在推荐系统中,冷启动或长尾是一个常见的问题,模型在数据量较少的user或item上的预测效果很差。造成冷启动样本预测效果不好的重要原因之一是,冷启动样本积累的数据比较少,不足以通过训练得到一个好的embedding(通过user或item的id,映射到一个可学习的向量),进而导致模型在这部分样本上效果较差。
今天这篇文章整理了2020年以来SIGIR、Multimedia等顶会中,围绕如何在数据不充分的情况下生成好的embedding表示的工作,主要集中在推荐系统领域user和item的embedding生成,解法包括domain adaptation、变分自编码器、对比学习、引入用户历史行为序列等。
1、利用域自适应解决冷启动问题
利用Domain Adaptation解决长尾问题的典型论文是ESAM: Discriminative Domain Adaptation with Non-Displayed Items to Improve Long-Tail Performance(SIGIR 2020)。核心思路是通过特征分布、用户反馈等信息,利用DA将尾部item对齐到头部item上。
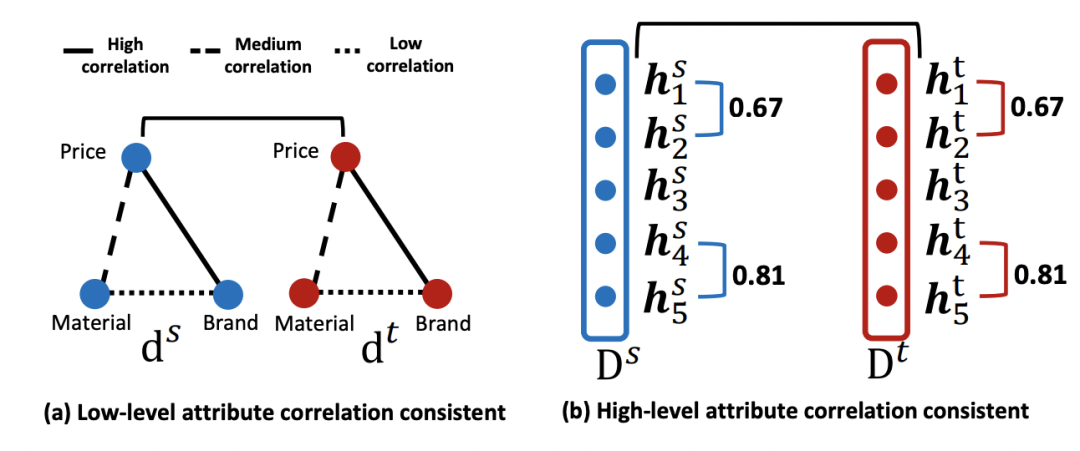
本文解决长尾item的预估准确性问题。长尾item指的是或者展现机会比较少的item,模型在这部分item学习不充分,会导致推荐过程中无法准确实现长尾item的推荐,这又进一步恶化了长尾item的学习,形成马太效应。文中的一个核心假设是,无论一个item是否是长尾,它们的一些属性信息是有关联的,例如奢侈品类型的item价格都高、价格特征和品牌关系更大而和材质关系小等等。这些特征之间的关联是可以从头部item泛化到长尾item上的。
