目录
搭建hadoop
下载hadoop
JAVA
下载bin
windows
改环境变量
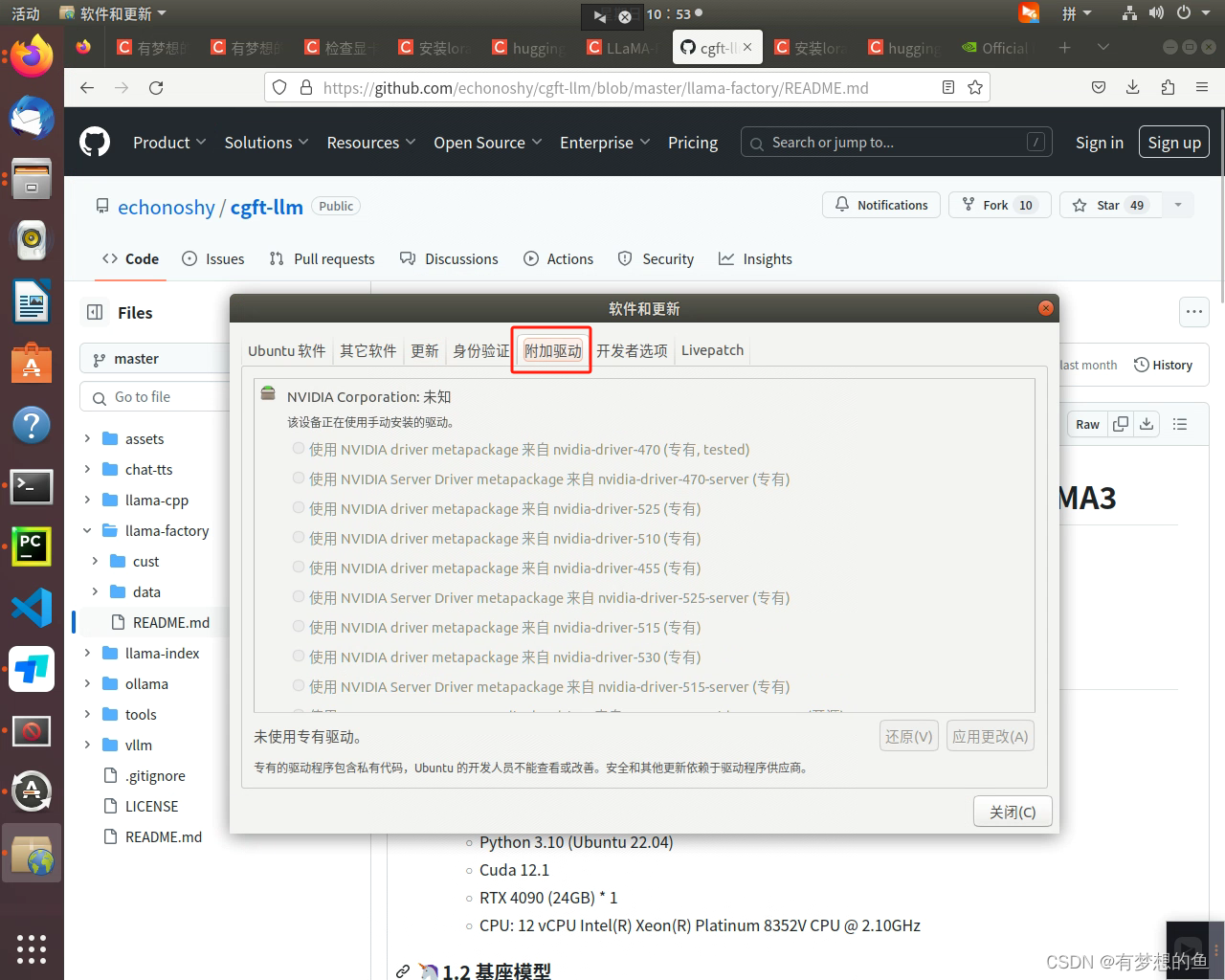
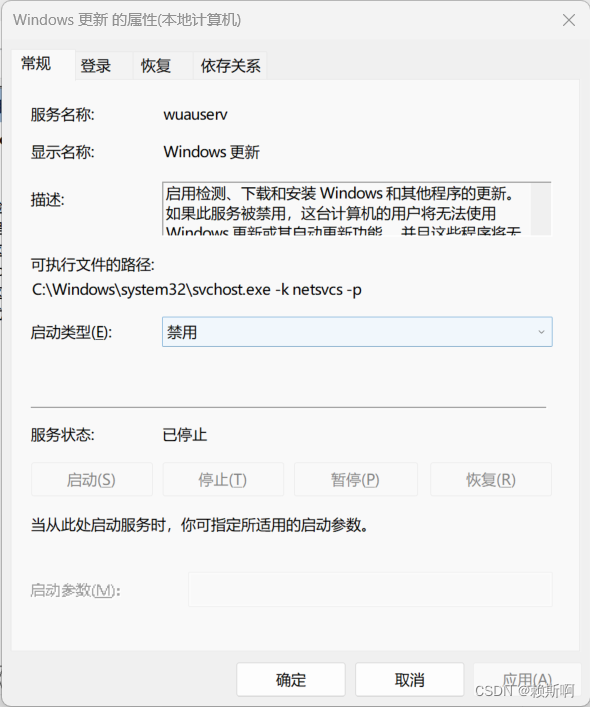
将winutils.exe和hadoop.dll放到C:\Windows\System32下,然后重启
修改配置
vim core-site.xml
vim hdfs-site.xml
hadoop-env.sh
mapred-site.xml
yarn-site.xml
格式化命令
启动集群
启动命令
编辑
web管理页面
查看示例
hadoop
Hadoop是什么
Hadoop的优势
Hadoop的组成
三个组件协作关系
hadoop生态圈
hdfs
hdfs是什么
shell操作命令
创建目录
上传文件夹
上传模糊匹配的命令
查看文件
查看文件内容
下载文件
删除
拷贝
hdfs架构图
HDFS 块(Block)
NameNode:
DataNode:
Client:
SecondaryNameNode:
checkpoint
hdfs持久化
NameNode
fsimage
Edits
生成fsimage和edits场景
安全模式
什么是安全模式
进入安全模式的三种情况
HDFS写原理
HDFS读原理
hdfs集群
心跳机制
hdfs优缺点
HDFS优点:
HDFS劣势:
MapReduce
什么是MapReduce
流程
架构图
示例
Yarn
什么是yarn
架构图
Yarn工作流程
Yarn作业提交全过程
作业提交
作业初始化
任务分配
任务运行
进度和状态更新
作业完成
MR任务执行
Yarn调度器
FIFO调度器
容量调度器(Capacity Scheduler)
公平调度器(Fair Scheduler)
与容量调度器对比
公平调度器缺额
公平调度器策略
参考文章
hadoop官网
https://hadoop.apache.org/
搭建hadoop
下载hadoop
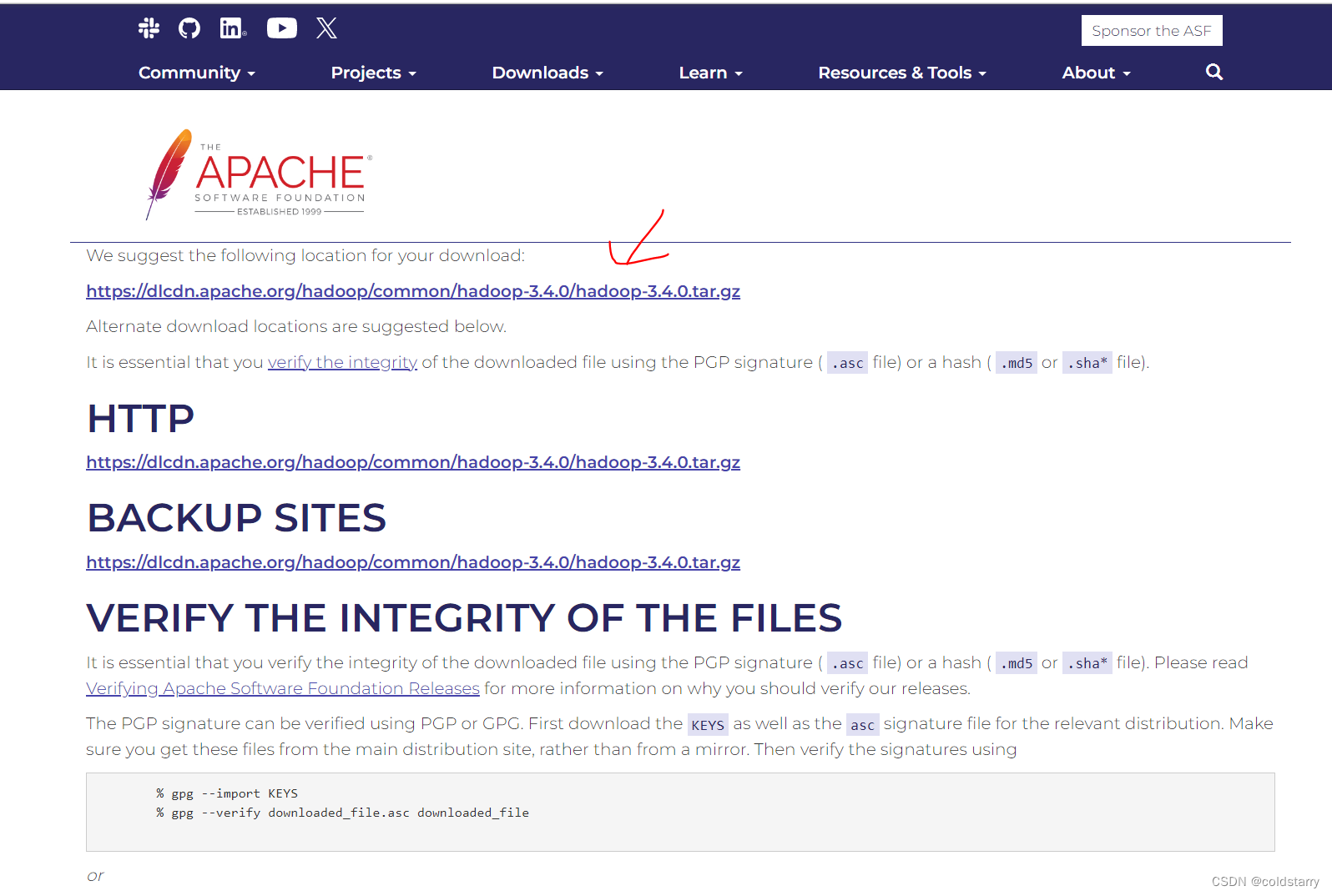
下载后的目录作用

