回车'\n'作为结束符,它就可以接收含有空格的字符串。它也可以修改字符串输入结束符,这里以'#'作为结束符作为展示,#不会存储到字符串中!
2.4 总结
使用cout标准输出对象(控制台)和cin标准输入对象(键盘)时,必须包含< iostream >头文件 以及按命名空间使用方法使用std。 其中,cout和cin是全局的流对象,endl是特殊的C++符号,表示换行输出,他们都包含在包含< iostream >头文件中,>>是流提取运算符,<<是流插入运算符,使用C++输入输出更方便,不需要像printf/scanf输入输出时那样,需要手动控制格式。 C++的输入输出可以自动识别变量类型。注意,我们在输入和输出字符串时,其实和C语言是一样的,但是在输入字符串时,C++有特殊的处理方式!
三、const关键字(重点)
const、指针、引用这三个概念在C++中非常重要,必须要搞明白!我们在学习过程中要明白:站在编译器的角度思考编译通过和不通过的原因,这样就明白了编译器是怎么编译的,达到明白原理,这样才不会被繁杂灵活多变的语法规则弄糊涂,理解加记忆,这样才会学的清楚,学明白。
3.1 const变量
这一小节,我们主要学习:const变量在C和C++中的区别。在VS编译器中,以.c后缀结尾的文件,它是以C语言的方式进行编译链接, 以.cpp后缀结尾的文件,以C++的方式进行编译链接。
//.c文件
#include <stdio.h>
int main()
{
const int n = 10; 注意:const修饰的常变量,因为不能在修改,一开始必须初始化
int arr[n] = { 1,2,3 };
return 0;
}我们知道:C语言中的常变量不可以用来作为定义数组的大小,因此,这里是以c语言的方式编译,不会通过!这其实是因为:C语言中,以变量为主,因此这个常变量在编译链接时被当作是变量,在编译阶段,它会去所在的内存空间地址取值!(它是一个左值)
#include <iostream>
using namespace std; //命名空间
//.cpp文件
int main()
{
const int n = 10;
int arr[n] = { 1,2,3 };
return 0;
}C++中,以常量为主,因此这个常变量在编译链接时被当作是常量,这是因为n是常变量,编译阶段直接进行替换成10,所以编译会通过! 因此,以c++的方式编译,可以通过!C++中常变量可以用来作为定义数组的大小!
练习题:
#include <iostream>
using namespace std; //命名空间
//.cpp文件
int main()
{
const int a = 10;
int b = 0;
int* ip = &a;
int* ip = (int *)&a;
*ip = 100;
b = a;
printf("a=%d b=%d *ip=%d\n", a, b, *ip);
return 0;
}注意:这里的打印结果是:10 10 100 而不是:100 100 100
分析:
- 第一行:const修饰的变量表示此变量只可读,不可修改,所以叫做常变量!定义的时候必须初始化
- 第三行: 编译无法通过!因为后面可以通过指针解引用修改a的值:*ip=20;,但是上面经过const限定此变量无法修改!矛盾了!
- 第四行:通过强制转换使得编译通过,注意:这里可不是替换,这里就是取地址,取得仍然是a的地址!
- 第五行:通过解引用将a所在内存空间的值修改为100
- 第六行:在编译阶段直接替换a的值10给b,b等于10,注意可不是100赋值给b!!!
- 第七行:输出结果是10(编译阶段直接替换) 10 100,但是:在内存中a是100, b是10, *ip是100。
通过这个例子:可以深刻的理解:const修饰的常变量它是在编译阶段直接进行替换!
总结:(根据汇编代码可以看出来)
C++中凡是const修饰的常整型变量,是在编译的阶段,编译器直接将常整型变量进行替换 ,因此解引用也不会修改变量本身,但是内存中的值会发生变化!!!但是在C语言中,常变量会从内存地址空间取值,因此,指针解引用会修改变量本身 , 打印的值是:100 100 100
3.2 const与指针的关系
对于一个指针有两个属性,一个是指针指向的数据,一个是指针本身(指针的指向),因此,const可以修饰的指针变量就会有三种情况:
- const放在*的左边,修饰的是指针指向的数据,也就是指针指向的变量是常变量,不可以通过指针解引用修改该变量!
- const放在*的右边,修饰的是指针本身, 也就是说不可以修改指针的指向!
- const既放在*的左边,又放在*的右边,那么,它既修饰指针指向的数据,又修饰指针变量本身!!
