2-requests模块(6节课学会爬虫)
- 1,安装requests
- 2,发送get,post请求,获取响应
- 3,response的方法
- 方法一(Response.text)
- 方法二(response.content.decode())
- 4,获取网页源码的正确打开方式(一定能获取网页正确解码的字符串)
- 5,发送带header的请求
- 6,使用超时参数
- 7,Retrying模块的学习
- 8,处理cookie相关的请求
- 方法一,直接携带cookie请求url地址
- 方法二,在程序中登录
1,安装requests
pip install requests
2,发送get,post请求,获取响应
Response = requests.get(url) 发送get请求,请求url地址对应的响应
发送post请求
Data={请求体的字典}
response = requests.post(url,data=data)
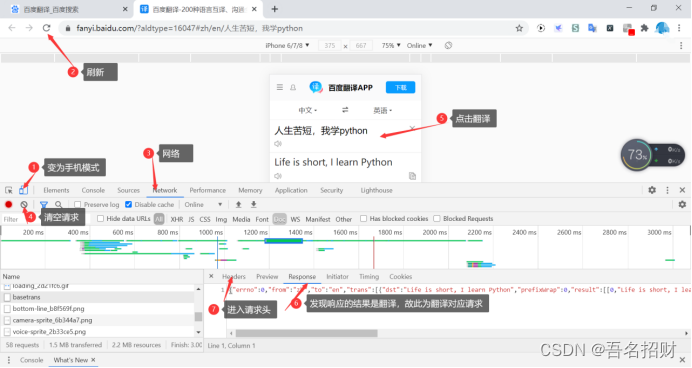
下面模拟浏览器发送post请求,能进行翻译
(1)找到要发送的url地址
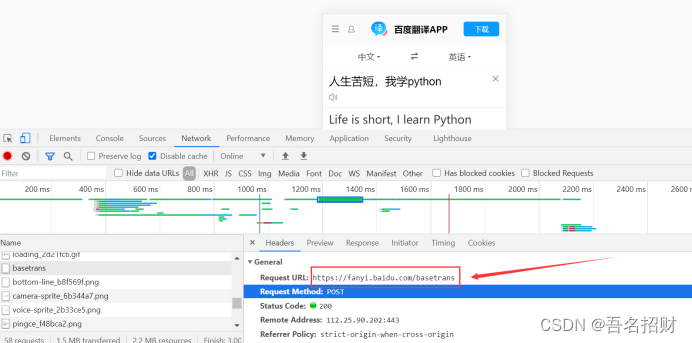
import requests
url = "https://fanyi.baidu.com/basetrans"
(2)要携带的数据,在最下方
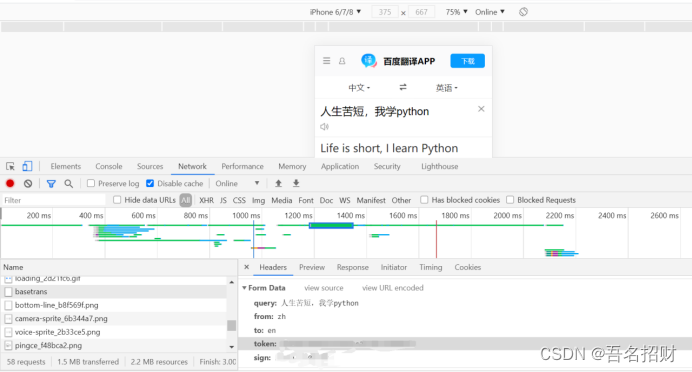
将其复制到字典中,并变成键值对的形式
程序如下(data内容并不全面,需补充,可能是导致后方,无法返回结果的原因)
data={
"query": "人生苦短,我学python",
"from":"zh",
"to": "en"
}
3,response的方法
方法一(Response.text)
该方式往往会出现乱码,出现乱码使用response.encoding=”utf-8”进行解码
ç™¾åº¦ä¸€ä¸‹ï¼Œä½ å°±çŸ
import requests
url = "http://www.baidu.com"
response = requests.get(url) #发送get请求
#print(response) #<Response [200]>尖括号表示对象,200是状态码
response.encoding="utf-8"
print(response.text)
百度一下,你就知道
方法二(response.content.decode())
把响应的二进制流转换成str类型
import requests
url = "http://www.baidu.com"
response = requests.get(url) #发送get请求
#print(response) #<Response [200]>尖括号表示对象,200是状态码
#获取网页的HTML字符串
# response.encoding="utf-8"
# print(response.text)
print(response.content.decode())
