提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 富集分析
- 一些理论知识
- 具体代码
- 富集不到的补救措施
- 更多资料---
- 问题数据和常见错误分析
- Part4-复杂数据及其分析
- 多分组数据分析流程
- tinyarray简化版本分析流程
- 多分组数据分析流程
- 1.获取数据
- 2.生成分组向量与探针注释
富集分析
一些理论知识
- 最常用于富集分析的数据库:GO 和 KEGG
- 人类的基因被数据库收录的 8000 个左右,被分类到不同的 KEGG 通路/GO term(细胞组分/分子功能/生物过程三个子部分)
- 用于富集分析的 R 包:clusterProfiler,Y叔开发的,还有一本书,clusterProfiler book
- 富集分析中得到的两个值的解释:
GeneRatio:差异基因中富集到的数量/差异基因在数据库中的数量
bgRatio:该通路总共多少个基因/数据库中总共多少个基因
5. 所谓是否富集(p值):geneRatio对于bgRatio是否明显较大,即“实际中奖概率”是否明显比“理论中奖概率”大,即:衡量每个通路里的基因在差异基因里是否足够多
具体代码
rm(list = ls())
load(file = 'step4output.Rdata')
library(clusterProfiler)
library(ggthemes)
library(org.Hs.eg.db)
library(dplyr)
library(ggplot2)
library(stringr)
library(enrichplot)
(1)输入数据
gene_diff = deg$ENTREZID[deg$change != "stable"]
#输入数据为change不为stable的ENTREZID
(2)富集
ekk <- enrichKEGG(gene = gene_diff,organism = 'hsa')
ekk <- setReadable(ekk,OrgDb = org.Hs.eg.db,keyType = "ENTREZID")
ego <- enrichGO(gene = gene_diff,OrgDb= org.Hs.eg.db,
ont = "ALL",readable = TRUE)
#setReadable和readable = TRUE都是把富集结果表格里的基因名称转为symbol
#> class(ekk)
#[1] "enrichResult"
#attr(,"package")
#[1] "DOSE"
#ekk是对象
#??enrichResult 查看帮助文档
#(3)可视化
dotplot(ego, split = "ONTOLOGY") +
facet_grid(ONTOLOGY ~ ., space = "free_y",scales = "free_y")
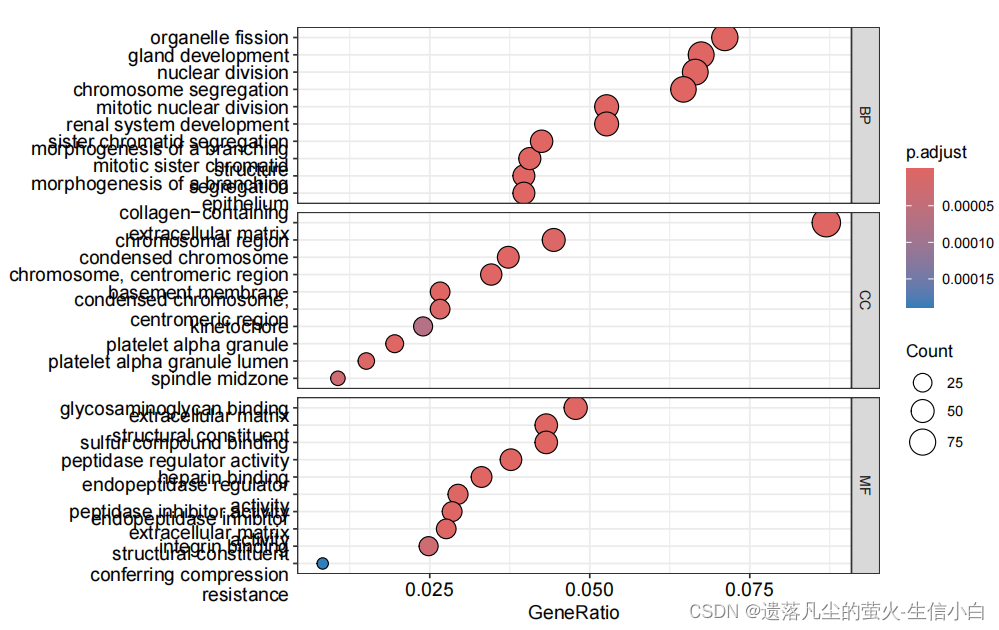
#(3)可视化
dotplot(ego, split = "ONTOLOGY") +
