AI圈最近又发生了啥新鲜事?
该栏目以周更频率总结国内外前沿AI动态,感兴趣的可以点击订阅合集以及时收到最新推送
B站CEO陈睿:每月超过8000万用户在平台看AI内容
B站15周年庆上B站董事长兼CEO陈睿发表演讲,公布了B站上AI的内容消费趋势。2023年,B站AI相关内容的日均视频播放量同比增长超过80%,每个月有超过8000万用户在B站看AI,AI相关内容消费人群中有60%为00后
https://www.jiemian.com/article/11336481.html
近八成高考生使用百度AI志愿助手
全国超1300万考生陆续进入高考填报志愿环节,据百度官方发布的数据,仅6月25日一天,就有超过1000万用户使用了百度AI志愿助手,辅助填报志愿。也就是说,近八成的考生使用了AI志愿填报服务
https://www.lieyunpro.com/archives/493529
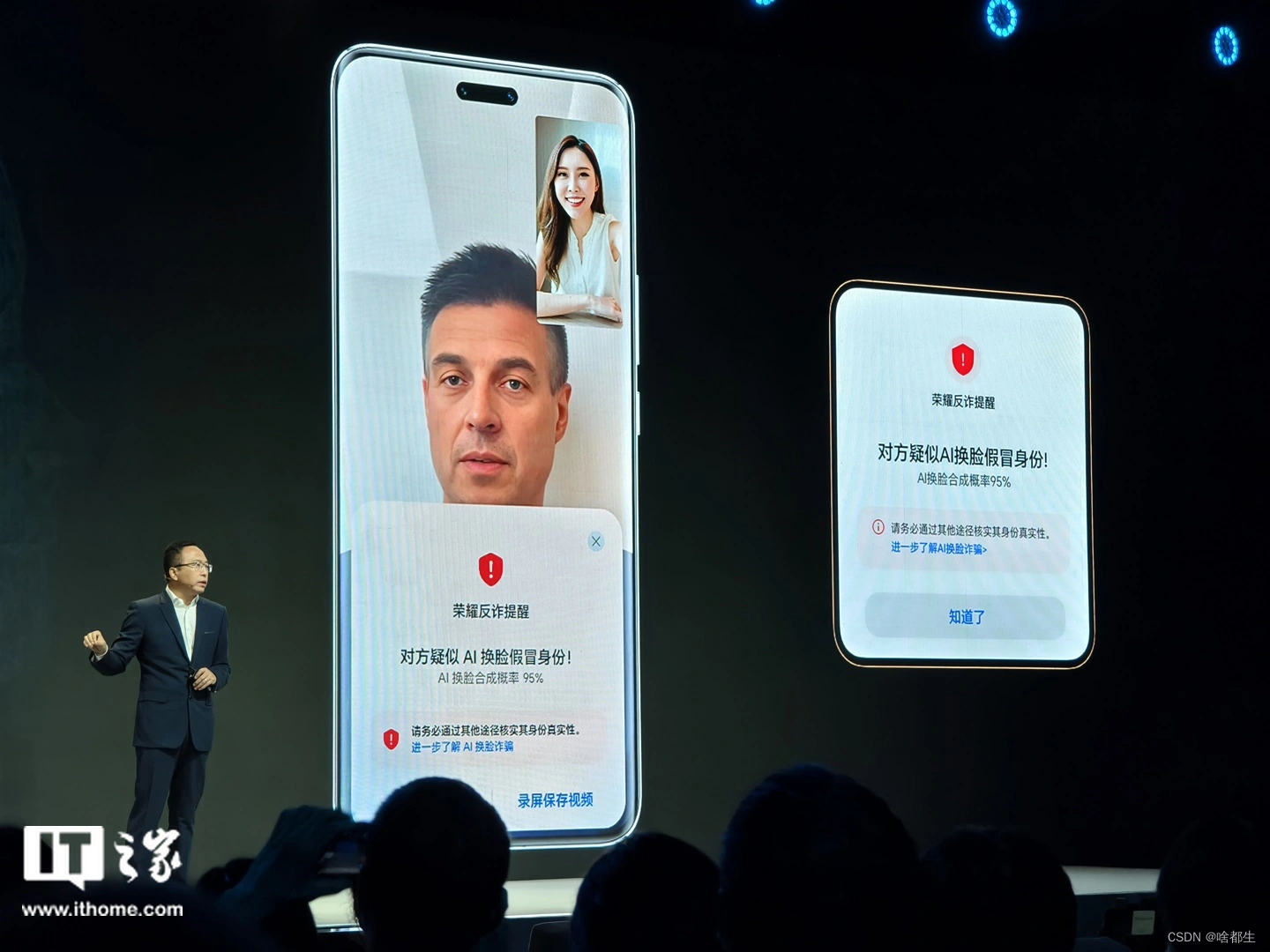
荣耀发布手机行业首个端侧AI反诈检测技术
上海世界移动通信大会(2024MWC上海)期间,荣耀终端发布了手机行业首个端侧AI反诈检测技术。据介绍,该技术能够自主识别用户视频通话中的画面要素。若检测到视频中存在AI换脸,将会向用户发出风险提醒
https://www.ithome.com/0/777/798.htm
文心一言4.0 Turbo发布
百度正式发布了一款新模型文心一言4.0 Turbo,新模型已正式在网页以收费形式向用户开放,并同期通过千帆大模型平台对开发者开放API。根据官网披露的数据,文心一言4.0 Turbo进一步强化检索能力,上下文输入的长度从4.0版的2K tokens升级到了128K tokens,可同时阅读100个文件/网址,AI生图的分辨率也从512x512升级至1024x1024
https://new.qq.com/rain/a/20240628A06TTP00
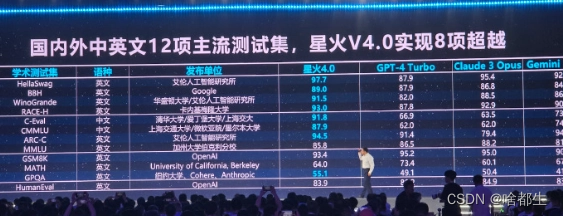
科大讯飞发布讯飞星火大模型 V4.0,称整体超越 GPT-4 Turbo