#include <iostream>
using namespace std; //命名空间
int main()
{
int a = 10, b = 20;
int* p1 = &a;
*p1 = 100;
p1 = &b;
const int* p2 = &a;
*p2 = 100; //编译无法通过!const放在*的左边,修饰指针指向的数据变量,无法通过解引用修改变量
p2 = &b; //编译可以通过!指针本身的指向可以发生改变!
int const* p3 = &a; //const放在类型的左边和右边都是一样的,与p2没有区别
int *const p4 = &a;
*p4 = 100; //编译可以通过,const放在*的右边,修饰的是指针本身,也就是说不可以修改指针的指向,但是可以通过解引用修改变量!
p4 = &b; //编译无法通过!const放在*的右边,修饰的是指针本身,也就是说不可以修改指针的指向!!!
const int* const p5 = &a; //const既放在*的左边又放在*的右边,修饰指针指向的数据,也就是指针指向的变量是常变量,不可以通过指针解引用修改它!
//修饰指针本身,也就是说不可以修改指针的指向!也就是说:此时是双重限定!!!
*p5 = 100; //编译无法通过!
p5 = &b; //编译无法通过!
return 0;
}3.3 常变量与指针
#include <iostream>
using namespace std; //命名空间
int main()
{
const int a = 10; //常变量:表示a无法修改!!!
int* p1 = &a; //编译无法通过,指针未有任何修饰,可以通过*p1=100;解引用修改a的值!!
const int* p2 = &a; //编译可以通过,const放在*的左边,修饰的是指针指向的数据,也就是指针指向的变量是常变量,不可以通过指针解引用修改它,也就是*p2=100;不可以,符合a的定义!
int* const p3 = &a; //编译无法通过,const放在*的右边,修饰的是指针本身也就是说不可以修改指针的指向!但是可以通过指针解引用修改a,*p3=100,与a的定义矛盾。
const int* const p4 = &a; //双重限定可以通过,没有办法通过解引用修改a的值,*p4=100;会通过,符合a常变量的定义!
int* p5 = (int*)&a; //编译可以通过,但是不安全,此时可以解引用修改a,指针进行了强转!
return 0;
}总结:
- const修饰的变量称之为常变量,代表的是该变量只可以读取,但是不能修改!凡是可以通过指针修改解引用修改该变量的,都没有办法编译通过!这就是编译器的原则!否则与常变量的定义发生矛盾!!
- 常变量只能拿常性指针指向!!!只有这样才不会通过指针解引用修改常变量的值。
- 全局变量未初始化默认用0做初始化,局部变量未初始化则是随机值!只要是基本数据类型,不论是全局变量还是局部变量,只要拿const修饰,都必须要进行初始化!!如果不初始化,编译器会报错!!但是如果是构造类型,比如结构体,const修饰的全局结构体变量会用0做初始化,但是const修饰的局部结构体变量是随机值!!
- int* const sp; 这样的常性指针,定义的时候也必须要进行初始化 int* const sp=&a;否则编译器同样会报错!
3.4 指针的兼容规程
指针的兼容规程通常指的是在C和C++编程语言中关于不同类型指针之间的兼容性规则。这些规则规定了哪些类型的指针可以相互转换,以及在进行这种转换时需要注意的事项。这些规则的目的是为了确保程序的安全性和可移植性,避免因不兼容的指针操作引起未定义行为或潜在的错误。通过下面三个例子进行理解:
示例一:
#include <iostream>
using namespace std; //命名空间
int main()
{
int a = 10,b = 20;
int *p = &a; //p是普通的指针,指针的类型是:int *
int *s1= p; //编译可以通过,两个指针的类型相同
const int *s2= p; //编译可以通过,指针s2的类型是:const int * ,指针能力被收缩
int *const s3 = p;//编译可以通过,指针s3的类型是: int * const,指针能力被收缩
const int *const s4 = p; //编译可以通过,指针s4的类型是:const int * const,指针能力被收缩
return 0;
}
总结:
能力强的指针赋值给能力收缩的指针,这些都是可以通过的!!(一个指针赋值给另外一个指针,不能出现指针能力的扩张!!!!)
示例二:
#include <iostream>
using namespace std; //命名空间
int main()
{
int a = 10, b = 20;
const int* p = &a; //常性指针,代表不可通过指针解引用修改a的值!指针的类型就是:const int *
int* s1 = p; //编译无法通过! 这里s1没有限定,因此s1可以指向a,还可以通过指针解引用修改a的值,*s1=100;这两个指针之间赋值,指针的能力被扩张了,编译器是不允许的!
const int* s2 = p; //编译可以通过!指针的能力相同,都是const int *,并且都不可以通过解引用修改a
int* const s3 = p; //编译无法通过!s3的const放在*的右边,修饰指针本身,但可以通过解引用修改变量a,*s3=100,但是本来的指针p是不可以的,这样的指针互相赋值,导致指针的能力被扩张,编译器是不允许的!
const int* const s4 = p; //编译可以通过!双重限定!指针的能力被缩小,这是编译器允许的!
