与其碌碌无为,不如兴风作浪。
虽然不是所有的系统都需要很多的并发编程技术,但是掌握常见的高并发秘籍,便能让我们的系统快起来,面对访问量的剧增从容应对。
接下来,为我们一起来看看常见的高并发技术有哪些。总结起来,主要包括缓存、限流、熔断降级、异步、池化、代码优化、JVM调优、预热、等。
缓存
主要包括本地缓存和分布式缓存。可以使用Redis和Caffeine等方式缓存数据,一般情况下分布式系统使用分布式缓存就可以了。对于高并发的系统,可以考虑多级缓存,但是要考虑内存以及数据一致性问题。
本地缓存:解决redis的热key问题和提升性能;
分布式缓存:解决缓存容量和提升性能。
本地缓存
虽然redis号称单节点能抗住10Wqps,但是开发过程中为了保险,会降低预期。那么如何发现这些热点key呢?可以在开发的时候凭业务经验估计,比如秒杀的商品信息。上线后,也可以随时在客户端进行收集。
Caffeine是基于java8实现的新一代缓存工具,缓存性能接近理论最优。可以看作是Guava Cache的增强版,功能上两者类似,不同的是Caffeine采用了一种结合LRU、LFU优点的算法:W-TinyLFU,在性能上有明显的优越性。
使用方式如下:
public class CaffeineCacheTest {
public static void main(String[] args) throws Exception {
//创建guava cache
Cache<String, String> loadingCache = Caffeine.newBuilder()
//cache的初始容量
.initialCapacity(5)
//cache最大缓存数
.maximumSize(10)
//设置写缓存后n秒钟过期
.expireAfterWrite(17, TimeUnit.SECONDS)
//设置读写缓存后n秒钟过期,实际很少用到,类似于expireAfterWrite
//.expireAfterAccess(17, TimeUnit.SECONDS)
.build();
String key = "key";
// 往缓存写数据
loadingCache.put(key, "value");
// 获取value的值,如果key不存在,获取value后再返回
String value = loadingCache.get(key, CaffeineCacheTest::getValueFromDB);
// 删除key
loadingCache.invalidate(key);
}
private static String getValueFromDB(String key) {
return "value";
}
}
分布式缓存
也就是引入redis中间件进行数据缓存。
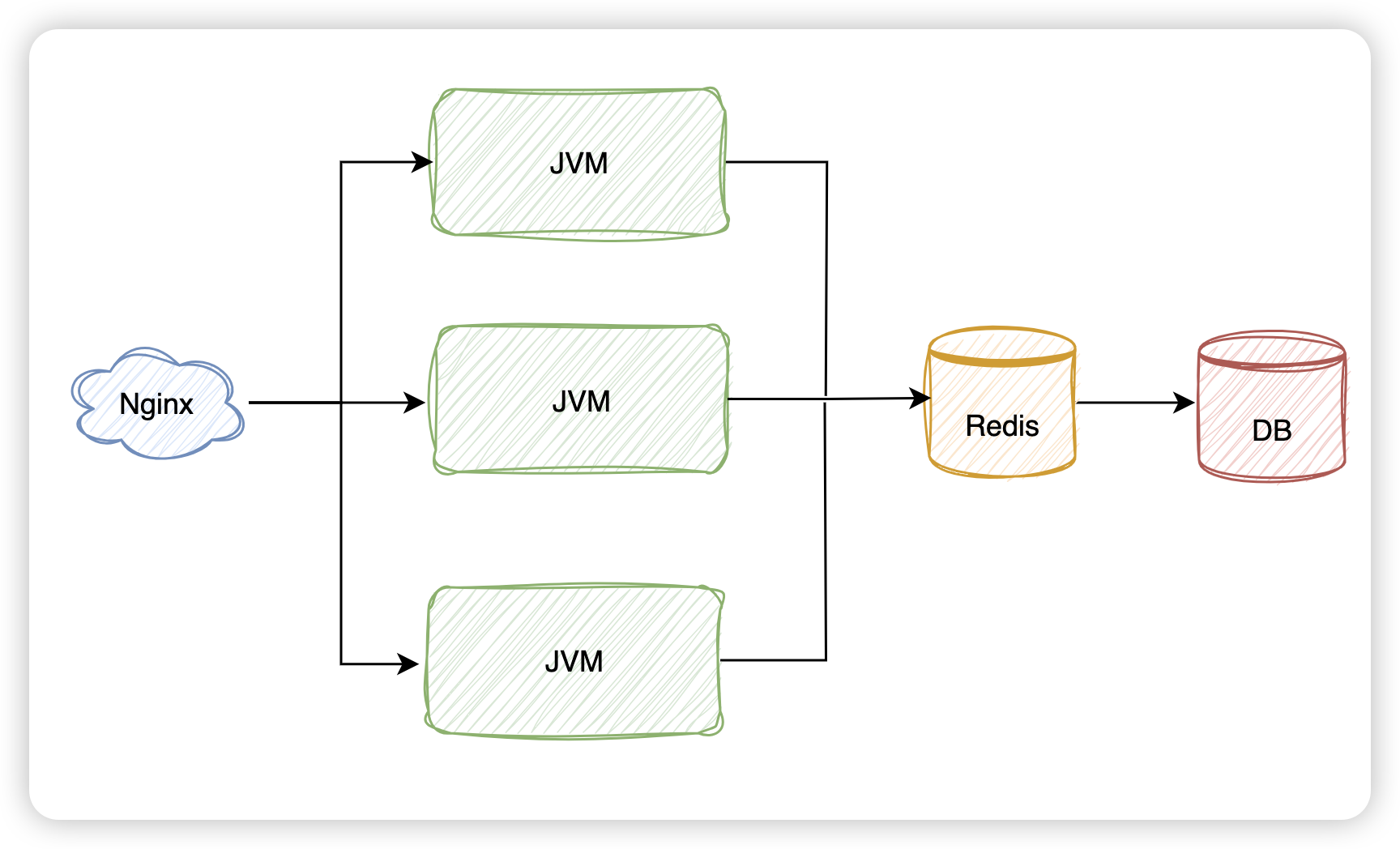
使用Spring Cache进行商品类目数据缓存:
/**
* 商品类目
*/
@DubboService
@CacheConfig(cacheNames = CACHE_NAME_CATEGORY)