JAVA
需要安装java,并且保证路径没有空格
下载bin
windows要去 https://gitee.com/nkuhyx/winutils
下载bin,并且将bin的内容拷贝到hadoop的bin文件夹中
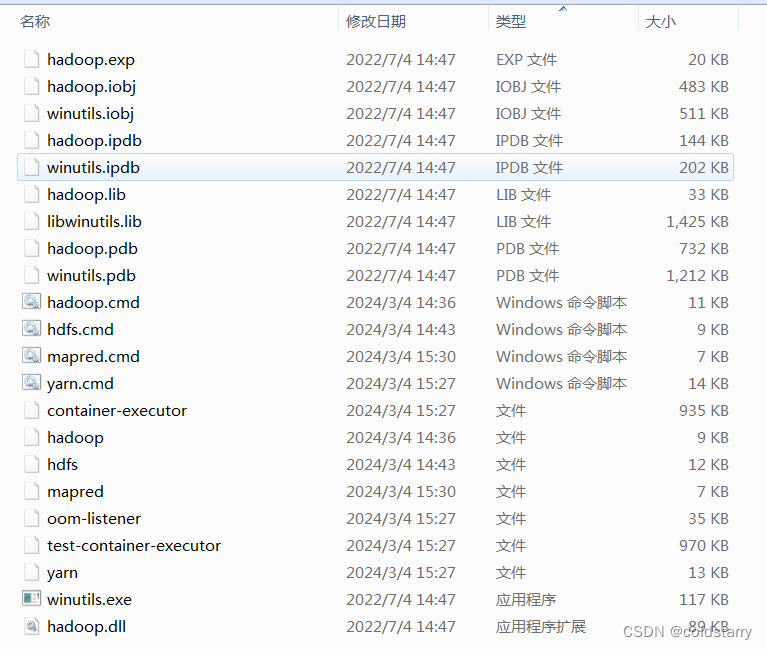
windows
最好别用windows搭,贼坑,我都搭建完了,运行mapreduce的词频统计,还是失败(应该是权限问题,找了很多资料也解决不了),基于hadoop的hive也会失败(跟词频统计失败相同的报错),有空搭建个docker的
改环境变量
新增 HADOOP_HOME hadoop路径 xxx\hadoop-3.4.0
path后面新增 ;%HADOOP_HOME%\bin;%HADOOP_HOME%\sbin;
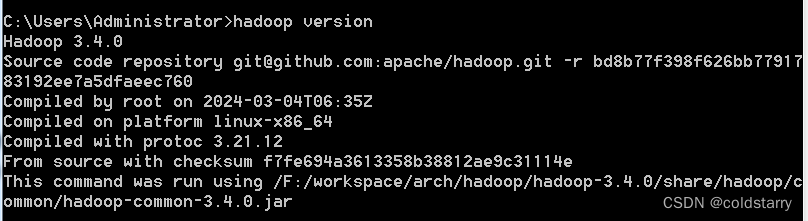
看一下安装完成
hadoop version
将winutils.exe和hadoop.dll放到C:\Windows\System32下,然后重启
F:\workspace\arch\hadoop\hadoop-3.4.0\share\hadoop\mapreduce>hadoop jar hadoop-m
apreduce-examples-3.4.0.jar pi 1 1
修改配置
vim core-site.xml
core-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:9820</value>
</property><!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>F:/workspace/arch/hadoop/hadoop-3.4.0/data</value>
</property></configuration>
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>localhost:9870</value>
</property>
<!-- 2nn wen段访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>localhost:9868</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>${hadoop.tmp.dir}/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>${hadoop.tmp.dir}/dfs/data</value>
</property></configuration>
hadoop-env.sh

我的配置
export JAVA_HOME=F:\NoMoving\jdk8
hadoop-env.cmd
mapred-site.xml
<configuration>
<!--设置MR程序默认运行模式:YARN集群模式 local本地模式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--MR程序历史服务地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>localhost:10020</value>
</property>
<!--MR程序历史服务器web端地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>localhost:19888</value>
</property>
<!---->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!---->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!---->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property></configuration>
yarn-site.xml
<configuration>
<!--设置YARN集群主角色运行机器位置-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<!---->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--是否对容器实施物理内存限制-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--开启日志聚集-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--设置yare历史服务器地址-->
<property>
<name>yarn.log.server.url</name>
<value>http://localhost:1988/jobnistory/logs</value>
</property>
</configuration>
格式化命令
在hadoop\hadoop-3.4.0\bin中,运行命令
hdfs namenode -format
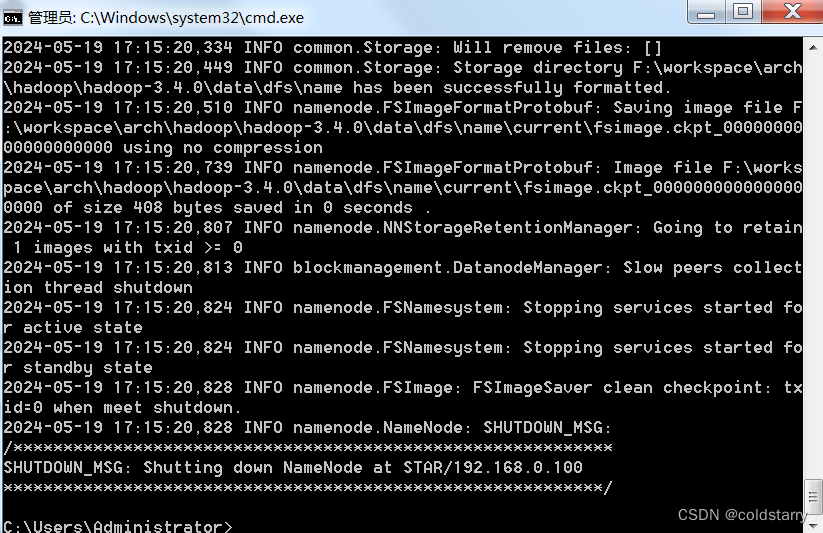
自动生成了这俩文件夹,注意,data文件夹不可以自己先创建好,要让程序自动创建

启动集群
启动命令
在hadoop\hadoop-3.4.0\sbin文件夹中运行命令
start-dfs.cmd
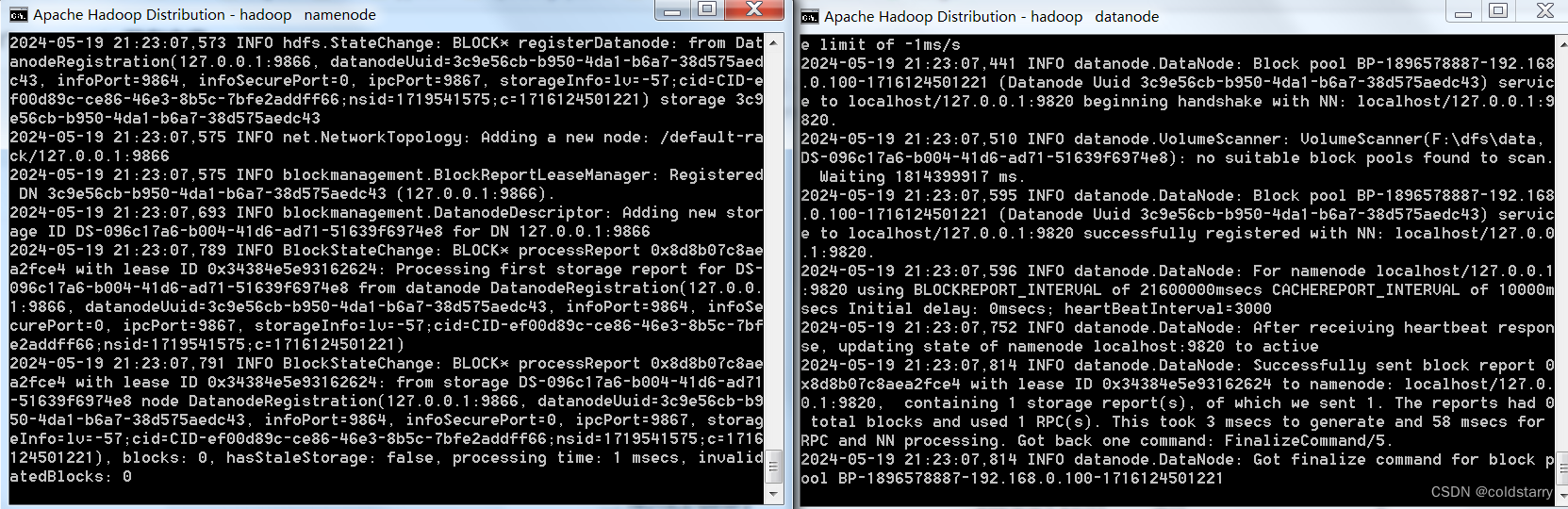
jps看看状态
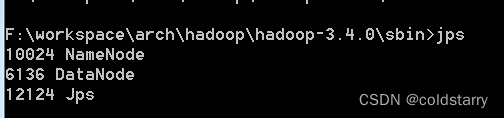
全部启动
start-all.sh
stop-all.sh
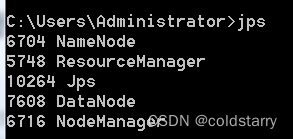
web管理页面
打开网页
http://localhost:9870/
yarn页面
http://localhost:8088/
查看示例
试验一下,使用hadoop自带的功能
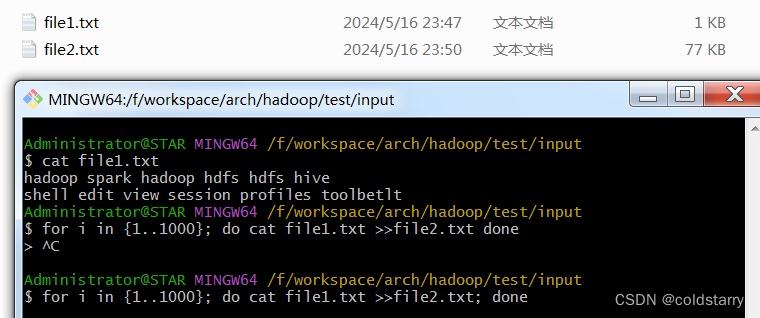
在input的文件夹下,创建file1.txt文件,内容是
hadoop spark hadoop hdfs hdfs hive
shell edit view session profiles toolbetlt
在shell中用命令把这个文件的内容做多次重复
for i in {1..1000}; do cat file1.txt >>file2.txt; done
将input上传到hdfs中

看一下上传成功了没

hadoop
Hadoop是什么
- Hadoop是一个由Apache基金会所开发的分布式系统基础架构
- 主要解决海量数据的存储和海量数据的分析计算问题
- 通常Hadoop是指一个更广泛的概念–Hadoop生态圈
Hadoop的优势
- 高可靠性:Hadoop底层维护了多个数据副本,所以即使Hadoop某个计算元素存储出现故障,也不会导致数据的丢失
- 高扩展性:在集群运行间动态增加服务器,可方便地扩展数以千计的节点
- 高效性:在MapReduce思想下,Hadoop是并行工作的,以加快任务处理速度。
- 高容错性:能够自动将失败的任务重新分配
Hadoop的组成
- 在Hadoop1.x时代,Hadoop中的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大
- 在Hadoop2.x时代,增加了Yarn。Yarn只负责资源的调度,MapReduce只负责运算,降低了耦合度
- Hadoop3.x在组成上没有变化
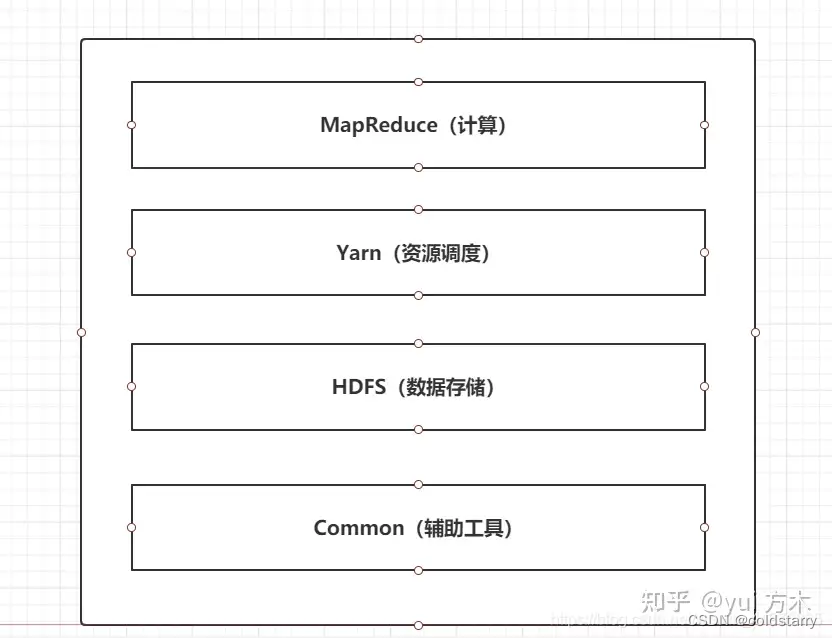
三个组件协作关系

hadoop生态圈
hdfs
hdfs是什么
Hadoop Distributed File System(简称 HDFS)是一个分布式文件系统,是 Hadoop 的核心组件之一。它能够将大规模数据存储到多个服务器集群上,并提供数据访问服务。
shell操作命令
创建目录

