目录
- 手动实现 DataWorks 的数据质量监控告警功能
- 1. 简介:
- 2. 数据表准备
- 2.1 tmp_monitor_tbl_info (数据监控信息表)
- 2.2 tmp_monitor_rule_info (数据质量监控规则表)
- 2.3 tmp_monitor_tbl_info_log_di (数据监控信息记录表)
- 3. 程序开发
- 3.1 数据检查程序
- 3.2 告警信息推送程序
- 3.3 告警样例
- 4. 规则代码
- 4.1 表行数,上周期差值
- 4.2 表行数, 固定值
- 4.3 表行数, n天波动率
- 5. 结语
- end
手动实现 DataWorks 的数据质量监控告警功能
1. 简介:
使用Python 实现对数据库表的监控告警功能, 并将告警信息通过钉钉机器人发送到钉钉群
实现DataWorks中数据质量的基本功能, 当然 DW的数据质量的规则类型很多, 用起来比较方便, 这里目前简单实现了其中三个规则类型的功能, 仅供参考, 欢迎交流;
初次使用Python, 请多指教
使用工具: MaxCompute
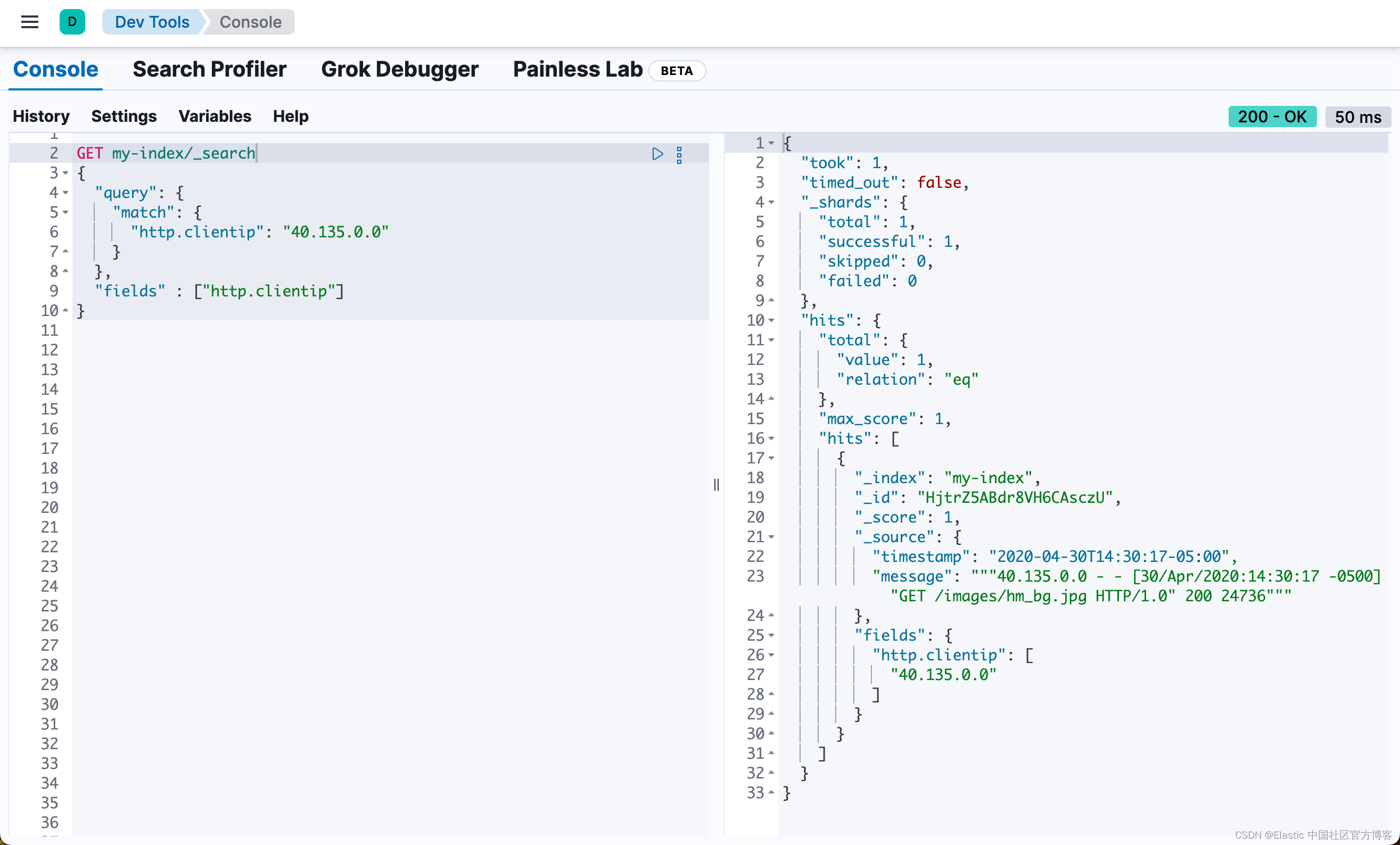
2. 数据表准备
2.1 tmp_monitor_tbl_info (数据监控信息表)
创建 数据监控信息表 (事务表)
CREATE TABLE IF NOT EXISTS tmp_monitor_tbl_info (
`id` STRING COMMENT '表编号id'
, `tbl_name` STRING COMMENT '表名'
, `pt_format` STRING COMMENT '分区格式: yyyy-MM-dd,yyyyMMdd 等'
, `val_type` STRING COMMENT '值类型: 表行数,周期值等'
, `monitor_flag` int COMMENT '监控标识: 0:不监控, 1:监控;'
, `rule_code` int COMMENT '规则编码: 1:表行数,上周期差值, 2:表行数,固定值 等'
, `rule_type` STRING COMMENT '规则类型: 表行数,上周期差值; 表行数,固定值; 与固定值比较 等'
, `expect_val` int COMMENT '期望值'
, `tbl_sort_code` int COMMENT '表类型编码: 0:其它(维表类), 1:亚马逊, 2:中小平台, 3:市场数据 等'
, `tbl_sort_name` STRING COMMENT '表类型名字: 0:其它(维表类), 1:亚马逊, 2:中小平台, 3:市场数据 等'
, `pt_num` INT COMMENT '分区日期差值'
, `monitor_freq` STRING COMMENT '监控频率: h:小时监控; d:天监控;'
, `monitor_hour` STRING COMMENT '监控时间: 默认值:every hour'
, `rule_parameters` STRING COMMENT '规则参数: 不同规则的补充参数(默认:无)'
, `tbl_id` STRING COMMENT '表ID: 一个表对应一个ID'
) COMMENT '数据监控表信息'
tblproperties ("transactional"="true",
"write.bucket.num" = "10",
"acid.data.retain.hours"="120")
;
更新数据DML
-- 插入几条数据
INSERT INTO TABLE tmp_monitor_tbl_info (id, tbl_name, pt_format, val_type, monitor_flag, rule_code, rule_type, expect_val
, tbl_sort_code, tbl_sort_name, pt_num, monitor_freq, monitor_hour, rule_parameters, tbl_id)
VALUES
('7583f809d87a3743d1bbc151372edc74', 'ods_amazon_amz_order_df', 'yyyyMMdd', '表行数', 1, 1, '表行数,上周期差值', 0, 1, '亚马逊-退款分析', -1, 'd', '03', '无', 149)
, ('be970b38a04b6ab054f5c1f9ccb91b07', 'ods_dawnwin_erp_op_order_df', 'yyyyMMdd', '表行数', 1, 1, '表行数,上周期差值', 0, 1, '亚马逊-退款分析', -1, 'd', '03', '无', 150)
, ('1f18a778e6631176bab2a7c4d3415915', 'dws_amazon_market_refund_analysis_di', 'yyyyMMdd', '表行数', 1, 2, '表行数,固定值', 200, 1, '亚马逊-退款分析', -1, 'd', '08', '无', 151)
;
-- id 生成 MD5(CONCAT(tbl_name, '_', rule_code, '_', rule_parameters))
