-
打开终端(在Unix或macOS上)或命令提示符/Anaconda Prompt(在Windows上)。
-
创建一个名为
lora的虚拟环境并指定Python版本为3.9。
https://github.com/echonoshy/cgft-llm/blob/master/llama-factory/README.md
GitHub - hiyouga/LLaMA-Factory: Unify Efficient Fine-Tuning of 100+ LLMs
conda create --name lora python=3.9
- 激活新创建的虚拟环境。
conda activate lora
- 克隆项目。
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
- 安装Python依赖项。由于您已经有了依赖项的列表,您可以使用
pip来安装它们。
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install transformers_stream_generator bitsandbytes tiktoken auto-gptq optimum autoawq -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install --upgrade tensorflow -i https://pypi.tuna.tsinghua.edu.cn/simple
- 运行代码。
CUDA_VISIBLE_DEVICES=0 USE_MODELSCOPE_HUB=1 python src/webui.py
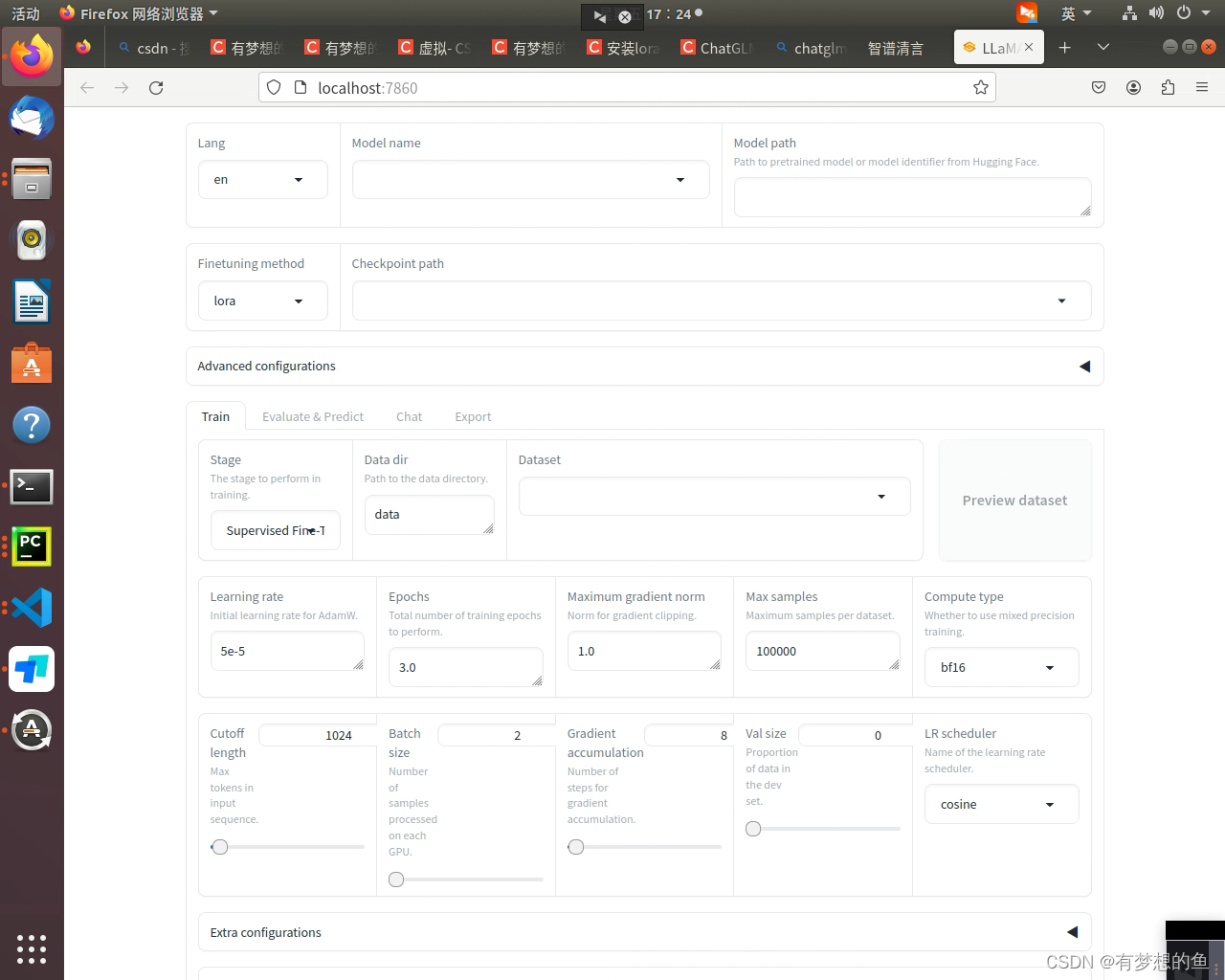 当您完成工作后,您可以停用虚拟环境。
当您完成工作后,您可以停用虚拟环境。
llamafactory-cli train cust/train_llama3_lora_sft.yaml
conda deactivate
请确保您已经有了conda命令行工具,并且已经添加到您的系统环境变量中。如果您还没有安装conda,您可以从Anaconda或Miniconda官网下载并安装。
请注意,如果您在安装过程中遇到任何依赖性问题,您可能需要根据错误信息调整包的版本或安装顺序。
微调命令
(构建 cust/train_llama3_lora_sft.yaml)
(命令行执行:llamafactory-cli train cust/train_llama3_lora_sft.yaml)
(打开ui: llamafactory-cli webchat cust/train_llama3_lora_sft.yaml)
cutoff_len: 1024
dataset: fintech,identity
dataset_dir: data
do_train: true
finetuning_type: lora
flash_attn: auto
fp16: true
gradient_accumulation_steps: 8
learning_rate: 0.0002
logging_steps: 5
lora_alpha: 16
lora_dropout: 0
lora_rank: 8
lora_target: q_proj,v_proj
lr_scheduler_type: cosine
max_grad_norm: 1.0
max_samples: 1000
model_name_or_path: /root/autodl-tmp/models/Llama3-8B-Chinese-Chat
num_train_epochs: 10.0