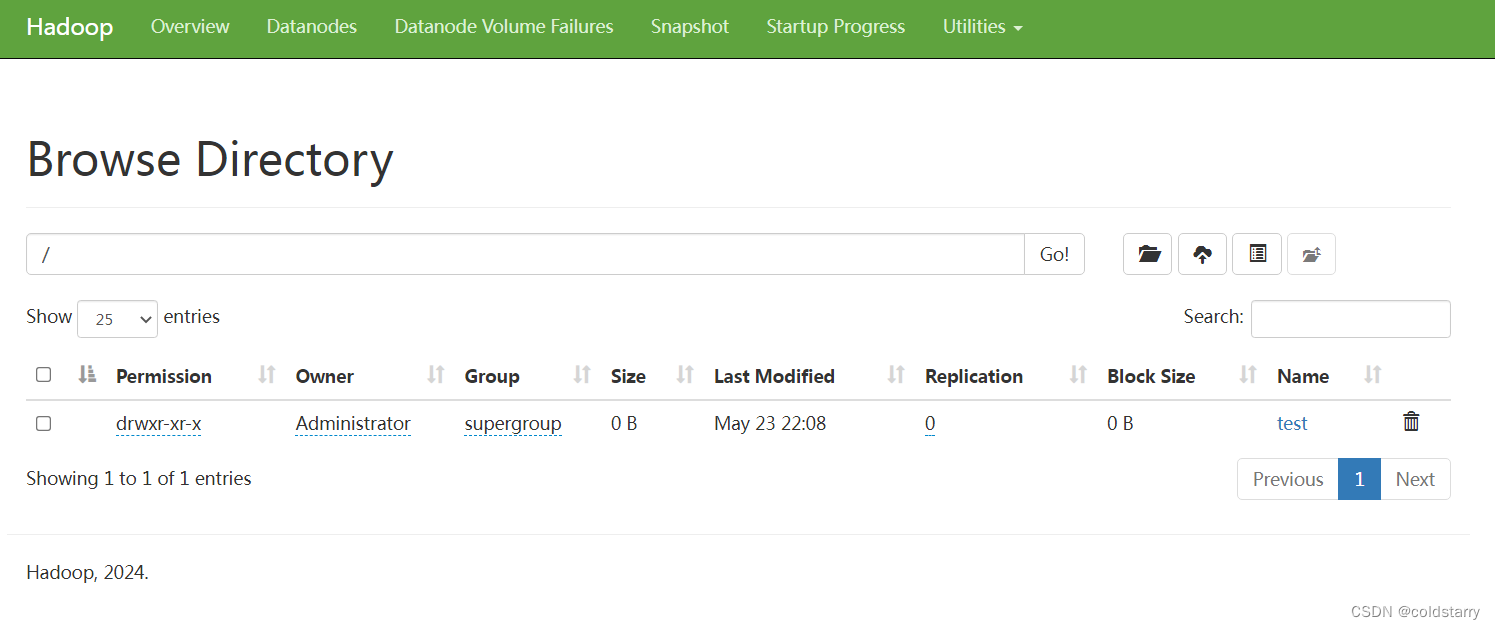
创建一个目录
hdfs dfs -mkdir /test
一次创建多个目录
hdfs dfs -mkdir -p /test/a/b/c
上传文件夹
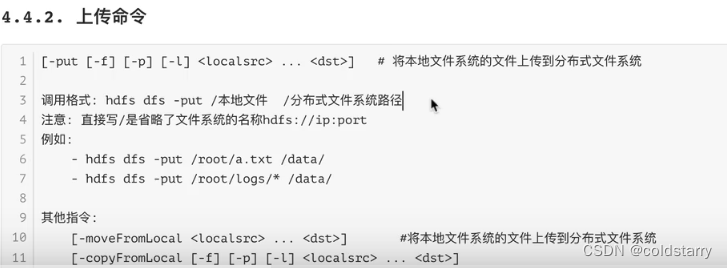
上传文件夹到根目录
hdfs dfs -put test/ /

上传模糊匹配的命令
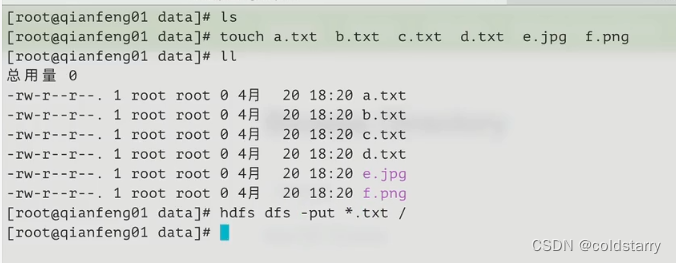
查看文件
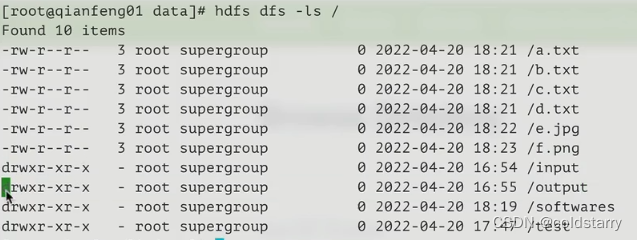
查看文件内容

下载文件

删除

拷贝

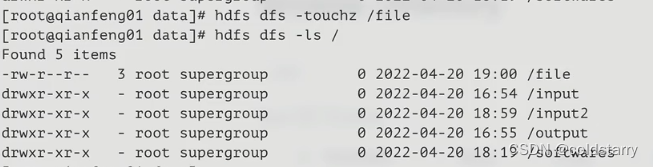
创建空文件
hdfs架构图
1、NameNode和DataNode节点初始化完成后,采用RPC进行信息交换,采用的机制是心跳机制,即DataNode节点定时向NameNode反馈状态信息,反馈信息如:是否正常、磁盘空间大小、资源消耗情况等信息,以确保NameNode知道DataNode的情况;
2、NameNode会将子节点的相关元数据信息缓存在内存中,对于文件与Block块的信息会通过fsImage和edits文件方式持久化在磁盘上,以确保NameNode知道文件各个块的相关信息;
3、NameNode负责存储fsImage和edits元数据信息,但fsImage和edits元数据文件需要定期进行合并,这时则由SecondNameNode进程对fsImage和edits文件进行定期合并,合并好的文件再交给NameNode存储。
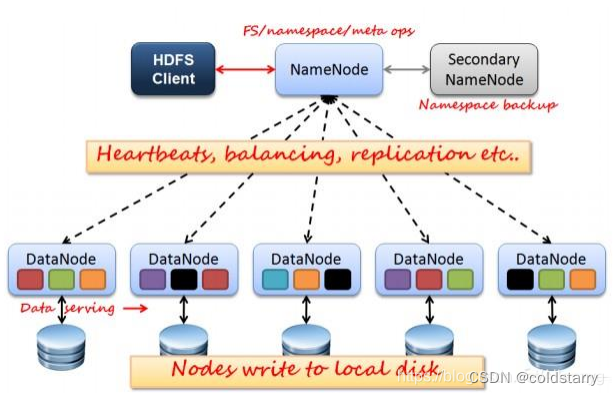
HDFS 也是按照 Master 和 Slave 的结构。分 NameNode、 SecondaryNameNode、DataNode 这几个角色。
HDFS 块(Block)
块是 hdfs 中存储、读写数据的基本单位。客户端向 DN 读写数据的时候,是按块来读写的。
HDFS 的设计目标是寻址时间占传输时间的 1%,一般情况下,寻址时间为 10ms(?),那么传输时间就是 1000 ms 即 1s,现在大多数磁盘的读写速度是 100 MB/s,那么传输一个单位的数据就是 1s × 100 MB/s = 100 MB,而 100 接近 128(2的7次方),所以 hdfs 默认的块大小是 128 MB。
当然,我也说是大多数磁盘的读写速度是 100 MB/s,而有些性能好的磁盘可以达到更高的速度,那么就可以把块设置的更大。
块要结合到磁盘读写速度,既不能太大,也不能太小,否则都会违反 hdfs 的设计目标:
(1)太大会导致寻址时间变的特小,而传输时间变的特大。程序在处理这块数据时,会非常慢。
(2)太小会导致 NN 中存储的块信息太多,增加 NN 的寻址时间。
综上:影响 hdfs 块大小的就是磁盘的读写速度。当然也不能让寻址时间过长,这就要求我们不能在 hdfs 中存储大量的小文件。
NameNode:
(1)负责管理 hdfs 的名称空间,即存储元数据信息(文件名、大小、位置等)
(2)配置副本策略
(3)接收来自 DN 的心跳,并且可以给 DN 发送命令
(4)接收 DN 上报的块信息
(4)处理客户端请求
DataNode:
(1)存储实际的数据块(注意,不是文件本身)
(2)执行数据块的读写操作
Client:
(1)把文件分成块,上传到 hdfs
(2)与 NN 交互发出读写文件的请求,并获得文件的位置信息
(3)与 DN 交互,读写文件
SecondaryNameNode:
为了避免edits文件过大,以及缩短NameNode启动时恢复元数据的时间,我们需要定期地将edits文件合并到fsimage文件,该合并过程叫做checkpoint。(注意:合并 Fsimage 和 Edits 十分占内存, 2NN 与 NN 不能放在同一台节点上,否则会降低 NN 的性能)
对于大型的HDFS集群,fsimage能达到几个GB大小,NameNode通常需要处理非常多的事务,导致NameNode的负担比较重,再让它来进行I/O密集型的文件合并操作就不太合适了,所以HDFS引入了SecondaryNameNode专门负责这件事。也就是说,SecondaryNameNode(简称SNN)是辅助NameNode进行checkpoint操作的角色
SNN的checkpoint时机:
- 默认情况下,SNN每隔1小时进行一次checkpoint
- 但如果还没到1小时,距离上一次checkpoint后事务累积已经超过了1百万,就会立刻触发一次checkpoint
(2)在紧急情况下,辅助恢复 NN
checkpoint
checkpoint过程如下:
- SNN请求NN生成新的edits_inprogress文件,后续新的edits将写入该文件中,之前正在写的edits文件成为待合并状态。NN同时更新seen_txid文件的内容为最新的edit文件ID。
- SNN使用HTTP GET请求的方式将待合并的edits文件和fsimage文件从NN复制到SNN本地。
- SNN将fsimage文件加载到内存,并重放edits文件中的事务进行合并,保存为新的fsimage文件。
- SNN使用HTTP PUT请求的方式将合并后的fsimage复制回NN,保存为.ckpt临时文件。
- NN将.ckpt临时文件重命名为正式的fsimage文件名。
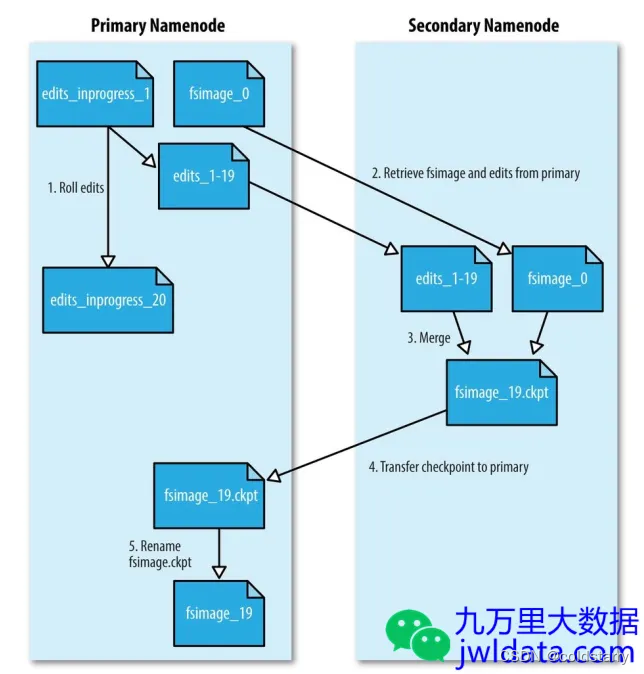
上面说的都是集群只有一个NameNode的情况。如果HDFS NameNode开启了HA的话,SecondaryNameNode会被替换成standby NameNode,checkpoint过程会直接交给standby NameNode来负责。active NameNode会将edits文件同时写到本地与共享存储(比如QJM方案就是JournalNode集群)上去,standby NameNode从JournalNode集群拉取edits文件,和从active NameNode拉取的fsimage进行合并,并保持fsimage文件与active NameNode的同步
hdfs持久化
NameNode
1、`第一次启动 NameNode 格式化后,创建 Fsimage 和 Edits 文件。如果不是第一次启动,直接加载 Edits 和 Fsimage 文件到内存。
2、客户端对元数据进行增删改的请求。
3、NameNode 记录操作日志,更新滚动日志。
4、NameNode 在内存中对数据进行增删改查。
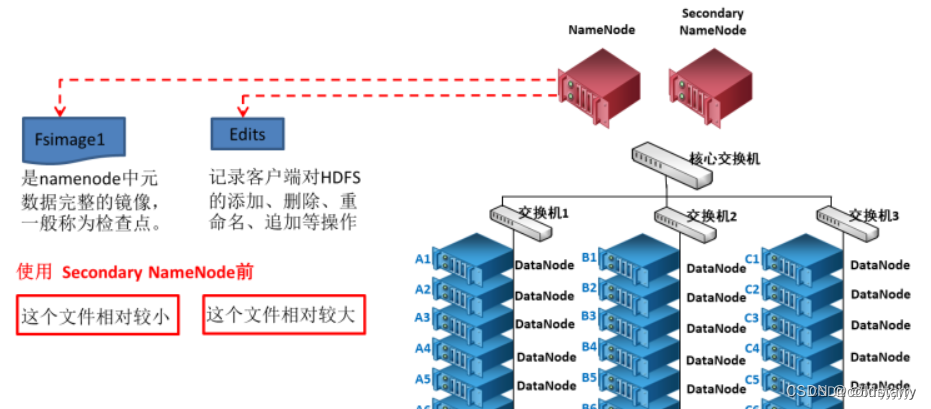

