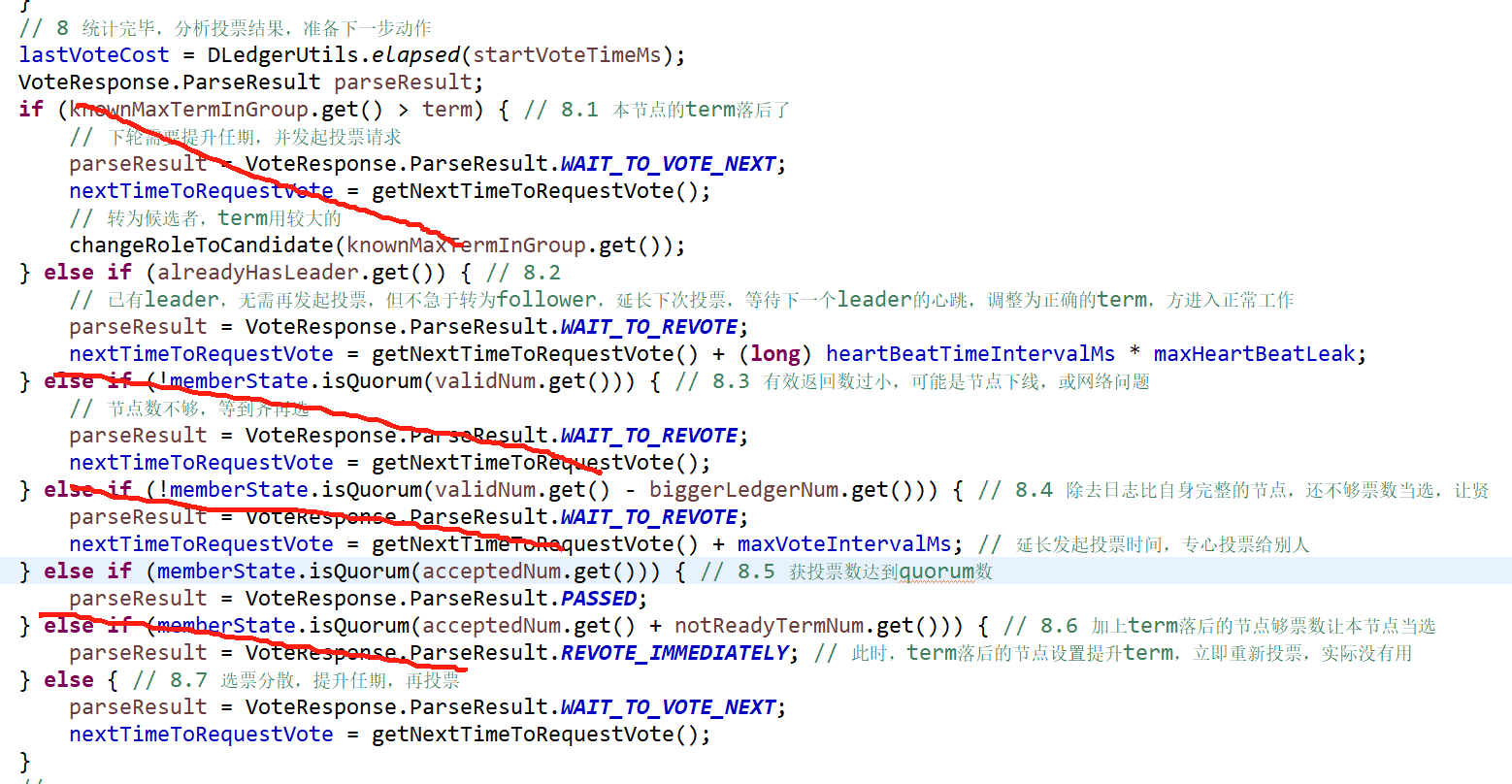
这篇文章是 2023 ICCV 的一篇文章,主要介绍一套统一的去马赛克的算法框架的
由于手机 Camera 上 CMOS 的单个 pixel size 比较小,所以现在很多手机的 Camera CMOS 会采用一些独特的非 Bayer 模式的 CFA (Quad, Nona 以及 Q X Q) 等,这类非 Bayer 模式的特点是在一个局部邻域内的像素是同样的颜色,可以根据不同的光照条件,进行灵活的转换,不过也对去马赛克的方式带来了挑战,如果处理不好,很容易带来 artifacts。之前的去马赛克方法主要是针对传统的 Bayer 模式设计的,对于非 Bayer 类型的 CFA 模式,需要对不同的 CFA 模式设计不同的去马赛克算法。这篇文章的作者提出了一种高效的统一去马赛克的方法,一个模型可以实现对传统的 Bayer 类型以及非 Bayer 类型的 RAW 图像进行去马赛克,这个方法称为基于知识学习的去马赛克方法(KLAP),使用自适应的 CFA filters,每种 CFA 的自适应 filter 只占总参数量的 1%,但依然可以有效地处理所有的 CFA 类型。更进一步的,通过在推理阶段使用元学习的策略(KLAP-M),这个模型可以消除实际 RAW 数据中未知的与 sensor 相关的伪纹理,从而可以有效地将仿真数据与实际数据连接起来。文章提出的 KLAP 和 KLAP-M 的方法在仿真数据与实际数据上对 Bayer 及非 Bayer 类型的 CFA 的去马赛克表现都达到 SOTA 水平。
Introduction
在 ISP 流程中,去马赛克是非常重要的一个模块,因为我们的手机 sensor 捕获的是一个单通道的 RAW 图,但是我们最终看到的图像是一个 RGB 三通道的图像,那么从单通道的 RAW 图到三通道的 RGB 图像的这个过程,就是我们常说的去马赛克的操作。随着目前智能手机的影像质量越来越高,所用的sensor 的像素数量也越来越多,从以前的几百万像素,到后来的 12M,到目前的 50M,甚至有 200M,也就是 2 亿像素,虽然像素的数量在不断增加,但是 sensor 的整体面积并没有增大很多,所以带来的最终结果就是减小了单个像素的感光面积,小像素会导致 sensor 对光照更敏感,也更容易带来噪声,为了解决这个问题,所以现在的很多 sensor 在传统 Bayer CFA 的基础上,发展出了很多不同的非 Bayer 类型的 CFA,简单来说,就是将同颜色的小像素在相邻区域进行统一的排布,形成 2 × 2 , 3 × 3 , Q × Q 2 \times 2, 3 \times 3, Q \times Q 2×2,3×3,Q×Q 的排布,这种排布的好处就是当光线不足的时候,这些相邻同颜色的像素可以合并成一个像素,从而提升整体的信噪比。而当光线充足的时候,又可以变成单个像素成像,从而提升成像的分辨率。不过这种非 Bayer 类型的 CFA 需要专门的去马赛克算法的支持,不同的 CFA 需要不同的去马赛克算法。如果每个 CFA 都需要一个单独的去马赛克模型,那么对于一个需要在不同光照条件下变换不同 CFA 模式的 sensor 来说,是不够灵活的。所以这篇文章就想设计一个统一的去马赛克算法框架,以自适应的去适配不同的 CFA 模式。