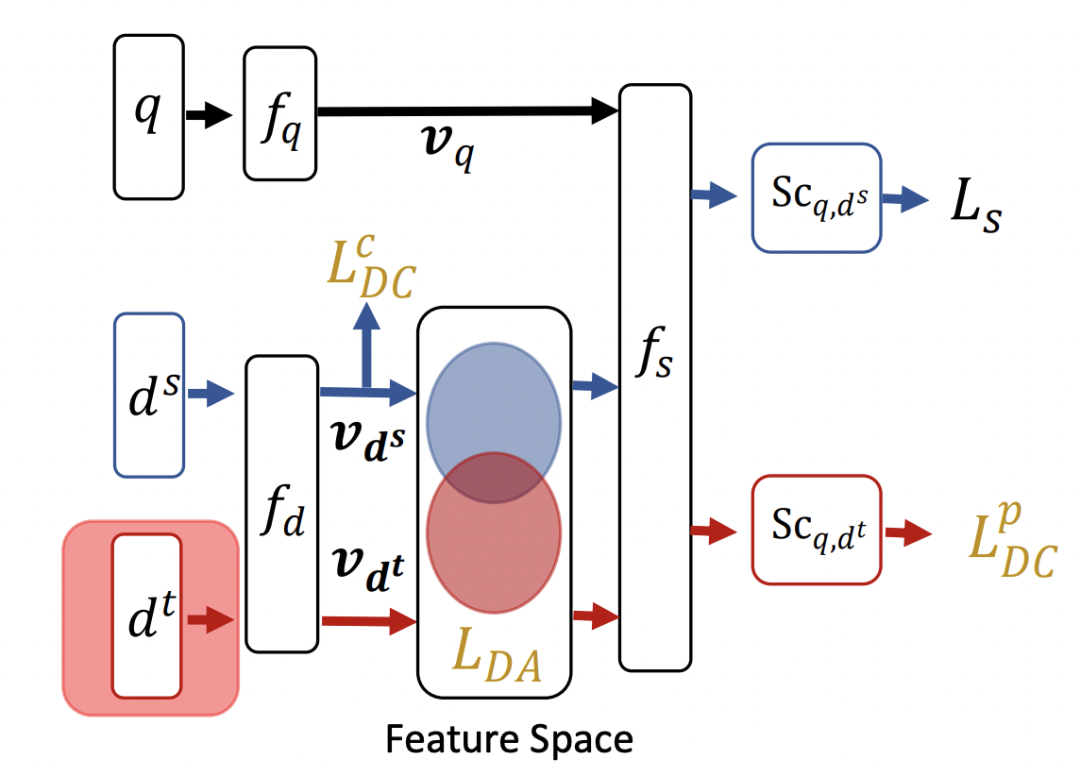
本文主要采用Domain Adaptation的思路对齐头部item和长尾item。首先将头部item和长尾item分别视为source domain和target domain。整体的损失函数公式如下,包括4个部分:
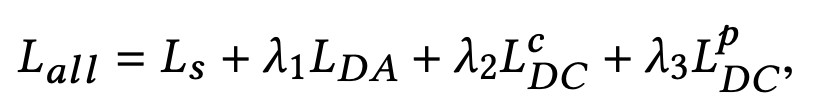
其中Ls是头部item和对应query的预测误差。LDA对应attribute correlation congruence (A2C) ,其目标是为了缩小source domain和target domain特征关系的差异。由于希望长尾item各个特征之间的相互关系与头部一致(例如上面的价格和品牌特征关系更相关,和材质关系弱的规律),这个底层特征规律也会反映到上层item特征表征向量上。因此这里使用下面公式计算两个domain中,item向量各个维度之间的关系的一致性,实际采用mini-batch的方式采样一部分样本计算,公式如下(注意这里的h指的是多个样本某一个维度的向量):
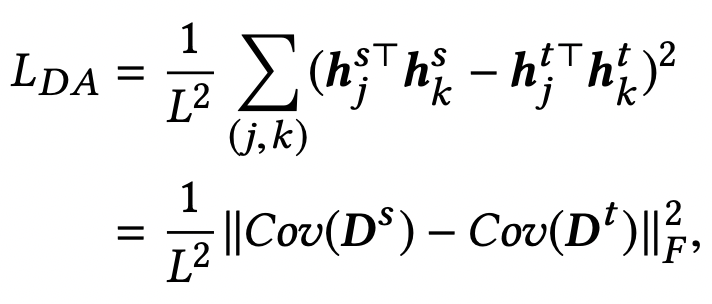
文中的另一个假设是如果两个item相似,它们对应的用户反馈也应该是相似的,不管是否是长尾item,基于此提出了center-wise clustering,也就是LDCc部分,让具有相似用户反馈的item距离更近。最后,文中引入了自监督学习的思路,给未展现的item分配一个伪标签,伪标签来自于上一版模型的预测结果,并且通过正则化生成选择那些足够置信的伪标签,这部分对应LDCp
2、根据属性特征生成embedding
