这是《Attention Is All You Need》通俗解读的第2篇,上一篇见这里。
本篇解读模型结构的编码器和解码器,对应于论文的 3.1 小节。
这一部分在论文中作者写的并不长,很多内容没有展开来讲。
虽然对于这一类具有原创架构的论文而言,模型结构是非常重要的一部分,几乎都会写的非常详细,但是作者却对很多算法和技术采取了“一带而过”的写作方式。
也就是说,作者默认读者对背景知识和常见算法非常了解,这也导致了很多人第一次阅读这篇论文时非常困难。
在论文的“3. Model Architecture”部分,作者主要介绍了他们提出的 Transformer 架构是如何实现的,一起来看看吧。
Most competitive neural sequence transduction models have an encoder-decoder structure.
Here, the encoder maps an input sequence of symbol representations (x1, ..., xn) to a sequence of continuous representations z = (z1, ..., zn). Given z, the decoder then generates an output sequence (y1, ..., ym) of symbols one element at a time. At each step the model is auto-regressive, consuming the previously generated symbols as additional input when generating the next.
第一段是背景知识。
这一段的主要内容是:传统的序列转录模型(你可以理解为讲一个序列转换为另一个序列的 Seq2Seq模型)都是基于encoder-decoder架构。
encoder也叫编码器,decoder也叫解码器。
对于编码器而言,输入序列(假设是中文句子)可以用(x1,....xn)来表示,每一个x可以认为是一个token向量,而编码器会将这个序列映射到另一个特征向量z,解码器收到这个向量z之后,会输出目标句子(假设是英文句子)。
但是这里需要强调一点:解码器输出目标句子时是一个单词一个单词输出的,每输出一个目标单词的时刻可以认为是一个时间步。
在输出某个单词时,解码器会根据之前已输出的内容来输出当前的内容,也就是说,之前的输出会影响当前的输出。这部分内容在这里讲的很详细,你可以来这里了解一下。
第一段内容可能是为了行文逻辑的考虑,作者引出编码器和解码器架构,为下文做铺垫。
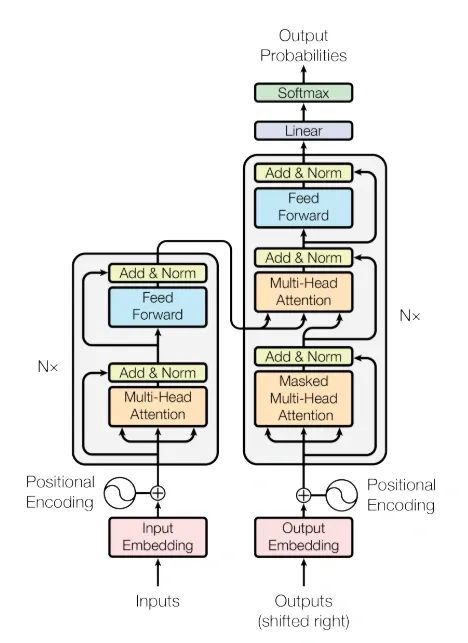
在接下来的一段,作者就简明扼要的提到了Transformer架构的大致框架,并且放出了 Transformer 的经典架构图(这张图你可能在很多场合都见到过)。
The Transformer follows this overall architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder, shown in the left and right halves of Figure 1, respectively.
作者提到,Transformer 架构的整体仍然是编码器和解码器结构,但是和之前不同的是,编码器和解码器都采用了注意力层+FC层的结构,整体架构你可以参考下面的图,读到这里暂时不用太关注细节,请继续往下看。