facet_grid(ONTOLOGY ~ ., space = "free_y",scales = "free_y")
dotplot(ekk)
#或者是dotplot
table(ekk@result$p.adjust<0.05) #创建一个表格,显示经过多重比较校正后的 P 值小于 0.05 的次数
table(ekk@result$pvalue<0.05) ## 创建一个表格,显示未校正的 P 值小于 0.05 的次数
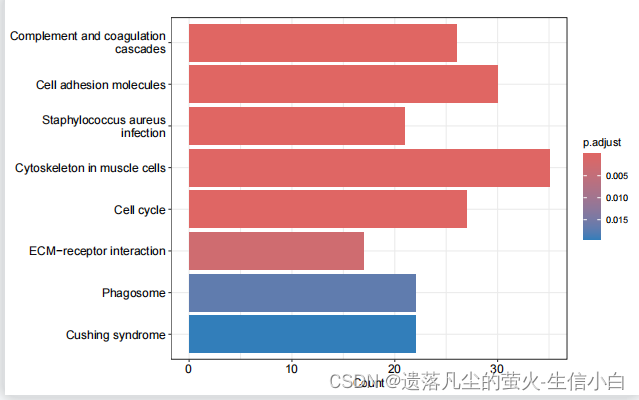
#(3)可视化
dotplot(ego, split = "ONTOLOGY") +
facet_grid(ONTOLOGY ~ ., space = "free_y",scales = "free_y")
dotplot(ekk)
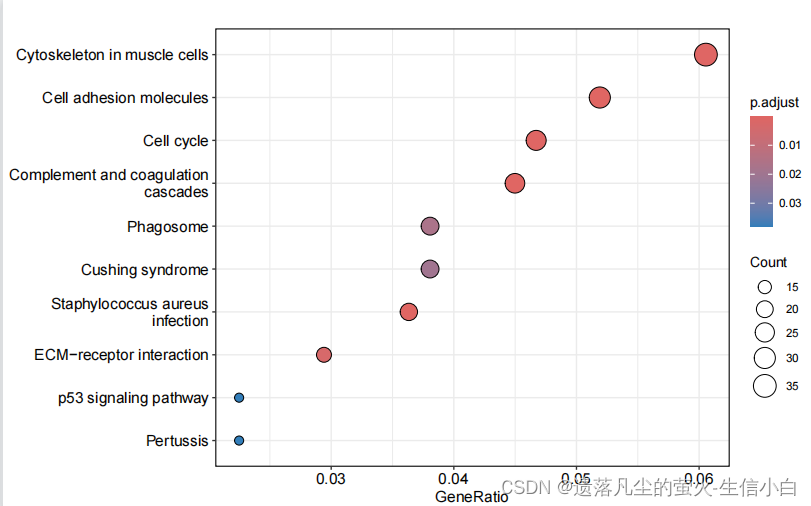
直接对自定义对象写的自定义函数,不需要加任何参数调整就可以直接出图,方便!
富集不到的补救措施
- 调整logFC、pvalue的阈值(通常是调整logFC),以改动差异基因数量
- 不适用默认的padj,而是使用原始p值,在文章中说明清楚即可
- 换富集方法,GSEA也可以做KEGG富集
- 调整参数maxGSSize = 500,默认参数为500表示500个基因以上的通路不考虑,可以调大成1000之类
更多资料—
- GSEA:https://www.yuque.com/docs/share/a67a180f-dd2b-4f6f-96c2-68a4b86fe862?#
添加链接描述 - Y叔的书:http://yulab-smu.top/clusterProfiler-book/index.html
添加链接描述 - GOplot:https://mp.weixin.qq.com/s/LonwdDhDn8iFUfxqSJ2Wew
添加链接描述 - 网上的资料和宝藏无穷无尽,学好R语言慢慢发掘~
问题数据和常见错误分析
1.数据提交者的锅
表达矩阵是空的
表达矩阵不完整
表达矩阵被标准化过
表达矩阵有错误或异常值
解决办法:
换一个数据
处理原始数据
2.你的锅
用芯片流程分析转录组数据
忘记log/多余log
分组搞错
探针注释错误
id转换用错物种
3.不可抗力
找不到探针注释
数据有错又找不到原始数据
找不到想要的实验设计
Part4-复杂数据及其分析
多分组数据
多数据联合分析
加权共表达网WGCNA
蛋白互作网络
添加链接描述
分组聚类的热图
table(ekk@result$p.adjust<0.05)
#检查富集到了多少条通路
多分组数据分析流程
tinyarray简化版本分析流程
需要R包版本2.3.1及以上:
### 运行代码块的快捷键
在RStudio中,你可以使用以下快捷键来运行当前的代码块或所选代码:
- Windows/Linux: `Ctrl + Enter`
- macOS: `Cmd + Enter`
这些快捷键会执行光标所在的代码块,或者如果使用了文本选择,那么执行所选部分的代码。
1.获取数据
rm(list = ls())