在讯飞星火 V4.0 发布会上,科大讯飞发布了讯飞星火大模型 V4.0,以及在医疗、教育、商业等多个领域的人工智能应用。在国内外中英文 12 项主流测试集中,星火 V4.0 在8个测试集中排名第一,领先国内大模型,并在文本生成、语言理解、知识问答、逻辑推理、数学能力等方面实现对 GPT-4 Turbo 的整体超越
https://www.ithome.com/0/778/092.htm
《Python机器学习》作者新作:从头开始构建大型语言模型
知名机器学习和AI研究员Sebastian Raschka继《Python机器学习》后再出新作——《Build a Large Language Model (From Scratch)》,全面解析了大型语言模型(LLM)的构建过程,从创建到训练和调整一应俱全,此外,他还在GitHub上公开了与该书配套的代码库。
https://mp.weixin.qq.com/s/2eCzTVpZJYFZD5cAT3ju4g
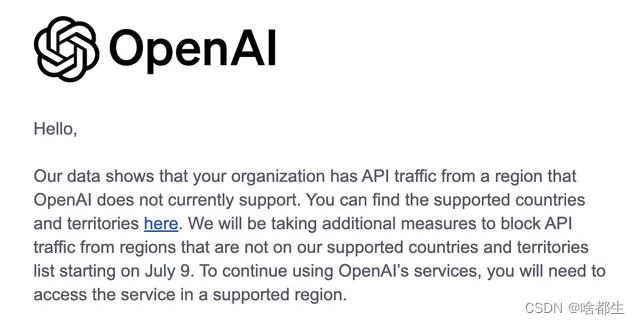
OpenAl将封杀来自非支持国家和地区的API流量
OpenAl宣布为了维护服务质量和安全性,将采取额外措施来限制来自当前不支持的国家和地区的API流量。据官方推送的邮件通知中明确指出,自7月9日起,OpenAI将开始阻止来自非支持国家和地区的API流量。受影响组织若希望继续使用OpenAI的服务,必须在其支持的国家或地区内访问
https://mp.weixin.qq.com/s/0_sQCEmiaMptSDxHTWmPLQ
OpenAI 推出新模型 CriticGPT,用于检测 GPT 生成代码中的错误
OpenAI 发布了一个名为 CriticGPT 的新型人工智能模型。该模型基于 GPT-4 构建,专门用于审查和识别大型语言模型(如 ChatGPT)生成的代码中的错误。通过人类反馈强化学习(RLHF)技术,CriticGPT 提高了代码审查的准确性和效率,能够识别并解释 AI 输出中的潜在问题,从而帮助提升代码的质量和安全性

https://openai.com/index/finding-gpt4s-mistakes-with-gpt-4
