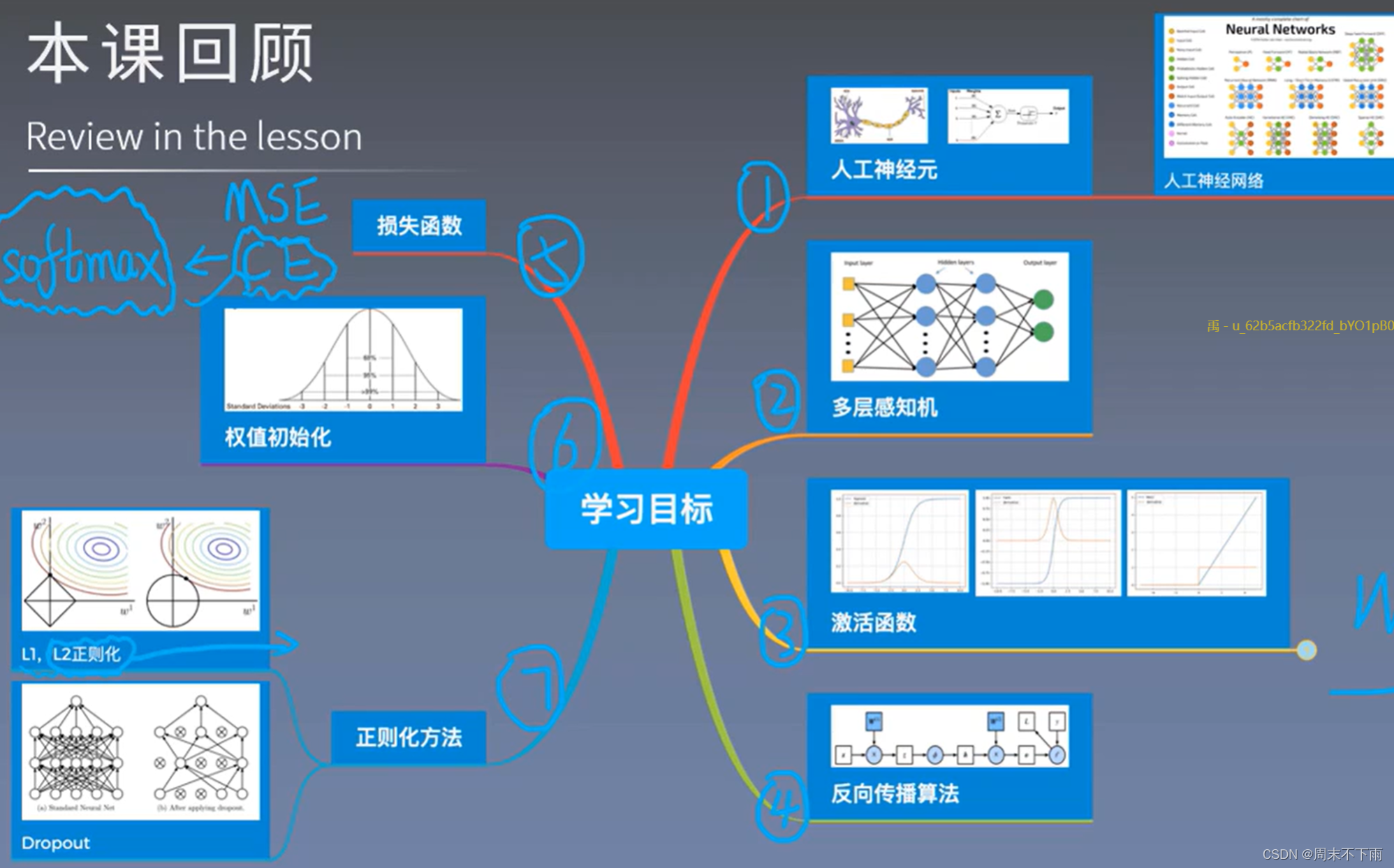
文章目录
- 一、反向传播
- 1.1 梯度下降法
- 1.2 学习率
- 二、损失函数
- 2.1 两种常见的损失函数
- 2.2 CE(交叉熵)
- 2.3 其他的损失函数和网址
- 三、权值初始化
- 3.1 自适应标准差:自适应方法随机分布中的标准差
- 四、正则化方法
- 4.1 过拟合、方差、偏差、噪声
- 4.2 两种常用的正则化
- 4.3 随机失活(正则化方法)
- 4.4 其他正则化方法
- 五、其他
一、反向传播
前向传播:输入层数据开始从前向后,数据逐步传递至输出层
反向传播:损失函数开始从后向前,梯度逐步传递至第一层