fsimage
fsimage文件是NameNode中关于元数据的镜像,一般称为检查点,它是在NameNode启动时对整个文件系统的快照。包含了整个 HDFS文件系统的所有目录和文件的信息,可以说fsimage就是整个hdfs的目录清单,通过对其进行分析,可以分析出hdfs上小文件的分布情况
Edits
Editlog 主要是在 NameNode 已经启动情况下对 HDFS 进行的各种更新操作进行记录,HDFS 客户端执行所有的写操作都会被记录到 Editlog 中
生成fsimage和edits场景

安全模式
什么是安全模式
Hdfs 的安全模式,即 HDFS safe mode, 是 HDFS 文件系统的一种特殊状态,在该状态下,hdfs 文件系统只接受读数据请求,而不接受删除、修改等变更请求,当然也不能对底层的 block 进行副本复制等操作。
从本质上将,安全模式 是 HDFS 的一种特殊状态,而 HDFS 进入该特殊状态的目的,是为了确保整个文件系统的数据一致性/不丢失数据,从而限制用户只能读取数据而不能改动数据的。
进入安全模式的三种情况
- HDFS 集群正常冷启动
在 HDFS 集群正常冷启动时, NameNode 会在 SafeMode 状态下维持相当长的一段时间,此时你不需要去理会,等待它自动退出安全模式即可。
- block 丢失率达到 0.1%
如果 NameNode 发现集群中的 block 丢失率达到一定比例时(0.1%), NameNode 就会进入安全模式,换句话说,文件系统的块有99.9%以上是可用的,系统才能正常使用,不进入安全模式。这个丢失率是可以手动配置的
- 手动进入安全模式
HDFS写原理
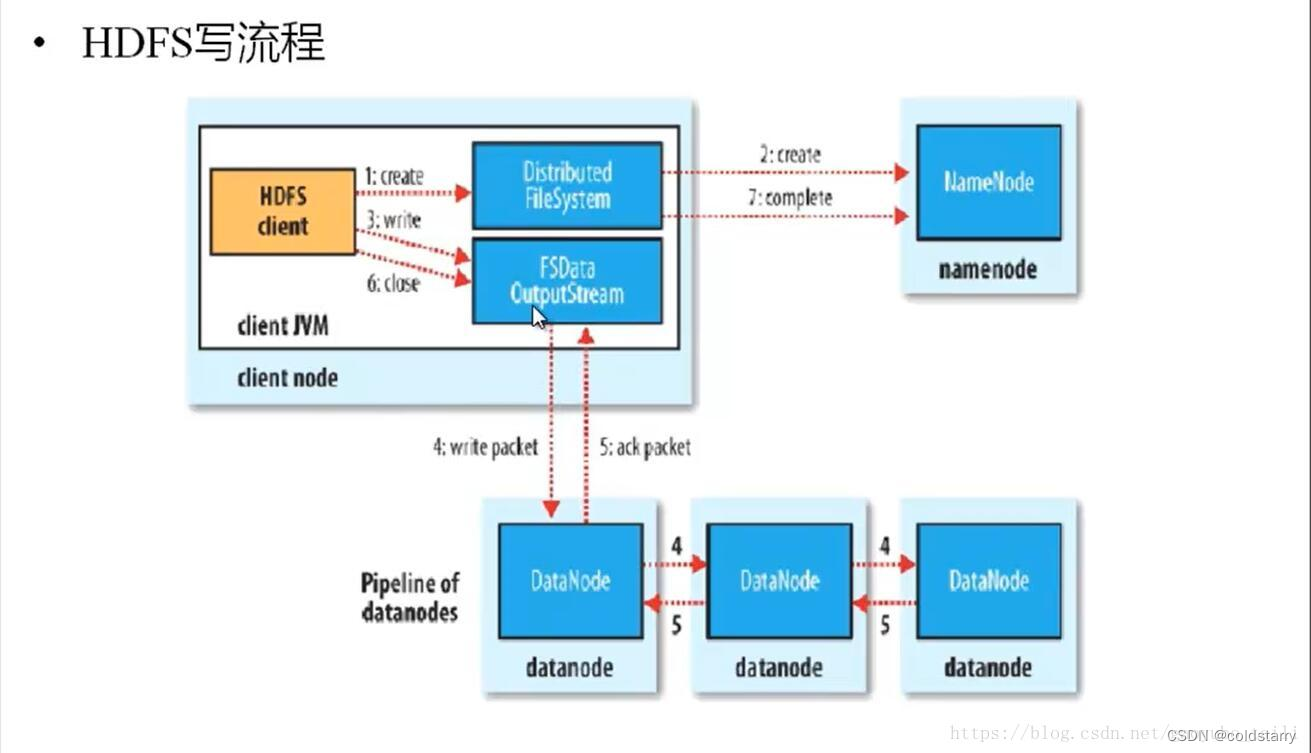
1、HDFS客户端提交写操作到NameNode上,NameNode收到客户端提交的请求后,会先判断此客户端在此目录下是否有写权限,如果有,然后进行查看,看哪几个DataNode适合存放,再给客户端返回存放数据块的节点信息,即告诉客户端可以把文件存放到相关的DataNode节点下;
2、客户端拿到数据存放节点位置信息后,会和对应的DataNode节点进行直接交互,进行数据写入,由于数据块具有副本replication,在数据写入时采用的方式是先写第一个副本,写完后再从第一个副本的节点将数据拷贝到其它节点,依次类推,直到所有副本都写完了,才算数据成功写入到HDFS上,副本写入采用的是串行,每个副本写的过程中都会逐级向上反馈写进度,以保证实时知道副本的写入情况;
3、随着所有副本写完后,客户端会收到数据节点反馈回来的一个成功状态,成功结束后,关闭与数据节点交互的通道,并反馈状态给NameNode,告诉NameNode文件已成功写入到对应的DataNode。
写期间出现故障的处理
如果在数据写入期间datanode发生故障,则执行以下操作(对写入的数据的客户端是透明的)。首先关闭管道,然后将确认队列(ack queue)中的数据包都添加回数据队列(data queue)的最前端,以确保故障节点下游的datanode不会漏掉任何一个数据包。为存储在正常的datanode上的数据块指定一个新的标识,并将该标识传递给namenode,以便故障datanode在恢复后可以删除存储的部分数据块。从管线(pipeline)中删除故障数据节点并把使用剩下的正常的datanode构建一个新的管线(pipeline)。余下的数据块写入新的管线中。namenode注意到块副本量不足时,会在另一个节点上创建一个新的复本,后续的数据块继续正常接受处理
HDFS读原理
1、HDFS客户端提交读操作到NameNode上,NameNode收到客户端提交的请求后,会先判断此客户端在此目录下是否有读权限,如果有,则给客户端返回存放数据块的节点信息,即告诉客户端可以到相关的DataNode节点下去读取数据块;
2、客户端拿到块位置信息后,会去和相关的DataNode直接构建读取通道,读取数据块,当所有数据块都读取完成后关闭通道,并给NameNode返回状态信息,告诉NameNode已经读取完毕。
3、客户端在读取指定datanode的块时,如果网络异常,无法读取,会读取这个块对应的备份datanode,在namenode返回的数据中包含了备份的datanode地址
4、客户端读取一个块成功后,读取下一个块的内容,追加在这个块之后
