当前,百度智能云云数据库特惠专场开始!热销规格新用户免费使用,欢迎参与!
大模型效果让人惊艳,但是还是存在知识更新不及时,容易幻觉,没有内部知识的原因,所以带火了 RAG 技术。
根据现在调查,目前超过 80% 的落地应用基本都是 RAG,这个主要还是这块比较成熟,像大家期待的 Agent 技术还在发展中,没有特别成功的范例。
RAG 是检索增强生成(Retrieval-augmented Generation)。利用向量相似度检索技术搜索文档,然后组合成 prompt 喂给大模型,大模型再生成最终的答案。这就规避了刚才讲到的大模型几个典型问题。RAG 是一个非常实用的技术。
但是要做好 RAG 要经过数据提取、数据索引、检索、生成四个阶段,每个阶段都有不少难点。先用一张简单的图给大家看下 RAG 的过程,RAG 分数据提取,数据索引,检索到最后生成这么几步。
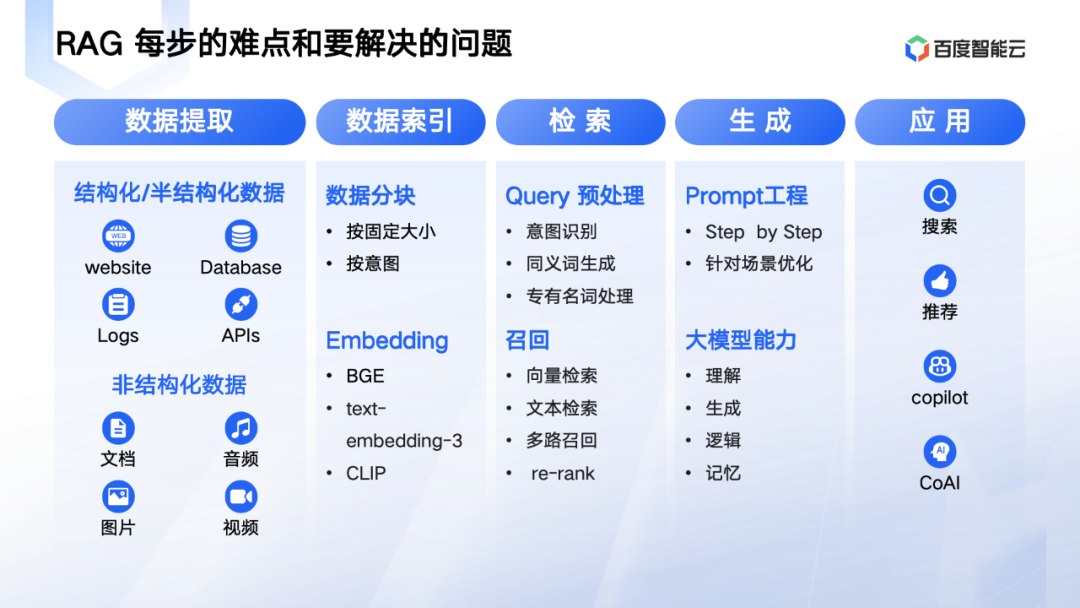
RAG 技术还在快速发展,所以每一步现在都不是特别成熟,都有不少难点,我这里简单提一下给大家做参考:
1、首先是数据提取。
这一步的核心是要把各种结构化,非结构化数据能提取出来,用于后面的处理。这里的复杂度主要是:
1.1 文件格式复杂,以 pdf 为例子,不光有文字,还夹杂有图表,图片里面又有文字。
1.2 文件有上下文,要把上文相关的元信息提取出来,后面就更容易处理。如果不提取元信息,那下一步数据分块,就容易切分错误。
2、其次数据索引。
这一步做好文档的切分, embedding 模型,把文件 embedding 成向量,才可以把向量存到向量数据库里面去。这里的难点又有两个:
2.1 数据切分,过大,过小都会有问题。所以一般是按照 300~400 个字节切分。还有处理更精细的,是按意图切分。
2.2 另外就是 embedding 模型,文本类的有 BGE,openAI 的 text-embedding-3;文图关联的只有 CLIP。现在这块的多模态模型是下一步重点。
3、然后就是检索。
检索主要分 query 预处理,召回两个步骤:
3.1 query 预处理主要的步骤是意图识别,同义词生成,专有名词生成等。
3.2 召回主要就是向量数据库的工作,要支持向量检索,文本检索,多路召回能力,召回之后重排技术。
4、最后是生成阶段。
检索出来的结果在给大模型之前,还要 prompt 优化,包括 prompt 加上 step by step ,针对场景的加上相应的提示词等。
最后的结果依赖大模型的理解,生成,逻辑推理能力。大模型能力的强弱也直接决定 RAG 的效果。
所以大家会看到要把 RAG 作为大模型应用目前主要落地场景,但还是有非常多改进的空间的,这方面的创业公司也很多,技术发展也很快,机会很多。现在典型的 RAG框架有 dify,FastGPT ,百度智能云的 App builder等,大家都可以去试一试。
RAG 技术从业务逻辑上来讲,是对大模型最新的知识的补充,所以 RAG 未来的空间,核心是企业私有化知识到底多不多,有没有用于业务价值的地方。这并不取决于大模型本身能力发展到什么程度,大模型变得多智能。因为大模型再智能也无法获取私有的数据。总的来说,RAG 的未来还是大有可为!
当前,百度智能云云数据库特惠专场开始!热销规格新用户免费使用,欢迎参与!









![[Go Web] Kratos 使用的简单总结](https://img-blog.csdnimg.cn/direct/2d5605e71c5b457abde6121c80884bb3.png)
![【Python】已解决:FileNotFoundError: [Errno 2] No such file or directory: ‘配置信息.csv‘](https://img-blog.csdnimg.cn/direct/75f82cb33069453bba360e4c179d337a.png)