根据属性特征生成embedding是业内解决冷启动问题的常用做法。虽然对于冷启动样本,根据id生成embedding比较困难,但是这些user和item一般都有比较丰富泛化特征,例如用户的年龄、爱好,商品的价格、品类等。因此可以将问题转换为学习一个映射函数,根据泛化特征生成id embedding。
第一篇文章是Recommendation for new users and new items via randomized training and mixture-of experts transformation(SIGIR 2020)。本文同时解决item侧和user侧的冷启动问题,核心思路也是学习一个映射函数,根据user或item的side information生成比较好的id embedding。本文主要包括3个核心点:学习side information到id embedding的映射函数、随机化训练、多专家映射网络。
在映射函数学习上,一方面在模型中只输入side information生成user侧和item侧的表示计算loss;另一方面使用一个预训练的良好id embedding指导映射函数学习,通过L2距离约束映射函数产出embedding和预训练embedding的距离。
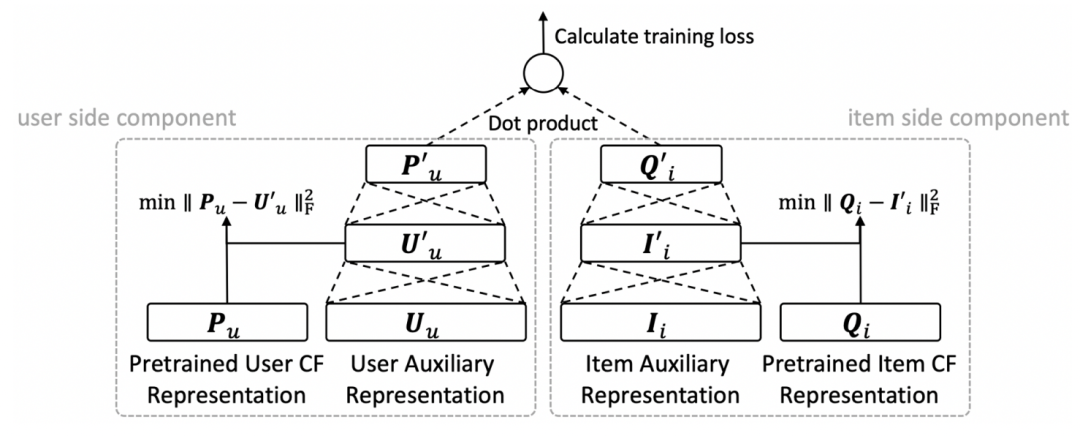
在随机化训练上,上面的框架可能存在一侧信息学的不好影响了另一侧的学习的情况。为了解决这个问题,在训练过程中会以一定概率选择是使用预训练的embedding还是通过映射函数生成的embedding。
最后,以往的映射函数都是所有user或item共用一个,但是实际上一个映射函数可能无法兼容所有情况,例如存在两个user的特征差别很大但是兴趣类似的情况。为了解决这个问题,文中采用了多专家网络的思路,采用多个专家网络生成的embedding进行组合得到最终表示。
