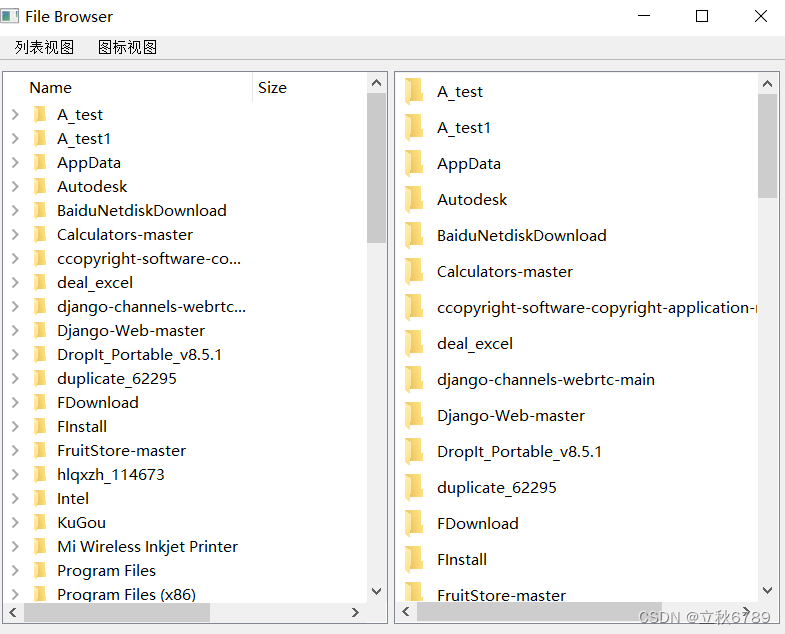
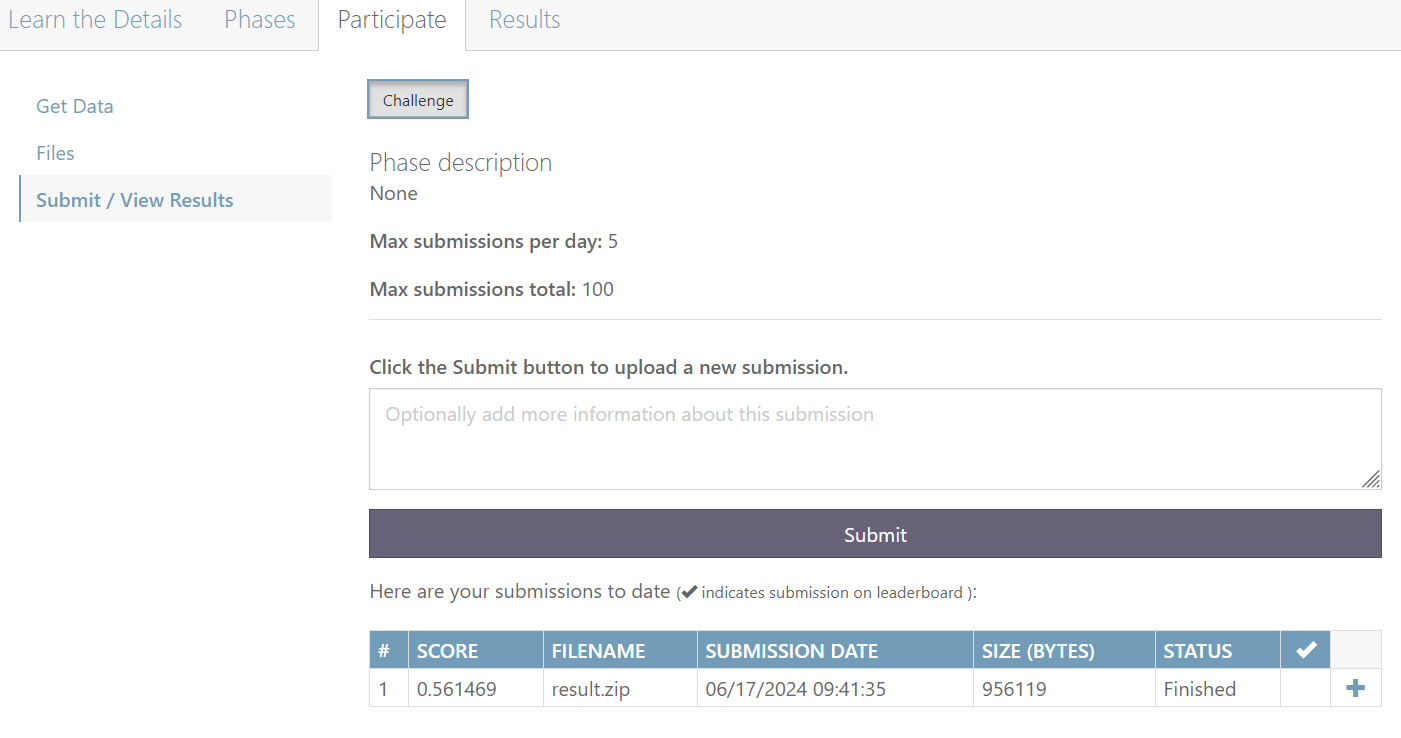
这里是基于encoder-decoder和注意力机制 模型代码,sigmoid对资产进行调仓。训练直接使用收益作为优化函数
import torch
import torch.nn as nn
from dataloader import create_dataloaders
class Attention(nn.Module):
def __init__(self, hidden_dim):
super(Attention, self).__init__()
self.attn = nn.Linear(hidden_dim * 2, hidden_dim)
self.v = nn.Parameter(torch.rand(hidden_dim))
def forward(self, hidden, encoder_outputs):
"""
参数:
hidden (torch.Tensor): 解码器的隐藏状态,形状为 (batch_size, 1, hidden_dim)
encoder_outputs (torch.Tensor): 编码器的输出序列,形状为 (batch_size, seq_len, hidden_dim)
返回:
attention_weights (torch.Tensor): 注意力权重,形状为 (batch_size, seq_len)
"""
# 获取时间步数
timestep = encoder_outputs.size(1) # seq_len
# 重复hidden,形状为 (batch_size, seq_len, hidden_dim)
h = hidden.repeat(1, timestep, 1) # h: (batch_size, seq_len, hidden_dim)
# 拼接h和encoder_outputs,形状为 (batch_size, seq_len, hidden_dim * 2)
energy = torch.tanh(self.attn(torch.cat((h, encoder_outputs), dim=2))) # energy: (batch_size, seq_len, hidden_dim)
# 转置energy以便进行批次矩阵乘法,形状为 (batch_size, hidden_dim, seq_len)
energy = energy.transpose(1, 2) # energy: (batch_size, hidden_dim, seq_len)
# 重复v参数,形状为 (batch_size, 1, hidden_dim)
v = self.v.repeat(encoder_outputs.size(0), 1).unsqueeze(1) # v: (batch_size, 1, hidden_dim)