return 0;
}
示例三:
#include <iostream>
using namespace std; //命名空间
int main()
{
int a = 10, b = 20;
int* const p = &a; //p修改指针本身,p的指向不能发生变化。即p=&b;是错误的!但*p=100是可以的!指针的类型是:int * const
int* s1 = p; //编译可以通过,s1未进行限定,*s1 =100或者 s1=&b都是可以通过的, 但是s1=&b,不会修改p的指向,即s1指向的改变不会改变p的指向的改变,这是可以通过的!
const int* s2 = p; //编译可以通过,s2限定的是指针指向的数据,*s2=100不可以,但是s2=&b;是可以的,但是不会修改p的指向,即s1指向的改变不会改变p的指向的改变,这是可以通过的!
int* const s3 = p; //可以通过,s3限定的是指针本身,s3=&b是不可以的,原来的p也是不可以修改指向的,s3修改不修改指针的指向与p无关,即s1指向的改变不会改变p的指向的改变,这是可以通过的!
const int* const s4 = p; //可以通过,s4是双重限定,*s4=100;s4=&b都是不可以的,原来的p也是不可以修改指向的,s3修改不修改指针的指向与p无关,即s1指向的改变不会改变p的指向的改变,这是可以通过的!
return 0;
}
虽然原来的指针p被修饰自身了(p的指向不能发生变化),但是,其他指针的指向发生变化与否与p的指向无关,二者没有必然联系,指针的能力也就没有扩张一说,因此,这些都是可以编译通过的!!!对于两个指针之间的赋值,约束强的指针可以约束能力弱能力强的指针可以赋值给能力收缩的指针,但是不能出现指针能力的扩张! const修饰的指针本身可以赋值给任意类型的指针(const的位置随便加)
四、引用/别名(重点)
4.0 复习两个运算符
*和&这两个运算符在C++中运用非常广泛,并且它们在不同的场景下,有着不同的使用方法,如下所示:
#include <iostream>
using namespace std; //命名空间
int main()
{
int a=10,b=20;
c = a * b; // 这里是乘法运算符
int* p = &a; //这里的*是定义指针变量类型符,这里的p的类型是:int *
*p = 100; //这里的*是解引用操作符
return 0;
}
#include <iostream>
using namespace std; //命名空间
int main()
{
int a=10,b=20;
int c=a & b //这里的&是位运算符
int *p=&a; //这里的&是取地址符
int& ra =a //这里的&是引用符,ra的类型是:int & (整型引用)
return 0;
}4.1 引用的概念
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。 比如:李逵,在家称为"铁牛",江湖上人称"黑旋风"。
如何定义:
类型& 引用变量名(对象名) = 引用实体;
这就是引用变量的定义,&和类型结合称之为引用符号,这里就不是取地址的意思!而是别名。
注意一点:引用变量的类型必须和引用实体是同种类型的!!!
分析如下代码:
#include <iostream>
using namespace std; //命名空间
int main()
{
int a = 10;
int b = a;
int &ra = a; //引用:别名,也就是同一个实体有两个名字,它们占用同一块内存空间,a的类型是:int 但是ra的类型是:int &(整型引用)
a = 100;
ra = 200; //程序走到这里,a和ra等价的,都是200!
int* ip = &a;
int* sp = &ra; //取ra的地址就是取a的地址,同一块内存空间,只是一个别名,ip和sp指向同一块内存空间,因此他们的值也是相同的!
printf("%p\n", &a); //这两个打印出来的地址都是相同的,因为他们是同一块内存空间,地址编号应相同
printf("%p\n", &ra);
return 0;
}在内存中如下图所示 :

总结:
引用就是别名,也就是同一个实体有两个名字, 它们占用同一块内存空间,不论是修改变量本身还是修改变量的引用都是修改这块内存空间!因此,我们要知道,修改一个变量有两种方式:一种是通过变量本身修改,另外一种是通过变量的引用来修改此变量!!
4.2 引用的特点
为深入理解引用的特点,请按下面的例子:
#include <iostream>
using namespace std; //命名空间
int main()
{
int a = 10;
int &ra; //这是不允许的,定义引用的时候必须要进行初始化,没有空引用,起别名必须要存在对应的实体!
int &ra = NULL; //这也是不允许的,没有空引用
int &&rb = ra; //这也是不允许的,没有引用的引用,所谓的二级引用,注意:引用无等级之分,它只是别名!它不像指针有二级指针
return 0;
}
- 引用在定义的时侯必须初始化为某个对象实体!
- 引用不可以为空,也就是必须要有实体,即没有空引用
- 引用没有等级之分,即没有引用的引用,不像指针有二级指针,三级指针....
