目录
一、引言
二、Qwen-VL 介绍
2.1 Qwen-VL 特点
2.2 Qwen-VL 原理
2.3 Qwen-VL 模型结构
三、FastAPI封装Qwen-VL大模型服务接口
3.1 FastAPI 极简入门
3.1.1 FastAPI
3.1.2 uvicorn
3.1.3 pydantic
3.2 QwenVL-API服务端
3.2.1 代码示例
3.2.2 代码详解
3.2.3 代码使用
3.3 QwenVL-API客户端
3.3.1 代码示例
3.3.2 代码要点
3.3.2 代码使用
四、总结
一、引言
之前在热榜第一🏆文章GLM-4中提到了最新开源的GLM-4V-9B多模态模型,其中采用python对GLM-4V-9B推理方法进行实现,而实际应用到项目中,仅有推理代码只能进行离线测试,如果想应用到线上,还是需要封装成OpenAI兼容的API接口。今天我们基于FastAPI,以Qwen-VL为例,讲述如何封装一个私有化的多模态大模型(MLLMs)。
OpenAI兼容的API接口(OpenAI-API-compatible):是个很重要的接口规范,由大模型王者OpenAI制定,简单来说就是接口名、传参方式、参数格式统一仿照OpenAI的接口方式,这样可以降低使用接口的学习与改造,做到多厂商、多模型兼容。
- DIFY平台:自定义的接口要求复合OpenAI兼容API规范才能使用
- vLLM、Ollama、Xinference等开源推理框架:接口均参照OpenAI兼容API规范
本文基于FastAPI简单实现了一个遵照OpenAI兼容接口的Qwen-VL服务端和客户端接口,用于交流学习,如有问题与建议欢迎大家留言指正!
二、Qwen-VL 介绍
2.1 Qwen-VL 特点
Qwen-VL 是阿里云研发的大规模视觉语言模型(Large Vision Language Model, LVLM)。Qwen-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。Qwen-VL 系列模型的特点包括:
- 强大的性能:在四大类多模态任务的标准英文测评中(Zero-shot Captioning/VQA/DocVQA/Grounding)上,均取得同等通用模型大小下最好效果;
- 多语言对话模型:天然支持英文、中文等多语言对话,端到端支持图片里中英双语的长文本识别;
- 多图交错对话:支持多图输入和比较,指定图片问答,多图文学创作等;
- 首个支持中文开放域定位的通用模型:通过中文开放域语言表达进行检测框标注;
- 细粒度识别和理解:相比于目前其它开源LVLM使用的224分辨率,Qwen-VL是首个开源的448分辨率的LVLM模型。更高分辨率可以提升细粒度的文字识别、文档问答和检测框标注。
目前,提供了 Qwen-VL 系列的两个模型:
- Qwen-VL: Qwen-VL 以 Qwen-7B 的预训练模型作为语言模型的初始化,并以 Openclip ViT-bigG 作为视觉编码器的初始化,中间加入单层随机初始化的 cross-attention,经过约1.5B的图文数据训练得到。最终图像输入分辨率为448。
- Qwen-VL-Chat: 在 Qwen-VL 的基础上,我们使用对齐机制打造了基于大语言模型的视觉AI助手Qwen-VL-Chat,它支持更灵活的交互方式,包括多图、多轮问答、创作等能力。
2.2 Qwen-VL 原理
Qwen-VL模型网络包括视觉编码器(Vision Encoder)、视觉语言适配器(VL Adapter)、语言模型(LLM)三部分,其中编码器1.9B、视觉语言适配器0.08B、语言模型7.7B,共计9.6B。(GLM-4V-9B)约13B。两者视觉编码器占比分别为20%和30%。
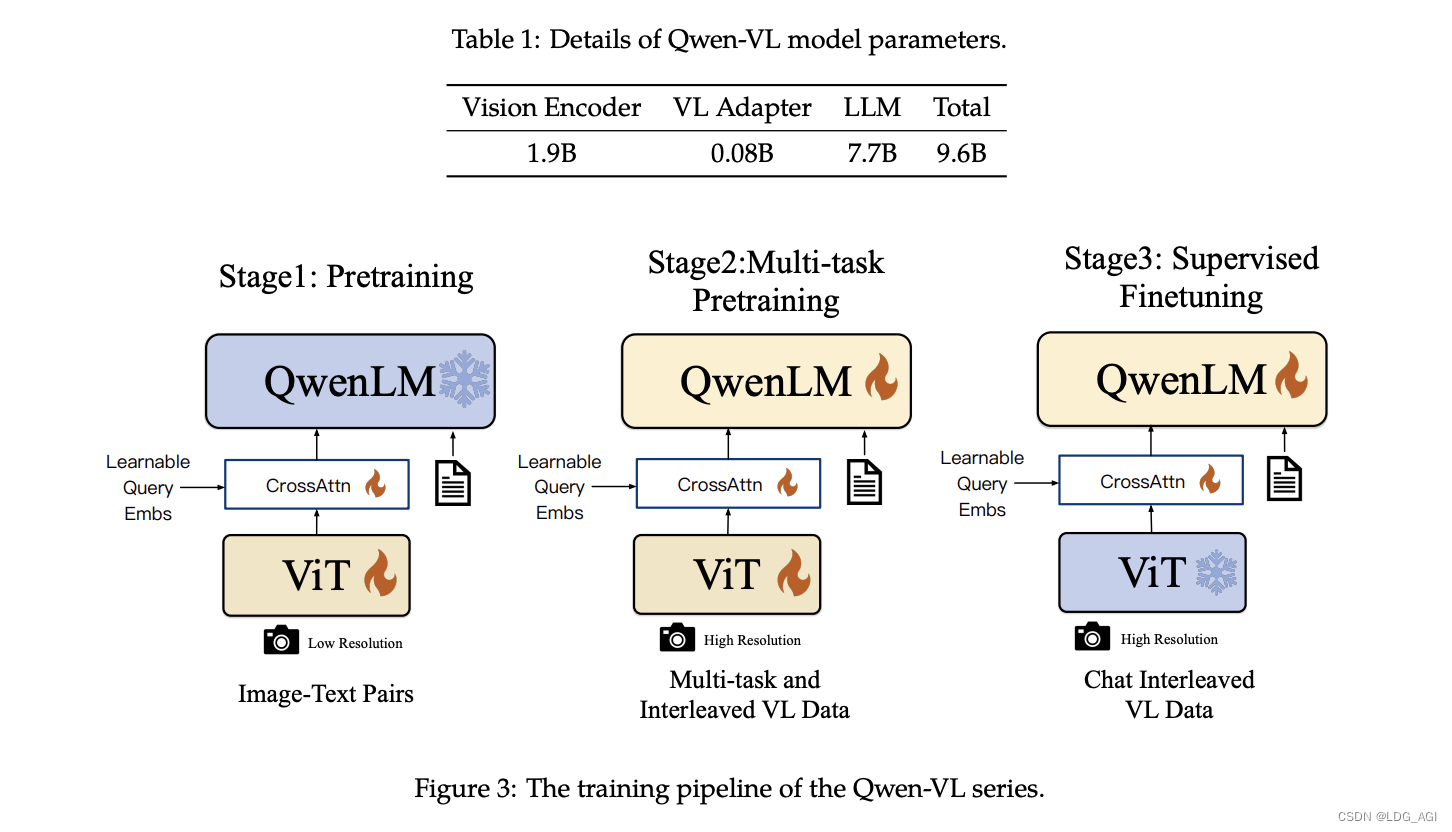
具体的训练过程分为三步:
- 预训练:只优化视觉编码器和视觉语言适配器,冻结语言模型。使用大规模图像-文本配对数据,输入图像分辨率为224x224。
- 多任务预训练:引入更高分辨率(448x448)的多任务视觉语言数据,如VQA、文本VQA、指称理解等,进行多任务联合预训练。
- 监督微调:冻结视觉编码器,优化语言模型和适配器。使用对话交互数据进行提示调优,得到最终的带交互能力的Qwen-VL-Chat模型。
2.3 Qwen-VL 模型结构
通过之前的文章中讲述的使用transformers查看model结构的方法,查看模型结构如下,包含以下几个部分
- ModuleList语言模型部分:包含32个QwenBlock,每个QwenBlock中包含1个QwenAttention和QwenMLP
- ViT视觉编码器部分:包含TransformerBlock和Resampler部分:
- TransformerBlock包含48个VisualAttentionBlock,每个VisualAttentionBlock包含1个1664维输入的VisualAttention和1个Sequential的mlp
