来源:投稿 作者:LSC
编辑:学姐
一、视频分析处理的完整流程
(1)视频编解码的入门知识
尽管压缩工具五花八门,但是他们的目的都只有一个:都是为了减小文件的占用空间。
除去我们常见的.zip,.7z,.rar等格式外,其实我们接触的.mp3,.mp4,.AVI等格式也都有着压缩的作用。只不过和.zip这样的专有的压缩格式相比他们执行的是有损压缩。
为什么要进行视频压缩呢? 因为未经压缩的数字视频的数据量巨大;储存困难:一张DVD只能储存几秒钟未压缩的数字视频。
(2)为什么可以压缩
压缩的本质就是——去除冗余信息:
-
空间冗余:图像相邻像素之间有较强的相关性
-
时间冗余:视频序列的相邻图像之间内容相似
-
编码冗余:不同像素值出现的概率不同
-
视觉冗余:人的视觉系统对某些细节不敏感
-
知识冗余:规律性的结构可由先验知识和背景知识得到
(3)数据压缩分类
无损压缩(Lossless)
-
压缩前解压缩后图像完全一致X=X'
-
压缩比低(2:1~3:1)
-
例如:Winzip,JPEG-LS
有损压缩(Lossy)
-
压缩前解压缩后图像不一致X≠X'
-
压缩比高(10:1~20:1)
-
利用人的视觉系统的特性
-
例如:MPEG-2,H.264/AVC,AVS
(4)Intel Media SDK概述
Intel Media SDK是开发专业的视频和媒体应用程序。在适用于Windows和Linux的应用程序中提供硬件加速的视频编码、解码和处理。
SDK主要目的是为了简化开发:
使用此SDK中包含的库、工具和示例,为数字监控、零售、工业、智能家居、视频会议等开发专业级媒体和视频应用程序,并支持硬件加速,可实现快速视频转码,图像处理和媒体工作流程。

