文章目录
- 1 机器学习的四个分支
- 1.1 监督学习
- 1.2 无监督学习
- 1.3 自监督学习
- 1.4 强化学习
- 2 评估机器学习模型
- 2.1 训练集、验证集和测试集
- 2.2 注意事项
- 3 数据预处理、特征工程和特征学习
- 3.1 神经网络的数据预处理
- 3.2 特征工程
- 4 过拟合与欠拟合
- 4.1 减小网络大小
- 4.2 添加权重正则化
- 4.3 添加dropout正则化
- 5 机器学习的通用工作流程
- 5.1 定义问题,收集数据集
- 5.2 选择衡量成功的指标
- 5.3 确定评估方法
- 5.4 准备数据
- 5.5 开发比基准更好的模型
- 5.6 扩大模型规模:开发过拟合的模型
- 5.7 模型正则化与调节超参数
1 机器学习的四个分支
1.1 监督学习
1.定义
给定一组样本(通常由人工标注),它可以学会将输入数据映射到已知目标(标注)。
2.除了分类和回归外,监督学习的其他变体
- 序列生成,给定一张图像,预测描述图像的文字;
- 语法树预测,给定一个句子,预测其分解生成的语法树;
- 目标检测,给定一张图像,在图中特定目标的周围画一个边界框;
- 图像分割,给定一张图像,在特定物体上画一个像素级的mask;
1.2 无监督学习
1.定义
指在没有目标的情况下,寻找输入数据的变换形式。
2.实例
- 降维
- 聚类
1.3 自监督学习
1.定义
指没有人工标注的标签的监督学习,但标签仍然存在,它们是从输入数据中生成的,通常使用启发式算法生成。
2.实例
- 自编码器,其生成的目标就是未经修改的输入;
- 给定视频中过去的帧来预测下一帧,这也属于时序监督学习,用未来的输入数据作为监督。
1.4 强化学习
1.定义
智能体接收有关环境的信息,并学会选择使得某种奖励最大化的行动。
2 评估机器学习模型
2.1 训练集、验证集和测试集
1.三种经典的评估方法
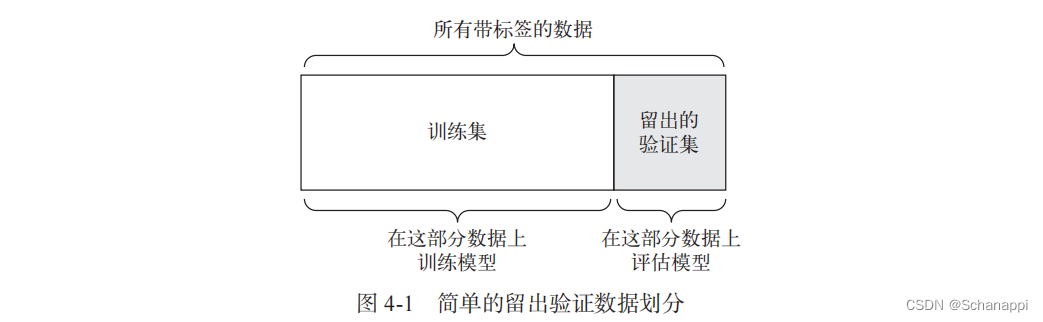
(1)简单的留出验证
- 方法:留出一定比例的数据作为测试集,在剩余的数据上训练和验证模型,然后在测试集上评估模型。
- 缺点:如果可用的数据太少,那么验证集和测试集包含的样本就很少,无法在统计学上代表数据。
num_validation_samples = 10000
np.random.shuffle(data) # 打乱数据
validation_data = data[:num_validation_samples] # 定义验证集
data = data[num_validation_samples:]
training_data = data[:] # 定义训练集
# 在训练数据上训练模型,并在验证数据上评估模型
model = get_model()
model.train(training_data)
validation_score = model.evaluate(validation_data)
# 调节模型、重新训练、评估,然后再次调节
# 一旦调节好超参数,通常就在所有非测试数据上从头训练最终模型
model = get_model()
model.train(np.concatenate([training_data, validation_data]))
test_score = model.evaluate(test_data)
(2)K折验证
- 方法:将数据划分为大小相同的K个分区,对于每个分区i,在剩余的K-1个分区上训练模型,然后在分区i上评估模型,最终分数等于K个分数的平均值。
- 优点:适用于模型性能变化很大的情况。

k = 4
num_validation_samples = len(data) // 4
np.random.shuffle(data)
validation_scores = []
for fold in range(k):
# 选择验证数据分区
validation_data = data[num_validation_samples * fold :
num_validation_samples * (fold + 1)]