- Resampler包含1个MultiheadAttention
QWenLMHeadModel(
(transformer): QWenModel(
(wte): Embedding(151936, 4096)
(drop): Dropout(p=0.0, inplace=False)
(rotary_emb): RotaryEmbedding()
(h): ModuleList(
(0-31): 32 x QWenBlock(
(ln_1): RMSNorm()
(attn): QWenAttention(
(c_attn): Linear(in_features=4096, out_features=12288, bias=True)
(c_proj): Linear(in_features=4096, out_features=4096, bias=False)
(attn_dropout): Dropout(p=0.0, inplace=False)
)
(ln_2): RMSNorm()
(mlp): QWenMLP(
(w1): Linear(in_features=4096, out_features=11008, bias=False)
(w2): Linear(in_features=4096, out_features=11008, bias=False)
(c_proj): Linear(in_features=11008, out_features=4096, bias=False)
)
)
)
(ln_f): RMSNorm()
(visual): VisionTransformer(
(conv1): Conv2d(3, 1664, kernel_size=(14, 14), stride=(14, 14), bias=False)
(ln_pre): LayerNorm((1664,), eps=1e-06, elementwise_affine=True)
(transformer): TransformerBlock(
(resblocks): ModuleList(
(0-47): 48 x VisualAttentionBlock(
(ln_1): LayerNorm((1664,), eps=1e-06, elementwise_affine=True)
(ln_2): LayerNorm((1664,), eps=1e-06, elementwise_affine=True)
(attn): VisualAttention(
(in_proj): Linear(in_features=1664, out_features=4992, bias=True)
(out_proj): Linear(in_features=1664, out_features=1664, bias=True)
)
(mlp): Sequential(
(c_fc): Linear(in_features=1664, out_features=8192, bias=True)
(gelu): GELU(approximate='none')
(c_proj): Linear(in_features=8192, out_features=1664, bias=True)
)
)
)
)
(attn_pool): Resampler(
(kv_proj): Linear(in_features=1664, out_features=4096, bias=False)
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=4096, out_features=4096, bias=True)
)
(ln_q): LayerNorm((4096,), eps=1e-06, elementwise_affine=True)
(ln_kv): LayerNorm((4096,), eps=1e-06, elementwise_affine=True)
)
(ln_post): LayerNorm((4096,), eps=1e-06, elementwise_affine=True)
)
)
(lm_head): Linear(in_features=4096, out_features=151936, bias=False)
)三、FastAPI封装Qwen-VL大模型服务接口
3.1 FastAPI 极简入门
搭建1个FastAPI服务依赖fastapi、pydantic、uvicorn三个库:
3.1.1 FastAPI
FastAPI是一个现代、快速(高性能)的Web框架,用于构建API,用Python编写。它基于标准的Python类型提示,提供自动的交互式文档和数据验证。
代码示例:
# 导入FastAPI模块
from fastapi import FastAPI