Deep Demosaicing for Each Non-Bayer CFA
Operating Principles of Non-Bayer Sensors
文章首先展示了非 Bayer 模式的 sensor 在不同光照下的输出方式,如图 2 所示:

对于一个 Q × Q Q \times Q Q×Q 的非 Bayer 的 sensor,当光照不足的时候, Q × Q Q \times Q Q×Q 的像素会合成一个大的像素,然后再经过去马赛克算法,这种方式就是通过增大感光面积来提升信噪比,不过代价就是会损失空间分辨率,而当光照充足的时候, Q × Q Q \times Q Q×Q 的每个 pixel 不再做融合,而是直接参与成像,这个时候有两种操作,一种是先将 Q × Q Q \times Q Q×Q 做一个马赛克算法,变成常规的 Bayer 模式,然后再过去马赛克算法,另外一个操作就是直接将 Q × Q Q \times Q Q×Q 的模式通过去马赛克算法,这两种方式的好处就是成像分辨率提升了,不过每个像素的感光面积下降了,所以需要在光照充足的时候用。所以不同的成像模式,需要不同的去马赛克算法进行支撑。
Data Synthesis for Demosaicing All CFAs
接下来,文章介绍了数据构造的流程,为了构造数据对,文章设计了一种从高质量的 sRGB 图像到 RAW 图的过程, 如图 3 所示:

简单来说,就是将 ISP 流程中的模块倒转过来,对于颜色亮度来说,需要做逆变换,包括 tone 的逆处理,gamma 的逆变换,CCM 的逆变换以及白平衡的逆变换,不过一般来说,RAW 图到 sRGB 图可能会有动态范围的损失,所以最好能用高比特的 sRGB 图进行退化,才能得到高保真的 RGB 图,做完这些,得到依然是 RGB 域的图像,需要再经过叠加噪声以及通道拆分,下采样,再合并成一个单通道的 RAW 图,这个 RAW 图可以是常规的 Bayer 模式的,也可以是非 Bayer 模式的。
Domain Gap in Synthetic and Real CIS RAW
文章也提到了域差异的问题,这是很多 low-level 的计算机视觉问题的通病吧,仿真构造的数据与实际的数据多多少少总会存在一些域差异,如何拟合或者跨过这个域差异是很多研究者一直在努力解决的问题。文章为了解决或者减轻域差异带来的泛化性问题,提出了一种 meta learning 的策略。
Unified Deep Demosaicing for Multiple Bayer and Non-Bayer CFAs
接下来,是文章的方法部分,整个方法分成三步,如图 4 所示:

Step 1: Two-stage Knowledge Learning
这一步就是利用两阶段知识迁移的方法训练一个统一的去马赛克模型,首先对于每个特定的 CFA 来说,都会有一个单独的去马赛克模型,称为 IM,假设这些 IM 都有同样的网络结构,不过包含不同的网络参数, { θ i } i = 1 k \{\theta_i\}_{i=1}^{k} {θi}i=1k,其中 θ \theta θ 表示网络参数, i = 1 , 2 , . . . k i=1,2,...k i=1,2,...k 表示不同的 CFA 类型,也就是不同的 IM 模型, k k k 表示总共的 CFA 类型,文章中 k = 4 k=4 k=4, θ u m \theta_{um} θum 表示统一的去马赛克模型的网络结构和参数,一般来说 IM 在对特定的 CFA 类型的时候,去马赛克效果是最好的,不过每个 CFA 类型需要配一个 IM,那么 K 种 CFA 类型就要配 K 个模型。