# 使用剩余数据作为训练数据
training_data = data[: num_validation_samples * fold] +
data[num_validation_samples * (fold + 1) :]
# 创建一个全新模型
model = get_model()
model.train(training_data)
validation_score = model.evaluate(validation_data)
validation_scores.append(validation_score)
# 最终验证分数:K折验证分数的平均值
validation_score = np.average(validation_scores)
# 在所有非测试数据上训练最终模型
model = get_model()
model.train(data)
test_score = model.evaluate(test_data)
(3)带有打乱数据的重复K折验证
- 方法:多次使用K折验证,在每次将数据划分为K个分区之前都先将数据打乱,最终分数是每次K折验证分数的平均值。这种方法需要训练和评估P * K个模型(P是重复次数)。
- 优点:适用于可用数据较少,但又需要尽可能精确地评估模型。
- 缺点:计算代价很大。
2.2 注意事项
- 数据代表性。例如,需要对数字图像进行分类,而图像样本是按类别分类的,此时在将数据划分为训练集和测试集之前,通常应该打乱数据。
- 时间箭头。如果想要根据过去预测未来,那么在划分数据前不应该打乱数据,要始终确保测试集中所有数据的时间晚于训练集数据。
- 数据冗余。确保训练集和验证集之间没有交集
3 数据预处理、特征工程和特征学习
3.1 神经网络的数据预处理
1.向量化
神经网络的所有输入和目标都必须是浮点数张量(特定情况下可以是整数张量)。无论处理什么数据,都必须先将其转换为张量,这一步骤叫做数据向量化。
2.值标准化
(1)输入数据应该具有以下特征
- 取值较小,大部分值应该在0~1范围内;
- 同质性,所有特征的取值都应该在大致相同的范围内。
(2)标准化方法
将每个特征分别标准化,使其平均值为0、标准差为1。
x -= x.mean(axis=0)
x /= x.std(axis=0)
3.处理缺失值
一般而言,对于神经网络,将缺失值设为0是安全的。
如果测试数据中存在缺失值,而网络是在没有缺失值的数据上训练的,那么网络不可能学会忽略缺失值。在这种情况下,应该人为生成一些有缺失项的训练样本:多次复制一些训练样本,然后删除测试数据中可能缺失的某些特征。
3.2 特征工程
定义:指在将数据输入模型之前,利用你自己关于数据和机器学习算法的知识对数据进行硬编码的转换,以改善模型效果。其实就是用更简单的方式表述问题,从而进行简化。
4 过拟合与欠拟合
为了避免过拟合,最好的解决方法是获取更多的训练数据。
但是如果没办法获取更多数据,次优的解决方法是调节模型允许存储的信息量,或对模型允许存储的信息加以约束。这种方法叫做正则化,接下来介绍几种常见的正则化方法。
4.1 减小网络大小
1.定义
减少模型大小,即减少模型中可学习参数的个数(由层数和每层的单元个数决定),这也叫做模型容量。
2.合理性
如果网络的记忆资源有限,就很难学会输入数据和目标之间的映射,因此,为了让损失最小化,网络必须学会对目标具有很强预测能力的压缩表示。
3.一般的工作流程
在验证集上评估一系列不同的网络架构,开始选择相对较少的层和参数,然后逐渐增加层的大小或增加新层,直到这种增加对验证损失的影响变得很小。
4.2 添加权重正则化
1.定义
强制让模型权重只能取较小的值,从而限制模型的复杂度,使得权重值的分布更加规则。
2.实现方法
向网络损失函数中添加与较大权重值相关的成本,成本有两种形式:
- L1正则化,添加的成本与权重系数的绝对值(权重的L1范数(norm))成正比;
- L2正则化,添加的成本与权重系数的平方(权重的L2范数)成正比,L2正则化也叫作权重衰减。
3.在Keras中,添加权重正则化的方法是向层传递权重正则化实例作为关键字参数。
l2(0.001) 的意思是该层权重矩阵的每个系数都会使网络总损失增加0.001 * weight_coefficient_value。