Encoder: The encoder is composed of a stack of N = 6 identical layers. Each layer has two
sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, positionwise fully connected feed-forward network. We employ a residual connection [11] around each of the two sub-layers, followed by layer normalization [1]. That is, the output of each sub-layer is LayerNorm(x + Sublayer(x)), where Sublayer(x) is the function implemented by the sub-layer itself. To facilitate these residual connections, all sub-layers in the model, as well as the embedding layers, produce outputs of dimension dmodel = 512.
这一段作者开始介绍 Transformer 架构中的解码器,也就是上图左侧的部分。
解码器由6个相同的层组成,上图左侧的N=6。
每个层有两个子层组成:第一个子层叫做多头注意力层,第二个子层是一个非常简单的、逐点运算的全连接前馈神经网络层(这里说白了就是一个简单的 FC,不要被长串的英文所吓到)。
在两个子层中,都使用了残差结构,将输入和输出进行相连(你可以看到左侧的残差相连结构),每个子层残差相连(使用Add运算将输入和子层的输出相加)后,都会通过一个 LayerNorm层,因此,每一个子层都可以表达为:LayerNorm(x + Sublayer(x))的形式。
因此,对于第一个子层,你可以写成LayerNorm(x + MHA(x)), MHA 代表多头注意力层,对于第二个子层,你可以写成LayerNorm(x + FF(x)),FF代表前馈全连接层。
在这里,我们可以将两个子层组成的神经网络块叫做 Transformer Block,也就是 Transformer 块,和 Renset 结构中的残差块类似。
在每一个block中,每个子层中都有残差连接,而残差连接(加法)要求两个输入的数据维度相同,因此作者在本段的最后一句说到,为了满足残差连接的需求,也为了使模型更加简单,所有子层输入的维度(包括Embedding层,因为Embedding的输出是MHA层的输入)和所有子层输出的维度,都是512。
也就是说作者为了简化模型运算,将每一个block输入和输出的维度都做了恒等限定。
关于编码器,作者到这里就介绍完了,至于细节,在后面会介绍,接下来继续看解码器。

Decoder: The decoder is also composed of a stack of N = 6 identical layers. In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack. Similar to the encoder, we employ residual connections around each of the sub-layers, followed by layer normalization. We also modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i.
解码器和编码器非常相似,从上图你也可以看的出来。
它也是由6个完全相等的block组成,区别在于,解码器中有3个子层。
其中,后面的两个子层和编码器完全相同,而第一个子层,也就是多出来的子层也是一个多头注意力层,唯一不一样的是该子层的多头注意力层中间的 softmax 函数计算方式不一样,因此作者把这一层叫做 Masked-MHA,带掩码的多头注意力层。
为什么要多出一层带掩码的注意力呢?
简单介绍一下就是:解码器是负责输出目标句子的。假设将一个中文句子翻译为英文,解码器在输出某个单词时(假设该单词在目标句子的第 i 的位置),此时计算注意力时应该只关注前 i-1 个单词,而不应该关注到 i 之后的单词。
这是因为解码器是输出结果,只能已经输出的内容(过去)对当前输出的单词有影响,i 之后的单词的(未来)不应该对当前的输出产生任何影响。
因此作者在其中加了掩码,就是将 i 之后的注意力全部置为零,使其不对当前时刻产生影响。
当然这么做也是为了保持训练和推理时的一致性,从而使得推理更加准确,具体细节这里不多展开,后面再详细介绍。
所以,你可以看到,编码器和解码器是Transformer 架构中非常重要的部分,而作者仅用了两小段就介绍完了。
至于为什么需要使用 LayerNorm 和残差结构,这里并未详细介绍,但没关系,后面的文章会详细介绍,这两段也仅需要了解到Transformer的大致结构即可。
前文链接:
《Attention is all you need》通俗解读,彻底理解版:part1-CSDN博客
我的技术专栏已经有几百位朋友加入了。
如果你也希望了解AI技术,学习AI视觉或者大语言模型,戳下面的链接加入吧,这可能是你学习路上非常重要的一次点击呀
CV视觉入门第三版(细化版)完成
我的Transformer专栏努力更新中
最后,送一句话给大家:生活不止眼前,还有诗和远方,共勉~





![C语言力扣刷题10——有效的括号——[栈]](https://img-blog.csdnimg.cn/direct/151398ee6ea748bbbd0de91ba723f734.png)