首先,对每个 CFA 类型,先单独预训练一个 IM 模型,网络结构用基础的 NAFNet,然后在知识收集(knowledge collection)阶段,用每个训练好的 IM 作为老师,UM 模型作为学生,去训练 UM 模型,这有点像知识蒸馏;然后是knowledge examination (KE) 阶段,这个阶段,IM 模型不再参与引导,而是直接用所有 CFA 类型的训练数据,一块训练 UM 模型,这个思路整体还是比较合理的,先利用知识蒸馏引导 UM 模型,然后再用实际的训练数据进行训练,这样可以增大 UM 模型的处理能力。
Step 2: Adaptive Discriminative Filters for each specific CFA Pattern
上面介绍的第一步,是让 UM 模型见过所有不同的 CFA 类型,然后在实际处理的时候,文章作者认为模型处理不同 CFA 类型的时候,可能网络激活的 kernel 也不一样,基于这样一个假设,文章作者借用 FAIG 的思路,设计了一个 Adaptive Discriminative Filters 也就是 ADP,首先对于本文的任务来说,FAIG 的 分数可以表示为: F S j = F A I G j ( θ u m j , θ i j , x i ) FS_{j}=FAIG_{j}(\theta_{um}^{j}, \theta_{i}^{j}, x_{i}) FSj=FAIGj(θumj,θij,xi),其中 i i i 表示 CFA 类型的编号, j j j 表示网络中 kernel 的编号,也就是说,对于某个 kernel j j j 来说,其在 UM 模型中与在 IM 模型中的相似性可以由一个度量,基于这个度量,可以进行排序,然后选择前 q% 的 kernel 作为处理每个 CFA 类型的去马赛克的 kernel,为了将 UM 模型的 kernel 与 IM 模型的 kernel 更好的融合,文章设计了如下的融合表达式:
θ a d p j = θ u m j + ∑ i = 1 k α i θ i j ∗ M i j (1) \theta_{adp}^{j} = \theta_{um}^{j} + \sum_{i=1}^{k} \alpha_{i} \theta_{i}^{j} \ast M_{i}^{j} \tag{1} θadpj=θumj+i=1∑kαiθij∗Mij(1)
其中, j j j 表示 kernel 的编号, θ u m j \theta_{um}^{j} θumj 表示 Step-1 中预训练好的 UM 模型, α i \alpha_{i} αi 表示对某种特定 pattern 的标识,取值为 0 或者 1, θ i j \theta_{i}^{j} θij 表示每个特定 CFA 类型下,额外增加的 kernel, M i j M_{i}^{j} Mij 表示一个掩码,q% 在文章中取了一个经验值 1%,每种 CFA 类型都取 1%,所以最终的参数量,是 UM 本身的参数加上额外 4% 的参数。