如何理解第三条?请看下面代码:
分析:为什么没有二级引用: 反证法:如果二级引用成立: int main() { int a = 10; int &ra= a; int &&rb=ra; } 引用的含义:a==>ra ra==>a ,a和ra等价, 因此:int &&rb =ra <==> int &rb =a;应当也成立, 那么左边就会出现两个式子:int &&rb和int &rb,明显不正确,编译器肯定不知道哪个是对的, 不符合,因此,原假设不成立,也就是没有二级引用之说!
再看下面的例子,进行理解引用:
#include <iostream>
using namespace std; //命名空间
int main()
{
int a = 10,b=20;
int &ra = a;
int &ra = b; //这里是错误的!引用一旦引用一个实体,再不能引用其他实体
int &rb = ra; //这里其实和int &rb = a; 等价,ra就是a,a就是ra;
int &rc = ra; //a这个实体有3个别名:ra、rb、rc 这都是左值引用(一个&号),所以修改a就会有四种方式,通过变量本身或者引用变量
int &&r = 10; //扩充:这里可不是二级引用,这里是右值引用(两个&&符号)
/*注意如下:
右值引用的编译规则:
int tmp =10;
int &r =tmp;
*/
r = r+100; //注意:这里对r的改变,是对临时量tmp的改变,而不是对10改变,10是字面常量,不可以修改!
return 0;
}
- 引用一旦引用一个实体,再不能引用其他实体;
- 一个变量可以有多个引用;
- 对于右值引用,必须引用的是右值(不可以取地址)
4.2.1 总结引用的特点
- 引用在定义的时侯必须初始化为某个对象实体!
- 引用不可以为空,也就是必须要有实体,即没有空引用
- 引用没有等级之分,即没有引用的引用,不像指针有二级指针,三级指针....
- 引用一旦引用一个实体,再不能引用其他实体;
- 一个变量可以有多个引用;
- 对于右值引用,必须引用的是右值(不可以取地址)
4.2.2 C++11相关概念:左值、右值、将亡值
- 左值:凡是可以取地址的,如&a,这里的a就是左值,变量;
- 右值:不可以取地址的, 如&10,这里的10就是右值,字面常量;
- 将亡值:表达式计算过程(c=a+b)或者函数调用的过程中产生的临时量,表达式计算完,这个值就不存在了(亡值)。
记住:凡是由内置类型(char、int...)在计算过程中产生的将亡值都具有常性(const)!!!(可读不可修改,a+b=c,左边计算完后是亡值,它是常性,不可修改)
因此不可将变量赋值给表达式,是因为表达式计算的值是将亡值,它具有常性,不可修改!!!
4.2.3 引用的分类
在C语言中定义变量 ,只关注变量的类型,int a = 10; 从变量类型看:这是整型变量 ,而在C++11中,会从两个方面看:值类型和值类别,从值类别看,a是左值(可以取地址&a),10是右值(常量不可以取地址)。const int b = 20; 从变量类型看:这是常整型变量 ,C++11中,从值类别看,b是左值(可以取地址&b),20是右值(常量不可以取地址)。
其实还有一种值类别,叫做:将亡值,表达式计算过程(a=10,b=20,c=a+b理解:a+b计算会产生一个临时变量30)或者函数调用的过程中产生的临时量,表达式计算完,这个值就不存在了(亡值)。
因此,根根据变量本身是左值还是右值,就会有相应的左值引用和右值引用。等号右边是一个左值(可以取地址),那么左边就要用左值引用引用(一个&符号)它,等号右边是一个右值(不可以取地址),那么左边就要用右值引用(两个&&符号)引用它,记住:将亡值可以初始化左值引用也可以初始化右值引用,将亡值在不具有名字的时候,它是右值,具备名字的时候,他就是左值!因此,将亡值归为左值还是右值,取决于它是否有名字!!有可能是左值也有可能是右值,右值的最基本概念就是没有名字!!!
int a = 10;
int &ra = a; //这是a的普通左值引用
const int &cra = a; //这是a的常性左值引用,可以引用a,但是不可以通过引用修改a
int &&rra = a; //这是错误的,两个&&代表它是一个右值引用,它只能引用一个右值(没有办法取地址的),而a是左值(可以取地址&a)
int &&rra = 10; //这是正确的,两个&&代表它是一个右值引用,它只能引用一个右值(没有办法取地址的),而10是右值(不可以取地址&10)4.2.4 总结
C++11根据值类别,将引用分为:左值引用(只能引用一个左值)和右值引用(只能引用一个右值)
- 左值引用就是一个&符号,右值引用就是两个&&号,对应等号右边就放相应的左值(可以取地址)和右值(不可以取地址)
- 不论是左值引用还是右值引用,它本身就是一个别名!只是对应的值类别不同而已!
