目录:
- 什么是zip函数
- zip的基本使用
- zip与列表、字典的结合
- zip的长度匹配规则
- 实际应用
1. 什么是zip函数
zip函数在Python中用于将多个可迭代对象(如列表、元组、字符串等)打包成一个元组的列表,其中每个元组包含的是原始对象中的对应元素。
换句话说,它像是一根神奇的针线,将不同序列的相同位置的元素缝合在一起,形成新的组合。
这种方式非常适合处理需要同步遍历多个列表的情况。
2. zip的基本使用
首先,让我们通过一个简单的例子感受zip的魅力:
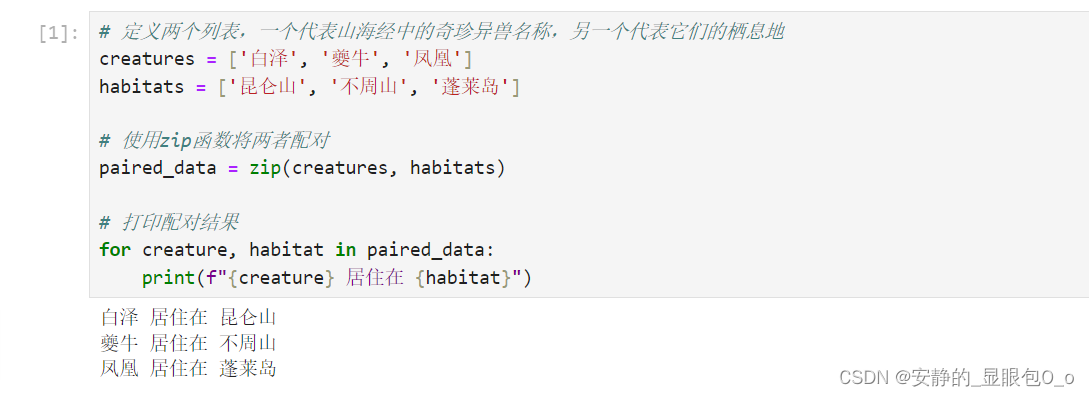
# 定义两个列表,一个代表山海经中的奇珍异兽名称,另一个代表它们的栖息地
creatures = ['白泽', '夔牛', '凤凰']
habitats = ['昆仑山', '不周山', '蓬莱岛']
# 使用zip函数将两者配对
paired_data = zip(creatures, habitats)
# 打印配对结果
for creature, habitat in paired_data:
print(f"{creature} 居住在 {habitat}")
输出结果:
白泽 居住在 昆仑山
夔牛 居住在 不周山
凤凰 居住在 蓬莱岛
这里,zip(creatures, habitats)创建了一个迭代器,每次迭代都会产出一对来自两个列表的元素。通过for循环遍历这个迭代器,我们可以清晰地看到每种异兽与其栖息地的对应关系。
eg:
3. zip与列表、字典的结合
zip不仅能帮助我们并行遍历数据,还能与其他数据结构结合,实现更复杂的功能。
比如,将配对后的数据直接转换为列表或字典,可以进一步方便数据的管理和检索。
1、转换为列表
creatures = ['白泽', '夔牛', '凤凰']
habitats = ['昆仑山', '不周山', '蓬莱岛']
# 将zip结果转换为列表
paired_list = list(zip(creatures, habitats))
print(paired_list)
输出结果:
[('白泽', '昆仑山'), ('夔牛', '不周山'), ('凤凰', '蓬莱岛')]
2、构建字典
当我们想要根据一种属性(如名字)快速查找另一种属性(如栖息地)时,将zip的结果直接转换为字典非常有用。
creatures = ['白泽', '夔牛', '凤凰']
habitats = ['昆仑山', '不周山', '蓬莱岛']
#使用zip和dict构造字典,以奇珍异兽名为键,栖息地为值
creature_habitat_dict = dict(zip(creatures, habitats))
print(creature_habitat_dict)
输出结果:
{'白泽': '昆仑山', '夔牛': '不周山', '凤凰': '蓬莱岛'}
这样,通过名字查询栖息地就变得异常简单,只需一行代码:print(creature_habitat_dict[‘白泽’])即可得到“昆仑山”。

4. zip的长度匹配规则
值得注意的是,当使用zip合并不同长度的序列时,最终生成的配对数量由最短的序列决定。
这意味着如果一个列表比其他列表短,多出来的元素会被忽略。
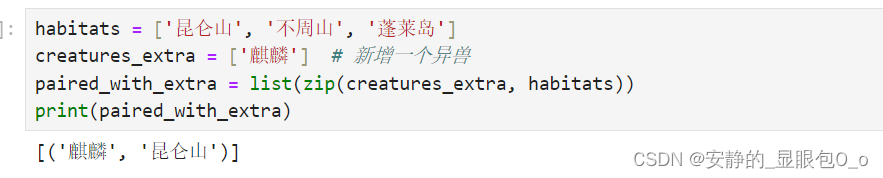
habitats = ['昆仑山', '不周山', '蓬莱岛']
creatures_extra = ['麒麟'] # 新增一个异兽
paired_with_extra = list(zip(creatures_extra, habitats))
print(paired_with_extra)
输出结果:
[('麒麟', '昆仑山')]
在这个例子中,尽管habitats列表中有三个元素,但由于creatures_extra只有一个元素,因此只产生了单个配对。
5. 实际应用
在实际工作中,zip能够极大地提升数据处理的效率,尤其是在数据分析、报表生成等领域。
比如,假设你正在处理一份销售数据,包括产品名称和对应的销售额,使用zip可以迅速将这些数据整合,进而进行排序、筛选或是转换为报表格式。
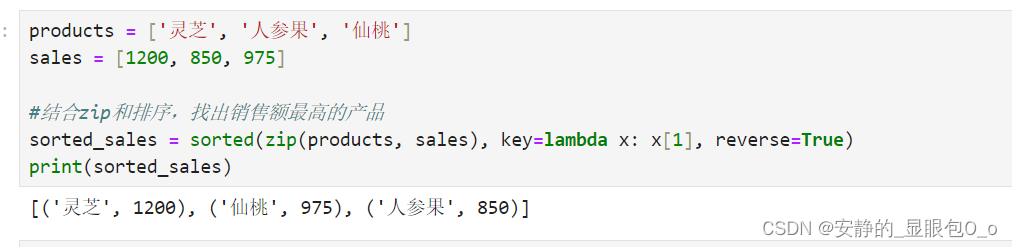
products = ['灵芝', '人参果', '仙桃']
sales = [1200, 850, 975]
#结合zip和排序,找出销售额最高的产品
sorted_sales = sorted(zip(products, sales), key=lambda x: x[1], reverse=True)
print(sorted_sales)
输出结果:
[('灵芝', 1200), ('仙桃', 975), ('人参果', 850)]
通过这样的方式,你不仅能够迅速识别出最畅销的产品,还能灵活地调整排序逻辑,满足不同的分析需求。