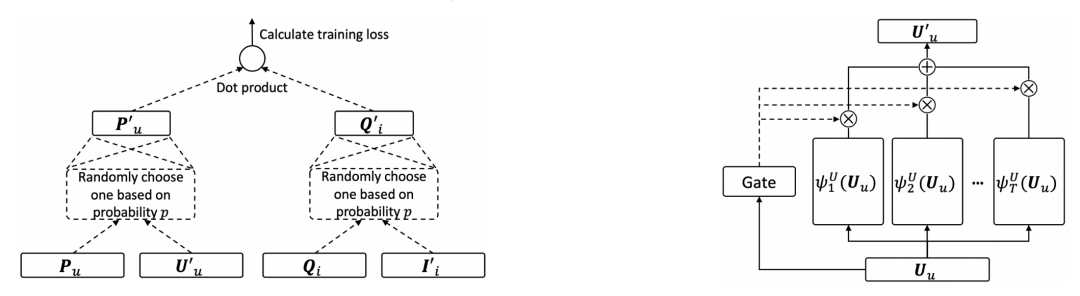
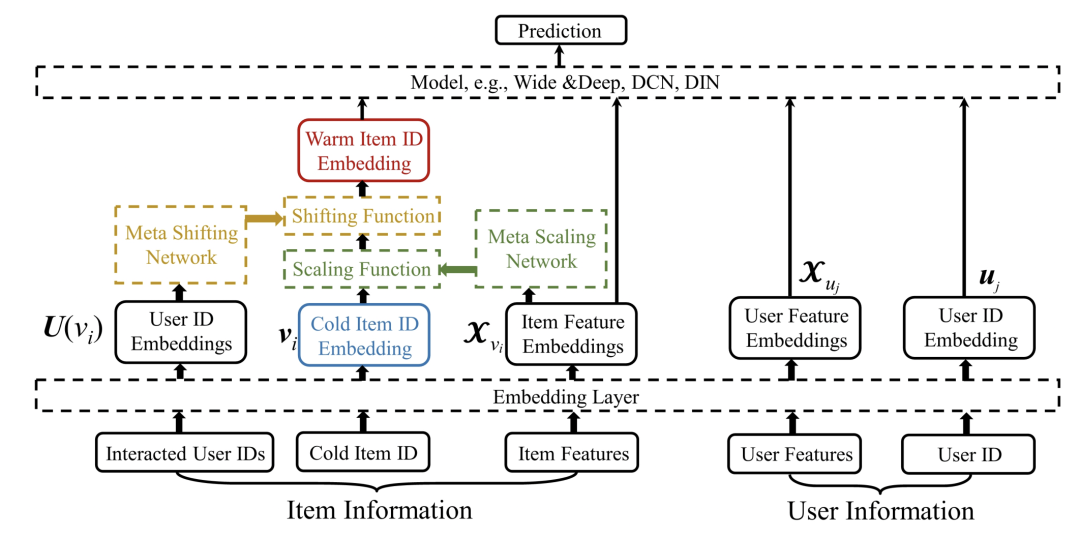
第二篇文章是Learning to warm up cold item embeddings for cold-start recommendation with meta scaling and shifting networks(SIGIR 2021)。本文的核心思路是,具有相似特征、相同用户群体点击的item应该更相似,因此本文利用了item的属性等特征以及user的特征对冷启动item做warm-up。核心公式是下面的scale+shift操作:
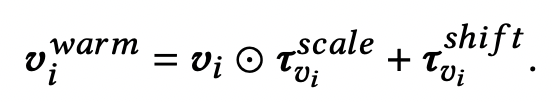
scale操作使用的是item的属性特征生成的向量,shift操作使用的是user的embedding。这两种信息同时作用到初始的item embedding上,实现冷启动embedding的warm-up。
在具体的训练方法上,首先使用所有数据训练一个基础的推荐模型,然后固定住其他参数不变,使用非冷启动item通过数据采样的方式模拟冷启动样本,在这些样本上单独训练scale、shift网络和item的embedding。冷启动item的embedding使用预训练模型产出的全局所有item的embedding求均值得到,避免随初始化影响模型训练。
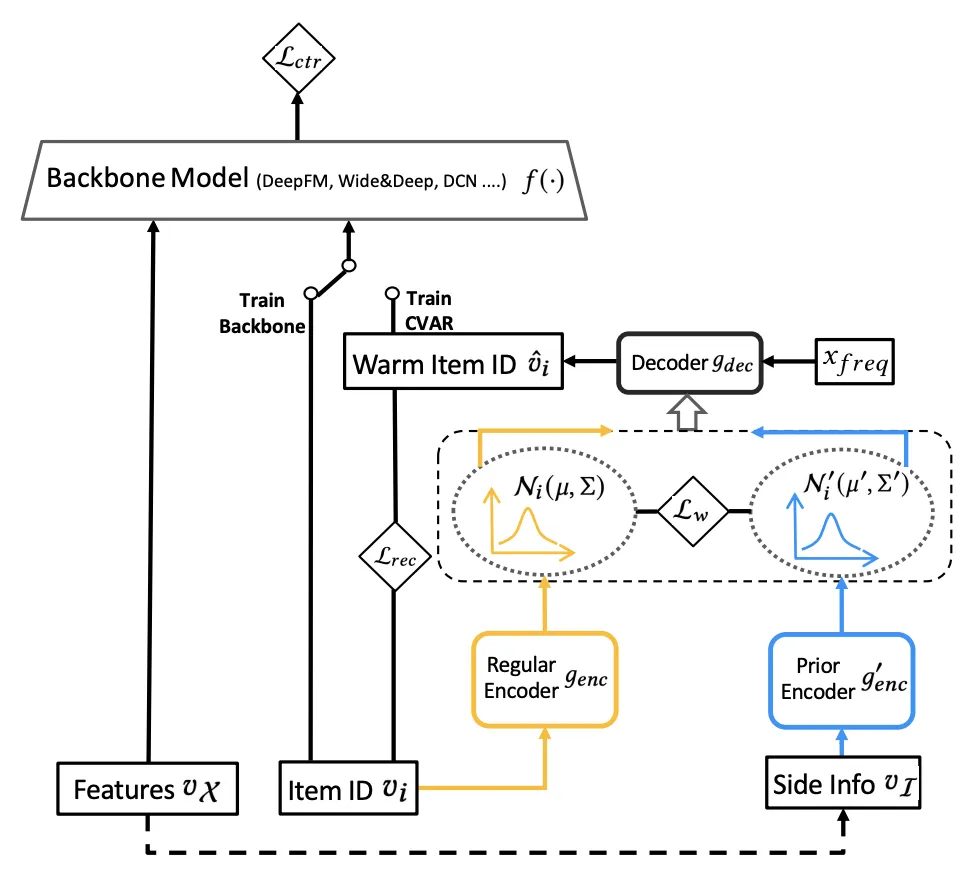
