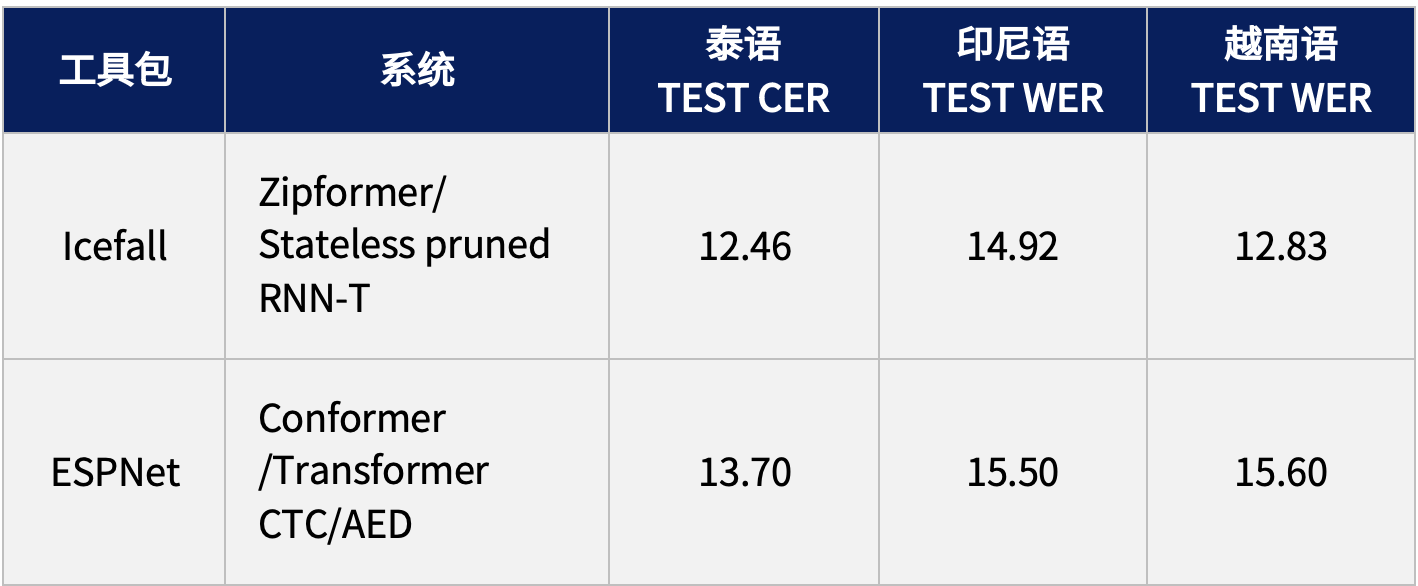
大模型训练使用的数据是开放的、广泛的,因此它显得更加的通用。然而在有些应用场景下,用户需要使用自己的数据使得大模型生成的内容更加贴切,也有时候用户的数据是敏感的,无法提供出来给大模型进行通用性的训练。RAG技术就是一种解决这种问题的方法。关于RAG的简单介绍,可以看笔者的这篇文章。
一个基于RAG技术的大语言模型应用的架构示意图如下所示:
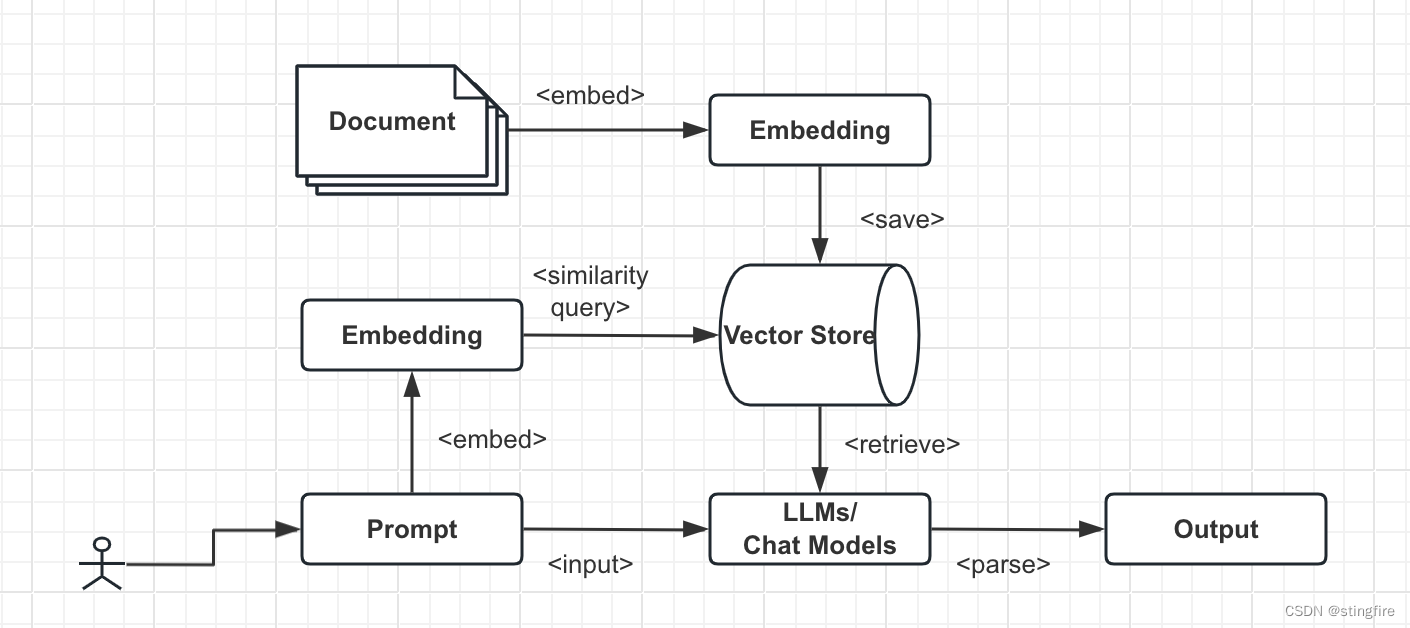
- 用户的私有数据(这里以Document表示)经过嵌入模型转换成对应的embedding存入Vector Store中:Document --> Embedding --> Vector Store。
- 使用者输入提示语Prompt,该Prompt也经过嵌入模型转换,然后转换后的结果作为查询条件在Vector Store中按照相似度查询出相关信息。这个结果解码后供大模型检索(Retrieve): Prompt --> Embedding --> Vector Store --> LLMs / Chat Models。
- 将前一步查询到的上下文内容和用户的prompt一并输入大模型来生成最终输出:Prompt --> LLMs / Chat Models --> Output。
LangChain对上述的过程进行支持,除了Prompt --> LLMs / Chat Models --> Output这条线在前面的Model I/O介绍之外,还有下面跟RAG相关的内容:
- Document Loaders:提供超过100种的文档加载器,覆盖类似PDF / Microsoft Office / JSON / CSV等等格式数据的加载。可以是本地的文档,也可以是在线的文档。
- Text Splitters:将加载的文档进行切割,这个数据预处理操作使得切割后的数据块内容更具相关性,为后续的检索操作提供更高质量的数据。
- Embedding Models:计算机不认识文字,它使用的是向量数据来计算相关文字的概率。因此需要将原始输入的文字转成相关向量,转换过程通过Embedding Models完成。
- Vector Stores:Embedding的存储场所,通过向量数据库提升embedding的查询和存储的效率。
- Retrievers:从Vector Stores中获取相关的数据,结合Prompt一块提供给大模型进行内容生成。
- Indexing:一个辅助功能,通过记录管理器(RecordManager)跟踪文档写入Vector Store中的情况。
上面的每一部分都包含LangChain实现的或者第三方提供的类,可以根据开发者的业务需要来挑选合适的实现。由于类别很多,限于篇幅不一一介绍,大家可以先通过这里的目录确定自己需要的工具。