- 一个&代表它是左值引用,它只能引用一个左值(可以取地址的)
- 两个&&代表它是右值引用,它只能引用一个右值(不可以取地址)
4.3 const引用(常引用)
const引用也被称之为万能引用,后面学习完,你也应该就能明白这个万能的含义,通过前面的学习,我们前面知道修改一个变量有两种方式:一种是直接修改变量,一种是通过变量的引用来修改变量,同时引用的底层其实是通过指针实现的,我们就可以把const修饰引用引用理解成const和指针的关系,但是,可没有:int & const ra=a; 这么一说,&必须与变量名结合才可以代表引用!!!这样方便我们理解,这样就有了常引用的这个概念。
请看如下代码:
#include <iostream>
using namespace std; //命名空间
int main()
{
int a = 10; //整型变量
const int b = 20; //常整型变量
int &ra = a; //这是正确的,a的引用(别名),通过ra可以修改a的值,对ra的改变就是对a的改变,ra=100等价于a=100;;
const int &cra = a; //这是正确的,a的引用(别名),但他是常性左值引用,可以引用a,可以读取a,但是不可以通过引用修改a,即cra=100;
cout << cra << endl; //打印的就是a 10
ra += 100; //通过ra将a修改为110
cout << cra << endl; //打印的是修改后的110
a += 100; //a自身修改为210
cout << cra << endl; //打印的是修改后的210
cra+=10; //这里编译无法通过,常引用不可以修改a!
return 0;
}直接修改a和通过普通的引用ra都可以修改a, 但是,cra是常性引用,可以读取a, 但是不可以通过引用修改a,任何对a的修改(无论是a自身修改还是通过引用修改),它都可以读取到!
const 修饰引用,表示它是常性引用,可以引用变量(作为变量的别名),它可以读取该变量, 但是不可以通过引用修改该变量; 对于普通的变量,既可以用普通引用引用他,又可以用常性引用引用它,区别只在于常性引用不可以修改变量!
再看如下代码:
#include <iostream>
using namespace std; //命名空间
int main()
{
const int b = 20; //这是常变量
int &rb = b; //这是错误的,因为b被限定是常变量,不可以修改它,这里的引用是普通引用,可以引用b,并且可以通过引用修改b即rb+=100(等价于b+=100;);与定义矛盾,!!
const int &crb = b; //这是正确的,它是常性引用,可以引用b,但是不可以通过引用修改b,这与定义符合!!
}对于常变量,就只能用常引用来引用该变量,因为常变量不可以被修改,加了限制,我们的引用也应该加限制!!!
4.3.1 总结
总结:
1、普通变量可以初始化为普通引用,也可以初始化为常引用,如下:int a =10; int& ra =a; //正确 const int& cra = a; //正确2、常变量只能初始化为常引用!不可以初始化为普通引用!!如下:
const int b = 20; int& rb = b; //错误 const int& crb = b; //正确3、常性引用是一种万能引用,不但可以引用变量(左值),也可以引用字面常量(右值常量,不可以修改),如下所示:
const int& rc = 100; //左边是常性左值引用(不会进行修改),右边是一个右值 rc = rc+200; //编译无法通过! 底层过程(临时量): int tmp = 100; const int& rc = tmp; 常性左值引用, 不可以通过引用rc修改tmp,即rc =rc+ 200;这是不可以的!rc本身具有常性。int&& rrc = 100; //这里rrc是100的右值引用 rrc = rrc+ 200; //编译可以通过! 底层过程(临时量): int tmp = 100; int&& rrc = tmp; 这里rrc是普通右值引用,可以通过rrc修改!!rrc = rrc+ 200; 注意:这里可不是将100修改成200,而是将临时量tmp修改成200,100是字面常量不能修改!!!4、 将亡值在不具有名字的时候,它是右值,要用右值引用(两个&&号),具备名字的时候,他就是左值,要用左值引用(一个&号)
5、
int&& cy = 100; //cy是100的右值引用 cy = cy+200; //编译可以通过 int&& cx = cy; //编译无法通过,错误的! int& cx = cy; //正确的! 注意:100此时有名字叫cy,cy的值类别是左值(可以取地址),因此,要用左值引用它。(一个&号) 因为cy这个右值引用有了具体的名字,就要把他看成是左值,就应该用左值引用来引用他
4.4 使用场景
4.4.1 引用作为形参替代指针
使用指针交换两个整数:
#include <iostream>
using namespace std; //命名空间
void Swap(int* a, int* b)
{
//if(NULL==a||NULL==b) return ;
assert(a != NULL && b != NULL);
//函数的形参必须给出判断,参数的合法性检验!!!传指针必须进行指针判空,防止空指针解引用出现崩溃!
int tmp = *a;
*a = *b;
*b = tmp;
}
int main()
{
int x = 2, y = 9;
Swap(&x, &y);
return 0;
}
#endif
/*对参数的检测有两种方式:
第一种:if判断 :比较柔和!