(5)图像预处理
图像预处理的目的:
图像预处理,是将每一个图像分检出来交给识别模块识别,这一过程称为图像预处理。在图像分析中,对输入图像进行特征抽取、分割和匹配前所进行的处理。
图像预处理的常用方法:
图像预处理的主要目的是消除图像中无关的信息,恢复有用的真实信息,增强有关信息的可检测性和最大限度地简化数据,从而改进特征抽取、图像分割、匹配和识别的可靠性。
(6)图像预处理的常用方法
图像分析中,图像质量的好坏直接影响识别算法的设计与效果的精度,因此在图像分析(特征提取、分割、匹配和识别等)前,需要根据图像识别任务的不同进行预处理。
常见的图像预处理方法包括:
图像颜色空间转换、图像二值化、图像滤波、图像金字塔、图像ROI、几何变换、形态学变换、图像边缘检测等,这里主要介绍图像ROI以及图像几何变换中的缩放这两种方法。
图像ROI区域概述:
ROI(Region Of Interest),指图像分析中感兴趣的区域。只要找到这个ROI区域,那么需要处理的图像就由原来的大图变为一个小图像区域,可以减少处理时间,增加处理精度。以人脸识别为例,图像中待检测的人脸就是感兴趣区域(ROI)。提取ROI区域可以说是计算机视觉中必不可少的操作。

ROI提取(切片操作)

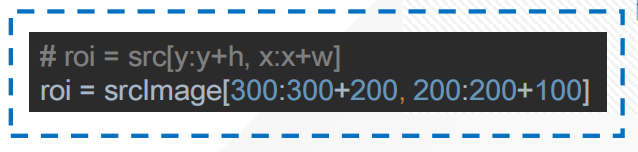
在一个行人监控场景中,摄像机是固定的,相机对着门。当有人出现时,保存当前行人。我们感兴趣的是行人,其他的是背景,背景变化不大没有必要保存(节约储存空间),门框在原图像中的位置是固定的,并且行人出现在门框中。在该场景中,可以使用切片操作提取门框。假设门框左上角在原图像中的坐标为(200,300),门框宽100,高200。