反向传播的作用是用于权重的更新,使得输出更加贴近标签
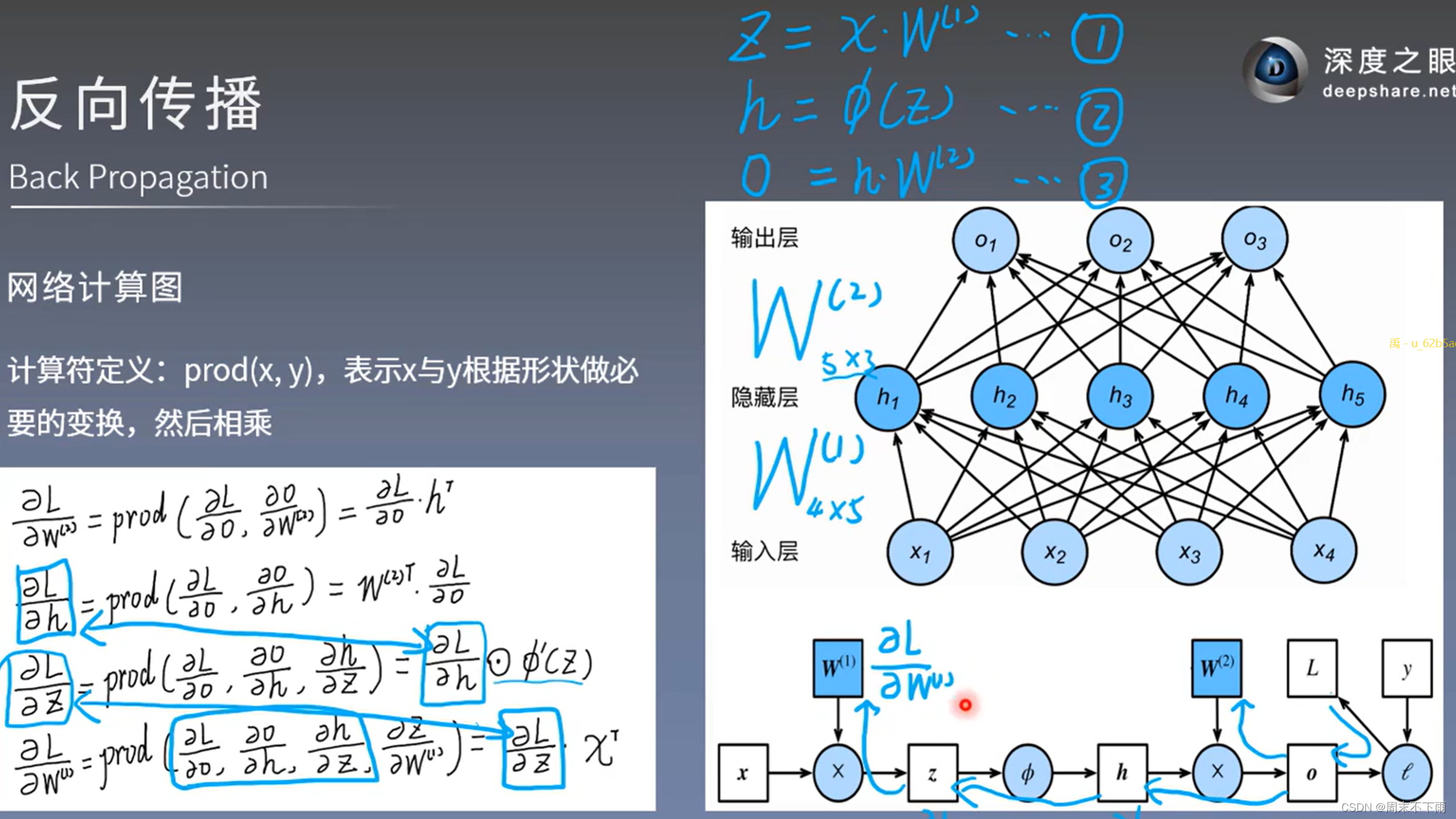
1.1 梯度下降法
在多元函数中有方向导数这一概念,在某一点上有众多的方向导数,其中最大值的方向称之为梯度方向。
在梯度下降法中,权值沿梯度负方向更新,使函数值减小,因此,得到的某一点的梯度的方向后,其反方向,就是我们所求方向。也就是下降更快
1.2 学习率
学习率:控制更新步长
沿梯度负方向更新

步长太长了,以致没有到达最小
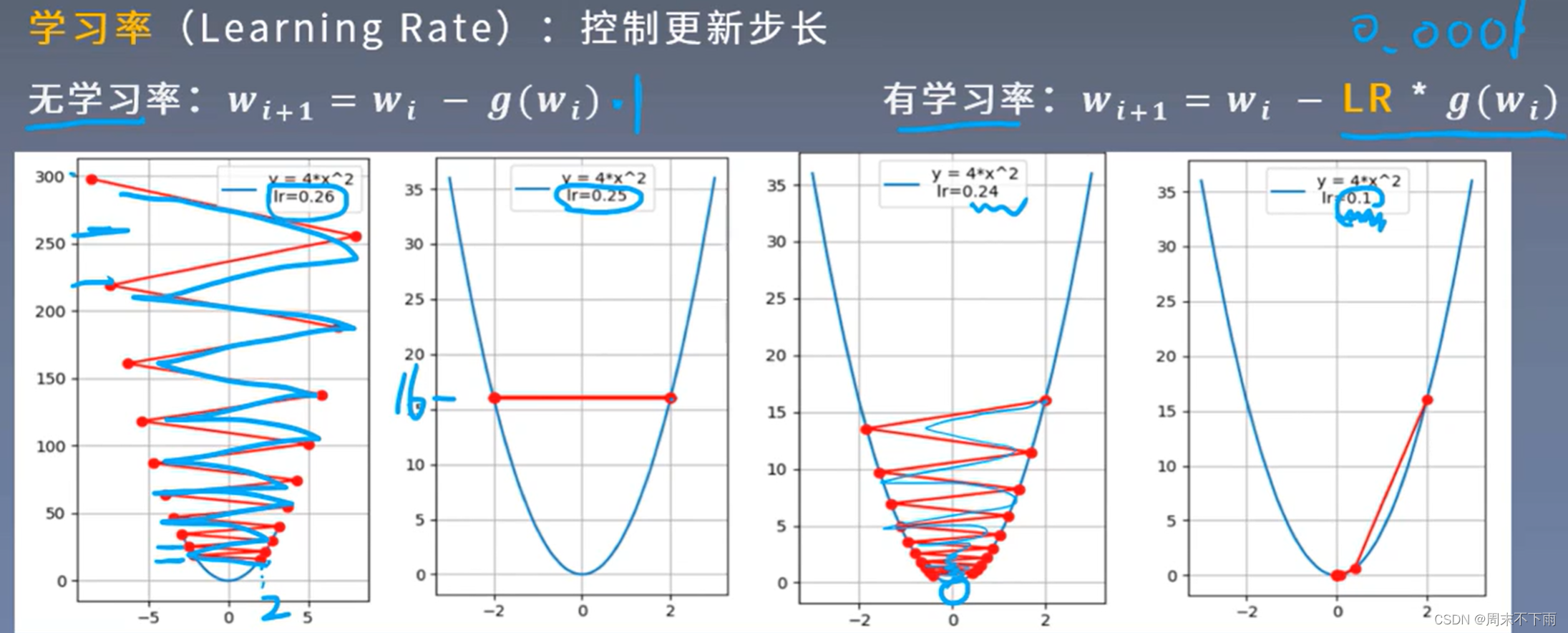
能接近最小值(目的)
通常学习率初始值为:0.1、0.01、0.001、0.0001这样
二、损失函数