@Slf4j
public class CategoryFacadeServiceImpl implements ICategoryFacadeService {
// 使用@Cacheable注解,它会将方法返回结果存储在注解指定的缓存中
@Override
@Cacheable
public List<CategoryResp> listAllCategory() throws ServiceException {
log.info("查询所有类目开始");
return allCategory;
}
// @CacheEvict 注解来表示删除一个、多个或所有的值,以刷新缓存
@Override
@Transactional(rollbackFor = Exception.class)
@CacheEvict(cacheNames = CACHE_NAME_CATEGORY, allEntries = true)
public Long saveAndUpdate(@NotNull CategoryReq req) throws ServiceException {
log.info("新增或修改类目开始CategoryReq{}", req);
return result;
}
@Override
@Transactional(rollbackFor = Exception.class)
@CacheEvict(cacheNames = CACHE_NAME_CATEGORY, allEntries = true)
public boolean deleteCategory(@NotNull Long id) throws ServiceException {
log.info("开始删除类目");
return flag&&mappingFlag;
}
}
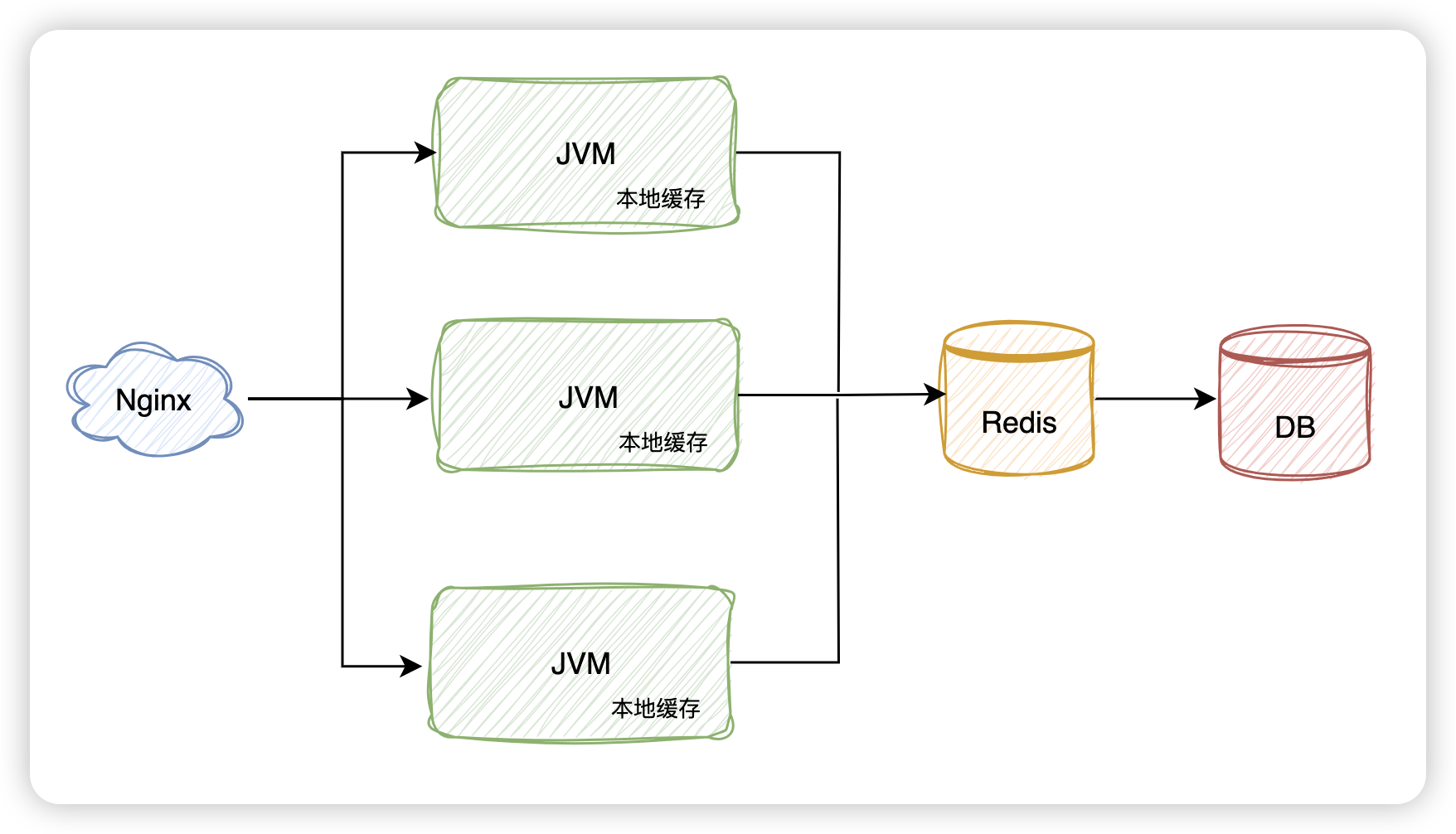
多级缓存
通过新增本地缓存,可用使得流量在应用层直接返回,避免进一步访问Redis。大大提高数据读取的效率,但是成本也是很高的。
- 内存要求:需要在应用服务器同于数据,需要提高应用服务器的内存;
- 数据一致性:需要保证多级缓存之间,各个本地缓存之间数据的一致性。
需要重具体的业务场景触发,兼顾以下三个方面考虑是否需要本地缓存:
- 并发量
- 内存情况
- 变更是否频繁
限流
限流是为了保护系统的可用性而做出的一种妥协,通过减低请求成功的数量,保证重要功能的可用。需要通过压测预估系统可承载的并发量。在系统资源紧张的情况下,保证系统的可用性。
可通过sentinel实现限流,经典算法包括令牌桶,漏桶,滑动时间窗口等。
熔断降级
熔断降级是分布式系统中常用的两种保护机制,旨在提高系统的稳定性和可用性。以下是关于熔断降级的详细解释:
熔断
定义:熔断类似于电路中的保险丝,当某个异常条件被触发时,直接熔断整个服务,防止系统因某个服务的故障而导致整体服务失败。