SELECT MD5(CONCAT('dwd_gmv_scm_book_balance_di', '_', 3, '_', '7')) AS id ;
-- 更新一条数据
UPDATE tmp_monitor_tbl_info SET tbl_id = 29 WHERE tbl_id = 33 ;
-- 删除一条数据
DELETE FROM tmp_monitor_tbl_info WHERE tbl_id = 30 ;
-- 查看数据
SELECT * FROM tmp_monitor_tbl_info ;
-- 添加列 添加字段
ALTER TABLE tmp_monitor_tbl_info ADD COLUMNS pt_num INT COMMENT '分区日期差值' ;
-- 更新数据, 给新增字段设置值
UPDATE tmp_monitor_tbl_info SET pt_num = -1 ;
-- 更新数据, 修改其中一条数据一个字段值
UPDATE tmp_monitor_tbl_info SET pt_num = -2 WHERE tbl_id = 38 ;
-- 更新数据
UPDATE tmp_monitor_tbl_info SET expect_val = 580 WHERE tbl_id in (26, 27) ;
-- 添加列 添加字段
ALTER TABLE tmp_monitor_tbl_info ADD COLUMNS tbl_id INT COMMENT '表ID: 一个表对应一个ID' ;
ALTER TABLE tmp_monitor_tbl_info_log_di ADD COLUMNS actual_val DECIMAL(20,6) COMMENT '真实值: 与期望值对应的真实值' ;
-- 更新数据, 给新增字段设置值
UPDATE tmp_monitor_tbl_info SET rule_parameters = '无' ;
UPDATE tmp_monitor_tbl_info SET tbl_id = CAST(id AS INT) ;
UPDATE tmp_monitor_tbl_info SET id = MD5(CONCAT(tbl_name, '_', rule_code, '_', rule_parameters)) ;
-- 更新数据, 修改其中一条数据一个字段值
UPDATE tmp_monitor_tbl_info SET monitor_freq = 'd' WHERE tbl_id = 3 ;
UPDATE tmp_monitor_tbl_info SET monitor_freq = 'd' WHERE tbl_id = 4 ;
-- 删除一条数据
DELETE FROM tmp_monitor_tbl_info WHERE tbl_id = 72 AND rule_parameters IN ('1', '7') ;
-- 插入几条数据
INSERT INTO TABLE tmp_monitor_tbl_info (id, tbl_name, pt_format, val_type, monitor_flag, rule_code, rule_type, expect_val, tbl_sort_code, tbl_sort_name, pt_num, monitor_freq, monitor_hour, rule_parameters, tbl_id)
VALUES
('5dc8f336c5c3b4c222c3215910e12400', 'dwd_gmv_scm_book_balance_di', 'yyyyMMdd', '表行数', 1, 3, '表行数,n天波动率', 5, 5, 'gmv', 0, 'd', '15,17,19', '1', 72)
, ('2394d8dc9954381bfe3f3d29a02bd263', 'dwd_gmv_scm_book_balance_di', 'yyyyMMdd', '表行数', 1, 3, '表行数,n天波动率', 10, 5, 'gmv', 0, 'd', '15,17,19', '7', 72)
;
-- 查看 监控表信息
SELECT * FROM tmp_monitor_tbl_info
ORDER BY tbl_id DESC
;
2.2 tmp_monitor_rule_info (数据质量监控规则表)
创建表DDL
-- 规则表
CREATE TABLE IF NOT EXISTS tmp_monitor_rule_info(
`rule_id` INT COMMENT '规则id'
, `rule_name` STRING COMMENT '规则名字' -- 表行数,上周期差值
, `rule_code` STRING COMMENT '规则代码'
, `rule_sql` STRING COMMENT '规则sql'
)
COMMENT '数据质量监控规则表'
tblproperties ("transactional"="true",
"write.bucket.num" = "10",
"acid.data.retain.hours"="120")
--lifecycle 365
;
插入数据/更新数据 DML
