应用层优化
Web服务器问题
寻找最优并发度
每个Web服务器都有一个最佳并发度——就是说,让进程处理请求尽可能快,并且不超过系统负载的最优的并发连接数。这就是前面说的最大系统容量。进行一个简单的测量和建模,或者只是反复试验,就可以找到这个"神奇的数",为此花一些时间是值得的。
对于大流量的网站,Web服务器同一时刻处理上千个连接是很常见的。然而,只有一小部分连接需要进程实时处理。其他的可能是读请求,处理文件上传,填鸭式服务内容,或者只是等待客户端的下一步请求。随者并发的增加,服务器会逐渐到达它的最大吞吐量。在这之后,吞吐量通常开始降低,更重要的是,响应时间(延迟)也会i那位排队而开始增加。为什么会这样呢?试想,如果服务器只有一个CPU,同时接受到100个请求,,会发生什么事情呢?j假设CPU每秒能够处理一个请求。即便理想情况下操作系统没有调度的开销,也没有上下文切换的成本,那100个请求也需要CPU花费整整100s才能完成。
处理请求i的最好办法是什么?可以将其一个个地排到队列中,也可以并行地执行在不同请求之间切换,每次切换都给每个请求相同的服务时间。在这两种情况下,吞吐量都是每秒处理一个请求。然而,如果使用队列(并发=1),平均延时是50s,如果是并发执行(并发=100)则是100s。在实践中,并发执行会使平均延时更高,主要是因为上下文切换的代价。
对于CPU密集型工作负载,最佳并发度等于CPU数量(或者CPU核数)。然而,进程并不总是处于可运行状态的,因为会有一些阻塞式请求,例如IO、数据库查询,以及网络请求。因此,最佳并发度通常会比CPU数量高一些。
可以预测最优并发度,但是这需要精确的分析。尝试不同的并发值,看看在不增加响应时间的情况下的最大吞吐量是多少,或者测量真正的工作负载进行分析,这通常更容易。Percona Toolkit的pt-tcp-model工具可以帮助从TCP转储中测量和建模分析系统的可扩展性和性能特性。
缓存
缓存对高负载应用来说至关重要。一个典型的Web应用程序会提高大量的内容,直接生成这些内容的成本比采用缓存要高得多(包括检查和缓存超时的开销),所以采用缓存通常可以获得数量级的性能提升。诀窍是找到正确的粒度和缓存过期策略组合。另外也需要决定哪些内容适合缓存,缓存在哪里。
典型的高负载应用会有很多层缓存。缓存并不仅仅发生在服务器上,而是在每一个环节,甚至包括用户的Web浏览器(这就是内容过期头的用处)。通常,缓存越接近客户端,就越节省资源并且效率更高。从浏览器缓存提供一张图片比从Web服务器的内容获取快得多,而从服务器的内存读取又比从服务器的磁盘上读取好得多。每种类型的缓存有其不一样的特点,例如容量和延时。
可以把缓存分成两大类:被动缓存和主动缓存。被动缓存除了存储和返回数据外不做任何事情。当从被动缓存请求一些内容时,要么可以得到结果,要么得到"结果不存在"。被动缓存的一个典型例子时memcached.相比之下,主动缓存会在访问未命中时做一些额外的工作。通常会将请求转发给应用的其他部分来生成请求结果,然后存储该结果并返回给应用。Squid缓存代理服务器就是一个主动缓存。设计应用程序时,通常希望缓存是主动的(也可以叫做透明的),因为它们对应用隐藏了检查——生成——存储这个逻辑过程。也可以在被动缓存的前面构建一个主动缓存。
应用层以下的缓存
MySQL服务器有自己的内部缓存,但也可以构建你自己的缓存和汇总表。可以对缓存表量身定制,使他们最有效地过滤、排序、与其它表关联、计数,或者用于其他用途。缓存表也比许多应用层缓存更持久,因为在服务器重启后它们还存在。
缓存并不总是有用。
必需确认缓存真的可以提升性能,因为有时候缓存可能没有任何帮助。例如,在实践中发现从Nginx的内存中获取内容比从缓存中代理中获取要快,如果代理的缓存在磁盘上则尤其如此.