触发条件:熔断的触发条件通常与服务调用的失败率、请求超时等有关。例如,在Spring Cloud的Hystrix组件中,如果检测到10秒内请求的失败率超过50%,则触发熔断机制。
作用:熔断机制通过快速失败和快速恢复,防止在复杂分布式系统中出现级联故障,从而提高系统的整体弹性。
降级
定义:降级是指在系统压力剧增或出现故障时,根据当前业务情况及流量,对一些服务和页面进行有策略的降级,以此缓解服务器资源的压力,保证核心业务的正常运行。
触发条件:降级的触发条件通常包括服务超时、失败次数、故障、限流等。在Hystrix中,降级可以在方法抛出异常、方法调用超时、熔断器开启拦截调用、线程池或队列或信号量已满等情况下触发。
目的:降级的目的是在系统出现问题时,仍能保证有限功能可用,提供一种退而求其次的解决方案。例如,在电商交易系统中,当系统负载过高时,可以开启降级功能,优先保证支付功能可用,而其他非核心功能如评论、物流、商品介绍等可以暂时关闭。
熔断与降级的区别
概念不同:熔断是当服务出现故障时,直接熔断整个服务,防止系统因某个服务的故障而导致整体服务失败;而降级是在系统压力剧增或出现故障时,通过关闭部分非核心功能来保证核心业务的正常运行。
触发条件不同:熔断的触发条件通常与服务调用的失败率、请求超时等有关;而降级的触发条件则包括服务超时、失败次数、故障、限流等。
归属关系不同:熔断时可能会调用降级机制,因为熔断是从全局出发,为了保证系统稳定性而停用服务;而降级是退而求其次,提供一种保底的解决方案。
常见的降级类型包括:大促非核心的接口降级;日志降级等。
异步
主要涉及到如何让程序在执行某些可能耗时的操作时,不会阻塞主线程,从而提高程序的响应性和性能。主要策略包括多线程和消息队列等。
系统解耦:对于不需要客户感知结果的部分,可通过消息的方式完成后续处理,完成后通知客户结果。不需要阻塞客户一直等待。
提升性能:对于一些查询操作,可能设置多个独立的数据内容,这种情况可以使用CompletableFuture进行一步任务编排,提升查询效率。
下面是通过任务编排实现商品属性查询的案例:
CompletableFuture<String> futureImg = CompletableFuture.supplyAsync(() -> {
System.out.println("查询商品的图片信息");
return "hello.jpg";
});
CompletableFuture<String> futureAttr = CompletableFuture.supplyAsync(() -> {
System.out.println("查询商品的属性");
return "黑色";
});
CompletableFuture<String> futureDesc = CompletableFuture.supplyAsync(() -> {
try { TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) { e.printStackTrace(); }
System.out.println("查询商品介绍");
return "华为";
});
// 等待全部执行完