INSERT INTO TABLE tmp_monitor_rule_info (rule_id, rule_name, rule_code, rule_sql)
VALUES
(1, '表行数,上周期差值', 'upper_period_diff', '')
, (2, '表行数,固定值', 'line_fixed_val', '')
, (3, '表行数,n天波动率', 'cycle_volatility', '')
;
UPDATE tmp_monitor_rule_info
SET rule_sql = "set odps.sql.hive.compatible=true ; INSERT INTO TABLE {res_tbl_name} PARTITION (pt='{pt}') SELECT a.id , a.tbl_name , a.stat_time , a.pt_format , a.stat_pt , a.val_type , a.val , a.rule_code , a.rule_type , a.expect_val , IF (a.val = 0, 1, (IF ((a.val - NVL(b.val,0)) >= {expect_val}, 0, 1 ))) AS is_exc , a.tbl_sort_code , a.tbl_sort_name , a.val - NVL(b.val,0) AS actual_val FROM ( SELECT concat( md5(concat('{tbl_name}', '_', date_format('{date_str}' ,'{pt_format}')) ), '_', {rule_code}, '_', HOUR('{now_time}') ) AS id , '{tbl_name}' AS tbl_name , '{now_time}' AS stat_time , '{pt_format}' AS pt_format , date_format('{date_str}' ,'{pt_format}') AS stat_pt , '{val_type}' AS val_type , COUNT(1) AS val , '{rule_code}' AS rule_code , '{rule_type}' AS rule_type , {expect_val} AS expect_val , {tbl_sort_code} AS tbl_sort_code , '{tbl_sort_name}' AS tbl_sort_name FROM {tbl_name} WHERE pt = date_format('{date_str}' ,'{pt_format}') ) a LEFT JOIN ( SELECT tbl_name, val FROM ( SELECT tbl_name, val , ROW_NUMBER() OVER(PARTITION BY tbl_name ORDER BY stat_time DESC ) AS rn FROM {res_tbl_name} WHERE pt = DATE_ADD('{pt}', -1) AND tbl_name = '{tbl_name}' AND rule_code = 1 ) WHERE rn = 1 ) b ON a.tbl_name = b.tbl_name ;"
WHERE rule_id = 1 ;
UPDATE tmp_monitor_rule_info
SET rule_sql = "set odps.sql.hive.compatible=true ; INSERT INTO TABLE {res_tbl_name} PARTITION (pt='{pt}') SELECT concat( md5(concat('{tbl_name}', '_', date_format('{date_str}' ,'{pt_format}')) ), '_', {rule_code}, '_', HOUR('{now_time}') ) AS id , '{tbl_name}' AS tbl_name , '{now_time}' AS stat_time , '{pt_format}' AS pt_format , date_format('{date_str}' ,'{pt_format}') AS stat_pt , '{val_type}' AS val_type , ct AS val , '{rule_code}' AS rule_code , '{rule_type}' AS rule_type , {expect_val} AS expect_val , IF (ct >= {expect_val}, 0, 1 ) AS is_exc , {tbl_sort_code} AS tbl_sort_code , '{tbl_sort_name}' AS tbl_sort_name , ct AS actual_val FROM ( SELECT COUNT(1) AS ct FROM {tbl_name} WHERE pt = date_format('{date_str}' ,'{pt_format}') ) a ;"
WHERE rule_id = 2 ;
UPDATE tmp_monitor_rule_info