from keras import models
from keras import layers
from keras import regularizers
model = models.Sequential()
model.add(layers.Dense(16, kenel_regularizer=regularizers.l2(0.001),
activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, kenel_regularizer=regularizers.l2(0.001),
activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
另外,还可以使用以下这些权重正则化来代替L2正则化。
# L1正则化
regularizers.l1(0.001)
# 同时做L1和L2正则化
regularizers.l1_l2(l1=0.001, l2=0.001)
4.3 添加dropout正则化
1.定义
对某一层使用dropout,就是在训练过程中随机将该层的一些输出特征舍弃(设置为0)。
drop比率是被设为0的特征所占的比例,通常在0.2~0.5之间。
测试时没有单元被舍弃,而该层的输出值需要按dropout比率缩小,因为这时比训练时有更多的单元被激活,需要加以平衡。
2.实例
假设一个包含某层输出的Numpy矩阵layer_output,其形状为(batch_size, features)。
(1)训练时,随机将矩阵中的一部分值设为0:
# 训练时,舍弃50%的输出单元
layer_output *= np.random.randint(0, high=2, size=layer_output.shape)
(2)测试时,将输出按照dropout比率缩小,在这里乘以0.5,因为前面舍弃了50%的单元:
layer_output *= 0.5
为了实现上述过程,还可以让两个运算在训练时进行,而测试时保持输出不变:
layer_output *= np.random.randint(0, high=2, size=layer_output.shape)
layer_output /= 0.5 # 在训练时应该是成比例放大
3.在Keras中,可以通过Dropout层向网络中引入dropout,它将被应用于前面一层的输出。
model.add(layers.Dropout(0.5))
5 机器学习的通用工作流程
5.1 定义问题,收集数据集
- 假设输出是可以根据输入进行预测的;
- 假设可用数据包含足够多的信息,足以学习输入和输出之间的关系。
5.2 选择衡量成功的指标
衡量成功的指标应该直接与目标保持一致。
- 对于平衡分类问题,使用精度和接收者操作特征曲线下面积(ROC AUC);
- 对于不平衡分类问题,使用准确率和召回率;
- 对于排序问题或多标签分类,使用平均准确率均值。
5.3 确定评估方法
- 留出验证集,适用于数据量很大的情况;
- K折交叉验证,适用于留出验证的样本量太少的情况;
- 重复的K折交叉验证,适用于可用数据量很少,同时模型评估又需要非常准确的情况。
5.4 准备数据
5.5 开发比基准更好的模型
1.目标
获得统计功效,即开发一个小型模型,能够打败纯随机的基准。
2.构建第一个工作模型的三个关键参数
- 最后一层的激活,对网络输出进行有效的限制;
- 损失函数,有时候难以将指标转化为损失函数,此时可以选择替代指标。
- 优化配置。
5.6 扩大模型规模:开发过拟合的模型
在得到具有统计功效的模型后,需要开发一个过拟合的模型,始终监控训练损失和验证损失,以及所关心的指标的训练值和验证值。一旦模型在验证数据上的性能开始下降,那么就出现了过拟合。
下一阶段将开始正则化和调节模型,以便尽可能地接近理想模型。
5.7 模型正则化与调节超参数
在这一步骤中,将要不断调节模型、训练、在验证数据上评估,再次调节模型,然后重复这一过程,直到模型达到最佳性能。
但是,如果多次使用验证过程来反馈调节模型, 会降低验证过程的可靠性。