第二种:assert断言:更加强硬:当有一个指针为NULL,程序直接终止!
参数里面有指针,一定要进行判空操作!!使用哪一种方式由自己决定!
*/使用引用交换两个整数:
#include <iostream>
using namespace std; //命名空间
//使用引用的方式
void Swap(int& a, int& b)
//传的是引用,并且没有空引用,不需要进行参数检测,但是引用不能给空,或者不给实参,这都是不允许的,这是它的灵活性差的特点!
{
int tmp = a;
a = b;
b = tmp;
}
int main()
{
int x = 2, y = 9;
Swap(x, y);
return 0;
}总结:
函数的副作用指的是:当在函数内部对形参改变,会导致实参跟着改变!传值调用不具备副作用!
从某种意义上说:引用是指针的语法糖,能用引用来替代一切指针的方案,引用相比指针的好处在于:不需要去判断引用是否为空!!因为:没有空引用!!!但是,在传参的时候,引用不能给空,或者不传,这都是不允许的!因为:首先没有空引用,其次,引用必须要进行初始化!
4.5 其他引用形式
4.5.1 数组的引用(数组的别名)
引用除了可以引用基本数据类型外,也可以引用数组,那又该如何引用,首先我们必须要知道一点,这一点才是需要我们把握的核心概念。引用的类型必须与被引用的变量的类型完全一致
请看如下代码:
#include <iostream>
using namespace std; //命名空间
int main()
{
char ch = 'a';
int a = 10;
float ft = 12.25;
/*基本数据类型/变量的引用: 引用的变量类型& 别名 = 引用变量*/
char& rch = ch;
int& ra = a;
float& rft = ft;
//引用的类型必须与被引用的变量的类型完全一致
/*数组的引用*/
const int n = 10;
int arr[n] = { 12,23,34,45,56,67,78,89,100 };
int& ra = arr[1]; //引用数组中的某个元素(变量)
int& br = arr; //这个方式引用整个数组是错误的!
int (&br)[n] = arr; //数组的描述由数据类型和数组大小决定,也就是说这个数组的类型是:int [n] ,为确保优先级正确,我们加上括号,这样就可以引用整个数组,引用了一个包含10个int类型元素的数组
int [n] (&br) = arr; //这是错误的!!不可以交换顺序
cout << sizeof(arr) << endl; //打印结果是数组所占整个空间大小:40
cout << sizeof(br) << endl; //打印结果是数组所占整个空间大小:40,br是arr的别名
return 0;
}指针数组的引用:

数组指针的引用:

4.5.2 指针的引用(指针的别名)
当然指针也可以有引用,请看如下代码:
#include <iostream>
using namespace std; //命名空间
int main()
{
int a = 10, b = 20;
int* p = &a;
int* s = p;
/*引用指针*/
int*& rp = p; //rp就是p的别名,rp和p占用同一块内存空间
*rp = 100; //这样就修改了a的值
rp = &b; //这样也就修改了p的指向
return 0;
}引用指针,其实就是这个指针的别名,同样可以通过这个指针的引用修改原来指针指向的变量,也可以修改原来指针变量的指向。
4.5.3 练习题
/****下面的语句编译均可通过,前面讲指针的兼容规程讲过********/
#if 0
#include <iostream>
using namespace std; //命名空间
int main()
{
int a = 10, b = 20;
int* const p = &a;
int* s1 = p;
const int* s2 = p;
int* const s3 = p;
const int* const s4 = p;
return 0;
}
#endif/*****练习题:对上面语句进行修改:结合了:引用、指针、const(这是C++中非常重要的三个概念)*****/
#if 1
#include <iostream>
using namespace std; //命名空间
int main()
{
int a = 10, b = 20;
int* const p = &a; //p=&b是错误的!
int*& s1 = p; //编译无法通过!这里s1是指针的引用,但是没有任何修饰,即可以通过s1=&b来修改s1的指向(s1和p是同一个实体),这与指针p发生冲突!
const int*& s2 = p; //编译无法通过!这里s1是指针的引用,只是修饰不能通过引用修改原来指针变量指向的数据。但是,可以通过s1=&b来修改s1的指向(s1和p是同一个实体),这与指针p发生冲突!
int* const& s3 = p; //编译可以通过!这里s1是指针的引用,并且限定不可以通过引用来修改原来指针变量p的指向。(s1和p是同一个实体),这与指针p不会发生冲突!
const int* const& s4 = p; //编译可以通过!这里s1是指针的引用,这是个双重限定,既不可以通过引用修改原来指针变量指向的数据,也不可以修改原来指针变量的指向!这与指针p不会发生冲突!
return 0;
}
#endif当结合引用、指针、const的时候,我们就需要认真分析了,这和前面的指针的兼容规则其实是一样的, 能力强的指针赋值给能力收缩的指针,这些都是可以通过的!!(一个指针赋值给另外一个指针,不能出现指针能力的扩张!!!!)