在今年的SIGIR上,***Improving Item Cold-start Recommendation via Model-agnostic Conditional Variational Autoencoder(SIGIR 2022)***提出使用变分自编码器提升使用特征生成id embedding的效果。这篇文章的解决item侧的冷启动问题,核心是利用Conditional Variational AutoEncoder(CVAE)对齐使用side information生成的item embedding和item的id embedding,这样对于冷启动样本可以使用side information生成更好的embedding。具体做法是,使用两个CVAE分别对item id生成的embedding和使用item的side information特征生成的embedding进行自编码,在隐空间让二者分布距离最小。在训练过程中,同一个样本会先使用主模型预估ctr,然后再走另一个自编码通道训练自编码器。
使用CVAE有什么好处呢?因为目标是学习side information到item embedding的映射,而模型在训练过程中得到的item embedding不一定完全反映的是side information,还包含了和user的交互信息,这导致很难让side information和item embedding对齐。因此文中采用CVAE,将item id embedding压缩到隐空间去除噪声,再在隐空间和side information侧信息对齐。
3、基于对比学习学习embedding
基于对比学习学习embedding的典型工作是Contrastive learning for cold-start recommendation(Multimedia 2021)。这里也借助了item的属性特征,通过对比学习拉近同一个item属性特征生成的embedding和id得到的embedding的距离。
