GaussDB关键技术原理:高性能(一)从数据库性能优化系统概述对GaussDB的高性能技术进行了解读,本篇将从查询处理综述方面继续分享GaussDB的高性能技术的精彩内容。
2 查询处理综述
内容概要:本章节介绍查询端到端处理的执行流程,首先让读者对查询在数据库内部如何执行有一个初步的认识,充分理解查询处理各阶段主要瓶颈点以及对应的解决方案,本章以GaussDB为例讲解查询执行的几个主要阶段,并且对相关的模块的重要优化点优化方向予以明确。
目的:通过对数据库执行处理过程的理解,能够把数据库性能调优分析的理解更加白盒化,在后续了解优化手段的同时也能够对根本内部实现原理有一个理解,能够让读者更加深入理解数据优化的核心理论实现。
2.1 查询处理流程
查询在经典数据库实现中需要依次进行以下4个环节,
(1)查询解析:对用户输入查询进行编译,把查询从文本方式翻译成执行引擎可以识别的语句。
(2)查询优化:对查询的进行基于规则的逻辑优化RBO和基于代价CBO的物理优化
(3)查询执行:将查询执行计划高效执行
(4)数据读取:实现对数据库的高效读取
(5)分布式执行:实现数据库的高效通信(分布式数据库)

对数据库的执行过程来说以上每个环节处理所花销的时间都是对最后查询执行时间的组成,因此每个环节执行效率都对性能会产生影响,决定查询端到端的性能。
2.2 查询解析器
查询解析是指将用户的SQL文本输入转换为数据库内核能够进行逻辑运算的翻译过程,SQL的解析过程主要分为以下几个阶段:

(1)词法分析Lexical Analysis:将用户输入的SQL语句拆解成单词(Token)序列,并识别出关键字、标识、常量等
(2)语法分析Syntax Analysis:分析器对词法分析器解析出来的单词(Token)序列在语法上是否满足SQL语法规则,通常识别出语法错误问题
(3)语义分析Semantic Analysis:语义分析是SQL解析过程的一个逻辑阶段,主要任务是在语法正确的基础上进行上下文有关性质的审查,在SQL解析过程中该阶段完成表名、操作符、类型等元素的合法性判断,同时检测语义上的二义性问题
以下是例举查询解析的全过程,从用户输入的SQL语句开始,依次经历了词法、语法、语义解析几个阶段:

查询解析阶段影响性能的关键因素:
(1)词法、语法分析效率
(2)语义分析效率
(3)查询的复杂度
查询解析阶段优化技术:
查询缓存技术,模板查询免解析
2.3 查询优化器
查询优化阶段主要是SQL执行过程中在优化器SQL Optimizer中执行的部分,优化器作为数据库的大脑是SQL执行路径决策者,从全局视角出发提升查询的性能,降低用户使用数据库调优的门槛。查询优化总体上分为逻辑优化、物理优化。

查询优化从总体上可以分成两类:
1、基于规则的逻辑优化(Rule-Base-Optimization),根据等价逻辑的变换让查询的计算复杂度降低,从而达到提升查询性能的作用。

上述例子中,通过等价outer join -> inner join变换,可以避免对内表结果集NULL的处理,减少了处理数据量,进而提升性能。
2、基于代价的物理优化(Cost-Base-Optimization),根据数据的分布(统计信息)情况来对查询执行路径进行评估,从可选的路径中选择一个执行代价最小的路径进行执行,例如是否选择索引SeqScan vs. IndexScan、选择哪个索引,两表关联选择什么样的连接顺序,选择怎样的具体算法等。

上述例子中,对数据量的准确评估,确定表关联的顺序,进而提升性能。
查询优化阶段的核心点:高效生成执行计划,有效消减处理数据的数据量、缩短执行流程,提升查询性能。
查询优化阶段优化技术:查询重写、基于成本预估的路径生成。
2.4 查询执行器
执行引擎负责查询的执行,在SQL执行栈中起到接受优化器生成的执行计划Plan、并对通过存储引擎提供的数据读写接口,实现对数据进行计算得到查询的结果集。在分布式数据库中,执行引擎的范围还应包括节点间网络数据交换和传输的部分。