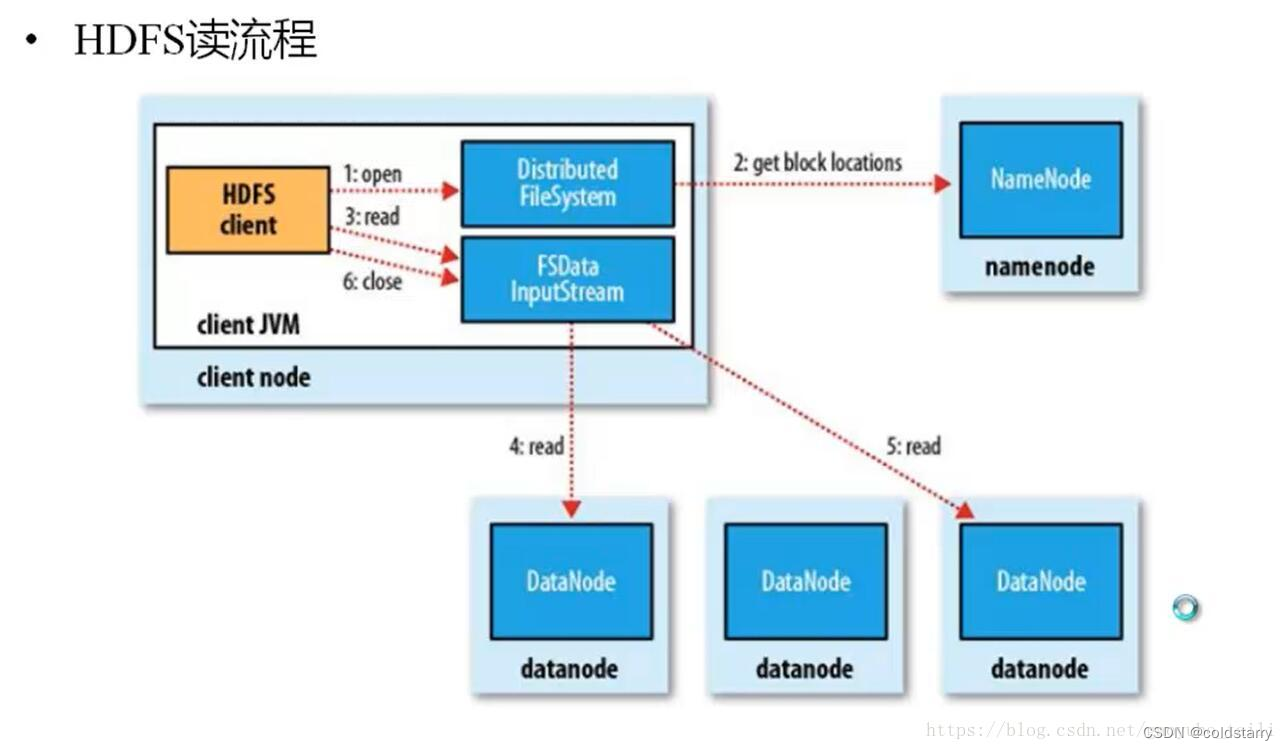
hdfs集群
心跳机制
心跳机制是指,每个DataNode节点定期向NameNode节点发送心跳信号,以表明该DataNode节点仍然处于活动状态。这个心跳信号包括该DataNode节点的状态信息,如已经存储的数据块信息,可用的存储容量等等。
NameNode节点通过接收来自DataNode节点的心跳信号,能够了解每个DataNode节点的状态,以及数据块的位置和副本的数量等信息。如果某个DataNode节点在一定时间内没有发送心跳信号,NameNode节点会将该节点标记为不可用状态,并且将该节点上的数据块副本重新分配到其他可用的DataNode节点上。
此外,HDFS的心跳机制还允许DataNode节点向NameNode节点汇报块的状态和副本的数量,以便NameNode节点可以及时地监控和管理数据块的存储和复制。同时,NameNode在收到DataNode的心跳信号后,也会向DataNode发送命令,如复制块、删除块等等。这些命令通常是为了维护数据块的完整性和可用性。
- 心跳机制的时间频率:
- 每三秒发送一次心跳信号
- 超过630秒没有收到心跳信号,认为节点失效并且将该节点上的数据块副本重新分配到其他可用的DataNode节点上
- 所有的datanode每6个小时向NameNode汇报一次自己完整的块信息,让NameNode校验更新
hdfs优缺点
HDFS优点:
1、高容错性
-
数据自动保存多个副本。它通过增加副本的形式,提高容错性。
-
某一个副本丢失以后,它可以自动恢复,这是由 HDFS 内部机制实现的。
2、适合批处理
-
它是通过移动计算而不是移动数据。
-
它会把数据位置暴露给计算框架。
3、适合大数据处理
-
处理数据达到 GB、TB、甚至PB级别的数据。
-
能够处理百万规模以上的文件数量,数量相当之大。
-
能够处理10K节点的规模。
4、流式文件访问
-
一次写入,多次读取。文件一旦写入不能修改,只能追加。
-
它能保证数据的一致性。
5、可构建在廉价机器上
-
它通过多副本机制,提高可靠性。
-
它提供了容错和恢复机制。比如某一个副本丢失,可以通过其它副本来恢复。
HDFS劣势:
1、不适合低延时数据访问
-
比如毫秒级的来存储数据,它做不到。
-
它适合高吞吐率的场景,就是在某一时间内写入大量的数据。
2、不适合小文件存储
-
存储大量小文件(这里的小文件是指小于HDFS系统的Block大小的文件(默认64M))的话,它会占用 NameNode大量的内存来存储文件、目录和块信息。这样是不可取的,因为NameNode的内存总是有限的。
-
小文件存储的寻道时间会超过读取时间,它违反了HDFS的设计目标。
3、不适合并发写入、文件随机修改
-
一个文件只能有一个写,不允许多个线程同时写。
-
仅支持数据 append(追加),不支持文件的随机修改。
MapReduce
什么是MapReduce
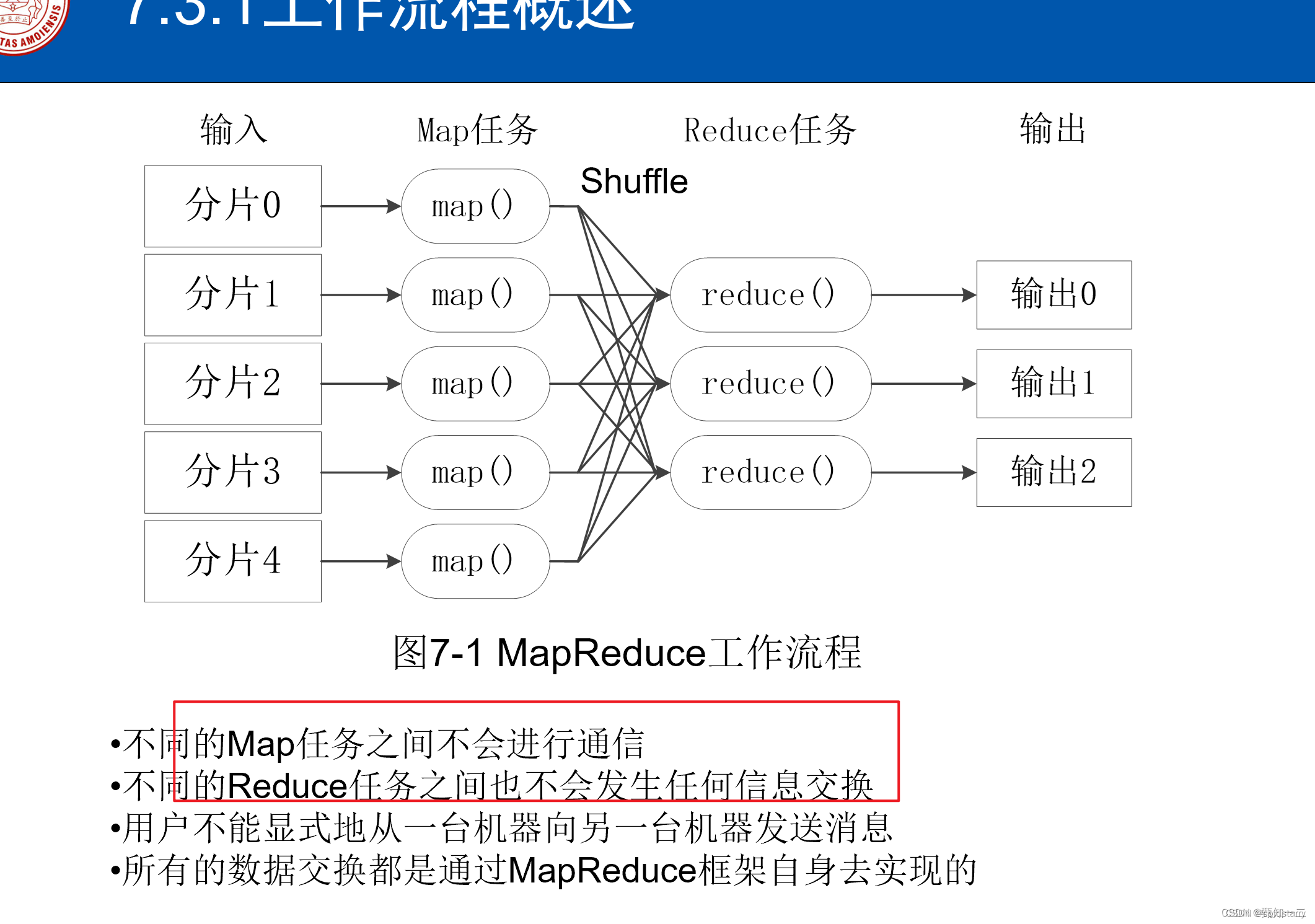
MapReduce 是一种用于处理大规模数据集的编程模型和计算框架,最初由 Google 提出,并被 Hadoop 等开源项目广泛应用。它主要包括两个阶段:Map 阶段和 Reduce 阶段
流程
1)Map 阶段(Map Phase):
- 输入数据被分割成大小相等的数据块,然后由多个 Map 任务并行处理。
- 每个 Map 任务接收一部分数据块,并将其转换成键-值对(Key-Value pairs)的集合。
- 用户定义的 Map 函数(mapper)被应用于每个键-值对,生成新的键-值对列表。
- Map 函数的输出会根据键的哈希值被分发到多个 Reduce 任务中,以便后续的 Reduce 阶段处理。
2)Shuffle 阶段(Sort and Shuffle):
- 在 Map 阶段之后,所有 Map 任务的输出会被分区并按照键的哈希值进行排序。
- 相同键的值被分配到相同的 Reduce 任务中,以便后续的 Reduce 阶段处理。
3)Reduce 阶段(Reduce Phase):
- 每个 Reduce 任务接收来自多个 Map 任务的输出,即经过分区和排序后的键-值对集合。
- 用户定义的 Reduce 函数(reducer)被应用于每个键-值对列表,生成最终的输出结果。
架构图
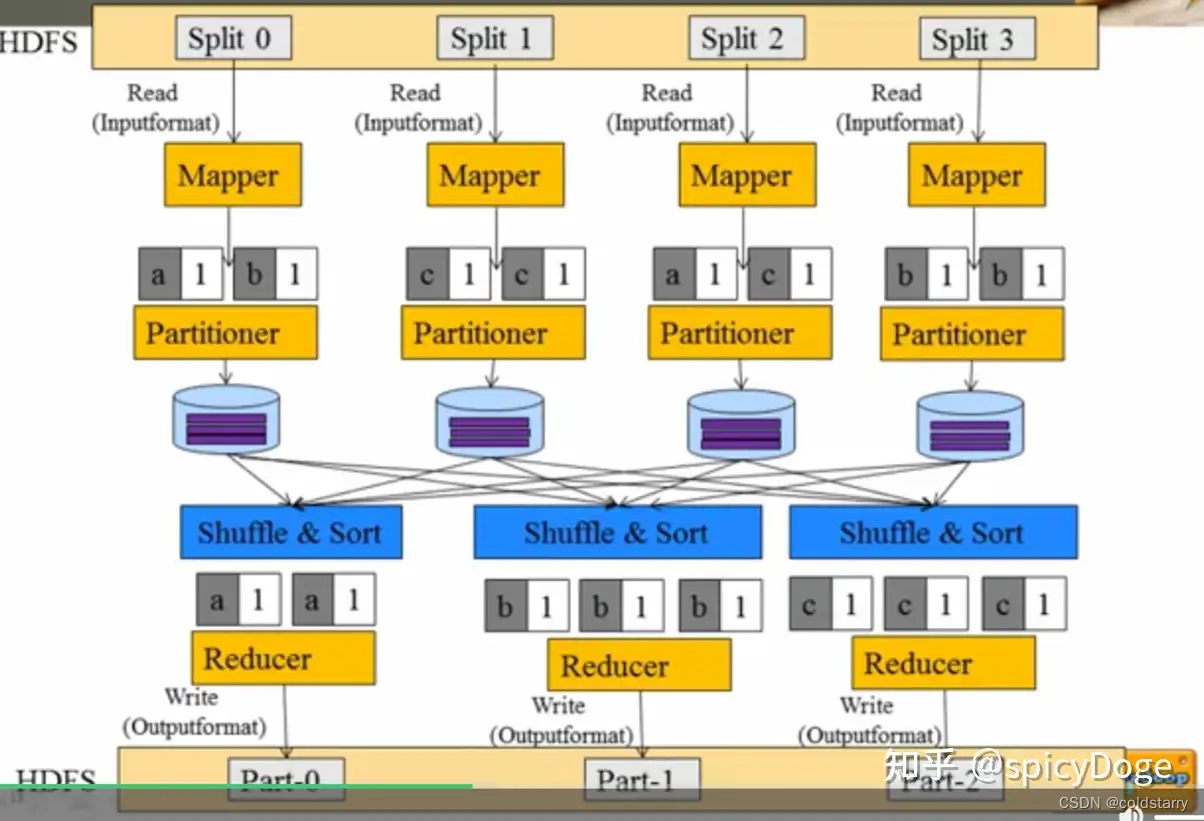