SET rule_sql = "set odps.sql.hive.compatible=true ; INSERT INTO TABLE {res_tbl_name} PARTITION (pt='{pt}') SELECT id , tbl_name , stat_time , pt_format , stat_pt , val_type , val_now AS val , rule_code , rule_type , expect_val , IF(val_last > 0, IF(ABS(val_now - val_last) / val_last * 100 > {expect_val}, 1, 0), IF(val_last = 0, 1, 0)) AS is_exc , tbl_sort_code , tbl_sort_name , IF(val_last > 0, ABS(val_now - val_last) / val_last * 100, -1) AS actual_val FROM ( SELECT concat( md5(concat('{tbl_name}', '_', date_format('{date_str}' ,'{pt_format}')) ), '_', {rule_code}, '_', '{rule_parameters}', '_', HOUR('{now_time}') ) AS id , '{tbl_name}' AS tbl_name , '{now_time}' AS stat_time , '{pt_format}' AS pt_format , date_format('{date_str}' ,'{pt_format}') AS stat_pt , '{val_type}' AS val_type , COUNT(1) AS val_now , '{rule_code}' AS rule_code , REPLACE('{rule_type}', 'n', '{rule_parameters}') AS rule_type , {expect_val} AS expect_val , {tbl_sort_code} AS tbl_sort_code , '{tbl_sort_name}' AS tbl_sort_name , ( SELECT val FROM ( SELECT tbl_name, val , ROW_NUMBER() OVER(PARTITION BY tbl_name ORDER BY stat_time DESC ) AS rn FROM {res_tbl_name} WHERE pt = DATE_ADD('{pt}', - CAST('{rule_parameters}' AS INT)) AND tbl_name = '{tbl_name}' AND rule_code = 3 ) WHERE rn = 1 ) AS val_last FROM {tbl_name} WHERE pt = date_format('{date_str}' ,'{pt_format}') ) a ;"
WHERE rule_id = 3 ;
-- 查看数据
SELECT * FROM tmp_monitor_rule_info ;
2.3 tmp_monitor_tbl_info_log_di (数据监控信息记录表)
创建表
CREATE TABLE IF NOT EXISTS puture_bigdata_dev.tmp_monitor_tbl_info_log_di (
`id` STRING COMMENT '监控id编码:md5(表名_分区)_小时'
, `tbl_name` STRING COMMENT '表名'
, `stat_time` STRING COMMENT '统计时间'
, `pt_format` STRING COMMENT '分区格式: yyyy-MM-dd,yyyyMMdd 等'
, `stat_pt` STRING COMMENT '统计分区'
, `val_type` STRING COMMENT '值类型: 表行数,周期值等'
, `val` int COMMENT '统计值'
, `rule_code` int COMMENT '规则编码: 1:表行数,上周期差值, 2:表行数,固定值 等'
, `rule_type` STRING COMMENT '规则类型: 表行数,上周期差值; 表行数,固定值; 与固定值比较 等'
, `expect_val` int COMMENT '期望值'
, `is_exc` int COMMENT '是否异常: 0:否,1:是,默认值0'
, `tbl_sort_code` int COMMENT '表类型编码: 0:其它(维表类), 1:亚马逊, 2:中小平台, 3:市场数据 等'
, `tbl_sort_name` STRING COMMENT '表类型名字: 0:其它(维表类), 1:亚马逊, 2:中小平台, 3:市场数据 等'
, `actual_val` DECIMAL(20,6) COMMENT '真实值: 与期望值对应的真实值'
) COMMENT '数据监控信息记录表'
PARTITIONED BY (pt STRING COMMENT '数据日期, yyyy-MM-dd')