下面简单实现一个基于LangChain的RAG代码:
from langchain_community.chat_models import ChatOllama
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores import FAISS
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# 使用PyPDFLoader加载pdf文件内容
loader = PyPDFLoader("example_data/LayoutParser-A-Unified-Toolkit-for-DeepLearning-Based-Document-Image-Analysis.pdf")
# 加载并切割,默认splitter为:RecursiveCharacterTextSplitter
pages = loader.load_and_split()
# 使用OllamaEmbeddings进行编码,本地ollama部署了phi3模型
ollama_embeddings = OllamaEmbeddings(model="phi3")
# 使用FAISS作为vector store,将文档内容使用phi3模型embedding编码后存入。
faiss_index = FAISS.from_documents(pages, ollama_embeddings)
# 使用Maximum Marginal Relevance search (MMR)算法搜索4个相近上下文
retriever = faiss_index.as_retriever(search_type="mmr", search_kwargs={"k": 4})
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# LCEL语法构造chain,并调用获得答案
prompt = hub.pull("rlm/rag-prompt")
example_messages = prompt.invoke(
{"context": "filler context", "question": "filler question"}).to_messages()
llm = ChatOllama(model="phi3")
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
for chunk in rag_chain.stream("How does LayoutParser work in document analysis?"):
print(chunk, end="", flush=True)
调用获得的输出(每次执行的结果不确定一样):