以上过程分步骤描述一下:
- 创建 Split。由于 Map 任务最终是分布式的进程运行在不同的机器上,split 描述了每个 Map 任务该去哪台机器上的整块数据中,读取哪一部分的数据;
- 读取数据;
- 数据经过用户编写的 Map 业务处理,输入的是 Key-Value 格式,输出也是 Key-Value 格式。这一步其实是对数据标记的过程,为每条数据标记一个特征(key),相同特征的数据最终会到一起;
- 数据经过分区后,写入到内存缓冲区中;
- 内存缓冲区被写满 80%后,在内存中进行排序(先按照分区排序,每个分区内部按照 key 排序);
- 如果定义了 combiner 的话,进行一次合并;
- 每个 Map 溢写出一个文件出来;
- 最终对每个 Map 溢写出的文件合并成一个大文件;
- 进行一次 combine,写入到本地文件中;
- 进行到 reduce 阶段,每个 reduce 任务从上游数据中拷贝出属于自己的文件
- 调用用户定义的 reduce 方法进行计算;
- 最终结果写入到 hdfs 中
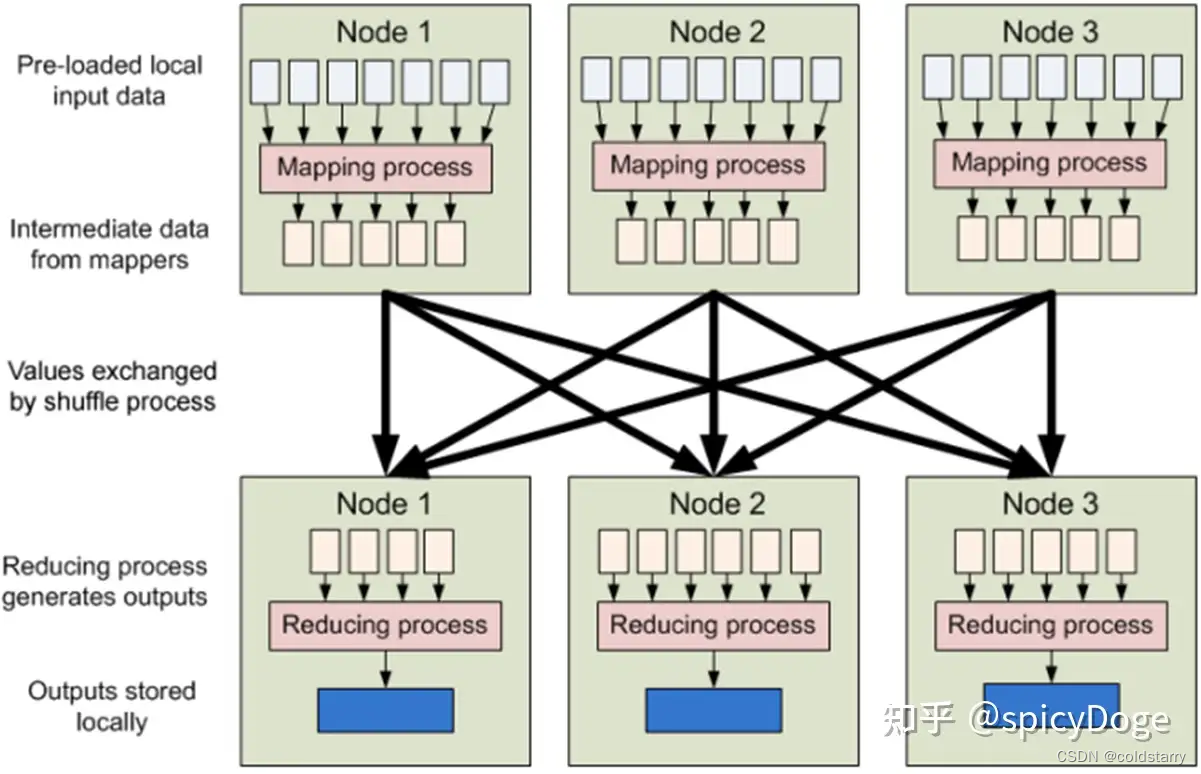
示例
已文字计数为例
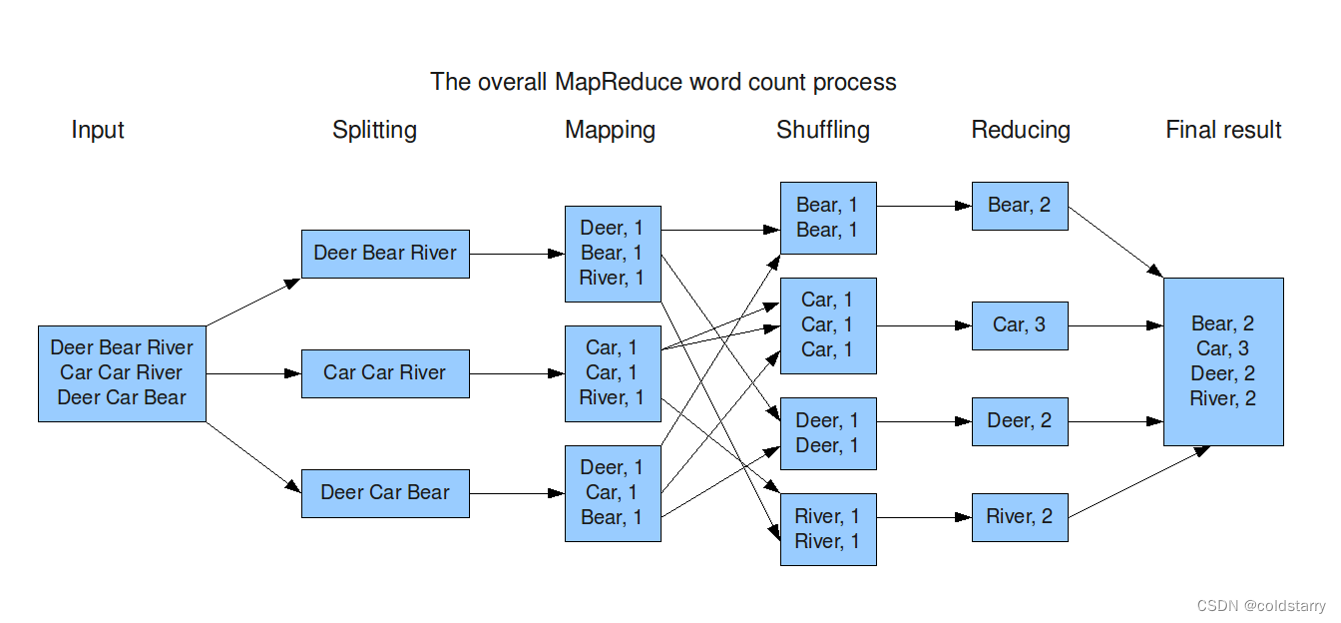
从MapReduce 自身的命名特点可以看出, MapReduce 由两个阶段组成:Map 和Reduce。
用户只需编写map() 和 reduce() 两个函数,即可完成简单的分布式程序的设计。
map() 函数以key/value 对作为输入,产生另外一系列 key/value 对作为中间输出写入本地磁盘。 MapReduce 框架会自动将这些中间数据按照 key 值进行聚集,且key 值相同(用户可设定聚集策略,默认情况下是对 key 值进行哈希取模)的数据被统一交给 reduce() 函数处理。
reduce() 函数以key 及对应的value 列表作为输入,经合并 key 相同的value 值后,产生另外一系列 key/value 对作为最终输出写入HDFS
hello world --WordCount 用户编写完MapReduce 程序后,按照一定的规则指定程序的输入和输出目录,并提交到Hadoop 集群中。作业在Hadoop 中的执行过程如图所示。Hadoop 将输入数据切分成若干个输入分片(input split,后面简称split),并将每个split 交给一个Map Task 处理;Map Task 不断地从对应的split 中解析出一个个key/value,并调用map() 函数处理,处理完之后根据Reduce Task 个数将结果分成若干个分片(partition)写到本地磁盘;同时,每个Reduce Task 从每个Map Task 上读取属于自己的那个partition,然后使用基于排序的方法将key 相同的数据聚集在一起,调用reduce() 函数处理,并将结果输出到文件中
Yarn
什么是yarn
Yarn 是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式 的操作系统平台,而 MapReduce 等运算程序则相当于运行于操作系统之上的应用程序。
架构图
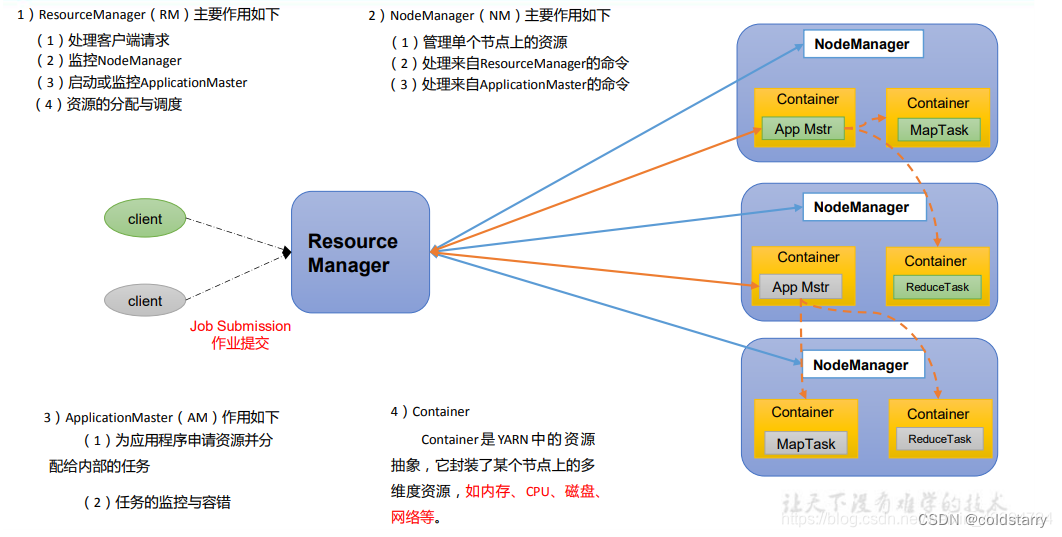
YARN主要由ResourceManager、NodeManager、ApplicationMaster和Container组成,之间通过RPC通讯
1、ResourceManager:是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(Applications Manager,ASM)
2、NodeManager:是每个节点上的资源和任务管理器,一方面,它会定时地向ResourceManager汇报本节点上的资源使用情况和各个Container的运行状态;另一方面,它接收并处理来自ApplicationMaster的Container启动/停止等各种请求
3、Container:是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,ResourceManager为ApplicationMaster返回的资源便是用Container表示
4、ApplicationMaster:用户提交的每个应用程序均包含一个ApplicationMaster,主要功能包括:
1)与ResourceManager调度器协商以获取资源(用Container表示)
2)将得到的任务进一步分配给内部的任务
3)与NodeManager通信以启动/停止任务
4)监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务
注意:MapTask、ReduceTask都运行在Container里面,ApplicationMaster也运作在Container里面,ApplicationMaster负责协调分发Task到Container