;
3. 程序开发
3.1 数据检查程序
程序代码
'''PyODPS 3
请确保不要使用从 MaxCompute下载数据来处理。下载数据操作常包括Table/Instance的open_reader以及 DataFrame的to_pandas方法。
推荐使用 PyODPS DataFrame(从 MaxCompute 表创建)和MaxCompute SQL来处理数据。
更详细的内容可以参考:https://help.aliyun.com/document_detail/90481.html
'''
import os
from odps import ODPS, DataFrame
from datetime import datetime, timedelta
from dateutil import parser
options.tunnel.use_instance_tunnel = True
# 获取当前时间
now_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("now_time:{}".format(now_time) )
pt = args['date']
hh = args['hour']
print("pt:{}".format(pt) )
print("hh:{}".format(hh) )
date = datetime.strptime(pt, "%Y-%m-%d")
# 结果表
res_tbl_name = "tmp_monitor_tbl_info_log_di"
# 监控表列表
# 小时任务里有天级别的监控表,做过滤,减少重复查询
sql_tbl_info = f"""
SELECT * FROM tmp_monitor_tbl_info
WHERE monitor_flag = 1 AND tbl_sort_code = 5
AND (monitor_freq = 'h' OR FIND_IN_SET('{hh}', monitor_hour) > 0)
"""
# 查出规则sql
def rule():
rule = f"""
SELECT rule_sql FROM tmp_monitor_rule_info
WHERE rule_id = {rule_code} ;
"""
return rule
# 具体规则(规则信息匹配之后, 执行规则sql)
def sql_rule():
sql = eval(f'f"{rule_sql}"')
return sql
# 执行监控统计代码
def ex_monitor(sql: str):
try :
#print (sql)
o.execute_sql(sql, hints={'odps.sql.hive.compatible': True , "odps.sql.submit.mode":"script"})
print("{}: 运行成功".format(tbl_name) )
except Exception as e:
print('{}: 运行异常 ======> '.format(tbl_name) + str(e))
# 执行sql, 打印结果
if __name__ == '__main__':
try :
with o.execute_sql(sql_tbl_info, hints={'odps.sql.hive.compatible': True}).open_reader() as reader:
for row_record in reader:
#print(row_record) # 打印一条数据值
tbl_name = row_record.tbl_name
pt_format = row_record.pt_format
val_type = row_record.val_type
monitor_flag = row_record.monitor_flag
rule_code = row_record.rule_code
rule_type = row_record.rule_type
expect_val = row_record.expect_val
tbl_sort_code = row_record.tbl_sort_code
tbl_sort_name = row_record.tbl_sort_name
pt_num = row_record.pt_num
rule_parameters = row_record.rule_parameters
date_str = (date + timedelta(days=pt_num)).strftime('%Y-%m-%d')
# 根据 rule_code 查找对应的规则代码
with o.execute_sql(rule(), hints={'odps.sql.hive.compatible': True}).open_reader(tunnel=True, limit=False) as reader:
for record in reader:
rule_sql = record.rule_sql
ex_monitor(sql_rule())
except Exception as e:
print('异常 ======> ' + str(e))