4.6 指针与引用的区别(面试)
从语法规则上讲:
- 引用概念上定义一个变量的别名,指针存储一个变量地址。
- 引用在定义时必须初始化,指针没有要求
- 程序为指针变量分配内存区域;而不为引用分配内存区域。
- 访问实体方式不同,指针需要显式解引用,使用时要在前加“*" ,引用编译器自己处理,引用可以直接使用。
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体;
- 没有NULL引用,但有NULL指针;
- 指针变量作为形参时需要测试它的合法性(判空NULL);引用不需要判空; .
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)
- 理论上指针的级数没有限制;但引用只有一-级。 即不存在引用的引用,但可以有指针的指针。
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小。
从汇编层次理解(引用的本质):
在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。在底层实现上实际是有区别的,因为引用是按照指针方式来实现的。



总结:
从汇编层次理解引用与指针变量的区别:编译器在编译的时候,会将引用修改为:被const修饰自身的指针(引用从初始化后不会发生变化),对于初始化引用和初始化指针,以及操作对应的变量在底层汇编代码都是一样的。引用在底层被编译器编译成指针,引用就是指针的语法糖。
4.7 引用作为函数的返回值类型
引用不仅可以作为函数的参数,还可以作为函数返回值,通过上面的学习,我们知道:引用在底层被编译器编译成指针,引用就是指针的语法糖。那它是不是和指针作为返回值一样呢?
(windows操作系统下:栈:1M,Linux操作系统下:栈:10M,栈区可以在VS平台上进行修改,Linux平台下编译时可以指定栈区的大小,怎么做?gcc -o main main.c -Wl,--stack,8388608)(以字节为单位)
看如下代码:
#if 0
#include <iostream>
using namespace std; //命名空间
int* func()
{
int arr[5] = { 1,2,3,4,5 }; //函数被调用时,在栈区为数组分配空间,函数调用结束后,函数栈帧这块内存空间将归还给操作系统,函数内部局部变量将被销毁,不可以作为返回值
return &arr[1];
}
int main()
{
int* p = func();
printf("p =%d\n", *p);
return 0;
}
#endif再看如下代码:
#if 0
#include <iostream>
using namespace std; //命名空间