可以使用如下所示代码提取门框:
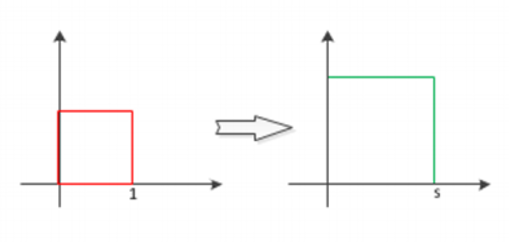
图像缩放:
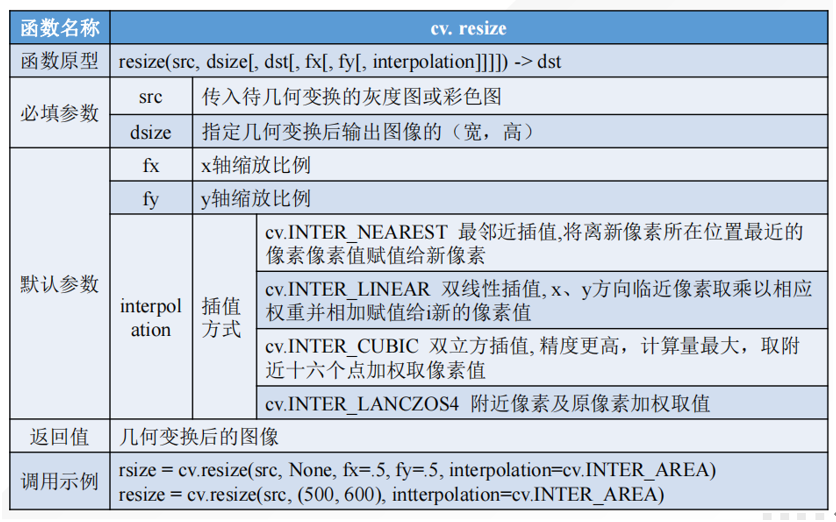
图像缩放是指将一副图像放大或缩小得到新图像。对一张图像进行缩放操作,可以按照比例缩放,亦可指定图像宽高进行缩放。放大图像实际上是对图像矩阵进行拓展,而缩小实际上是对图像矩阵进行压缩。放大图像会增大图像文件大小,缩小图像会减小文件体积。
模型推理部署的挑战:
-
[1]深度学习框架种类繁多:业界广泛使用的深度学习框架有许多,例如Caffe,TensorFlow,MXNet,Kaldi,PyTorch等。
-
[2]性能与功耗的限制: 深度学习网络的训练是在数据中心或服务器中进行的,而推理则可能在针对性能和功耗进行了优化的嵌入式平台上进行。使用原始训练框架进行推理,从软件角度(编程语言,第三方依赖关系,内存消耗,支持的操作系统)和硬件角度(不同的数据类型,有限的功耗)来看,此类平台通常都受到限制,因此通常不建议这样做(有时甚至是不可能的)。
-
[3]复杂性高: 针对上述两个难点有一种替代解决方案是使用针对特定硬件平台进行了优化的专用推理API。但是由于部署过程的其他复杂性包括支持越来越复杂的各种层类型和网络,导致确保变换网络后的模型准确性不受大的影响并非易事。
(7)模型部署的工作流程
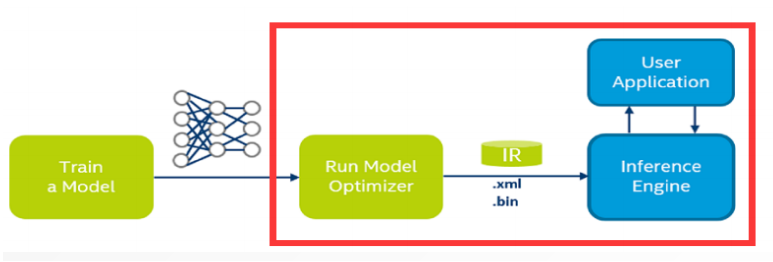
DLDT是Deep Learning Deployment Toolkit英特尔®深度学习部署工具包的缩写,其主要用于神经网络的推理。
部署训练完成的深度学习模型完整工作流程因受到应用场景需求、精确度以及硬件设备等诸多因素的影响较为复杂。