搞清楚三个点:损失函数、代价函数、目标函数
损失函数:是对于单个样本的真实值和输出值的差异
代价函数:总体的差异
目标函数:总体的差异和模型复杂度的情况(正则式)

2.1 两种常见的损失函数

第一个MSE就是预测值和真实值之间的平方均值。(回归)
回归任务是用于预测数值型数据的一种监督学习任务,就是预测
第二个CE就是,数据的分布和模型的分布之间的差异(模型得出的分布需要逼近真实的分布,即q要逼近p,越是靠近,说明分布越好越真实)(分类)
分类任务是数据项划分为预定义的类别或聚类,就是提炼出标签
2.2 CE(交叉熵)

交叉熵=信息熵+相对熵
注意:这里的信息熵的定义跟我之前通信原理笔记中的信息熵是同一个概念(等概时,信息熵最大)
《通信原理》期末复习笔记

Softmax函数是一种在深度学习中常用的函数,它主要用于多分类问题。它的主要作用是将一组数字(通常是概率)转化为一个概率分布。
原因:

2.3 其他的损失函数和网址
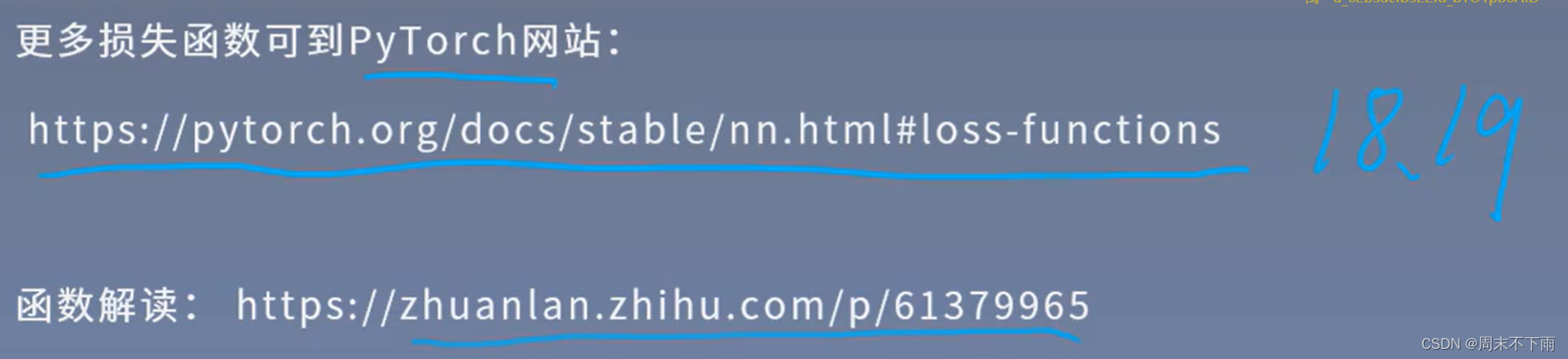
更多损失函数可到PyTorch网站
函数解读
三、权值初始化
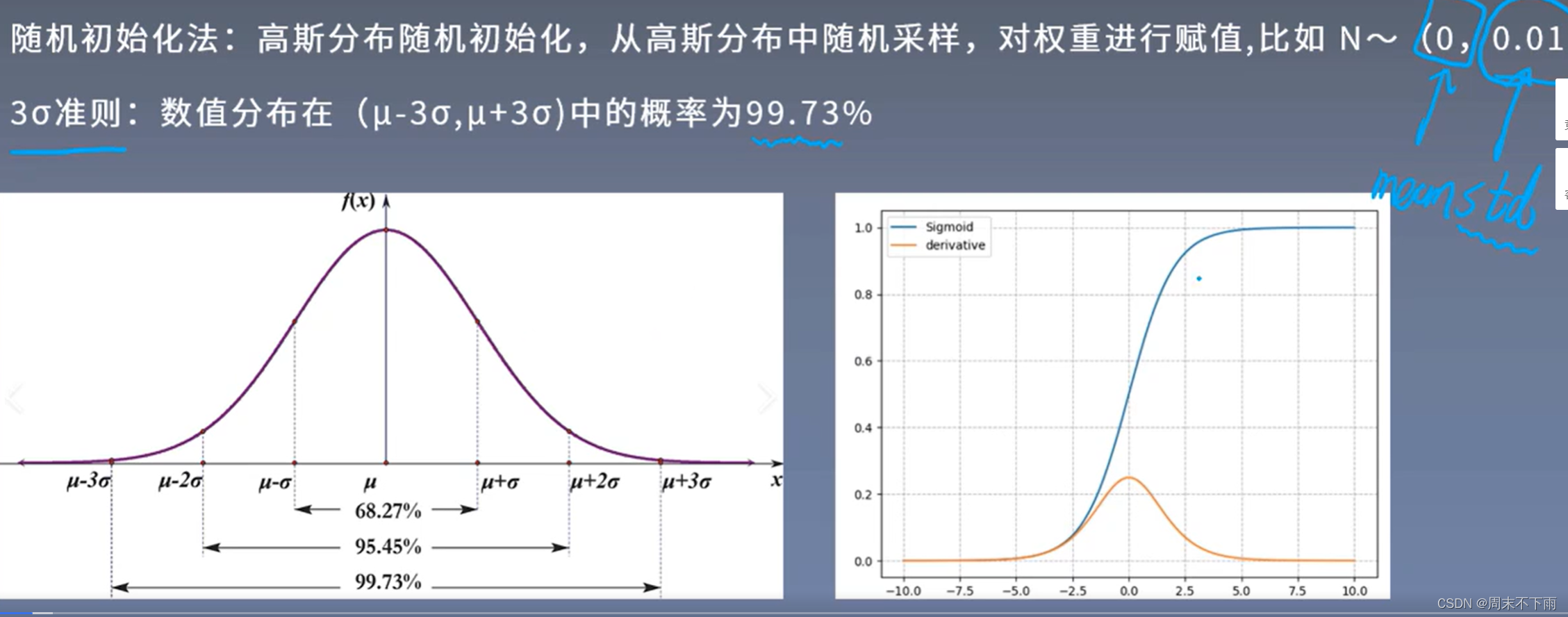
权重不能太小,也不能太大,否则乘上权重之后,激活函数就分布在饱和区域,几乎没有梯度了。一般使用高斯分布(正态分布),所以使用3σ准则,不会太大也不会太小
其中,高斯分布取决于两个值,即均值和方差。(尽量保持数据是一半正的,一半负的,均值为0)