经典的执行模型:Tuple-At-A-Time模型(Volcano-Model)
数据库的执行是把查询的处理步骤抽象成独立的基础算子,然后由执行框架驱动算子迭代的方式执行,每个算子抽象成open()/next()/close()三种操作,上层算子通过嵌套调用下层的next()进行处理数据的返回,同样初始化的过程和结束过程也通过open()/close()嵌套调用,火山模型也是大多数传统数据库实现的执行模型。
计划节点
typedef struct Operator
{
NodeTag
...
/* input plan tree(s) */
struct Operator *lefttree;
struct Operator *righttree;
...
} Plan;计划节点迭代执行
/* operator open 初始化操作 */
State *exec_init_opr(state)
{
switch(nodeTag(state)) {
...
}
}
/* operator next 执行操作 */
Tuple *exec_process(plan)
{
switch(nodeTag(plan)) {
case Scan: exec_scan();
case Join: exec_join(); // process state->left & righttree
{
exec_proc_node(state->lefttree);
exec_proc_node(state->righttree);
}
case Agg: exec_agg();
...
}
}
/* operator close 结束操作 */
void exec_deinit (state)
{
switch(nodeTag(state)) {
...
}
}关系数据库本身是对关系集合Relation的运算操作,执行引擎作为运算的控制逻辑主题夜视仪围绕着关系运算来实现的,在传统数据库实现理论中,算子的分类可以分成以下几类:
1、扫描类算子(Scan Plan Node)
扫描节点负责从底层数据来源抽取数据,数据来源可能是来自文件系统,也可能来自网络(分布式查询)。一般而言扫描节点都位于执行树的叶子节点,作为执行数的数据输入来源,典型代表SeqScan、IndexScan、SubQueryScan
关键特征:输入数据、叶子节点、表达式过滤
2、控制类算子(Control Plan Node)
控制算子一般不映射代数运算符,是为了执行器完成一些特殊的流程引入的算子,例如Limit、RecursiveUnion、Union
关键特征:用于控制数据流程
3、物化算子(Materialize Plan Node)
物化算子一般指算法要求,在做算子逻辑处理的时候,要求把下层的数据进行缓存处理,因为对于下层算子返回的数据量不可提前预知,因此需要在算法上考虑数据无法全部放置到内存的情况,例如Agg、Sort
关键特征:需要扫描所有数据之后才返回
4、连接算子(Join Plan Node)
这类算子是为了应对数据库中最常见的关联操作,根据处理算法和数据输入源的不同分成以下几种
关键特征:多个输入
传统执行模型的优缺点
-
优点:逻辑清晰,可读性可维护性较好
-
缺点:由于存在大量的function call, instruction cache missing因此运行效率低
2.5 分布式执行
分布式执行主要为分布式数据库提供一套完备的支撑数据跨节点交换,协同计算的计算框架,能够支撑位于不同地点的许多计算分片机通过网络互相连接,共同组成一个完整的、全局的逻辑上集中、物理上分布的大型数据库,数据的分布式切片方式从大的分类上有3种:
(1)Share-Memory共享内存(典型代表SQL Server),多个处理进程共享同一片内存,处理进程之间通过内部通讯机制进行通讯,通常具有很高的效率;但当更多的处理进程被添加到主机上时,内存/CPU资源竞争就成为瓶颈,进程越多瓶颈越厉害。

(2)Share-Disk共享磁盘(典型代表Oracle RAC),各个处理单元使用自己的私有 CPU和Memory,共享磁盘系统,可通过增加节点来提高并行处理的能力,扩展能力较好,类似于SMP(对称多处理)模式,这种架构需要通过一个狭窄的数据管道将所有I/O信息过滤到昂贵的共享磁盘子系统,当存储器接口达到饱和的时候,增加节点并不能获得更高的性能。

(3)Share-Nothing无共享(典型代表Teradata,GaussDB),各个处理单元都有自己私有的CPU/内存/硬盘等彼此之间相互独立,类似于MPP(大规模并行处理)模式,它是把某个表从物理存储上被水平分割,并分配给多台服务器(或多个实例),每台服务器可以独立工作,各处理单元之间通过协议通信,并行处理和扩展能力更好,只需增加服务器数就可以增加处理能力和容量,缺点是对于数据分库分表的设计存在门槛。

分布式执行-数据的分布与分区:
GaussDB的分布式部署模式采用shared-nothing方式,每个定义的表逻辑上通过分布列进行分布,通过分布类查询可以做到单DN访问。

分布式执行:数据重分布Data-Shuffling
分布式数据库中当两表关联的时候,如果有一张表的关联键不是分布键,或者发生聚集操作GroupKey不是分布键,那么就会发生表的广播或者重分布,将数据移动到一个节点上进行关联,否则查询的正确性无法得到保证。数据库工作节点数据迁移的类型主要有Broadcast广播(N:1)和Redistribute重分布(N:M)两种。
表信息:
- T1: distribute By HASH(c1)
- T2: distribute By HASH(c2)
执行查询:
- select * from t1 join t2 on t1.c1 = t2.c1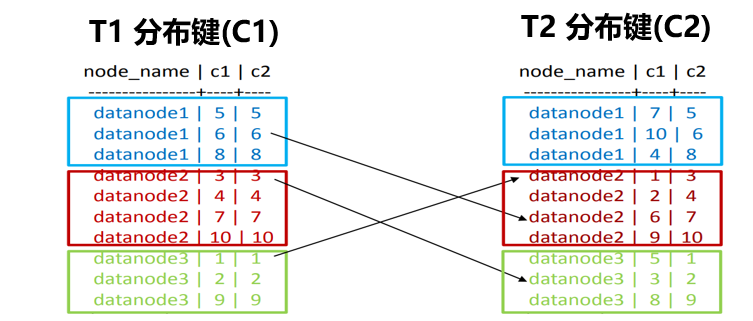
由于T1、T2的分布键不相同,直接在各个datanode上关联T1、T2查询的结果正确性无法保证。
方案1:对表T2按照t2.c1的键值进行重分布redistribute操作redis(t2)->t2’, t1 join t2’
方案2:对T1进行复制broadcast操作dup(t1)->t1’, t1’join t2
方案3:对T2进行复制broadcast操作dup(t2)->t2’, t2’join t1
对于两表关联中如果之间的Data-Locality不匹配,则需要先进行data-shuffling方可进行关联操作,data-shuffling的方案根据代价通常是数据移动的成本(数据量大小、数据倾斜)因素由优化器进行判断。
2.6 存储引擎数据读取
存储引擎主要实现高效存储数据确保数据库ACID(原子性、一致性、隔离性、持久性),正确并发读写、高性能读写等问题,从查询处理的视角通常执行算子Scan层调用存储引擎的数据读取接口进行数据读写,传统的存储引擎在查询处理的位置如下图。