3.2 告警信息推送程序
程序代码
'''PyODPS 3
请确保不要使用从 MaxCompute下载数据来处理。下载数据操作常包括Table/Instance的open_reader以及 DataFrame的to_pandas方法。
推荐使用 PyODPS DataFrame(从 MaxCompute 表创建)和MaxCompute SQL来处理数据。
更详细的内容可以参考:https://help.aliyun.com/document_detail/90481.html
'''
import json
import requests
from datetime import datetime
import os
from odps import ODPS, DataFrame
date_str = args['date']
# 接口地址和token信息
url = 'https://oapi.dingtalk.com/robot/send?access_token=*****' # 修改为自己的token
now_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print(now_time)
# 结果表
tbl_info = "tmp_monitor_tbl_info"
res_tbl_name = "tmp_monitor_tbl_info_log_di"
# 查出最新数据中, 存在异常的数据表信息, 根据不同业务流程配置 tbl_sort_code
sql_query = f"""
SELECT tbl_name, stat_time, stat_pt, val_type, val, rule_type, expect_val, is_exc, actual_val, rule_code
FROM (
SELECT tbl_name, stat_time, stat_pt, val_type, val, rule_type, expect_val, is_exc, actual_val, rule_code
, ROW_NUMBER() OVER(PARTITION BY tbl_name, rule_code, rule_type ORDER BY stat_time DESC) AS rn
FROM {res_tbl_name}
WHERE pt = '{date_str}'
AND tbl_sort_code IN (10, 13) -- 表种类
AND tbl_name IN (SELECT tbl_name FROM {tbl_info} WHERE monitor_flag = 1 AND tbl_sort_code IN (10, 13) ) -- 表种类
) a
WHERE rn = 1 AND is_exc = 1
"""
# 钉钉机器人,发送消息
def dd_robot(url:str, content: str):
HEADERS = {"Content-Type": "application/json;charset=utf-8"}
#content里面要设置关键字
data_info = {
"msgtype": "text",
"text": {
"content": content
},
"isAtAll": False
#这是配置需要@的人
# ,"at": {"atMobiles": ["15xxxxxx06",'18xxxxxx1']}
}
value = json.dumps(data_info)
response = requests.post(url,data=value,headers=HEADERS)
if response.json()['errmsg']!='ok':
print(response.text)
# 主函数
if __name__ == '__main__': # py3可以省略
try :
with o.execute_sql(sql_query, hints={'odps.sql.hive.compatible': True}).open_reader() as reader:
result_rows = list(reader) # 读取所有的结果行
result_count = len(result_rows) # 获取结果条数
#print("结果条数:", result_count) # 打印结果条数
if result_count > 0 :
for row in result_rows:
tbl_name = row.tbl_name
stat_time = row.stat_time
stat_pt = row.stat_pt
val_type = row.val_type
val = row.val
rule_type = row.rule_type
expect_val = row.expect_val
actual_val = row.actual_val
rule_code = row.rule_code
#print (tbl_name)
content = "数据质量(DQC)校验告警 \n "
content = content + "【对象名称】:" + tbl_name + " \n "
content = content + "【实际分区】:pt=" + stat_pt + " \n "