optim: adamw_torch
output_dir: saves/LLaMA3-8B-Chinese-Chat/lora/train_2024-05-25-20-27-47
packing: false
per_device_train_batch_size: 2
plot_loss: true
preprocessing_num_workers: 16
report_to: none
save_steps: 100
stage: sft
template: llama3
use_unsloth: true
warmup_steps: 0合并
llamafactory-cli export cust/merge_llama3_lora_sft.yaml### 上面文件内容Note: DO NOT use quantized model or quantization_bit when merging lora adapters
### model
model_name_or_path: /media/ldx/陈启的机械硬盘/models/Llama3-8B-Chinese-Chat1/
adapter_name_or_path: /home/ldx/LLaMA-Factory/saves/LLaMA3-8B-Chinese-Chat/lora/train_2024-07-01-20-27-47
template: llama3
finetuning_type: lora
### export
export_dir: /media/ldx/陈启的机械硬盘/models/Llama3-8B-Chinese-Chat-cq/
export_size: 4
export_device: cuda
export_legacy_format:
API对话
# 指定多卡和端口
CUDA_VISIBLE_DEVICES=0,1 API_PORT=8000
llamafactory-cli api cust/train_llama3_lora_sft.yamlCUDA_VISIBLE_DEVICES=0 API_PORT=8000 llamafactory-cli api --model_name_or_path megred-model-path --template llama3 --infer_backend vllm --vllm_enforce_eager
from openai import OpenAI
# autodl 中指令
# CUDA_VISIBLE_DEVICES=0 nohup python -m vllm.entrypoints.openai.api_server --model /autodl-tmp/LLM-Research/Meta-Llama-3-8B-Instruct --served-model-name Meta-Llama-3-8B-Instruct --dtype=half > vllm_test.out &
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="Meta-Llama-3-8B-Instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你是谁?"},
]
)
print("Chat response:", chat_response.choices)
终端对话
llamafactory-cli chat cust/train_llama3_lora_sft.yamlUI对话
llamafactory-cli webchat cust/train_llama3_lora_sft.yaml