这一步的作用,总得来说,就是在上一步完成 UM 训练的基础上,对 UM 中的一些 kernel 进行替换,以让 UM 模型可以更好的适应不同的 CFA 类型,而替换的准则就是用 FAIG 的思路,计算 UM 模型与 IM 模型里,同样位置的 kernel 参数的一种度量,然后选择前 1% 的 kernel 加入到 UM 模型中
Meta-learning during Inference
最后一步,文章作者为了减轻域差异带来的问题,提出了一种 meta learning 的在线 fine-tune 的策略,这个策略在推理的时候,需要对网络进行少量的迭代,以获得更为鲁棒的效果,这个 meta learning 的训练loss 包含了 pixel binning loss 以及 Noise2Self loss,因为 pixel binning 可以通过像素融合的方式,增大感光面积,提升信噪比,所以文章借助这个特性,提出了一种自监督的降噪方法来去除一些未知的伪纹理:

L p i x = ∣ G ( x J c , θ a d p ) − U ( G ( m ( x J c ) , θ a d p ′ ) ) ∣ (2) \mathcal{L}_{pix} = \left| G(x_{J^{c}, \theta_{adp}}) - U(G(m(x_{J^{c}}), \theta_{adp}')) \right| \tag{2} Lpix= G(xJc,θadp)−U(G(m(xJc),θadp′)) (2)
其中, x , J c x, J^{c} x,Jc 分别表示 RAW 图以及要用到的 mask 掩码, m , U m, U m,U 分别表示对 pixel binning 做平均,以及上采样操作,G 表示网络结构, θ a d p \theta_{adp} θadp 表示需要更新的网络参数, θ a d p ′ \theta_{adp}' θadp′ 网络的初始参数,在 meta learning 过程中不参与更新,这个 loss 设计的目的,就是想通过更新 θ a d p \theta_{adp} θadp 让网络可以学习到 pixel binning 的效果。
此外,作者还引入了另外修改后的 N2S loss 函数,让网络对各种噪声的表现更为鲁棒:
L N 2 S = ∣ G ( x J c , θ a d p ) J − x J ∣ (3) \mathcal{L}_{N2S} = \left| G(x_{J^{c}, \theta_{adp}})_{J} - x_{J} \right| \tag{3} LN2S= G(xJc,θadp)J−xJ (3)
最终 meta learning 阶段的 loss 可以表示成:
L t o t a l = λ p i x L p i x + λ N 2 S L N 2 S (4) \mathcal{L}_{total} = \lambda_{pix} \mathcal{L}_{pix} + \lambda_{N2S} \mathcal{L}_{N2S} \tag{4} Ltotal=λpixLpix+λN2SLN2S(4)






![摸鱼大数据——Spark基础——Spark环境安装——Spark Local[*]搭建](https://img-blog.csdnimg.cn/direct/c027155d833b4b0c90a33e2ee1e08a65.png)