3.1 自适应标准差:自适应方法随机分布中的标准差

这个初始化,就是使用均匀分布。里面的a和b在不同的层里面是不同的,所以叫自适应。这里面算出的均值和方差就是可以放入之前的高斯分布的均值和方差了。
除了上面这个xavier初始化(叉威尔),还有一个就是kaiming初始化(凯明)(也叫MSRA初始化)

在这一篇论文里面有。
四、正则化方法
正则化:减小方差的策略,通俗理解为减轻过拟合的策略
误差可分解为:偏差,方差与噪声之和。即误差=偏差+方差+噪声之和
偏差:度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力
方差:度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响
噪声:则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界
4.1 过拟合、方差、偏差、噪声
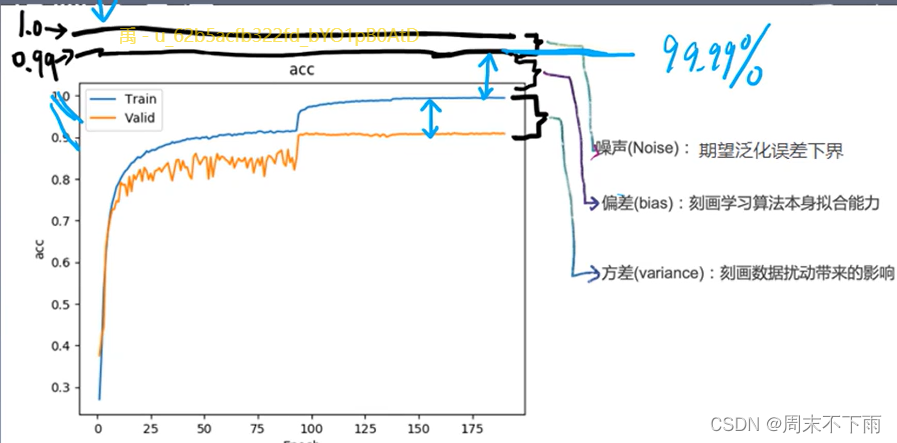
首先:蓝色是训练集,橙色是测试集。纵轴上的1,就是表示精度100%(但是不可能精度百分之百,实际肯定有误差-上帝来了也得99.99%)
其次:偏差就是本身的拟合能力,就是你拟合效果的精度咋样,和实际偏差多少
最后:方差就是训练集和测试集的差距。(就是表示你在不同数据集中又会有多少误差)
所以过拟合现象:方差过大
在训练集表现良好
在测试集表现糟糕