Response.requests.url #发送请求的url地址
Response.url #response响应的url地址
Response.requests.headers #请求头
Response.headers #响应请求
4,获取网页源码的正确打开方式(一定能获取网页正确解码的字符串)
当要获取网页时,使用下方的从前向后,第一种无法获取正确网页时,使用第二种,最后第三种,一定是可以能够获取的
1.response.content.decode()
2.response.content.decode("gbk")
3.reponse.content.decode('unicode-escape')
4.response.text
import requests
url = "https://fanyi.baidu.com/basetrans"
data={
"query": "人生苦短,我学python",
"from":"zh",
"to": "en"
}
reponse = requests.post(url,data=data)
print(reponse)
print(reponse.content.decode())
上方状态码是200,但是没有响应结果,虽然请求发出去了,但对方服务器将我们识别为爬虫了,所以不给响应
只有url和data是不够的,还需要headers的字段内容
5,发送带header的请求
为了模拟浏览器,获取和浏览器一模一样的内容
headers = {"user-agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1"}
当发现user-agent请求时还不能成功,需要再加入其它的参数,如下,可以将除cookie的所有参数带上,再不成功的话就只能带上cookie(百度翻译是必须要带上cookie的,有user-agent和cookie就足够了,但cookie最好不要使用自己的容易泄露很多信息)
headers = {"user-agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1","referer": "https://fanyi.baidu.com/?aldtype=16047"}
reponse = requests.post(url,data=data,headers=headers)
因为手机版的返回错误,故使用网页版的进行测试(网页版的测试成功了,手机版只有user-agent和cookie的话好像不行)
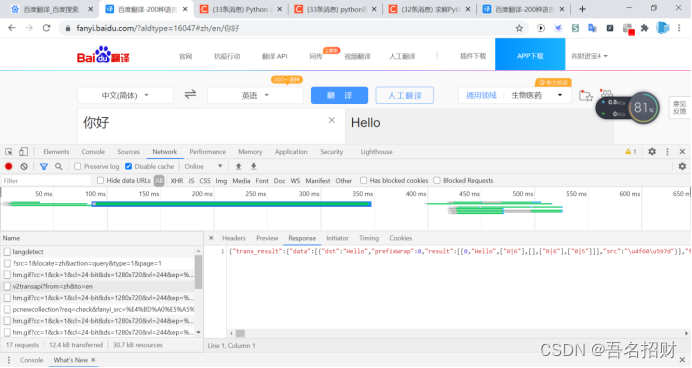
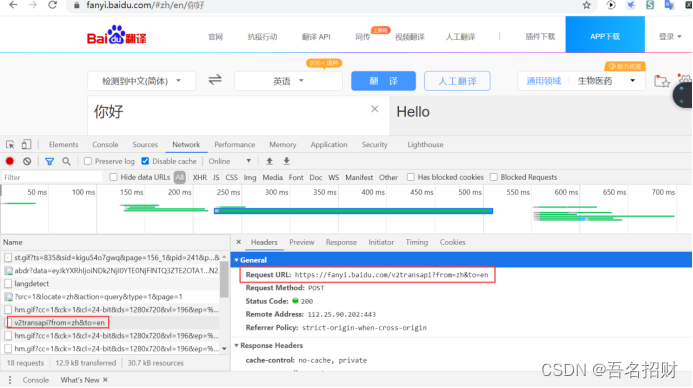
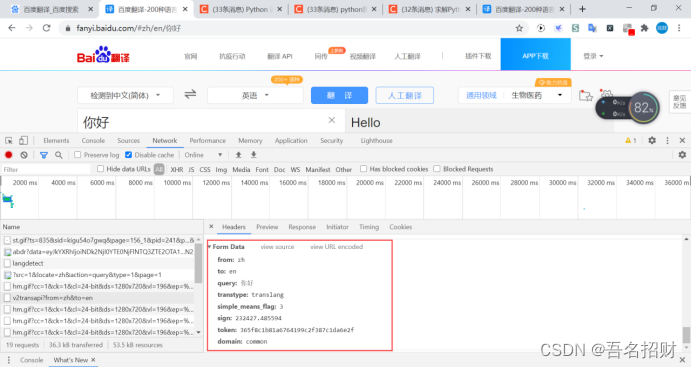
#模拟浏览器访问
url = "https://fanyi.baidu.com/v2transapi?from=zh&to=en"
data={
"from": "zh",
"to": "en",
"query": "你好",
"transtype": "translang",