// CompletableFuture<Void> allOf = CompletableFuture.allOf(futureImg, futureAttr, futureDesc);
// allOf.get();
// 只需要有一个执行完
CompletableFuture<Object> anyOf = CompletableFuture.anyOf(futureImg, futureAttr, futureDesc);
anyOf.get();
System.out.println("main....end....." + anyOf.get());
池化技术
池化技术主要用于避免频繁创建和销毁昂贵资源(如数据库连接、线程、大对象等)所带来的性能开销。通过预先创建一定数量的资源并维护在一个池中,当需要时从池中获取资源使用,使用完毕后归还到池中而不是直接销毁,可以显著提高应用程序的效率和响应速度。
下面是一些典型的Java池化技术实例:
- 数据库连接池:
- 实现库:Apache DBCP, C3P0, HikariCP, Tomcat JDBC Pool等。
- 作用:管理数据库连接,避免了每次数据库操作都新建和销毁连接的开销。
- 线程池:
- 实现库:java.util.concurrent.ExecutorService接口及其实现类,如ThreadPoolExecutor。
- 作用:预先创建一定数量的线程,将任务提交给线程池处理,提高了并发处理能力,同时也限制了系统创建过多线程导致的资源耗尽风险。
- 对象池:
- 实现库:Apache Commons Pool。
- 作用:适用于任何需要重用的对象,如大对象、网络连接、图形对象等,减少垃圾回收压力和创建对象的成本。
- 缓冲池(Buffer Pool):
- 在某些IO密集型应用中,如NIO(非阻塞I/O)编程,通过重用缓冲区可以提升读写效率。
使用池化技术的关键在于合理配置池的大小,过大可能导致资源浪费,过小则可能因为资源争抢而影响性能。此外,池化技术还需要考虑资源的分配与回收策略、超时处理、异常处理等机制,确保资源的有效管理和利用。
代码优化
通过优化代码逻辑,减少调用链路,减少数据库查询次数,提前校验流程。
JVM调优
主要是系统根据业务情况和机器配置设置合理的JVM参数。
预热
通过执行定时任务等方式提前将数据加载到缓存。通过预热,能够避免缓存刚开始没有数据时全量请求查数据库的行为。
如果秒杀要走正常的加入购物车流程,然后去来锁库存,最终去支付,这样整个流程太慢了,在高并发系统里边肯定会出现整个级联崩溃的情况。我们应该先做到预热库存,比如现在要秒杀的商品,数量有400件,我们给 redis 里面存一个 400 的信号量,想要秒杀的人进来之后,必须要先拿到信号量,这一块我们会对 redis 的信号量进行快速扣减,直接扣减1个数,所以无论有多少请求进来,即使有百万请求,最终也只有 400个人能拿到这个信号量的值。然后我们会将这 400 个人放行给我们后台的集群系统,这些请求即使走正常的下单逻辑,系统也不会出现什么问题。