Yarn工作流程
当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:第一个阶段是启动ApplicationMaster;第二个阶段是由ApplicationMaster创建应用程序,为它申请资源,并监控它的整个运行过程,直到运行完成。
如图2-11所示,YARN的工作流程分为以下几个步骤:
- 步骤1 用户向YARN中提交应用程序,其中包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等
- 步骤2 ResourceManager为该应用程序分配第一个Container,并与对应的NodeManager通信,要求它在这个Container中启动应用程序的ApplicationMaster
- 步骤3 ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7
- 步骤4 ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源
- 步骤5 一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务
- 步骤6 NodeManager为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务
- 步骤7 各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster查询应用程序的当前运行状态。
- 步骤8 应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己
Yarn作业提交全过程
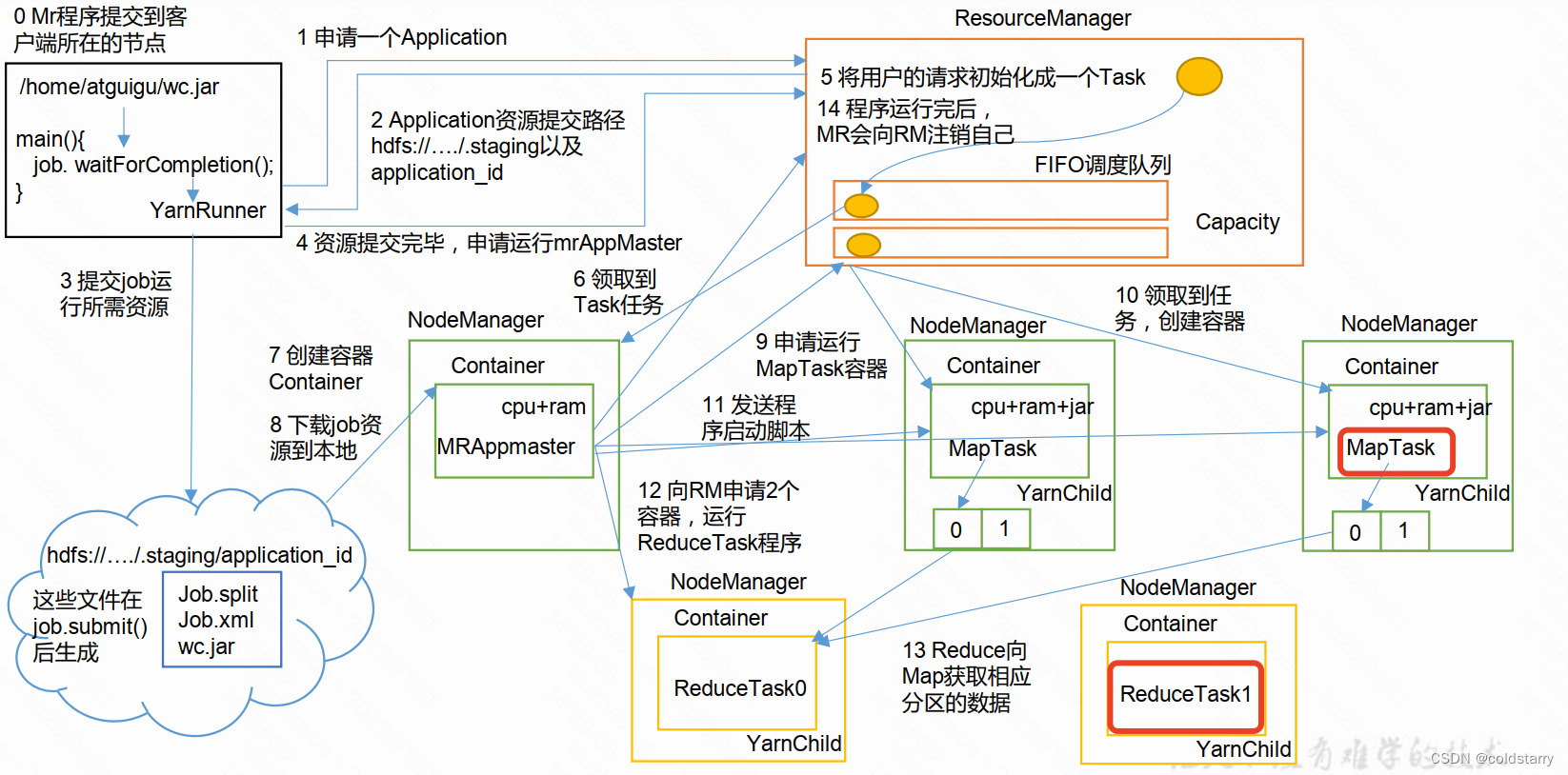
作业提交
第 1 步: Client 调用 job.waitForCompletion 方法,向整个集群提交 MapReduce 作业。
第 2 步: Client 向 RM 申请一个作业 id。
第 3 步: RM 给 Client 返回该 job 资源的提交路径和作业 id。
第 4 步: Client 提交 jar 包、切片信息和配置文件到指定的资源提交路径。
第 5 步: Client 提交完资源后,向 RM 申请运行 MrAppMaster。
作业初始化
第 6 步: 当 RM 收到 Client 的请求后,将该 job 添加到容量调度器中
第 7 步: 某一个空闲的 NM 领取到该 Job。
第 8 步: 该 NM 创建 Container, 并产生 MRAppmaster。
第 9 步:下载 Client 提交的资源到本地。
任务分配
第 10 步: MrAppMaster 向 RM 申请运行多个 MapTask 任务资源。
第 11 步: RM 将运行 MapTask 任务分配给另外两个 NodeManager, 另两个 NodeManager分别领取任务并创建容器。
任务运行
第 12 步: MR 向两个接收到任务的 NodeManager 发送程序启动脚本, 这两个NodeManager 分别启动 MapTask, MapTask 对数据分区排序。
第13步: MrAppMaster等待所有MapTask运行完毕后,向RM申请容器, 运行ReduceTask。
第 14 步: ReduceTask 向 MapTask 获取相应分区的数据。
第 15 步: 程序运行完毕后, MR 会向 RM 申请注销自己。
进度和状态更新
YARN 中的任务将其进度和状态(包括 counter)返回给应用管理器, 客户端每秒(通过mapreduce.client.progressmonitor.pollinterval 设置)向应用管理器请求进度更新, 展示给用户。
作业完成
除了向应用管理器请求作业进度外, 客户端每 5 秒都会通过调用 waitForCompletion()来检查作业是否完成。 时间间隔可以通过 mapreduce.client.completion.pollinterval 来设置。 作业完成之后, 应用管理器和 Container 会清理工作状态。 作业的信息会被作业历史服务器存储以备之后用户核查。
MR任务执行
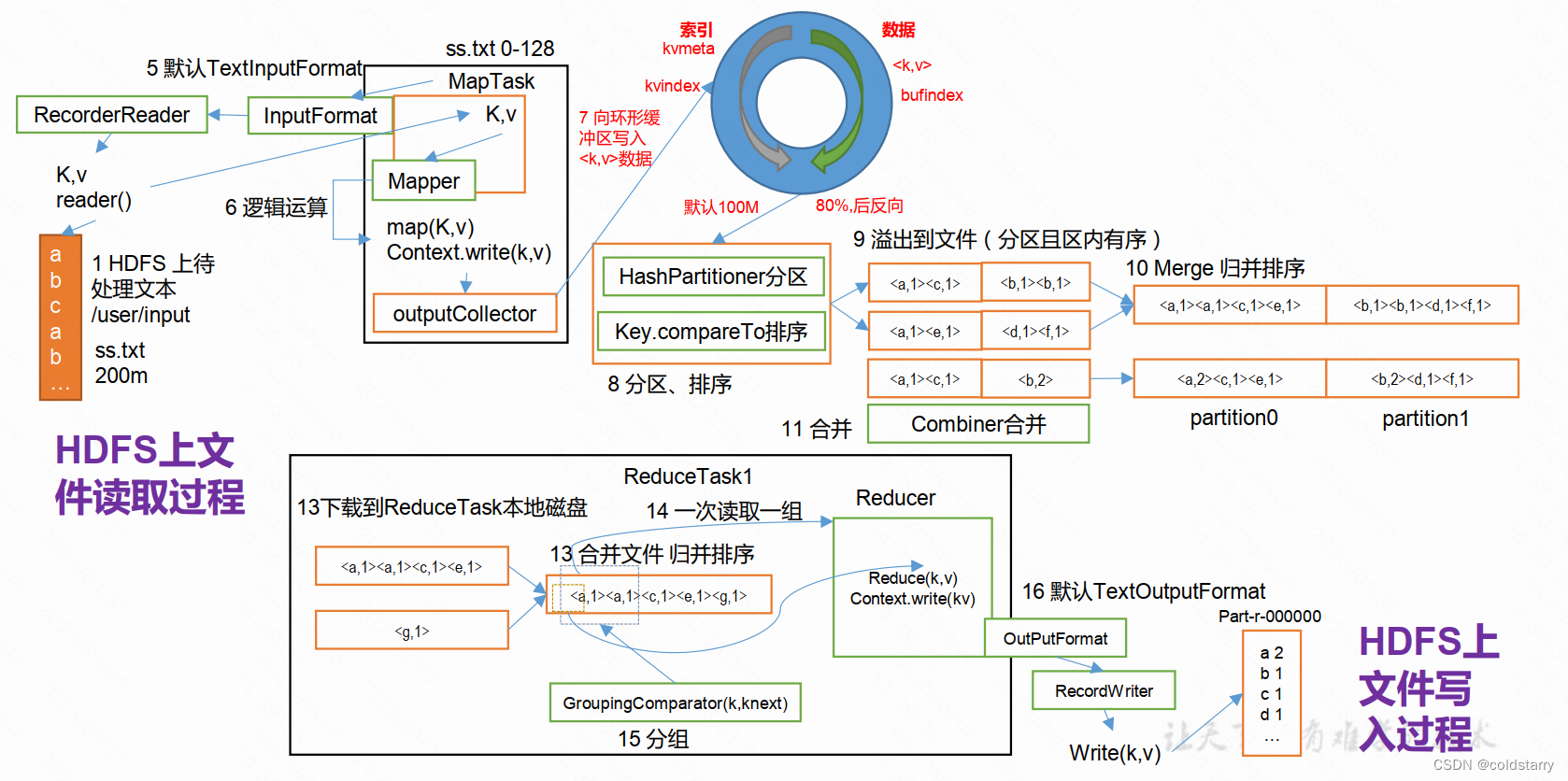
当ApplicationMaster在Container启动之后,也就是MapReduce具体的运行过程,会通过InputFormat阶段从HDFS拉取对应的数据分片,执行Map、Shuffle、Reduce进行数据处理,最后通过OutputFormat将数据写到HDFS或其他存储引擎上。
Yarn调度器
FIFO调度器
单队列,根据提交作业的先后顺序,先来先服务。优点:简单易懂。缺点:不支持多队列,生产环境很少使用
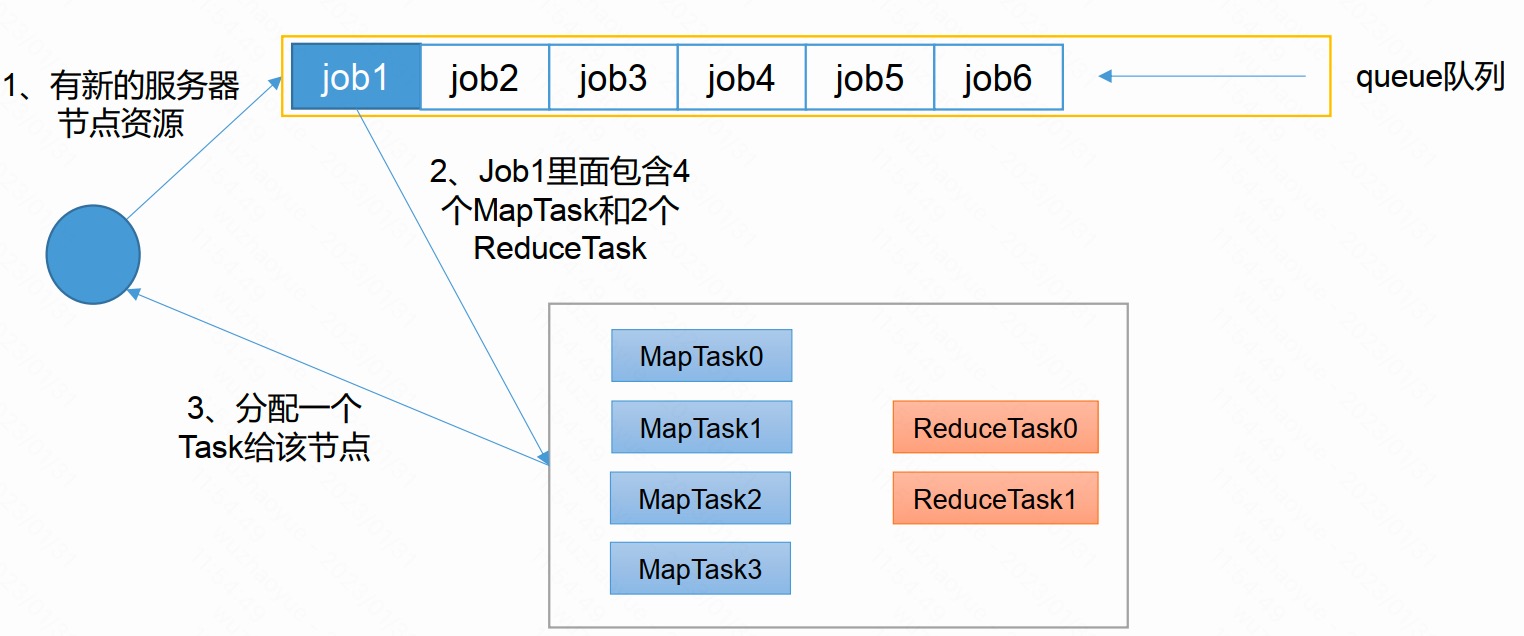
容量调度器(Capacity Scheduler)