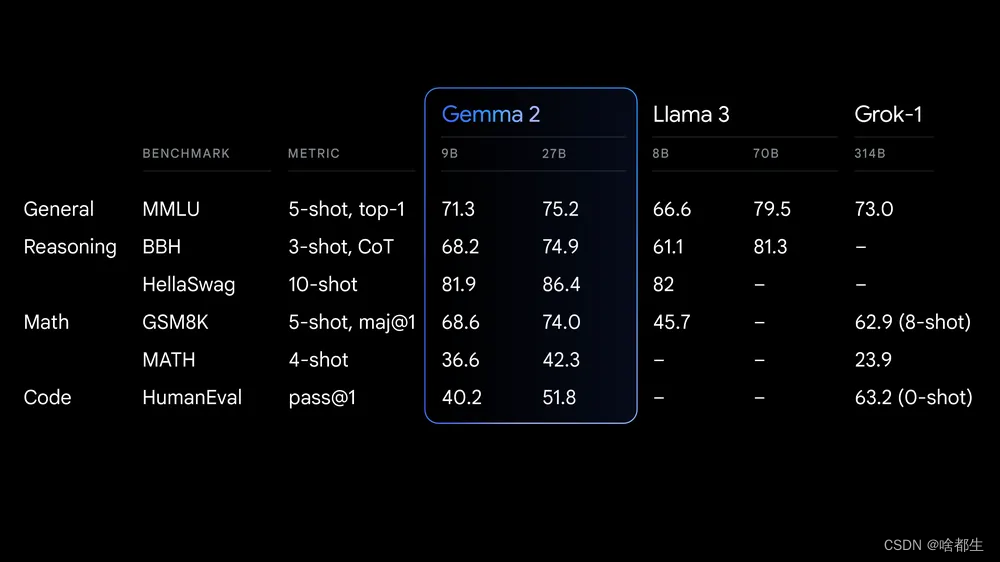
谷歌DeepMind发布全新开源AI模型Gemma 2
谷歌DeepMind推出了最新的开源人工智能模型Gemma 2,提供90亿(9B)和270亿(27B)两种参数版本。27B模型使用了13万亿tokens进行训练,而9B模型则使用了8万亿tokens。两者均支持8192上下文窗口,并可在Google AI Studio中使用。即将发布的2.6亿参数(2.6B)模型则小巧到可以在手机上本地运行
https://blog.google/technology/developers/google-gemma-2/
谢赛宁 Yann LeCun 团队发布开源多模态大模型 Cambrian-1
纽约大学谢赛宁和 Yann Lecun 团队最新开发了 Cambrian-1 多模态大模型,一个完全开放的项目,专注于视觉表征学习,并探索多模态大型语言模型(MLLM)的视觉中心能力。该项目旨在将研究焦点从扩大语言模型规模转移到增强视觉表征上,以促进多模态理解的稳健性
https://mp.weixin.qq.com/s/dYEO67z6QmnIgDAAJjWRkg
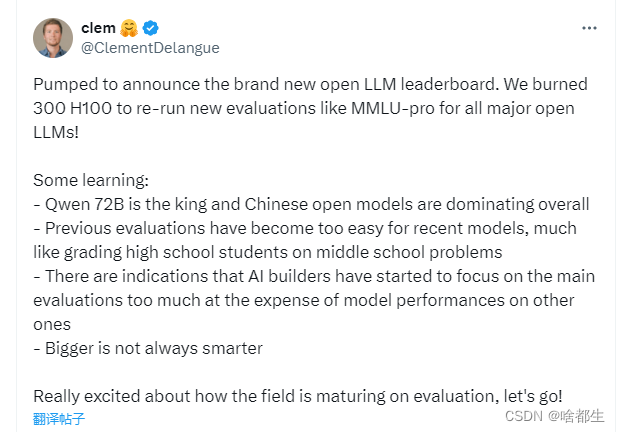
Hugging Face CEO:阿里Qwen-2成全球开源大模型排行榜第一,中国处于领导地位
Hugging Face的CEO在社交平台宣布,阿里最新开源的Qwen2-72B指令微调版本,成为开源模型排行榜第一名。他表示,为了提供全新的开源大模型排行榜,使用了300块H100对目前全球100多个主流开源大模型,例如,Qwen2、Llama-3、mixtral、Phi-3等,在BBH、MUSR、MMLU-PRO、GPQA等基准测试集上进行了全新评估。结果显示,阿里开源的Qwen-2 72B力压科技、社交巨头Meta的Llama-3、法国创企Mistral Al的Mixtral成为新的王者,中国在全球开源大模型领域处于领导地位
https://wallstreetcn.com/livenews/2743987