本文希望寻找一个本文通过对item表示最优化的推导,得出想要得到最优的item表示需要同时优化两个互信息:第一个是根据历史user-item的交互行为优化user-item的互信息;第二个是item的协同过滤信号得到的embedding与使用内容信息得到embedding的互信息。
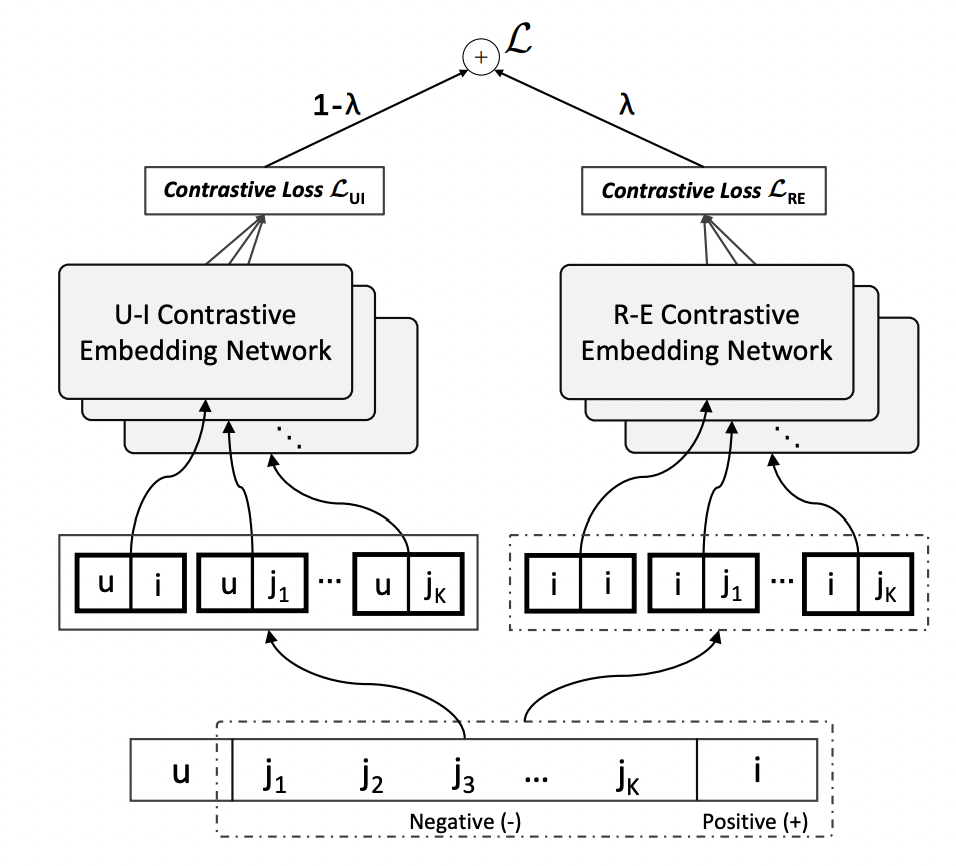
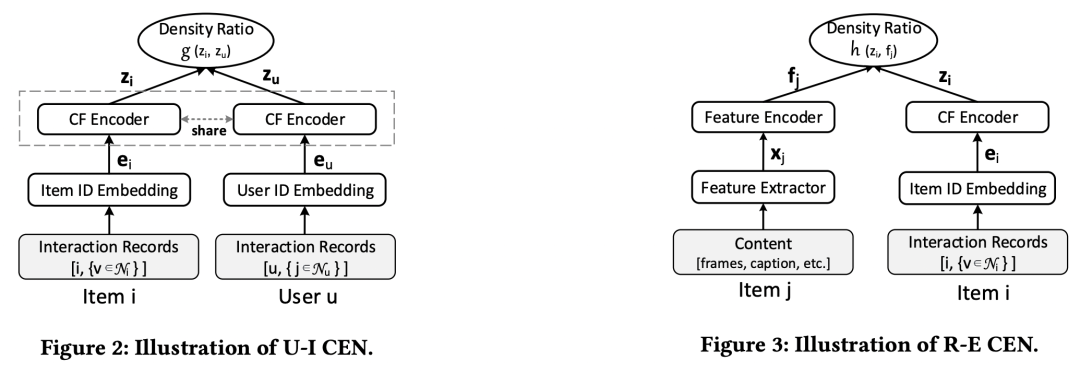
在优化上述互信息采用的是对比学习的方法学习。对于user-item的互信息,正样本为有交互的user-item pair,负样本中适应随机采样的item,直接使用id embedding加上一个Encoder学习二者的协同过滤embedding。对于item-item的互信息,同一个item为正样本,该item和其他随机采样的item为负样本,对比学习让通过内容生成的embedding和协同过滤学到的embedding相似。
4、根据用户历史行为生成embedding
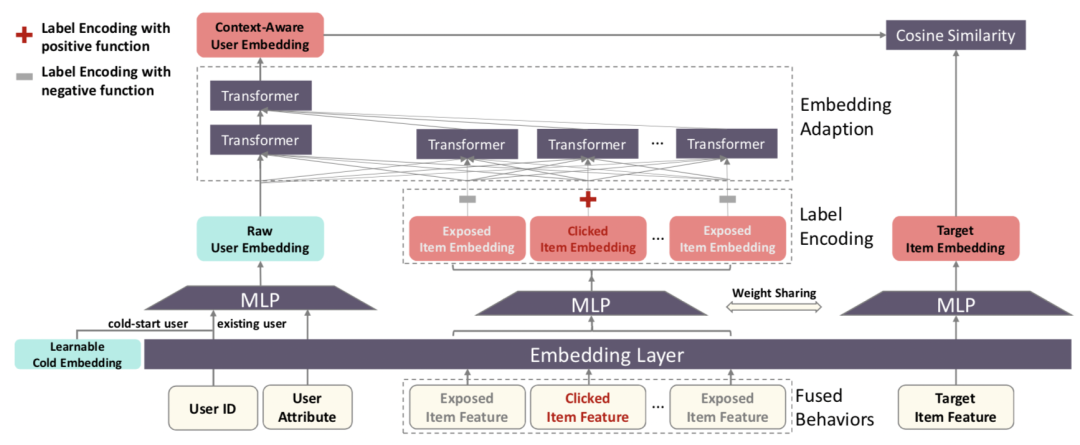
在今年SIGIR 2022中阿里发表了一篇文章Transform Cold-Start Users into Warm via Fused Behaviors in Large-Scale Recommendation(SIGIR 2022),主要利用用户的历史行为数据解决冷启动user的问题,一个核心点是引入曝光未点击的数据扩充冷启动用户稀疏的历史行为。一般的做法是对冷启动user生成一个更好的user id embedding。