原因很简单:缓存自身也有一些开销。比如检查缓存是否存在,如果命中则直接从缓存中返回数据。另外将缓存对象失效或者写入新的缓存对象都会有开销。缓存只在这些开销比没有缓存的情况下生成和提供数据的开销少时才有用。如果直到所有这些操作的开销,就可以计算出缓存能提供多少帮助。没有缓存时的开销就是每个请求生成数据的开销。有缓存的开销是检查缓存的开销加上缓存不命中的概率乘以生成数据的开销,再加上缓存命中的概率乘以缓存提供数据的开销。如果有缓存时的开销比没有时要低,则说明缓存可能有用,但依然不能保证。还要记住,就像从Nginx的内存中获取数据比从代理在磁盘中的缓存获取要好一样,有些缓存的开销比另外一些要低
应用层缓存
应用层缓存通常在同一台机器的内存中存储数据,或者通过网络存在另一台机器的内存中。因为应用可以缓存部分计算结果,所以应用缓存可能比更低层次的缓存更有效。因此应用层缓存可以节省两方面的工作:获取数据以及基于这些数据进行计算。一个很好的例子是HTML文本块。应用程序可以生成例如头条新闻的标题这样的HTML片段,并且做好缓存。后续的页面试图就可以简单地插入这个缓存过的文本。一般来说,在缓存数据前对数据做的处理越多,缓存命中节省的工作越多。
但应用层缓存也有缺点,那就是缓存命中率可能更低,并且可能使用较多的内存。假设需要50个不同版本的头条新闻标题,以使不同地区生活的用户看到不同的内容,那就需要足够的内存去存储全部50个版本,任何给定版本的标题命中次数都会更少,并且失效策略也会更加复杂。
应用缓存有许多种,下面是其中的一小部分:
1.本地缓存
这种缓存通常很小,只在进程处理请求期间存在于进程内存中。本地缓存可以有效地避免对某些资源的重复请求。这种类型的缓存技术并不复杂:通常只是应用代码中的一个变量或者哈希表。这种类型的缓存技术并不复杂:通常只是应用代码中的一个变量或者哈希表。例如,假设需要显式一个用户名,而且已经直到其ID,就可以创建一个get_name_from_id()函数并且在其中增加缓存。像下面这样:
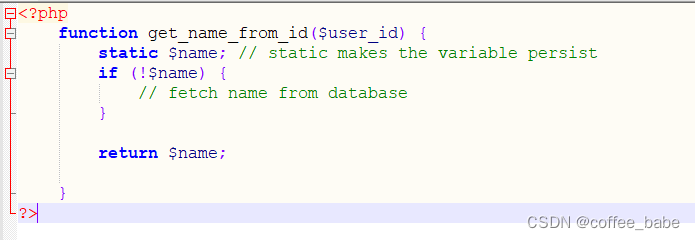
<?php
function get_name_from_id($user_id) {
static $name; // static makes the variable persist
if (!$name) {
// fetch name from database
}
return $name;
}
?>
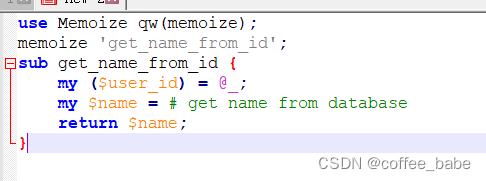
如果使用的是Perl,那么Memoize模块是函数调用结果标准的缓存方式:
use Memoize qw(memoize);
memoize 'get_name_from_id';
sub get_name_from_id {
my ($user_id) = @_;
my $name = # get name from database
return $name;
}