content = content + "【触发规则】: " + rule_type + " \n "
# 根据不同的规则, 输出不同的告警信息样式
if rule_code == '2' :
content = content + "【规则明细】: 当前样本值: " + val + " | 阈值: " + expect_val + " \n "
else :
content = content + "【规则明细】: 当前样本值: " + val + " | 阈值: " + expect_val + " | 实际值: " + actual_val + " \n "
content = content + now_time
dd_robot(url, content)
else :
print("无异常情况;")
except Exception as e:
print('异常 ========>' + str(e) )
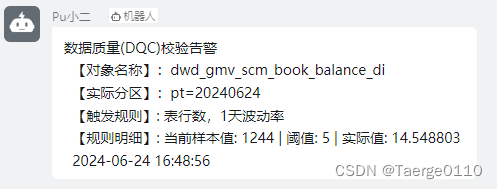
3.3 告警样例
数据质量(DQC)校验告警
【对象名称】:dwd_gmv_scm_book_balance_di
【实际分区】:pt=20240624
【触发规则】: 表行数,1天波动率
【规则明细】: 当前样本值: 1244 | 阈值: 5 | 实际值: 14.548803
2024-06-24 16:48:56
4. 规则代码
- 写入规则表里的 rule_sql 部分
4.1 表行数,上周期差值
# 1. 表行数,上周期差值
def sql_upper_period_diff():
sql = f"""
set odps.sql.hive.compatible=true ;
INSERT INTO TABLE {res_tbl_name} PARTITION (pt='{pt}')
SELECT
a.id
, a.tbl_name
, a.stat_time
, a.pt_format
, a.stat_pt
, a.val_type
, a.val
, a.rule_code
, a.rule_type
, a.expect_val
, IF (a.val = 0, 1, (IF ((a.val - NVL(b.val,0)) >= {expect_val}, 0, 1 ))) AS is_exc
, a.tbl_sort_code
, a.tbl_sort_name
, a.val - NVL(b.val,0) AS actual_val
FROM (
SELECT
concat( md5(concat('{tbl_name}', '_', date_format('{date_str}' ,'{pt_format}')) ), '_', {rule_code}, '_', HOUR('{now_time}') ) AS id
, '{tbl_name}' AS tbl_name
, '{now_time}' AS stat_time
, '{pt_format}' AS pt_format
, date_format('{date_str}' ,'{pt_format}') AS stat_pt
, '{val_type}' AS val_type
, COUNT(1) AS val
, '{rule_code}' AS rule_code
, '{rule_type}' AS rule_type
, {expect_val} AS expect_val
, {tbl_sort_code} AS tbl_sort_code
, '{tbl_sort_name}' AS tbl_sort_name
FROM {tbl_name}
WHERE pt = date_format('{date_str}' ,'{pt_format}')
) a
LEFT JOIN
(
SELECT tbl_name, val FROM (
SELECT tbl_name, val
, ROW_NUMBER() OVER(PARTITION BY tbl_name ORDER BY stat_time DESC ) AS rn
FROM {res_tbl_name}
WHERE pt = DATE_ADD('{pt}', -1)
AND tbl_name = '{tbl_name}'
AND rule_code = 1
) WHERE rn = 1
) b
ON a.tbl_name = b.tbl_name
;
"""
return sql
4.2 表行数, 固定值
# 2. 表行数, 固定值
def sql_line_fixed_val():
sql = f"""
set odps.sql.hive.compatible=true ;
INSERT INTO TABLE {res_tbl_name} PARTITION (pt='{pt}')
SELECT
concat( md5(concat('{tbl_name}', '_', date_format('{date_str}' ,'{pt_format}')) ), '_', {rule_code}, '_', HOUR('{now_time}') ) AS id
, '{tbl_name}' AS tbl_name