"simple_means_flag": "3",
"sign": "232427.485594",
"token": "365f8c1b81a6764199c2f387c1da6e2f",
"domain": "common"
}
headers = {
# "accept-encoding": "gzip, deflate, br",
# "accept-language": "zh-CN,zh;q=0.9",
# "cache-control": "no-cache",
# "content-length": "150",
# "content-type": "application/x-www-form-urlencoded; charset=UTF-8",
# "origin": "https://fanyi.baidu.com",
# "pragma": "no-cache",
# "referer":"https://fanyi.baidu.com/v",
# "sec-fetch-destv": "empty",
# "sec-fetch-mode": "cors",
# "sec-fetch-site": "same-origin",
# "x-requested-with": "XMLHttpRequest",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
"cookie": "使用自己的"
}
reponse = requests.post(url,data=data,headers=headers)
print(reponse.content.decode())
打印结果如下,有非常多的垃圾信息
{"trans_result":{"data":[{"dst":"Hello","prefixWrap":0,"result":[[0,"Hello",["0|6"],[],["0|6"],["0|5"]]],"src":"\u4f60\u597d"}],"from":"zh","status":0,"to":"en","type":2},1\",0]],[[\"'\",\"w_332\",\"w_321,w_332\",0],[\"Hi\",\"w_333\",\"w_322,w_333\",0],[\",\",\"w_334\",\"w_323,w_334\",0,\" \"],
6,使用超时参数
平时请求一个网页,当网络不好等会出现一直刷新的情况,一旦有一个页面卡住,就会效率低,可以使用超时参数进行改进,超时参数避免超时,会报错可以进行错误捕获
Requests.get(url,headers=headers,timeout=3) #3秒内必须返回响应,否则会报错
7,Retrying模块的学习
使用retry模块,将其定义一个函数,用来进行url的访问
Retry能够执行一个函数反复执行多少次当其报错的时候
Pip install retrying
import requests
from retrying import retry
#下方是电脑版的,若是手机版的,还需要更改为手机版