这种方法的缺点是生成user id embedding的网络是用非冷启动用户训练的,而冷启动用户和非冷启动用户的特征分布差异很大,导致非冷启动用户上训练的embedding生成器在冷启动用户上可能并不适用。本文的做法是使用用户的历史行为作为context来warm up初始的user embedding。具体做法是将用户历史行为序列和初始的user embedding拼接后过Transformer,实现user embedding的转换。
由于冷启动user的历史行为稀疏,点击行为就更稀疏了,因此本文会将用户历史点击和曝光未点击的行为都加进来作为历史行为序列,缓解冷启动用户的历史行为序列稀疏问题。点击和不点击是两种不同类型的交互行为,为了区分这两种不同的交互行为,文中将行为序列中每个item的embedding做了一步label encoding的变换,用一个可学习的参数根据交互类型(点击或未点击)进行转换,公式如下,其中rpos和rneg是两个带有可学习参数的转换函数,y是交互的类型:
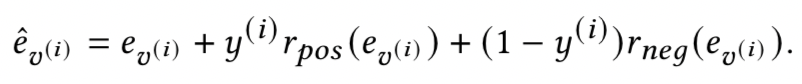
最后,本文在训练过程中会将冷启动user的embedding以一定概率替换成一个全局可学习的冷启动embedding,帮助模型对齐冷启动和非冷启动的id embedding分布。
5、总结
本文主要围绕推荐系统中,如何给冷启动或长尾的样本生成好的id embedding表示这一问题,介绍了近年来4种思路6篇顶会工作。包括domain adaptation、变分自编码器、对比学习、引入用户历史行为序列等多种类型的解法。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。