#打破下载时间的限制,改前60秒,改后10w秒
options(timeout = 100000)
options(scipen = 20)#不要以科学计数法表示
#前面是一样的
library(tinyarray)
packageVersion("tinyarray")
[1] ‘2.3.3’
library(stringr)
geo = geo_download("GSE7305") #geo_download实现下载和整理
exp = geo$exp #表示从名为 geo 的对象中提取名为 pd 的组件,并将提取的组件赋值给一个新的变量 pd。
exp = log2(exp+1)
boxplot(exp,las = 2) #查看有无异常样本
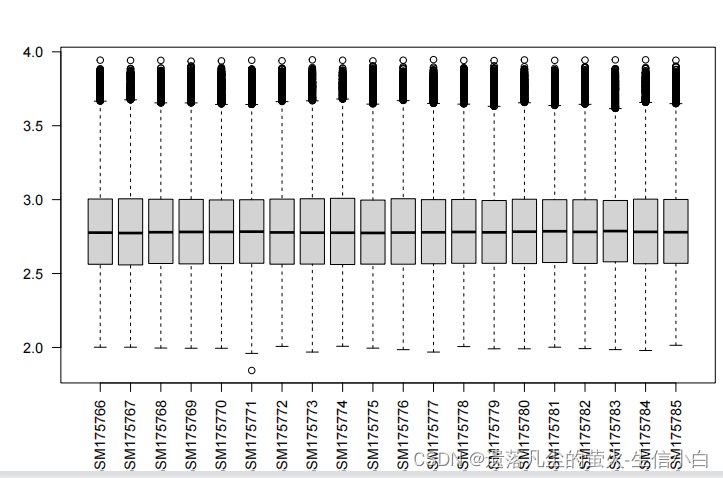
pd = geo$pd #提取临床信息
gpl_number = geo$gpl
#代替了第一个脚本
# 分组信息
k = str_detect(pd$title,"Normal");table(k)
Group = ifelse(k,"Normal","Disease")
Group = factor(Group,levels = c("Normal","Disease"))
Group = factor(Group,levels = c("Normal","Disease"))
# 探针注释
find_anno(geo$gpl)
library(hgu133plus2.db);ids <- toTable(hgu133plus2SYMBOL)
head(ids)
#差异分析和它的可视化
dcp = get_deg_all(exp,Group,ids,entriz = F) #get_deg_all实现差异基因和可视化
#代替了脚本3和脚本4
table(dcp$deg$change)
head(dcp$deg)
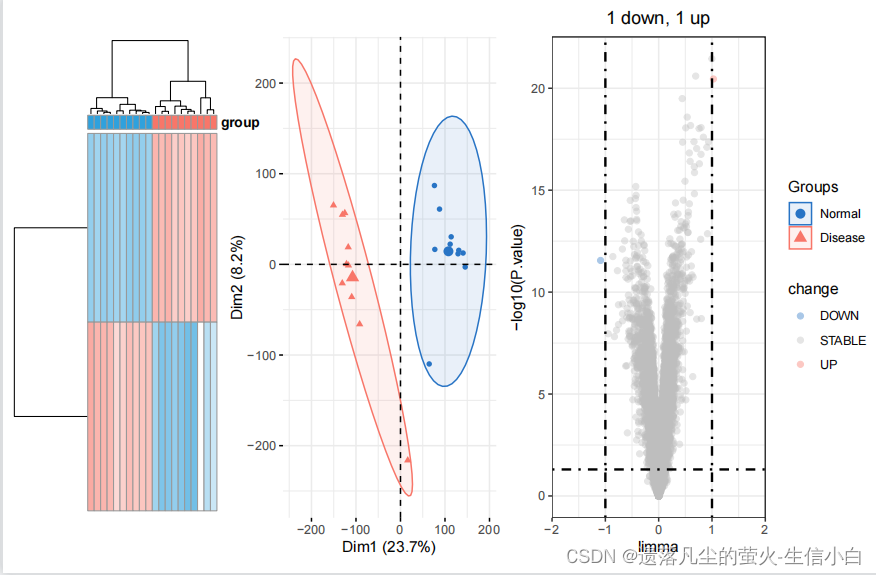
dcp$plots
library(ggplot2)
ggsave("deg.png",width = 15,height = 5)
> #差异分析和它的可视化
> dcp = get_deg_all(exp,Group,ids,entriz = F)
579 down genes,624 up genes
> table(dcp$deg$change)
down stable up
579 19621 624
> head(dcp$deg)
logFC AveExpr t P.Value
1 6.270309 8.436140 45.39552 0.000000000000000000000009106509
2 3.943359 7.351799 35.25755 0.000000000000000000002600407155
3 2.318498 6.631187 32.33367 0.000000000000000000017855505829
4 4.905540 8.140399 30.78154 0.000000000000000000053206731115