如果是单台机器,也可以使用一些简单的办法实现,但是不太灵活。比如:
监听启动事件
- 使用ApplicationListener监听ContextRefreshEvent或ApplicationReadyEvent等应用上下文初始化完成事件,在这些事件触发后执行数据加载的操作。
@Component
public class CacheWarmer implements ApplicationListener<ContextRefreshedEvent> {
@Override
public void onApplicationEvent(ContextRefreshedEvent event) {
// 执行缓存预热业务...
cacheManager.put("key", dataList);
}
}
@Component
public class CacheWarmer implements ApplicationListener<ApplicationReadyEvent> {
@Override
public void onApplicationEvent(ApplicationReadyEvent event) {
// 执行缓存预热业务...
cacheManager.put("key", dataList);
}
}
PostConstuct注解
该注解是Java jdk提供的注解,而不是Spring框架提供的。该注解的功能是当依赖注入完成后用于执行初始化的方法,并且只会被执行一次
@Component
public class CachePreloader {
@Autowired
private YourCacheManager cacheManager;
// 注解
@PostConstruct
public void preloadCache() {
// 执行缓存预热业务...
cacheManager.put("key", dataList);
}
}
实现InitializingBean接口
InitializingBean是Spring提供的拓展性接口,为bean提供了属性初始化后的处理方法,它唯一的方法便是afterPropertiesSet,凡是实现该接口的类,在bean属性初始化后都会执行该方法。
@Component
public class CachePreloader implements InitializingBean {
@Autowired
private YourCacheManager cacheManager;
@Override
public void afterPropertiesSet() throws Exception {
// 执行缓存预热业务...
cacheManager.put("key", dataList);
}
}
hi,你好,我是松语。985软件工程研究生毕业,一个工作三年的程序员。
这里有:
- 技术分享,包括编程技巧和踩坑记录等;
- 求职经验,校招、副业、社招跳槽经验等;
- 诗和远方。
亲爱的你,切莫辜负有梦想的自己,萍水相逢的感情,以及良辰美景好时光。