这里只介绍一种模型部署的典型工作流程:
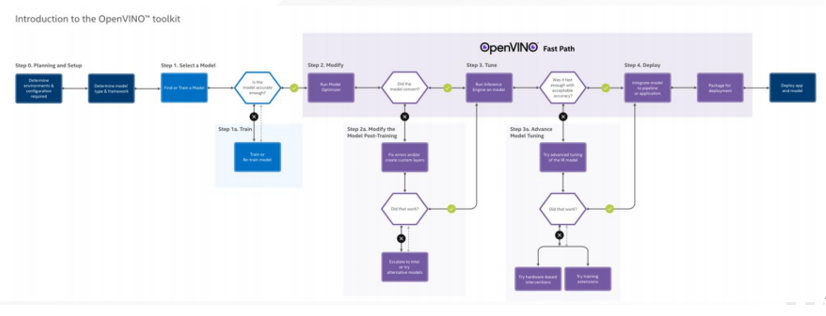
(8)模型部署的典型工作流程
-
[1]针对特定框架配置模型优化器(用于训练模型)。
-
[2]运行模型优化器,以基于训练后的网络拓扑,权重和偏差值以及其他可选参数,生成模型的优化中间表示(IR)。
-
[3]在目标环境中使用提供的Inference Engine示例应用程序,使用Inference Engine对IR格式的模型进行测试。
-
[4]将Inference Engine集成到您的应用程序中,以在目标环境中部署模型。
二、视频后处理
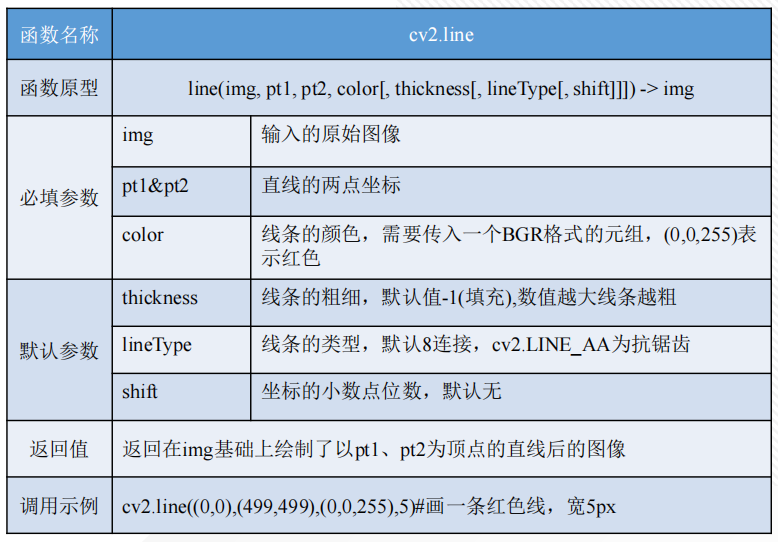
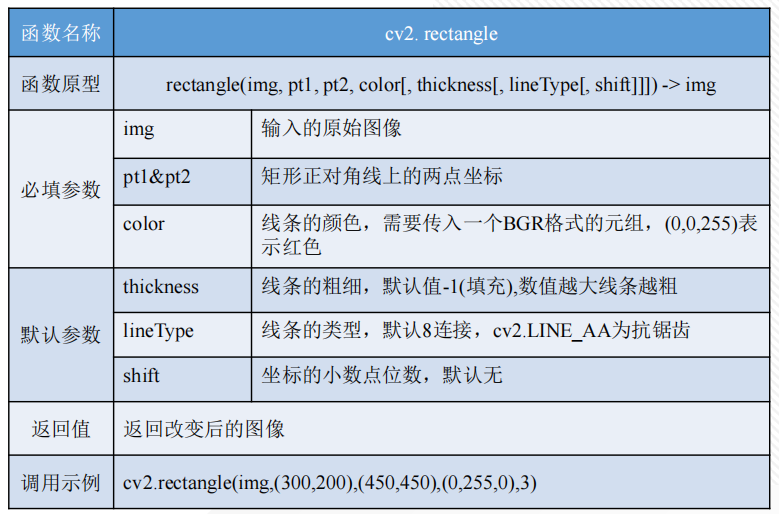
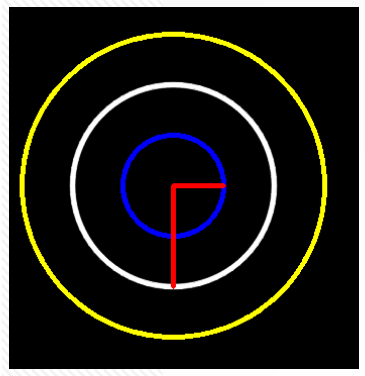
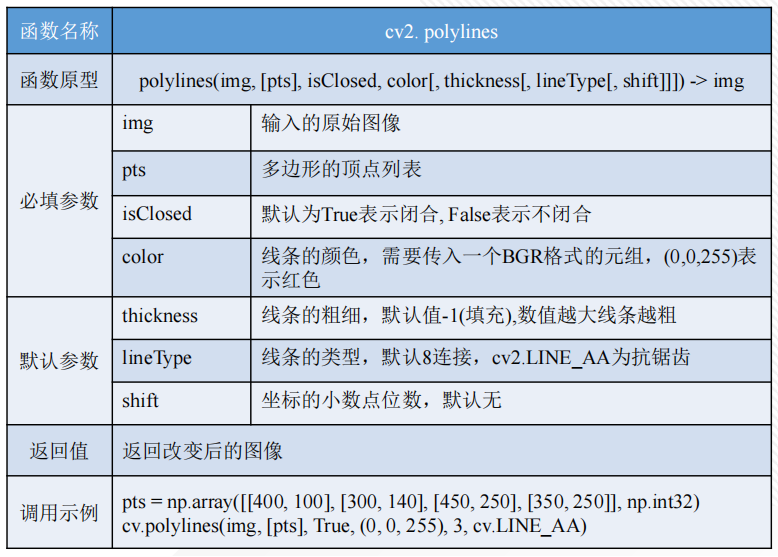
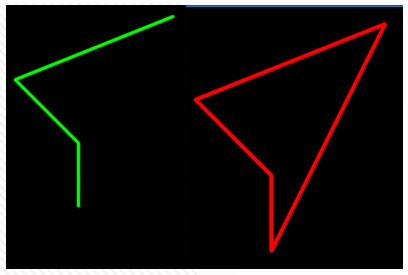
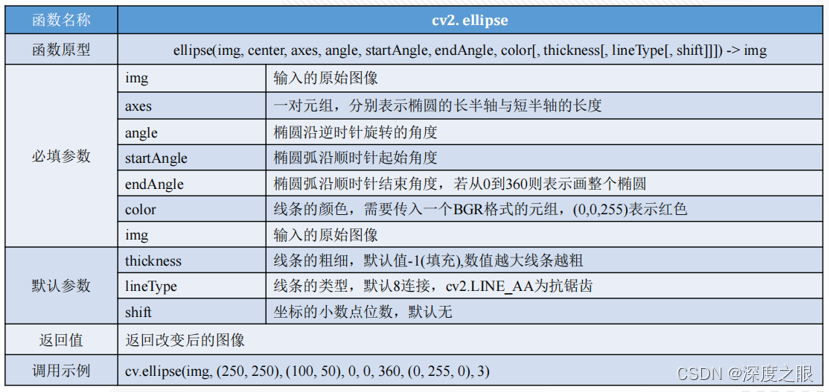
在图像处理中,经常需要将某个感兴趣区域用图形标注出来,特别是在物体检测、物体追踪技术中,绘图几乎是每个程序必不可少的功能。OpenCV提供了一些绘图函数,可以满足在图像中绘制直线、圆、矩阵、多边形、字符串等功能。

点击下方卡片关注《学姐带你玩AI》🚀🚀🚀
500+篇CVPR论文资料👉回复“CVPR”领取
更多算法技术干货、深度学习经验分享、AI前沿资讯等你来看
码字不易,欢迎大家点赞评论收藏!