论文名称:High-Resolution Image Synthesis with Latent Diffusion Models
发表时间:CVPR2022
作者及组织:Robin Rombach, Andreas Blattmann, Dominik Lorenz,Patrick Esser和 Bjorn Ommer, 来自Ludwig Maximilian University of Munich & IWR, Heidelberg University, Germany。
开源地址:https://github.com/CompVis/latent-diffusion
前言
本文就是VQGAN和DDPM的结合。在图像的2D特征向量上做加噪去噪,从而降低DDPM在全像素空间上生成造成计算量大的问题。而且在隐变量上训练DDPM在一定程度上并不会损失生成的细节。
1、方法
以VQGAN为例,第一个阶段是感知压缩阶段,旨在去掉无关的像素细节;第二个阶段是语义压缩阶段,让自回归模型来预测图像的语义。而本文就是找到两个压缩阶段之间的一个trade-off。
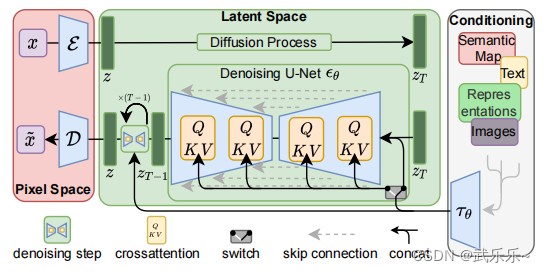
1.1.感知压缩阶段
该阶段用T-UNet来提取图像特征向量:
z
=
E
(
x
)
z = E(x)
z=E(x) ,其中
z
z
z 并不像VQGAN中一样是经过codebook后的特征向量,而是未经过codebook,因为作者认为此时
z
z
z 天然具有一定归纳偏置 ,有利于后续生成。而压缩的比例用变量 $f $ 进行表示(比如f=2就表示下采样2倍,f=1就是原始像素空间)。
解码器为
x
^
=
D
(
z
)
\hat x = D(z)
x^=D(z) 。
为了防止隐空间的特征向量有高方差,加了两个正则化,KL-reg和VQ-reg,分别对应VAE和VQGAN中的两种损失函数。
1.2.LDM
DM损失函数为:
L
D
M
=
E
x
,
ϵ
N
(
0
,
1
)
,
t
[
∣
∣
ϵ
−
ϵ
θ
(
x
t
,
t
)
∣
∣
2
2
]
\begin{equation} L_{DM}= E_{x,\epsilon~N(0,1),t} [||\epsilon-\epsilon_\theta(x_t,t)||_2^2] \tag{1} \end{equation}
LDM=Ex,ϵ N(0,1),t[∣∣ϵ−ϵθ(xt,t)∣∣22](1)
LDM的损失函数就是将采样样本x变成了隐空间
z
=
E
(
x
)
z=E(x)
z=E(x) :
L
D
M
=
E
E
(
x
)
,
ϵ
N
(
0
,
1
)
,
t
[
∣
∣
ϵ
−
ϵ
θ
(
x
t
,
t
)
∣
∣
2
2
]
\begin{equation} L_{DM}= E_{E(x),\epsilon~N(0,1),t} [||\epsilon-\epsilon_\theta(x_t,t)||_2^2] \tag{2} \end{equation}
LDM=EE(x),ϵ N(0,1),t[∣∣ϵ−ϵθ(xt,t)∣∣22](2)
而如果加一些条件(文本,layout,mask…)则损失函数为:
L
L
D
M
=
E
E
(
x
)
,
y
,
ϵ
N
(
0
,
1
)
,
t
[
∣
∣
ϵ
−
ϵ
θ
(
x
t
,
t
,
τ
θ
(
y
)
)
∣
∣
2
2
]
\begin{equation} L_{LDM}= E_{E(x),y,\epsilon~N(0,1),t} [||\epsilon-\epsilon_\theta(x_t,t, \tau_\theta(y))||_2^2] \tag{3} \end{equation}
LLDM=EE(x),y,ϵ N(0,1),t[∣∣ϵ−ϵθ(xt,t,τθ(y))∣∣22](3)
其中条件注入用了CrossAttn。
2、实验
2.1. class conditional
数据集:ImageNet和Celeb-A数据集。
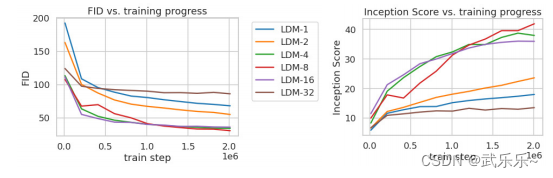
下图表示LDM-4/8收敛速度快,且生成图像的保真度高。
下图表示相同采样步数,LDM-8吞吐量高且生成图像逼真。
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
2.2. ConditionalLDM
Text2img训了一个1.45B的模型在LAION-400M。下图说明 class free guide 的trick非常有用,但训练资源加倍。
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
2.3. rescale
在AE和DM训练中,为了防止隐空间尺度任意变换,对
z
z
z 做了一下正则化,如下图所示,若不做正则化,生成图像细节不足。
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
思考:
LDM还能完成好多其余工作:比如text2img,img inpaint, mask2img, super等。是后续生成模型的基本组件。



![Java [数据结构] Deque与Queue](https://img-blog.csdnimg.cn/img_convert/beb760af9cc815cd3493733307071102.png)