5 4.878195 6.815838 29.02740 0.000000000000000000195062651758
6 4.106051 9.045949 28.82714 0.000000000000000000227319306208
adj.P.Val B probe_id symbol change
1 0.0000000000000000002489492 41.58809 202992_at C7 up
2 0.0000000000000000473924204 37.34483 204971_at CSTA up
3 0.0000000000000001952499562 35.77275 228564_at LINC01116 up
4 0.0000000000000004155825748 34.85700 208131_s_at PTGIS up
5 0.0000000000000013331313106 33.74579 210002_at GATA6 up
6 0.0000000000000013809647852 33.61341 212190_at SERPINE2 up
> dcp$plots
> library(ggplot2)
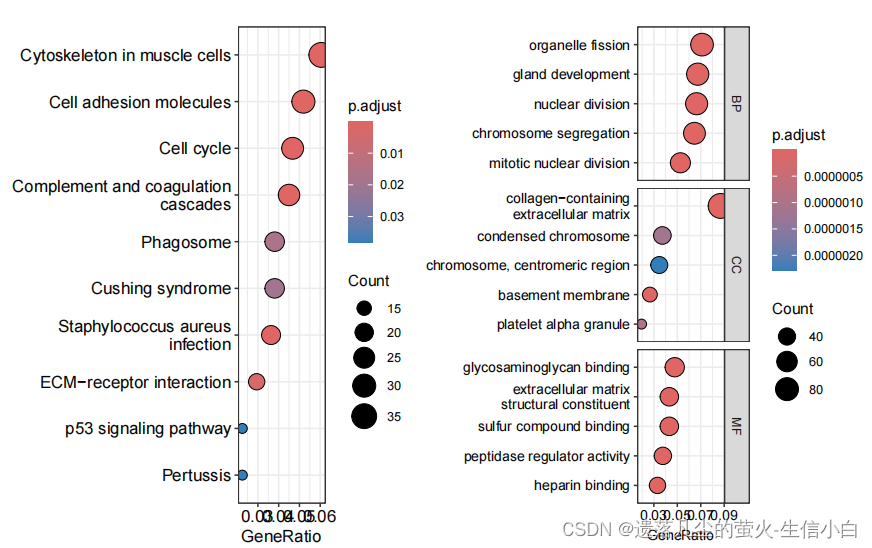
```{r}
#富集分析
deg = get_deg(exp,Group,ids)
genes = deg$ENTREZID[deg$change!="stable"] #取出差异基因ENTREZID
head(genes)
#有可能因为网络问题报错
g = quick_enrich(genes,destdir = tempdir()) #quick_enrich快速的富集分析
names(g) #元素的名字
g[[1]][1:4,1:4]
library(patchwork)
g[[3]]+g[[4]]
ggsave("enrich.png",width = 12,height = 7)
多分组数据分析流程
R包需要自己安装哦。如果不会安装,建议先学习R语言基础,不要直接上手实战。另外,学习本篇需要建立在tinyarray基本使用会了的基础上,不会的话先看复杂分析这里的第一个文件夹。
1.获取数据
rm(list = ls())
#打破下载时间的限制,改前60秒,改后10w秒
options(timeout = 100000)
options(scipen = 20)#不要以科学计数法表示
library(tinyarray)
packageVersion("tinyarray")
## [1] '2.3.3'
library(stringr)
gse = "GSE474"
geo = geo_download(gse)
exp = geo$exp
range(exp)
## [1] 0.050827 35799.757813
exp = log2(exp+1)
boxplot(exp,las = 2)
pd = geo$pd
gpl_number = geo$gpl
#获取数据和检查