# 创建一个FastAPI实例
app = FastAPI()
# 定义一个路径操作函数
@app.get("/")
async def root():
# 返回一个JSON响应
return {"message": "Hello World"}
# 运行应用
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)这段代码创建了一个简单的FastAPI应用,当访问根路径/时,会返回一个包含"Hello World"的消息。可以使用uvicorn运行这个应用,它是一个ASGI服务器,FastAPI是基于ASGI构建的
3.1.2 uvicorn
uvicorn是一个ASGI(Asynchronous Server Gateway Interface)服务器,用于运行现代的异步Python Web应用,如FastAPI。以下是如何使用uvicorn运行一个FastAPI应用的步骤:
假设你有一个名为main.py的文件,其中包含你的FastAPI应用:
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Hello World"}可以使用以下命令运行你的应用:
uvicorn main:app --reload这里的main是你的Python文件名(不包括.py扩展名),app是你的FastAPI实例的变量名。--reload标志告诉uvicorn在代码更改时自动重新加载应用,这对于开发非常有用。
3.1.3 pydantic
Pydantic是一个Python库,用于数据验证和设置管理。它被广泛用于FastAPI中,用于定义请求和响应模型,以进行数据验证和解析。
from pydantic import BaseModel
class Item(BaseModel):
name: str
description: str = None
price: float
tax: float = None
tags: list = []
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2},
"baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []},
}
item = Item(**items["foo"])
print(item)
# 输出: Item(name='Foo', description=None, price=50.2, tax=None, tags=[])3.2 QwenVL-API服务端
3.2.1 代码示例
from fastapi import FastAPI
from pydantic import BaseModel
import uvicorn
import requests
from io import BytesIO
from modelscope import snapshot_download
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
from PIL import Image
#import os
#os.environ["CUDA_VISIBLE_DEVICES"] = "1,2"
#model_dir = snapshot_download('ZhipuAI/glm-4v-9b')
model_dir = snapshot_download('qwen/Qwen-VL-Chat')
device = "auto"
tokenizer = AutoTokenizer.from_pretrained(model_dir,trust_remote_code=True)
qwen_vl = AutoModelForCausalLM.from_pretrained(model_dir, device_map=device, trust_remote_code=True,fp16=True).eval()
# 创建FastAPI应用实例
app = FastAPI()
# 定义请求体模型,与OpenAI API兼容
class ChatCompletionRequest(BaseModel):
model: str
messages: list
max_tokens: int = 1024
temperature: float = 0.7
# 文本生成函数
def generate_text(model: str, messages: list, max_tokens: int, temperature: float):
text = messages[0]["content"][0]["text"]
image_url = messages[0]["content"][1]["image_url"]["url"]
#print(text,image_url)