, '{now_time}' AS stat_time
, '{pt_format}' AS pt_format
, date_format('{date_str}' ,'{pt_format}') AS stat_pt
, '{val_type}' AS val_type
, ct AS val
, '{rule_code}' AS rule_code
, '{rule_type}' AS rule_type
, {expect_val} AS expect_val
, IF (ct >= {expect_val}, 0, 1 ) AS is_exc
, {tbl_sort_code} AS tbl_sort_code
, '{tbl_sort_name}' AS tbl_sort_name
, ct AS actual_val
FROM (
SELECT COUNT(1) AS ct
FROM {tbl_name}
WHERE pt = date_format('{date_str}' ,'{pt_format}')
) a ;
"""
return sql
4.3 表行数, n天波动率
# 3. 表行数, n天波动率
def sql_cycle_volatility():
sql = f"""
set odps.sql.hive.compatible=true ;
INSERT INTO TABLE {res_tbl_name} PARTITION (pt='{pt}')
SELECT
id
, tbl_name
, stat_time
, pt_format
, stat_pt
, val_type
, val_now AS val
-- , val_last
, rule_code
, rule_type
, expect_val
, IF(val_last > 0, IF(ABS(val_now - val_last) / val_last * 100 > {expect_val}, 1, 0), IF(val_last = 0, 1, 0)) AS is_exc
, tbl_sort_code
, tbl_sort_name
, IF(val_last > 0, ABS(val_now - val_last) / val_last * 100, -1) AS actual_val
FROM (
SELECT
concat( md5(concat('{tbl_name}', '_', date_format('{date_str}' ,'{pt_format}')) ), '_', {rule_code}, '_', '{rule_parameters}', '_', HOUR('{now_time}') ) AS id
, '{tbl_name}' AS tbl_name
, '{now_time}' AS stat_time
, '{pt_format}' AS pt_format
, date_format('{date_str}' ,'{pt_format}') AS stat_pt
, '{val_type}' AS val_type
, COUNT(1) AS val_now
, '{rule_code}' AS rule_code
, REPLACE('{rule_type}', 'n', '{rule_parameters}') AS rule_type
, {expect_val} AS expect_val
, {tbl_sort_code} AS tbl_sort_code
, '{tbl_sort_name}' AS tbl_sort_name
, (
SELECT val FROM (
SELECT tbl_name, val
, ROW_NUMBER() OVER(PARTITION BY tbl_name ORDER BY stat_time DESC ) AS rn
FROM {res_tbl_name}
WHERE pt = DATE_ADD('{pt}', - CAST('{rule_parameters}' AS INT))
AND tbl_name = '{tbl_name}'
AND rule_code = 3
) WHERE rn = 1
) AS val_last
FROM {tbl_name}
WHERE pt = date_format('{date_str}' ,'{pt_format}')
) a ;
"""
return sql
5. 结语
- 代码可以直接copy, 可开箱即用(部分内容, 如分区层级, 可根据你自己公司的数据表进行调整);
- 规则内容如有不懂, 欢迎咨询讨论;
- DataWorks的数据质量需要另外收费, 自己实现免费使用(当然DW可选择的规则会有很多, 目前只实现了常用的几个);
- 初次学习使用 python, 如若代码中有可精简的操作, 或方法, 欢迎指教;
- 后续会持续优化操作, 更新功能, 持续关注, 欢迎交流;
- 本博文是之前的升级版本: Python常用日期函数和日期处理方法;
- 欢迎留言讨论;





![[Microsoft Office]Word设置页码从第二页开始为1](https://img-blog.csdnimg.cn/direct/e9827a32189a4faabe2f1dc2889159fd.png)