在上面第二点提到目标函数中,由代价函数+约束项(约束项就是表示,拟合的不能太复杂,不然就会过拟合)
过拟合:
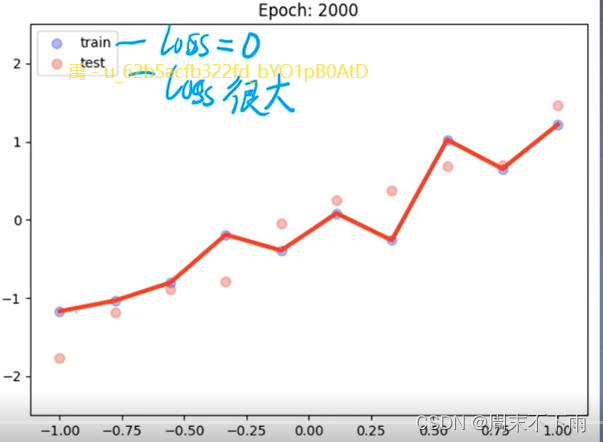
这个函数严格的经过了每一个点,但是对于测试集都太偏离,导致测试集的LOSS很大,这就是过拟合。
4.2 两种常用的正则化

有两种常用的分别是上图的L1和L2,也就是权重绝对值求和以及平方和。
对于L1
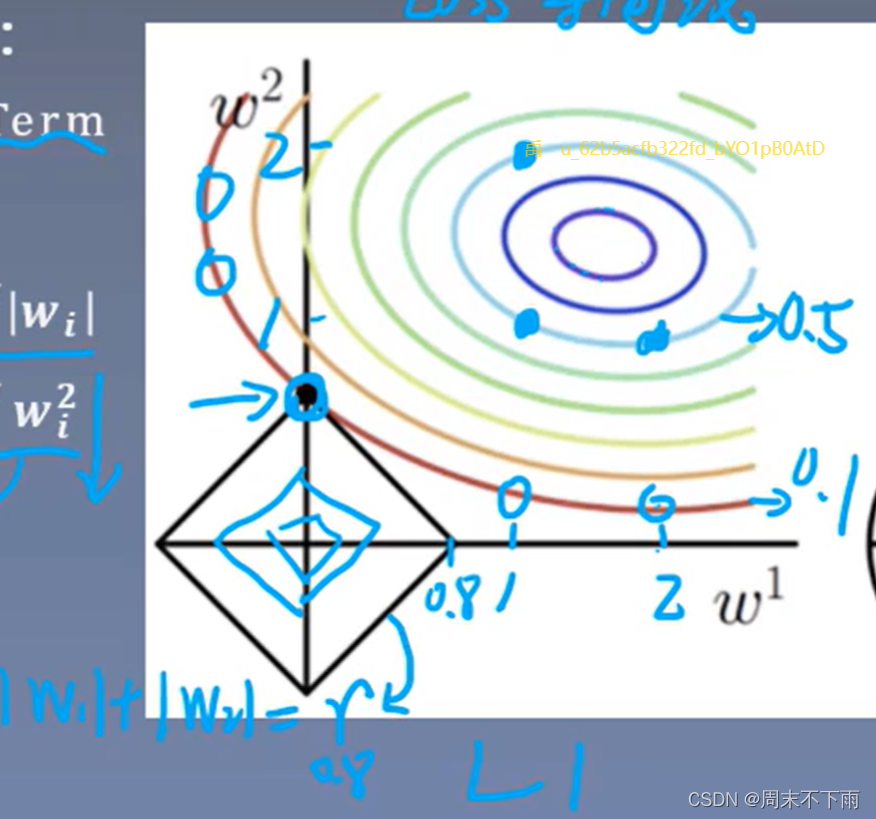
比方说红色的先是LOSS为0.1,那么W1和W2的最优解就是那个黑色点,而且具有权重的稀疏性。
对于L2
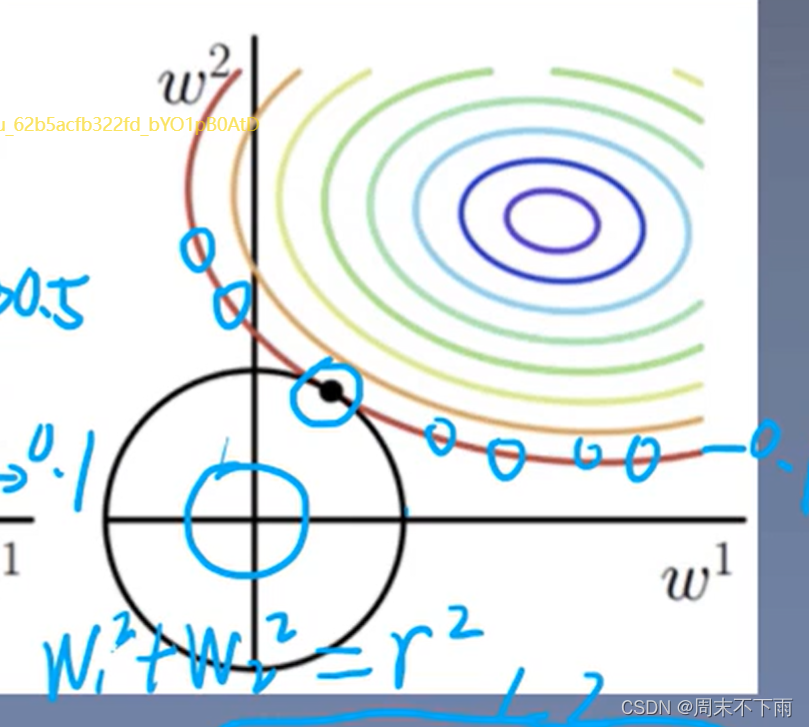
L2也称权值衰减