Yarn默认调度器,特点如下:
- 多队列: 每个队列可配置一定的资源量,每个队列采用FIFO调度策略。
- 容量保证:管理员可为每个队列设置资源最低保证和资源使用上限
- 灵活性:如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列
- 多租户:支持多用户共享集群和多应用程序同时运行。为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定
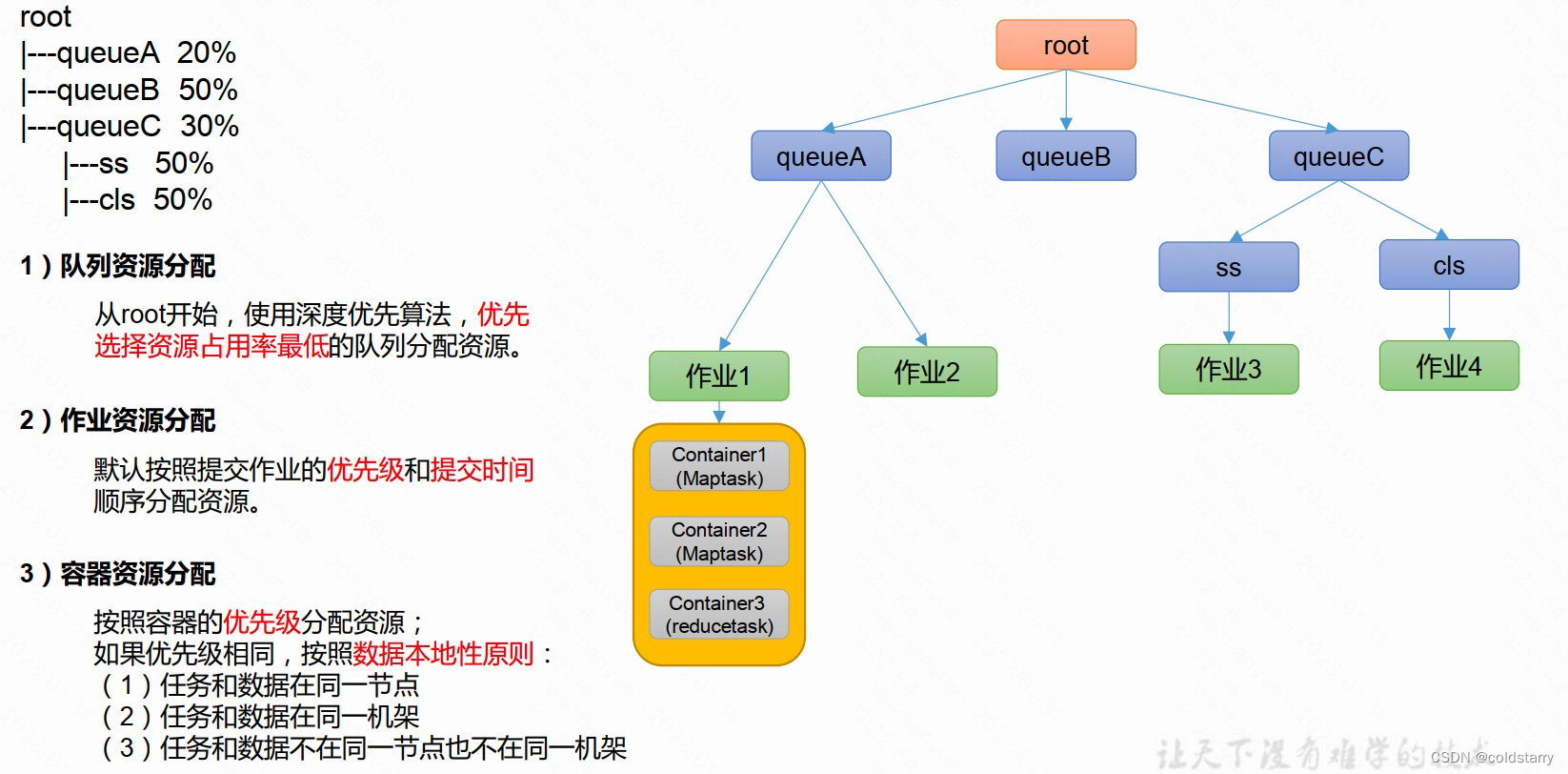
公平调度器(Fair Scheduler)
与容量调度器对比
1)与容量调度器相同点
- 多队列:支持多队列多作业
- 容量保证:管理员可为每个队列设置资源最低保证和资源使用上线
- 灵活性: 如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列。
- 多租户:支持多用户共享集群和多应用程序同时运行;为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定。
2)与容量调度器不同点
核心调度策略不同
- 容量调度器:优先选择资源利用率低的队列
- 公平调度器:优先选择对资源的缺额比例大的
每个队列可以单独设置资源分配方式
- 容量调度器: FIFO、 DRF
- 公平调度器: FIFO、 DRF、FAIR
公平调度器缺额
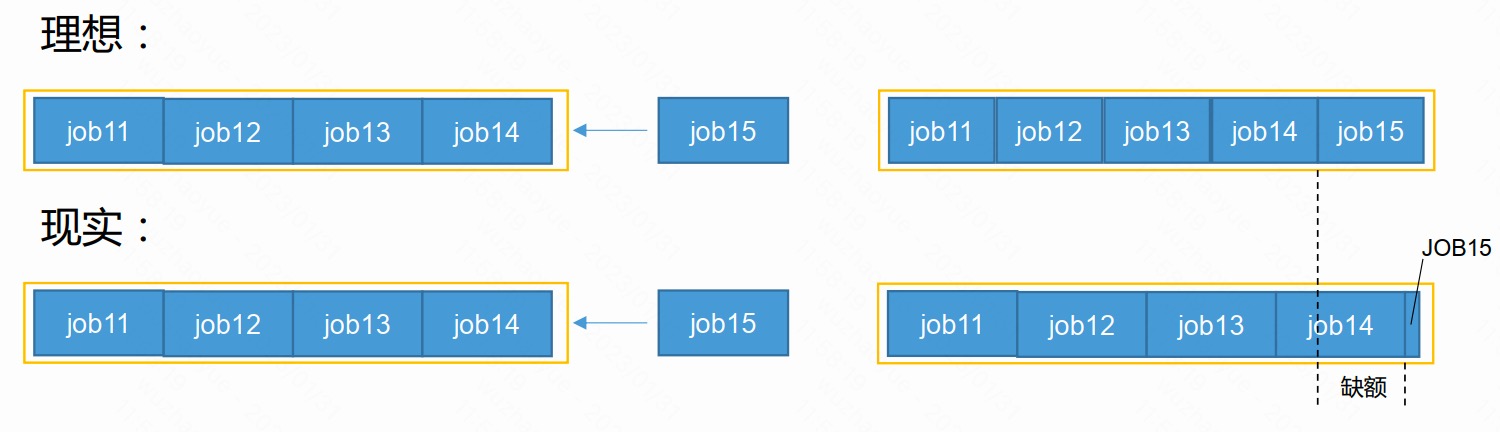
- 公平调度器设计目标是:在时间尺度上,所有作业获得公平的资源。某一时刻一个作业应获资源和实际获取资源的差距叫“缺额”
- 调度器会优先为缺额大的作业分配资源
公平调度器策略
1) FIFO策略
公平调度器每个队列资源分配策略如果选择FIFO的话, 此时公平调度器相当于上面讲过的容量调度器
2) Fair策略
Fair 策略(默认) 是一种基于最大最小公平算法实现的资源多路复用方式, 默认情况下, 每个队列内部采用该方式分配资源。 这意味着, 如果一个队列中有两个应用程序同时运行, 则每个应用程序可得到1/2的资源;如果三个应用程序同时运行, 则每个应用程序可得到1/3的资源
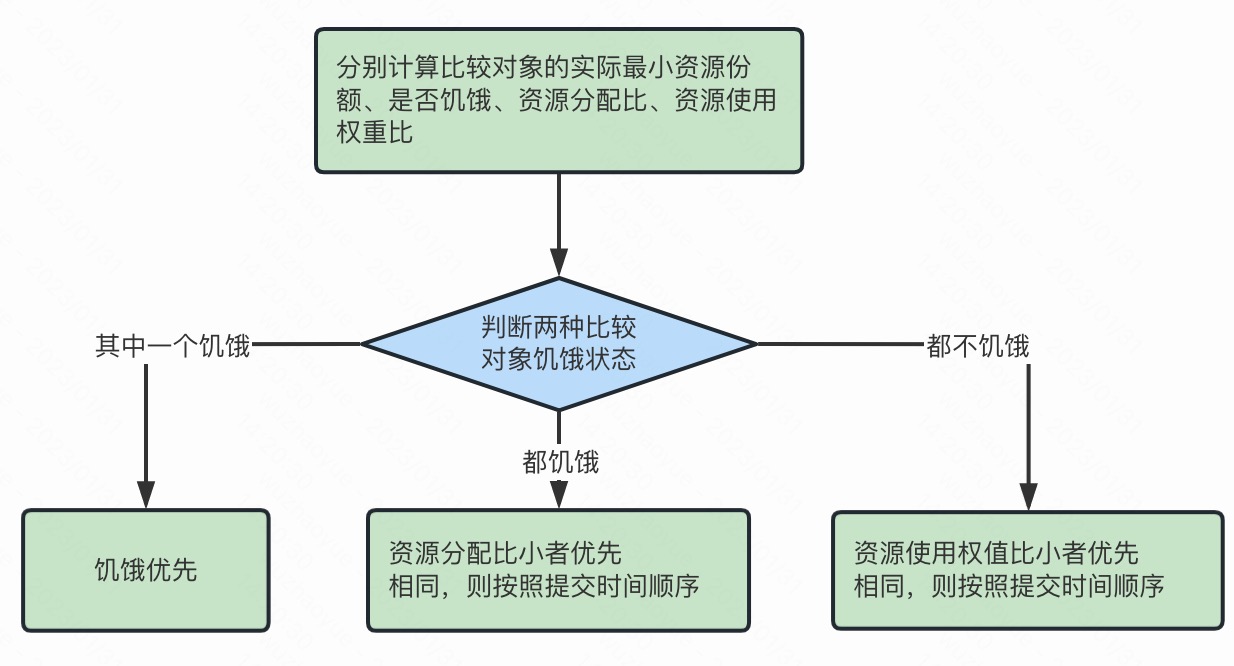
具体资源分配流程和容量调度器一致;
(1) 选择队列
(2) 选择作业
(3) 选择容器
以上三步, 每一步都是按照公平策略分配资源
➢ 实际最小资源份额: mindshare = Min(资源需求量, 配置的最小资源)
➢ 是否饥饿: isNeedy = 资源使用量 < mindshare(实际最小资源份额)
➢ 资源分配比: minShareRatio = 资源使用量 / Max(mindshare, 1)
➢ 资源使用权重比: useToWeightRatio = 资源使用量 / 权重
3) DRF策略
DRF(Dominant Resource Fairness)我们之前说的资源, 都是单一标准, 例如只考虑内存(也是Yarn默认的情况)。但是很多时候我们资源有很多种, 例如内存、CPU、网络带宽等,这样我们很难衡量两个应用应该分配的资源比例。
那么在YARN中, 我们用DRF来决定如何调度:
假设集群一共有100 CPU和10T 内存,而应用A需要(2 CPU, 300GB),应用B需要(6 CPU, 100GB)。则两个应用分别需要A(2%CPU, 3%内存)和B(6%CPU, 1%内存)的资源, 这就意味着A是内存主导的, B是CPU主导的,针对这种情况,我们可以选择DRF策略对不同应用进行不同资源(CPU和内存)的一个不同比例的限制。
参考文章
Hadoop 核心原理(贼全面)_hadoop原理-CSDN博客
hadoop(二:hadoop3.3.0搭建,HDFS shell 命令,MapReduce程序)_hadoop 3.3.0-CSDN博客
【好程序员】大数据开发技术Hadoop视频教程,Hadoop3.x从入门安装环境搭建到项目实战_哔哩哔哩_bilibili
Windows下安装Hadoop(手把手包成功安装)_windows安装hadoop-CSDN博客
HDFS原理(超详解)-CSDN博客
3 HDFS_hdfs命令计算hdfs读取时间-CSDN博客
https://zhuanlan.zhihu.com/p/61646300
Hadoop原理之——HDFS原理-CSDN博客
hdfs小文件使用fsimage分析实例_hdfs fsimage-CSDN博客
【Hadoop-HDFS】HDFS中Fsimage与Edits详解_hdfs fsimage-CSDN博客
HDFS 安全模式-CSDN博客
hdfs心跳机制_hdfs heartbeat packet-CSDN博客
https://zhuanlan.zhihu.com/p/374691395
Hadoop学习笔记-Yarn原理_公平调度器每个队列资源分配策略如果选择fifo的话,此时公平调度器相当于上面讲过-CSDN博客
https://www.cnblogs.com/wwzyy/p/17078564.html
MapReduce原理简介_2.mapreduce编程的原理是什么?-CSDN博客
Hadoop系统架构与简单介绍-腾讯云开发者社区-腾讯云
https://zhuanlan.zhihu.com/p/46242749
https://zhuanlan.zhihu.com/p/674039703
MapReduce的原理分析_根据下图分析mapreduce的设计架构及实现机制。-CSDN博客