GaussDB包含多种存储模式,按照存储格式划分可分为行存储格式、列存储格式,其中前者,主要适合在线交易类型业务(OLTP)而后者主要适合数据分析类型业务 (OLAP),此外还包含PAX混合存储格式,目前商用数据库支持的不多,开源的如ORC, Parquet格式,主要也是用于OLAP场景。
存储引擎主要核心模块:
(1)数据页面缓存池:数据页面读写先从页面缓存里读取和修改,如果缓存里不存在,再从数据文件读取页面。
(2)堆表Heap:表数据存储格式和访问接口
(3)索引Index:高效查询表数据
(4)日志WAL: 修改数据页面,必须先写WAL日志(redo log), 事务提交之前和脏页写盘之前必须保证WAL日志持久化到存储设备。
(5)事务并发控制: 正确读写,高性能并发读写。
(6)事务提交日志: 事务状态和提交时间戳
(7)WAL日志恢复:从检查点日志往后回放WAL日志
索引技术

索引在数据库中的实现为B树结构,索引的键值按照B树进行排序,能够将索引键值的查找由线性查找优化成B树查找。
(1)对于非叶子节点,indexTup指向下一个节点,而对于叶子节点,indexTup指向堆表里的行
(2)Special space中,实现了两个指针,用于指向左右兄弟节点。
(3)索引元组有序,第一个叶子节点中indexTup3实际为最大健值索引元组,即high key,第二个叶子节点中IndexTup1跟indexTup3指向相同的堆表中的行。High key是为了减少比较次数。
数据页面缓冲区
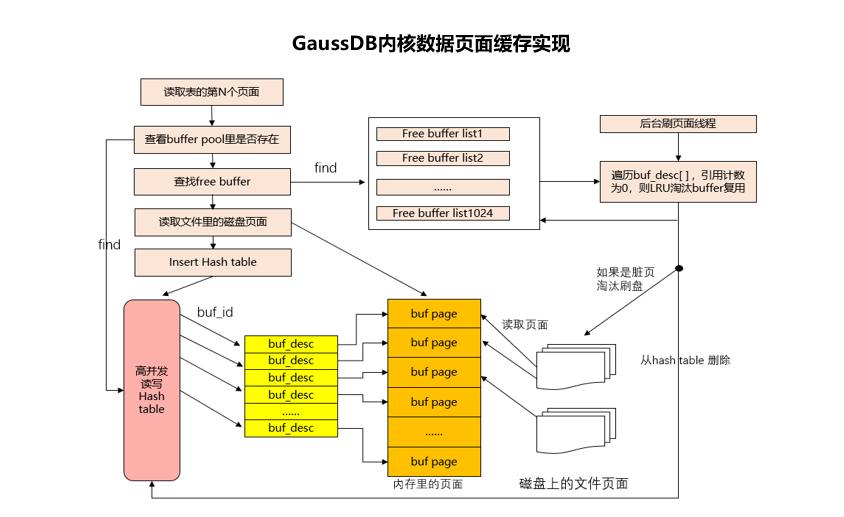
数据页面缓冲池设计主要是为了减少磁盘的读写。读页面尽可能多的命中内存buffer page,减少磁盘读取页面, 写操作批量刷盘, 而不是每修改一条数据,就写数据页面。
(1)为了提高缓存命中率,设计缓存淘汰算法来保证频繁访问的热页面尽量在内存buffer里
(2)设计多个buffer pool用于缓存不同的对象,一方面为了减少冲突,同时也提高了缓存命中率
(3)对于批量导入和批量读取的场景, 为避免污染整个buffer pool, 顺序读取一遍表数据,把整个buffer pool里页面都淘汰。设计buffer 批量读写获取策略,采用buffer ring的策略,固定范围的获取free buffer。
以上内容为查询处理综述的相关内容,下篇将分享高性能关键技术的精彩内容,敬请期待!