query = tokenizer.from_list_format([
{'image': image_url}, # Either a local path or an url
{'text': text}
])
response, history = qwen_vl.chat(tokenizer, query=query, history=None,max_new_tokens=max_tokens)
return response
# 定义路由和处理函数,与OpenAI API兼容
@app.post("/v1/chat/completions")
async def create_chat_completion(request: ChatCompletionRequest):
# 调用自定义的文本生成函数
response = generate_text(request.model, request.messages, request.max_tokens, request.temperature)
return {"choices": [{"message": {"content": response}}],"model": request.model}
# 启动FastAPI应用
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8888)3.2.2 代码详解
- 环境:在代码之前建立conda环境、pip代码中依赖的库,这个地方不讲啦,可以看之前的文章
- 下载必要的库:如上一节讲到的fastapi、pydantic、uvicorn等用于搭建api服务的库,以及modelscope、transformers、torch,以及图片处理的库io、PIL等
- 下载模型:基于modelscope的snapshot_download下载模型文件,专为网络不稳定的开发者服务
- 实例化分词器和模型:模型基于transformers的AutoTokenizer、AutoModelForCausalLM建立分词器和模型qwen_vl
- 实例化FastAPI:通过app=FastAPI()创建fastapi实例
- 定义请求体模型:继承pydantic的BaseModel,参数需要兼容OpenAI API
- 从主函数开始看:通过uvicorn.run启动Fastapi实例app,配置host和port
- 定义app的路由:路由指向v1/chat/completions
- 定义app的处理函数:处理函数调用generate_text函数,传入request接收的兼容OpenAI的请求体模型。
- 文本和图像生成generate_text:提取query、image_url,构造query,传入qwen_vl.chat(),基于图片和文本生成response返回
- API返回格式:拼接choices、message、content等构造兼容OpenAI API的返回
3.2.3 代码使用
使用CUDA_VISIBLE_DEVICES=2 python run_api_qwenvl.py启动,指定卡2运行api服务。

显存占用18.74G(模型尺寸9.6B,根据我们之前提过很多次的经验,推理模型显存占用=模型尺寸*2=9.6*2=19.2G)

3.3 QwenVL-API客户端
3.3.1 代码示例
import requests
import json
# 定义请求的URL
url = "http://0.0.0.0:8888/v1/chat/completions"
# 定义请求体
data = {
"model": "qwen-vl",
"messages":[{"role":"user","content":[{"type":"text","text":"这是什么?"},{"type":"image_url","image_url":{"url":"https://img1.baidu.com/it/u=1369931113,3388870256&fm=253&app=138&size=w931&n=0&f=JPEG&fmt=auto?sec=1703696400&t=f3028c7a1dca43a080aeb8239f09cc2f"}}]}],
"max_tokens": 1024,
"temperature": 0.5
}
# 将字典转换为JSON格式
headers = {'Content-Type': 'application/json'}
data_json = json.dumps(data)
# 发送POST请求
response = requests.post(url, data=data_json, headers=headers)
# 检查响应状态码
if response.status_code == 200:
# 如果响应成功,打印响应内容
print(response.json())