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}
@retry(stop_max_attempt_number=3) #让下面被装饰的函数反复执行三次,三次全部报错才会报错,中间有一次正常,程序继续往后走
def _parse_url(url):
print("*"*100)
response = requests.get(url,headers=headers,timeout=5)
return response.content.decode()
def parse_url(url):
try:
html_str = _parse_url(url)
except:
html_str = None
return html_str
if __name__ == '__main__':
url = "http://www.baidu.com"
print(parse_url(url)[:100]) #只打印前100字符串,此处访问成功只出现一行*
url1 = "www.baidu.com" #此处地址有误
print(parse_url(url1)) #会出现三行*
8,处理cookie相关的请求
人人网
方法一,直接携带cookie请求url地址
先在页面登录了,网页检查可得到cookie
(1)cookie放在headers中
Headers = {“user-agent”:”....”,”cookie”:”cookie 字符串”}
(2)cookie字典传给cookies参数
Cookied 的字典,与上方的headers形式是完全不同的,这不详细写了,可在网上查找
Requests.get(url,cookies=cookie_dict)
有些需要登录的是需要cookie的
方法二,在程序中登录
不直接在网上登录,而是在程序中登录,输入账号,密码
先发送post请求,获取cookie,带上cookie请求登录后的页面
1.session = requests.session() #seesion具有的方法和requests一样
2.Session.post(url,data,headers) #服务器设置在本地的cookie会存在session
3.Session.get(url) #会带上之前保存在session中的cookie
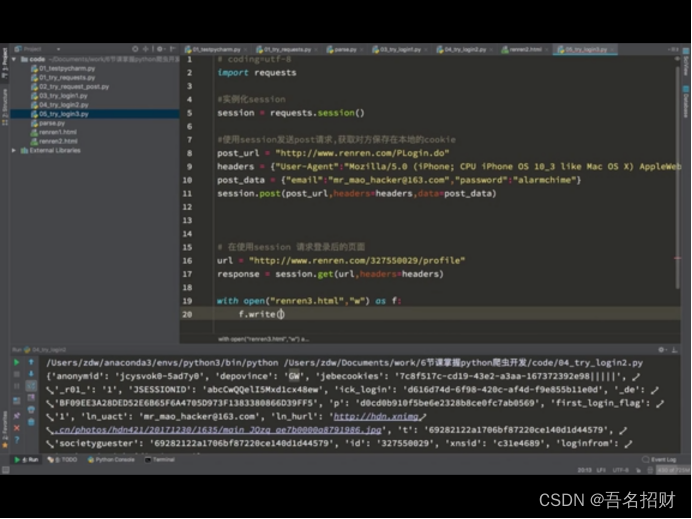
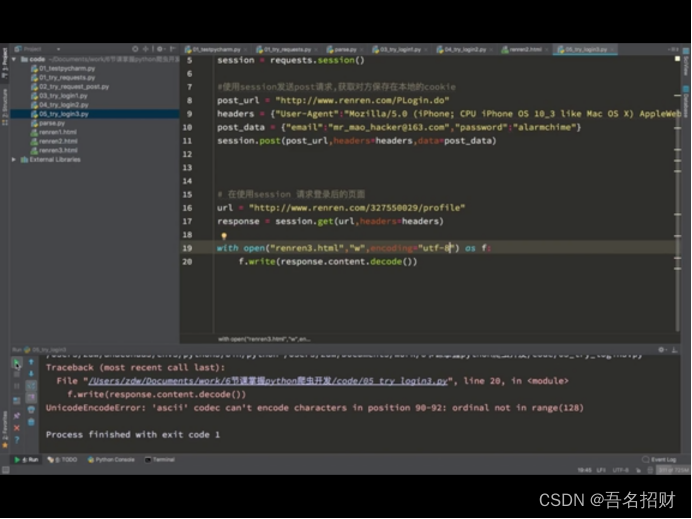
我们可以通过抓包,得到登录界面的请求post地址,
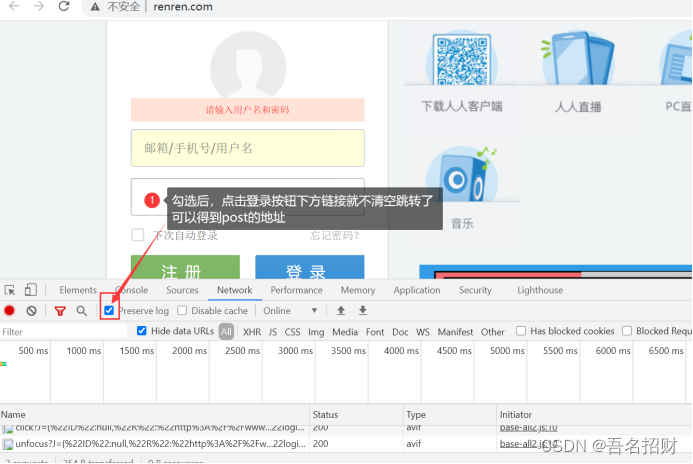
或者在form表单找action的url地址,或者模拟鼠标的selnum的模块,进行点击登录,输入账号密码(当密码在js中加密时)
在某些网站,会判断我们是否有cookie来判断我们是否为爬虫,也可以使用session先请求url地址,再
当我们使用一个用户名密码爬取大量数据,也是会被服务器认为是爬虫,这就需要有多套用户名密码,发送请求随机用户名密码进行请求