在最后一行,使得W_i减小了,所以也叫权值衰减,这里吧目标函数,简化为LOSS+系数*L2,(这个系数根据自己需要进行定义)
这样就可以解决过拟合现象
4.3 随机失活(正则化方法)
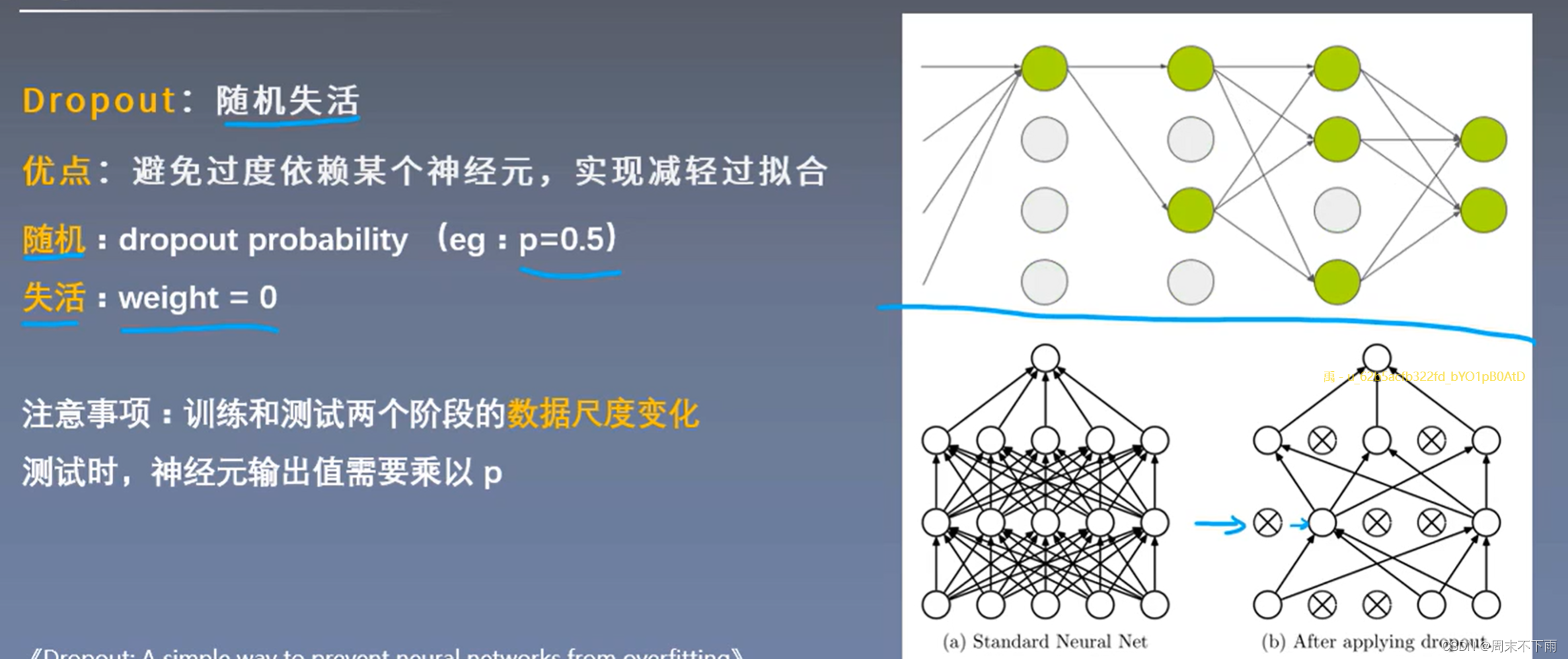
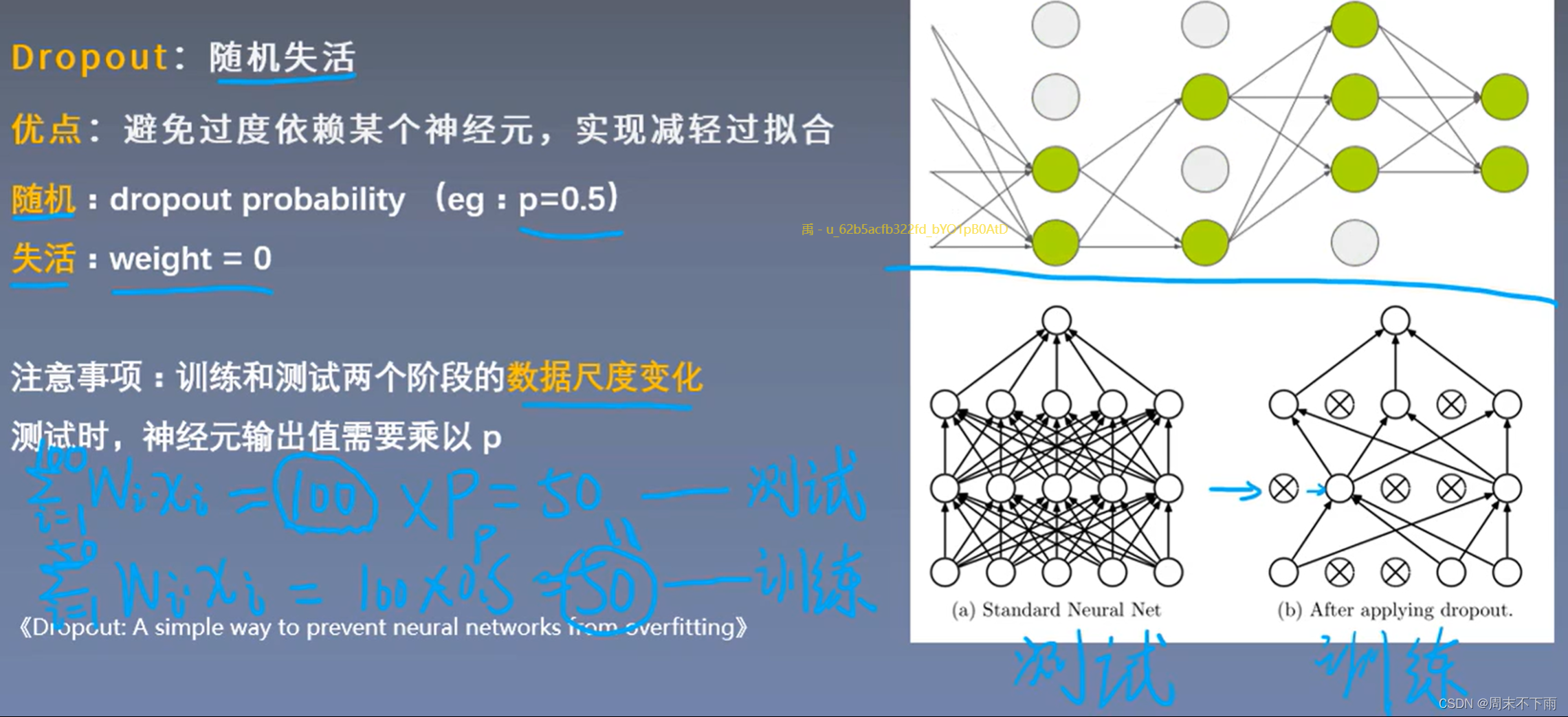
4.4 其他正则化方法
BN在CV中有很大的地位

五、其他
反向传播函数就是为了损失函数更小








![[Cloud Networking] VLAN](https://img-blog.csdnimg.cn/direct/340afe5490b24b13b61c47ebe0d53e26.png)