/**注意下面这种情况:地址作为参数传入,地址作为返回值出,此时就可以以指针方式返回!!!**/
int* func(int* p)
{
*p += 100;
return p;
//参数传进来是a的地址即p=&a;对a进行修改,函数调用结束p会被销毁,返回的不是p本身,而是返回的是p的值!也就是a的地址
}
int main()
{
int a = 10;
int* s = func(&a); //将p返回也就是a的地址返回给s,当func()函数调用结束,a仍然存在,此时s也就指向了a!!!可以访问到a
cout << *s << endl;
return 0;
}
#endif最后,请看如下代码:
#if 1
#include <iostream>
using namespace std; //命名空间
int& Add(int a, int b)
{
int c = a + b;
return c;
}
int main()
{
int& ret = Add(1, 2);
Add(3, 4);
cout << "Add(1, 2) is :" << ret << endl;
return 0;
}
#endif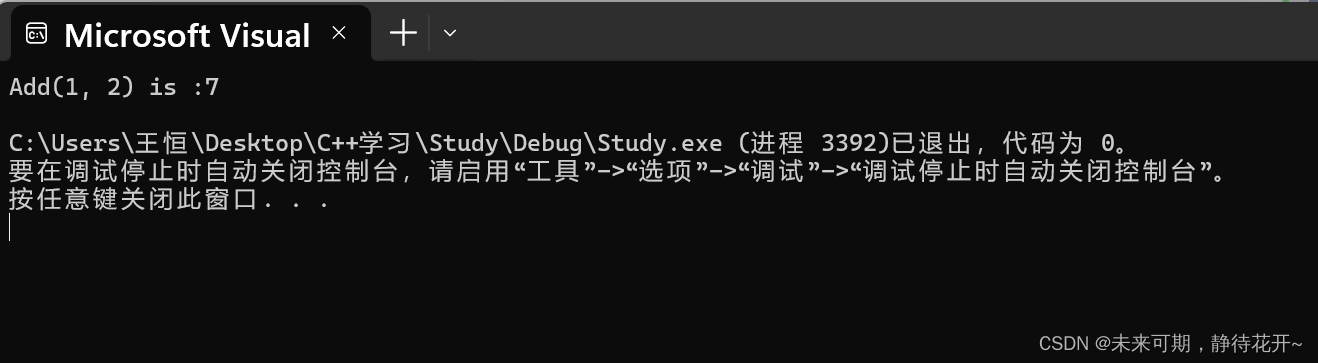
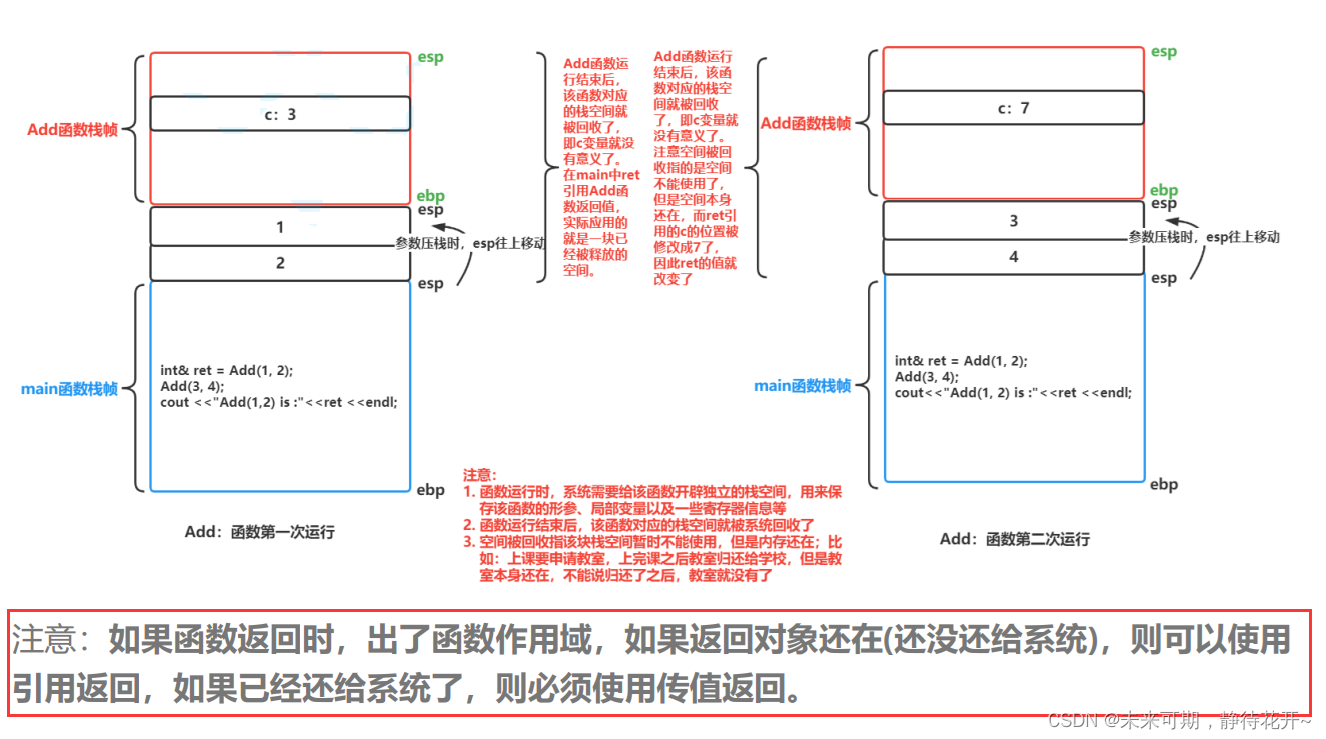
总结:
不可以对函数内部中的局部变量或对象以引用或指针的方式返回!!引用在编译阶段也会退化成指针
记住:只有变量/引用的生存周期不受函数的影响(全局变量、静态变量、堆区内的数据), 才可以将该变量或者该变量的地址(指针)或者引用的方式进行返回!!
4.8 传值、传引用效率比较
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直 接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效 率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。
- 传值调用函数: 既浪费空间,又消耗时间;
- 传址调用函数: 只需要四个字节空间(指针的大小),但是函数内部必须要进行断言指针是否为NULL;
- 传引用调用函数:引用在底层还是指针操作,引用是指针的语法糖,引用不可能为空,因此,不需要进行引用判空!
void funa(struct Student sx); void funb(struct Student *ps); void func(struct Student &s);从效率层面讲:尽可能拿引用替代指针,因为不需要进行判空,尽可能拿传指针来替代传值调用,节省内存空间,又节省时间。
这篇博客详细介绍C++入门需要懂得知识,为后续学习好C++做好准备, 如果对此专栏感兴趣,点赞加关注!