else:
# 如果响应失败,打印错误信息
print(f"Error: {response.status_code}, {response.text}")3.3.2 代码要点
requests:采用requests库进行请求,requests是一个在Python中用于发送HTTP请求的库。它允许你发送各种类型的HTTP请求,如GET、POST、PUT、DELETE等,以及处理响应。requests库的一个主要优点是它的易用性和简洁的API。
请求体data定义:完全模仿OpenAI API请求结构,服务端也根据此结构规范处理。
headers请求头:接口请求格式为JSON,采用json.dumps可以将字典型的data转换为json字符串,用于请求时采用json格式传输。更多json用法可以参考之前的文章
3.3.2 代码使用
将以上客户端代码放入post_api.py中,采用python post_api.py调用服务端接口。
比如传入的图片为:

qwen-vl输出为
![]()
“这是海面,可以看到远处的海平线和海岸线。天空中飘着美丽的云彩。”
glm-4v输出为

“这是一张展示海滨风景的图片。图中可以看到一片宁静的海洋,海面上有几块岩石露出水面。天空呈现出深浅不一的蓝色,其中散布着一些白云。在远处,可以看到陆地和大海的交界线,以及一些小岛或陆地突起。整个场景给人一种宁静、宽广的感觉。”
看起来glm-4v的效果要好一些,主要原因:
- 发布日期:qwen-vl发布于2023年8月22日,glm-4v发布于2024年6月6日,隔着将近一年
- 分辨率:qwen-vl是448*448,glm-4v是1120*1120
- 模型尺寸:qwen-vl是9.6B,glm-4v是13B
期待qwen2-vl的诞生吧!
四、总结
本文首先在引言中强调了一下OpenAI兼容API的重要性,希望引起读者重视,其次介绍了Qwen-VL的原理与模型结构,最后简要讲了下FastAPI以及搭配组件,并基于FastAPI封装了OpenAI兼容API的Qwen-VL大模型服务端接口,并给出了客户端实现。本文内容在工作中非常实用,希望大家能有所收获并与我交流。期待您的关注+三连!
文末按照要求附Qwen-VL在gitcode的链接,期待获得csdn的第一个奖项:GitCode - 全球开发者的开源社区,开源代码托管平台
如果您还有时间,可以看看我的其他文章:
《AI—工程篇》
AI智能体研发之路-工程篇(一):Docker助力AI智能体开发提效
AI智能体研发之路-工程篇(二):Dify智能体开发平台一键部署
AI智能体研发之路-工程篇(三):大模型推理服务框架Ollama一键部署
AI智能体研发之路-工程篇(四):大模型推理服务框架Xinference一键部署
AI智能体研发之路-工程篇(五):大模型推理服务框架LocalAI一键部署
《AI—模型篇》
AI智能体研发之路-模型篇(一):大模型训练框架LLaMA-Factory在国内网络环境下的安装、部署及使用
AI智能体研发之路-模型篇(二):DeepSeek-V2-Chat 训练与推理实战
AI智能体研发之路-模型篇(三):中文大模型开、闭源之争
AI智能体研发之路-模型篇(四):一文入门pytorch开发
AI智能体研发之路-模型篇(五):pytorch vs tensorflow框架DNN网络结构源码级对比
AI智能体研发之路-模型篇(六):【机器学习】基于tensorflow实现你的第一个DNN网络
AI智能体研发之路-模型篇(七):【机器学习】基于YOLOv10实现你的第一个视觉AI大模型
AI智能体研发之路-模型篇(八):【机器学习】Qwen1.5-14B-Chat大模型训练与推理实战
AI智能体研发之路-模型篇(九):【机器学习】GLM4-9B-Chat大模型/GLM-4V-9B多模态大模型概述、原理及推理实战
AI智能体研发之路-模型篇(十):【机器学习】Qwen2大模型原理、训练及推理部署实战
《AI—Transformers应用》
【AI大模型】Transformers大模型库(一):Tokenizer
【AI大模型】Transformers大模型库(二):AutoModelForCausalLM
【AI大模型】Transformers大模型库(三):特殊标记(special tokens)
【AI大模型】Transformers大模型库(四):AutoTokenizer
【AI大模型】Transformers大模型库(五):AutoModel、Model Head及查看模型结构
【AI大模型】Transformers大模型库(六):torch.cuda.OutOfMemoryError: CUDA out of memory解决
【AI大模型】Transformers大模型库(七):单机多卡推理之device_map
【AI大模型】Transformers大模型库(八):大模型微调之LoraConfig